이 글은 Preprocessing Unstructured Data for LLM Applications 코스를 보고 정리한 글입니다.
RAG Pipeline 의 핵심 요소들:
- Data Loading
- Chunking
- Embedding
- Storing in the vector database
- Retrieval
여기서는 Data Loading 과 Chunking 에 대해 데이터를 pre-processing 하는 부분을 집중적으로 다룸.
1. Overview of LLM Data Preprocessing
Data Preproocessing 이 사용되는 곳:
- Vector Store 에 데이터를 적재할 때 사용됨.
- Vector Store 에 적재되고 나면 LLM 에게 질문을 할 때 관련 정보를 검색해서 컨택스를 채워서 LLM 에게 질문을 할거임. 그러면 LLM 은 이 컨택스트로 부터 배워서 답변을 할거고.
Vector Database 에 적재되는 Document 는 크게 두 가지 요소로 분리해서 생각하면 된다:
- Document Element:
- Context 를 채울 Building block 임.
- Chunk 단위로 저장될 데이터들이기도 함.
- Title, Narrative Text, List Item, Table, Image 와 같은 데이터들이 있을 것.
- Element Metadata:
- Document Element 에 대한 metadata 임.
- 이런 메타 데이터를 이용해서 Hybrid Search 에 이용되서 필터링 할 수도 있을 것.
- Filename, FileType, Page Number, Section 등이 있음.
왜 Data Preprocessing 이 어려운가?
- 세상에는 다양한 데이터 포맷이 많음 (e.g Excel, HTML, PDF, Powerpoint, Word 등) 그리고 우리는 이 데이터를 가능한 같은 방식으로 표준을 정해서 처리하고 싶어한다. 이게 코드적으로도 깔끔하니까.
- 그러나 이런 Document 들은 다양한 포맷과 구조로 이뤄져있어서 쉽지 않다. HTML 은 Tag 를 기반으로 헤더 정보가 감싸져있다면 Markdown 은 '#' 라는 표현으로 표시되는 식으로 각자 다양한 요소로 표현되고 있기 때문임. 이런 것들 때문에 각 File format 마다 접근 방식이 달라져야 할 수도 있고, 이런 구조를 알아야지만 메타 데이터를 뽑아낼 수 있을거임.
2. Normalizing the Content
Data Preprocessing 은 다양한 포맷의 데이터를 공통의 포맷 데이터로 변환 시킨 후 사용하기 쉽게 JSON 으로 직렬화 하는거임.
이렇게 하면 여러가지 이점이 있음:
- 이 과정에서 불필요한 요소들은 다 제거하고 일관된 포맷으로 인해서 다음 Downstream Task 부터는 쉽게 사용할 수 있음.
- 공통된 포맷이기 때문에 Vector Store 에 Chunk 단위로 저장할 때 문서 별로 다양한 Chunk 전략을 할 필요없이 일관된 전략을 할 수 있음.
- JSON 구조로 직렬화해서 문서를 저장해둔다면 어떤 어플리케이션에서도 쉽게 사용할 수 있을 것.
공통된 포맷은 이런식으로 표현될거임:

여기서의 Data preprocessing 과정을 보면 비교적 쉬운 Semi-Structure 인 HTML 과 Powerpoint 는 Unstructured 라이브러리를 써서 공통된 포맷을 만드는 반면에 비교적 복잡한 파일 포맷인 PDF 인 경우에는 Model 기반으로 접근한다.
그래서 PDF 는 Unstructured API 를 이용함. 앞으로는 이런식으로 복잡한 구조하되어 있지 않은 데이터는 Open Source Model 을 튜닝하는 식으로 사용할 것 같음.
HTML 페이지부터 공통된 포맷으로 변경하는 예시부터 보자.
- 이 예시는 비교적 간단함. <h1> 태그에 HTML Title 이 들어가있고,<p> 태그에는 narritive text 가 들어가있을 것.
먼저 필요한 라이브러리를 다운받는다.
from IPython.display import JSON
import json
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.partition.html import partition_html
from unstructured.partition.pptx import partition_pptx
from unstructured.staging.base import dict_to_elements, elements_to_json
그리고 나중에 PDF 에서 사용할 Unstructured Client 도 세팅해놈.
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
)
다음과 같은 HTML 페이지가 있다고 가정해보자.
from IPython.display import Image
Image(filename="images/HTML_demo.png", height=600, width=600)
이를 공통된 포맷으로 바꾸는 건 간단함. 파일 이름을 가지고 오픈소스 라이브러리인 Unstructured 의 partition_html() 을 호출하면 됨.
filename = "example_files/medium_blog.html"
elements = partition_html(filename=filename)
그리고 이를 JSON 으로 직렬화한다.
element_dict = [el.to_dict() for el in elements]
example_output = json.dumps(element_dict[11:15], indent=2)
print(example_output)
그러면 이런식으로 출력을 볼 수 있음:
[
{
"type": "Title",
"element_id": "29887a5ff9846ccc23327565a07e17fa",
"text": "Share",
"metadata": {
"category_depth": 0,
"last_modified": "2024-03-30T04:25:39",
"page_number": 1,
"languages": [
"eng"
],
"file_directory": "example_files",
"filename": "medium_blog.html",
"filetype": "text/html"
}
},
{
"type": "NarrativeText",
"element_id": "2bc60d779d5ea8114272b3c498f34643",
"text": "In the vast digital universe, data is the lifeblood that drives decision-making and innovation. But not all data is created equal. Unstructured data in images and documents often hold a wealth of information that can be challenging to extract and analyze.",
"metadata": {
"last_modified": "2024-03-30T04:25:39",
"page_number": 1,
"languages": [
"eng"
],
"parent_id": "29887a5ff9846ccc23327565a07e17fa",
"file_directory": "example_files",
"filename": "medium_blog.html",
"filetype": "text/html"
}
},
{
"type": "NarrativeText",
"element_id": "03ceadc8956df0cbeb81d1b103e75ba0",
"text": "Enter Unstructured.io, a powerful tool to extract and efficiently transform structured data. With sixteen and counting pre-built connectors, the API can easily integrate with various data sources, including AWS S3, GitHub, Google Cloud Storage, and more.",
"metadata": {
"last_modified": "2024-03-30T04:25:39",
"link_texts": [
"Unstructured.io"
],
"link_urls": [
"https://www.unstructured.io/"
],
"page_number": 1,
"languages": [
"eng"
],
"parent_id": "29887a5ff9846ccc23327565a07e17fa",
"file_directory": "example_files",
"filename": "medium_blog.html",
"filetype": "text/html"
}
},
{
"type": "NarrativeText",
"element_id": "c08851ba52bd7d9d68c0398c1634a1fb",
"text": "In this guide, we\u2019ll cover the advantages of using the Unstructured API and Connector module, walk you through a step-by-step process of using it with the S3 Connector as an example, and show you how to be a part of the Unstructured community.",
"metadata": {
"last_modified": "2024-03-30T04:25:39",
"page_number": 1,
"languages": [
"eng"
],
"parent_id": "29887a5ff9846ccc23327565a07e17fa",
"file_directory": "example_files",
"filename": "medium_blog.html",
"filetype": "text/html"
}
}
]
다음으로는 Powerpoint 를 공통된 포맷으로 바꾸는 걸 보자.

filename = "example_files/msft_openai.pptx"
elements = partition_pptx(filename=filename)
element_dict = [el.to_dict() for el in elements]
JSON(json.dumps(element_dict[:], indent=2))
이렇게 출력될거임:


마지막은 PDF 파일:
코드는 다음과 같다:
filename = "example_files/CoT.pdf"
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(
files=files,
strategy='hi_res',
pdf_infer_table_structure=True,
languages=["eng"],
)
try:
resp = s.general.partition(req)
print(json.dumps(resp.elements[:3], indent=2))
except SDKError as e:
print(e)
JSON(json.dumps(resp.elements, indent=2))
출력 결과는 다음과 같을 것:
[
{
"type": "Title",
"element_id": "826446fa7830f0352c88808f40b0cc9b",
"text": "B All Experimental Results",
"metadata": {
"filetype": "application/pdf",
"languages": [
"eng"
],
"page_number": 1,
"filename": "CoT.pdf"
}
},
{
"type": "NarrativeText",
"element_id": "055f2fa97fbdee35766495a3452ebd9d",
"text": "This section contains tables for experimental results for varying models and model sizes, on all benchmarks, for standard prompting vs. chain-of-thought prompting.",
"metadata": {
"filetype": "application/pdf",
"languages": [
"eng"
],
"page_number": 1,
"parent_id": "826446fa7830f0352c88808f40b0cc9b",
"filename": "CoT.pdf"
}
},
{
"type": "NarrativeText",
"element_id": "9bf5af5255b80aace01b2da84ea86531",
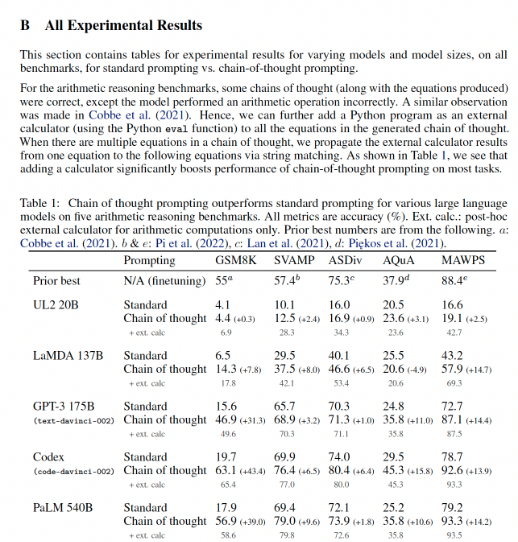
"text": "For the arithmetic reasoning benchmarks, some chains of thought (along with the equations produced) were correct, except the model performed an arithmetic operation incorrectly. A similar observation was made in Cobbe et al. (2021). Hence, we can further add a Python program as an external calculator (using the Python eval function) to all the equations in the generated chain of thought. When there are multiple equations in a chain of thought, we propagate the external calculator results from one equation to the following equations via string matching. As shown in Table 1, we see that adding a calculator signi\ufb01cantly boosts performance of chain-of-thought prompting on most tasks.",
"metadata": {
"filetype": "application/pdf",
"languages": [
"eng"
],
"page_number": 1,
"parent_id": "826446fa7830f0352c88808f40b0cc9b",
"filename": "CoT.pdf"
}
}
]
3. Metadata Extraction and Chunking
Metadata 는 어떻게 쓰이는가?
- 문서 자체에 대한 디테일한 설명들이 포함될 수 있음.
- Metadata 를 기반으로 데이터 필터링.
- 데이터 소스에 대한 정보들 (e.g filename, filetype, source URL)
- 구조적인 정보들. 해당 Element 가 어떤 Parent Section 에 속하는가 등에 대한 정보를 말함. Document 문서를 보면 대단원, 중단원, 소단원 등으로 나눠져있을거임. 해당 문서의 narritve text 가 소단원, 중단원, 대단원 중 어디에 속하느냐에 대한 정보를 말함.
Metadata 는 다음과 같을 것:

여기서 말하는 Hybrid Search 가 필요한 이유 (여기서는 BM25 와 같은 Keyword Matching 알고리즘을 사용해서 검색하는 걸 Hybrid
Search 라고 생각하지 않고, Semantic Search 에다가 필터링 기능을 합친 걸 Hybrid Search 라고 생각하는듯)
- Semantic Search 는 중복된 내용의 문서를 가져올 수 있음.
- 그리고 최신 정보만이 필요한 상황인데도 과거의 문서를 가져올 수도 있음.
- 중요한 정보가 다소 부족할 수도 있음. 중요한 정보는 이 Chunk 와 연관된 Chunk 에 있을 수 있다.
Metadata 를 이용해서 Chunking 을 잘 구성하는 것도 가능함.
먼저 Chunking 을 구성해야 하는 이유로는 LLM 의 Context Window 제약조건 때문임.
LLM 이 주어진 질문에 잘 답변하기 위해서는 컨택스트 정보를 풍부하게 줘야함. 그런데 이런 공간은 제약적이기 때문에 꼭 필요한 내용으로만 채워서 Context 를 구성하는게 좋음.
이를 위해 문서 전체를 이용해서 Context 를 구성하기 보다는 문서의 내용을 Chunk 단위로 자르고 Chunk 를 Vector Store 에서 잘 찾아와서 Context 를 구성하는게 중요하다.
그리고 이렇게 하는게 비용 측면에서도 더 저렴할 것.
가장 기본적인 Chunking 을 하는 전략은 문서의 텍스트를 일정한 사이즈의 Token 이나 Characters 로 잘라서 균일하게 내놓는 거임.
- 이 방식의 단점은 Context 를 풍부하게 만들기 어렵다는 거임.
- 질문이 들어왔을 떄 몇 개의 Chunk 들만 가지고 컨택스트를 구성하기에는 중요한 정보가 없을 수 있고, 비슷한 정보들만 제공하는 것일수도 있음. 같은 주제의 정보가 다른 chunk 로 쪼개질 수 있으니
하지만 Metadata 를 이용할 경우에는 이런 Chunking 전략을 좀 더 지헤롭게 해서 Context 를 풍부하게 만들 수 있음.
하나의 글에는 챕터가 있고 각 챕터 별로 소주제로 나뉜다. 이렇게 계층화된 구조로 이뤄져있는데 이를 Metadata 에 포함시켜서 검색할 때 Chunk 를 조립시키는 방식으로도 할 수 있는거임.
이전에 공통된 포맷으로 preprocessing 을 한 element 들로 chunking 을 만들 때는 다음과 같을거임:
- 하나의 Section 이나 Title 에서의 Element 들을 Chunk 로 만들거임. Element 들이 요소가 작다면 Chunk 로 합치도록 할 것.
- 그리고 다음 Section 이 나온다면 이제 새로운 Chunk 부터 다시 시작하면 됨.
이제 실습 코드 예시를 보자. 먼저 Document 를 공통된 포맷으로 변경하고, 이를 Chroma Vector Store 에 적재한 후 필터링 검색을 해볼거임.
필요한 라이브러리를 로드하고, Unstructured API 세팅한 후, 어떤 문서를 Vector Store 에 적재할 건지 보는 코드:
# Warning control
import warnings
warnings.filterwarnings('ignore')
import logging
logger = logging.getLogger()
logger.setLevel(logging.CRITICAL)
import json
from IPython.display import JSON
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.chunking.basic import chunk_elements
from unstructured.chunking.title import chunk_by_title
from unstructured.staging.base import dict_to_elements
import chromadb
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
)
from IPython.display import Image
Image(filename='images/winter-sports-cover.png', height=400, width=400)

Unstructured API 를 이용해서 Document 를 Preprocessing 하는 코드:
filename = "example_files/winter-sports.epub"
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(files=files)
try:
resp = s.general.partition(req)
except SDKError as e:
print(e)
JSON(json.dumps(resp.elements[0:3], indent=2))
이런 데이터가 JSON 으로 들어가있을거임.
[{'type': 'Title',
'element_id': '6c6310b703135bfe4f64a9174a7af8eb',
'text': 'The Project Gutenberg eBook of Winter Sports in\nSwitzerland, by E. F. Benson',
'metadata': {'languages': ['eng'],
'filename': 'winter-sports.epub',
'filetype': 'application/epub'}},
{'type': 'NarrativeText',
'element_id': '9ecb42d4f263247a920448ed98830388',
'text': '\nThis ebook is for the use of anyone anywhere in the United States and\nmost other parts of the world at no cost and with almost no restrictions\nwhatsoever. You may copy it, give it away or re-use it under the terms\nof the Project Gutenberg License included with this ebook or online at\n',
'metadata': {'languages': ['eng'],
'parent_id': '6c6310b703135bfe4f64a9174a7af8eb',
'filename': 'winter-sports.epub',
'filetype': 'application/epub'}},
{'type': 'NarrativeText',
'element_id': '87ad8d091d5904b17bc345b10a1c964a',
'text': 'www.gutenberg.org. If you are not located\nin the United States, you’ll have to check the laws of the country where\nyou are located before using this eBook.',
'metadata': {'languages': ['eng'],
'parent_id': '6c6310b703135bfe4f64a9174a7af8eb',
'filename': 'winter-sports.epub',
'filetype': 'application/epub'}}]
Vector Store 에 적재하기 전에 preprocessing 한 요소를 각 Section 과 연관시켜주는 작업을 하자.
그러니까 내용을 챕터 별로 묶어주는 역할을 하는거임. Vector Store 에는 Chunk 별로 데이터가 들어갈텐데, 이게 어떤 챕터와 연결되어 있는지 메타데이터에 넣어서 연결시키는거지.
그리고 Chunk 를 조회할 때 해당 챕터와 연결되어 있는 내용을 같이 조회해서 Context 를 구성할거임.
다음 코드는 챕터 이름과 Chapter Id 를 매핑시켜주는 코드임.
chapters = [
"THE SUN-SEEKER",
"RINKS AND SKATERS",
"TEES AND CRAMPITS",
"ICE-HOCKEY",
"SKI-ING",
"NOTES ON WINTER RESORTS",
"FOR PARENTS AND GUARDIANS",
]
chapter_ids = {}
for element in resp.elements:
for chapter in chapters:
if element["text"] == chapter and element["type"] == "Title":
chapter_ids[element["element_id"]] = chapter
break
chapter_ids
출력 결과는 다음과 같을 것:
{'a37f63b4dd470e0bc0d4d92e66758183': 'THE SUN-SEEKER',
'1766cdc7e0052527c77938d0a51d0495': 'RINKS AND SKATERS',
'99ff7a9efd2518b35b27b9bee204fc1d': 'TEES AND CRAMPITS',
'6cf4a015e8c188360ea9f02a9802269b': 'ICE-HOCKEY',
'f342e4727343974b173134e6931b9158': 'SKI-ING',
'a784c0efc6886ee75314b5fbb7b60ba0': 'NOTES ON WINTER RESORTS',
'ecc5c7f65b2e27481f7a70508aa9a4c4': 'FOR PARENTS AND GUARDIANS'}
예시로 이런식으로 해당 Chapter 에 대한 글들만 모을 수 있음.
chapter_to_id = {v: k for k, v in chapter_ids.items()}
[x for x in resp.elements if x["metadata"].get("parent_id") == chapter_to_id["ICE-HOCKEY"]][0]
다음은 Chroma Vector Store 에 해당 글들을 저장하는 코드: (글들은 Chatper 와 연결되어 있음 metadata 로)
client = chromadb.PersistentClient(path="chroma_tmp", settings=chromadb.Settings(allow_reset=True))
client.reset()
collection = client.create_collection(
name="winter_sports",
metadata={"hnsw:space": "cosine"}
)
for element in resp.elements:
parent_id = element["metadata"].get("parent_id")
chapter = chapter_ids.get(parent_id, "")
collection.add(
documents=[element["text"]],
ids=[element["element_id"]],
metadatas=[{"chapter": chapter}]
)
results = collection.peek()
print(results["documents"])
출력 결과:
['[Image\nunavailable.]', '[Image\nunavailable.]', 'Here is a remarkably varied programme, and one that will obviously\ngive a good spell of regular work to a candidate who intends to grapple\nwith it. It contains more of the material for skating than does the\ncorresponding English second test, in which only the four edges, the\nfour simple turns, and the four changes of edge are introduced, since\nthis International second test comprises as well as those, the four\nloops, and two out of the four brackets. These\nloops, which are most charming and effective figures, have nowadays no\nplace in English skating, since it is quite impossible to execute any of\nthem, as far as is at present known, without breaking the rules for\nEnglish skating, since the unemployed leg (i.e. the one not\ntracing the figure) must be used to get the necessary balance and swing.\nThey belong to a great class of figures like cross-cuts in all their\nvarieties, beaks, pigs-ears, &c., in which the skater nearly, or\nactually, stops still for a moment, and then, by a swing of the body or\nleg, resumes or reverses his movement. By this momentary loss and\nrecovery of balance there is opened out to the skater whole new fields\nof intricate and delightful movements, and the patterns that can be\ntraced on the ice are of endless variety. And here in this second\nInternational test the confines of this territory are entered on by the\nfour loops, which are the simplest of the “check and recovery” figures.\nIn the loops (the shape of which is accurately expressed by their names)\nthe skater does not come absolutely to a standstill, though very nearly,\nand the swing of the body and leg is then thrown forward in front of the\nskate, and this restores to it its velocity, and pulls it, so to speak,\nout of its loop. A further extension of this check and resumption of\nspeed occurs in cross-cuts, which do not enter into the International\ntests, but which figure largely in the performance of good skaters. Here\nthe forward movement of the skate (or backward movement, if back\ncross-cuts are being skated) is entirely checked, the skater comes to a\nmomentary standstill and moves backwards for a second. Then the forward\nswing of the body and unemployed leg gives him back his checked and\nreversed movement.', '[Image\nunavailable.]', '(a) A set of combined figures skated with another skater,\nwho will be selected by the judges, introducing the following calls in\nsuch order and with such repetitions as the judges may direct:—', 'CHAPTER\nVII', 'The figures need not be commenced from rest.', 'But when we consider that the first-class skater must be able to\nskate at high speed on any edge, make any turn at a fixed point, and\nleave that fixed point (having made his turn and edge in compliance with\nthe proper form for English skating, without scrape or wavering) still\non a firm and large-circumferenced curve, that he must be able to\ncombine any mohawk and choctaw with any of the sixteen turns, and any of\nthe sixteen turns with any change of edge, and that in combined skating\nhe is frequently called upon to do all these permutations of edge and\nturn, at a fixed point, and in\ntime with his partner, while two other partners are performing the same\nevolution in time with each other, it begins to become obvious that\nthere is considerable variety to be obtained out of these manœuvres. But\nthe consideration of combined skating, which is the cream and\nquintessence of English skating, must be considered last; at present we\nwill see what the single skater may be called upon to do, if he wishes\nto attain to acknowledged excellence in his sport.', 'Plate XXXII', 'He delivers the stone: the skip, eagle-eyed, watches the pace of it.\nIt may seem to him to be travelling with sufficient speed to reach the\nspot at which he desires it should rest. In this case he says nothing\nwhatever, except probably “Well laid down.” Smoothly it glides, and in\nall probability he will exclaim “Not a touch”: or (if he is very Scotch,\neither by birth or by infection of curling) “not a cow” (which means not\na touch of the besom). On the other hand he may think that it has been\nlaid down too weakly and will not get over the hog-line. Then he will\nshriek out, “Sweep it; sweep it” (or “soop it; soop it”) “man” (or\n“mon”). On which No. 2 and No. 3 of his side burst into frenzied\nactivity, running by the side of the stone and polishing the surface of\nthe ice immediately in front of it with their besoms. For, however well\nthe ice has been prepared, this zealous polishing assists a stone to\ntravel, and vigorous sweeping of the ice in front of it will give, even\non very smooth and hard ice, several feet of additional travel, and a\nstone that would have been hopelessly hogged will easily be converted\ninto the most useful of stones by diligent sweeping, and will lie a\nlittle way in front of the house where the skip has probably directed it\nto be. If he is an astute and cunning old dog, as all skips should be,\nhe will not want this first stone in the house at all; in fact, if he\nsees it is coming into the house, he will probably say “too strong.”\nYet, since according to\nthe rules only stones inside the house can count for the score, it seems\nincredible at first sight why he should not want every stone to be\nthere. This “inwardness” will be explained later.']
Chroma Vector Store 에 저장된 Document 를 특정 Chapter 별로 필터링해서 검색하는 코드:
result = collection.query(
query_texts=["How many players are on a team?"],
n_results=2,
where={"chapter": "ICE-HOCKEY"},
)
print(json.dumps(result, indent=2))
출력 결과:
{
"ids": [
[
"241221156e35865aa1715aa298bcc78d",
"7a2340e355dc6059a061245db57f925b"
]
],
"distances": [
[
0.5229758024215698,
0.7836340665817261
]
],
"metadatas": [
[
{
"chapter": "ICE-HOCKEY"
},
{
"chapter": "ICE-HOCKEY"
}
]
],
"embeddings": null,
"documents": [
[
"It is a wonderful and delightful sight to watch the speed and\naccuracy of a first-rate team, each member of which knows the play of\nthe other five players. The finer the team, as is always the case, the\ngreater is their interdependence on each other, and the less there is of\nindividual play. Brilliant running and dribbling, indeed, you will see;\nbut as distinguished from a side composed of individuals, however good,\nwho are yet not a team, these brilliant episodes are always part of a\nplan, and end not in some wild shot but in a pass or a succession of\npasses, designed to lead to a good opening for scoring. There is,\nindeed, no game at which team play outwits individual brilliance so\ncompletely.",
"And in most places hockey is not taken very seriously: it is a\ncharming and heat-producing scramble to take part in when the out-door\nday is drawing to a close and the chill of the evening beginning to set\nin; there is a vast quantity of falling down in its componence and not\nvery many goals, and a general ignorance about rules. But since a game,\nespecially such a wholly admirable\nand delightful game as ice-hockey, may just as well be played on the\nlines laid down for its conduct as not, I append at the end of this\nshort section a copy of the latest edition of the rules as issued by\nPrince\u2019s Club, London."
]
],
"uris": null,
"data": null
}
다음은 가볍게 Chunking 을 해보는 코드임:
- elements 를 합쳐서 chunk 로 만드는 코드임. 하나의 Cbunk 당 크기는 max_characters 설정에 따라서 3000 으로 하고, 각 Element 의 크기가 100 글자보다 작을 때 하나의 Chunk 로 합쳐짐
- len(elements) 를 하면 750 개 정도 나올거고, len(chunks) 하면 250개 정도 나옴.
elements = dict_to_elements(resp.elements)
chunks = chunk_by_title(
elements,
combine_text_under_n_chars=100,
max_characters=3000,
)
chunks[0].to_dict(), indent=2
출력 결과:
{\n "type": "CompositeElement",\n "element_id": "064cf072a51da0b00f32510011bfa7dc",\n "text": "The Project Gutenberg eBook of Winter Sports in\\nSwitzerland, by E. F. Benson\\n\\n\\nThis ebook is for the use of anyone anywhere in the United States and\\nmost other parts of the world at no cost and with almost no restrictions\\nwhatsoever. You may copy it, give it away or re-use it under the terms\\nof the Project Gutenberg License included with this ebook or online at\\n\\n\\nwww.gutenberg.org. If you are not located\\nin the United States, you\\u2019ll have to check the laws of the country where\\nyou are located before using this eBook.",\n "metadata": {\n "filename": "winter-sports.epub",\n "filetype": "application/epub",\n "languages": [\n "eng"\n ]\n }\n}
4. Preprocessing PDFs and Images
여기서는 단순한 PDF 파일 (문서의 레이아웃이 명확하고, 심플하게 나눠진 경우) 이 아닌 복잡한 레이아웃을 가졌거나, 스캔한 문서로 PDF 파일이 만들어 졌을 때 이것에 대한 텍스트를 추출하는 방법과 Image 에서 텍스트 데이터를 추출하는 방법에 대해서 다룬다.
주로 구조화 되어있는 파일들인 HTML 이나 Markdown 이 아닌 파일들에 대해서 처리하는 방법임.
크게 두 가지 방법이 있음:
- Document Layout Detection
- Vision Transformer Model
Document Layout Detection:
- OCR 을 이용해서 텍스트를 추출하는 방법이다. (물론 간단한 PDF 파일이라면 그냥 텍스트를 추출할 수도 있음)
- 이를 위해서 Yolox 모델을 이용해서 Object Dection 을 하고, 해당 객체가 무엇인지 라벨링을 해놓으면 OCR 을 해서 텍스트를 추출할 수 있다.
- 모르는 라벨링의 경우에는 추출하기가 힘듬. 그래서 유연성이 떨어질 수 있으나 Vision 모델 보다는 싸다.
Vision Transformer Model:
- Vision 모델에다가 image 를 넣으면 텍스트를 JSON 형식으로 추출하는 방법이다.
- 어떠한 구조화되어 있지 않는 모델이라도 유연하게 사용할 수 있다.
- 계산 비용이 많이 들어가고, 할루시네이션이 생길 수 있는 문제가 발생할 수 있음.
여기서는 같은 파일이 HTML 과 PDF 로 있다고 했을 떄 데이터 추출을 비교해볼거임. HTML 은 이전에 살펴본대로 Unstructured 라이브러리를 쓰고, PDF 는 여기서 배운 Document Layout Detection 을 사용해볼것.
먼저 필요한 라이브러리를 다운받고, UnstructuredClient 를 설정하자.
# Warning control
import warnings
warnings.filterwarnings('ignore')
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.partition.html import partition_html
from unstructured.partition.pdf import partition_pdf
from unstructured.staging.base import dict_to_elements
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
)
다음 CNN 뉴스들을 가지고, 데이터 처리를 해볼거임
from IPython.display import Image
Image(filename="images/el_nino.png", height=600, width=600) 
먼저 HTML 부터 처리해보자.
filename = "example_files/el_nino.html"
html_elements = partition_html(filename=filename)
for element in html_elements[:10]:
print(f"{element.category.upper()}: {element.text}")
출력 결과:
TITLE: CNN
UNCATEGORIZEDTEXT: 1/30/2024
TITLE: A potent pair of atmospheric rivers will drench California as El Niño makes its first mark on winter
TITLE: By Mary Gilbert, CNN Meteorologist
UNCATEGORIZEDTEXT: Updated:
3:49 PM EST, Tue January 30, 2024
TITLE: Source: CNN
NARRATIVETEXT: A potent pair of atmospheric river-fueled storms are about to unleash a windy and incredibly wet week in California in what is the first clear sign of the influence El Niño was expected to have on the state this winter.
NARRATIVETEXT: The soaking storms will raise the flood threat across much of California into next week, but it appears the wet pattern is likely to continue well into February as a more typical El Niño pattern kicks into gear.
NARRATIVETEXT: El Niño – a natural phenomenon in the tropical Pacific that influences weather around the globe – causes changes in the jet stream that can point storms directly at California. Storms can also tap into an extra-potent supply of moisture from the tropics called an atmospheric river.
NARRATIVETEXT: El Niño hasn’t materialized many atmospheric rivers for California so far this winter, with most hitting the Pacific Northwest.
다음은 같은 데이터이나 PDF 파일 형식인 경우 처리해보자.
- 간단한 PDF 파일이라면 patition_pdf() 라이브러리를 쓰면 되고, 복잡한 레이아웃이거나 OCR 이 필요한 경우라면 API 를 사용해서 해결한다.
filename = "example_files/el_nino.pdf"
pdf_elements = partition_pdf(filename=filename, strategy="fast")
for element in pdf_elements[:10]:
print(f"{element.category.upper()}: {element.text}")
partition_pdf() 결과
UNCATEGORIZEDTEXT: 1/30/24, 5:11 PM
NARRATIVETEXT: Pineapple express: California to get drenched by back-to-back storms fueling a serious flood threat | CNN
UNCATEGORIZEDTEXT: CNN 1/30/2024
NARRATIVETEXT: A potent pair of atmospheric rivers will drench California as El Niño makes its first mark on winter
TITLE: By Mary Gilbert, CNN Meteorologist
TITLE: Updated: 3:49 PM EST, Tue January 30, 2024
TITLE: Source: CNN
NARRATIVETEXT: A potent pair of atmospheric river-fueled storms are about to unleash a windy and incredibly wet week in California in what is the first clear sign of the influence El Niño was expected to have on the state this winter.
NARRATIVETEXT: The soaking storms will raise the flood threat across much of California into next week, but it appears the wet pattern is likely to continue well into February as a more typical El Niño pattern kicks into gear.
NARRATIVETEXT: El Niño – a natural phenomenon in the tropical Pacific that influences weather around the globe – causes changes in the jet stream that can point storms directly at California. Storms can also tap into an extra-potent supply of moisture from the tropics called an atmospheric river.
PDF 파일 텍스트 추출을 위한 Unstructured API 사용
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(
files=files,
strategy="hi_res",
hi_res_model_name="yolox",
)
try:
resp = s.general.partition(req)
dld_elements = dict_to_elements(resp.elements)
except SDKError as e:
print(e)
for element in dld_elements[:10]:
print(f"{element.category.upper()}: {element.text}")
출력 결과:
HEADER: 1/30/24, 5:11 PM
HEADER: CNN 1/30/2024
HEADER: Pineapple express: California to get drenched by back-to-back storms fueling a serious flood threat | CNN
TITLE: A potent pair of atmospheric rivers will drench California as El Niño makes its first mark on winter
NARRATIVETEXT: By Mary Gilbert, CNN Meteorologist
NARRATIVETEXT: Updated: 3:49 PM EST, Tue January 30, 2024
NARRATIVETEXT: Source: CNN
NARRATIVETEXT: A potent pair of atmospheric river-fueled storms are about to unleash a windy and incredibly wet week in California in what is the first clear sign of the influence El Niño was expected to have on the state this winter.
NARRATIVETEXT: The soaking storms will raise the flood threat across much of California into next week, but it appears the wet pattern is likely to continue well into February as a more typical El Niño pattern kicks into gear.
NARRATIVETEXT: El Niño – a natural phenomenon in the tropical Pacific that influences weather around the globe – causes changes in the jet stream that can point storms directly at California. Storms can also tap into an extra-potent supply of moisture from the tropics called an atmospheric river.
HTML 과 비교해보면 똑같지는 않으나 유사함. 그러나 이 정도로 충분할 수 있음.
5. Extracting Tables
HTML 이나 Word 와 같은 문서들은 구조화 되어 있어서 테이블 정보를 쉽게 뽑을 수 있지만 이미지로 되어있는 테이블 같은 경우는 뽑아내기가 어려울거임.
여기서는 Table 에 있는 데이터들을 뽑아오는 방법을 다룸.
방법은 3가지가 있음:
- Table Transformer
- Vision Transformer
- OCR processing
Table Transformer:
- 동작 과정은 다음과 같다:
- 1) Document Layout Detection 으로 Table Cell 에 대한 경계 상자를 그려낸 뒤 테이블을 식별화 함
- 2) 이 정보를 Table Transformer 에게 넘겨주면 Table 에 대한 정보를 HTML 테이블 형식으로 정리해준다.
- 이 방식의 장점은 경계 상자 내에 Table Cell 에 대한 위치 정보를 이용한다는 거임. 이렇게 하면 이 Cell 이 어느 열과 행에 속하는지 알 수 있기 떄문에 데이터를 그룹화해서 정리하기 쉽고, 해당 영역 내에서만 데이터를 뽑아내면 되니까 훨씬 정확하다는 장점이 있음.
- 하지만 Cell 마다의 API Call 을 해야하니 비용이 나갈 수 있다는 단점도 있음.
Vision Transformer:
- 이전에 배운 것과 같다. 다만 출력이 이전에는 JSON 출력이었다면 여기서는 HTML 테이블 형식으로 출력함.
- 장점은 Transformer 에 비해 싸다라는 거고, 단점은 할루시네이션이 발생할 수 있다는거임.
OCR Postprocessing:
- Table 정보를 OCR 로 처리해 내는 걸 말한다.
- 빠르고 가볍고 정확하다는 장점이 있지만 이걸 못하는 구조의 테이블도 있어서 유연하지는 않음.
- OCR 처리 후의 형식은 다음과 같기 때문에 이후 후처리가 필요하다.

이제 Table Transformer 모델을 가지고 테이블 데이터를 추출하는 예시를 보자.
먼저 이전과 같이 필요한 라이브러리를 설치하고, Unstructured Client 를 세팅해야함.
# Warning control
import warnings
warnings.filterwarnings('ignore')
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.staging.base import dict_to_elements
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
)
다음 파일에 있는 테이블 데이터를 가져올거임.
from IPython.display import Image
Image(filename="images/embedded-images-tables.jpg", height=600, width=600) 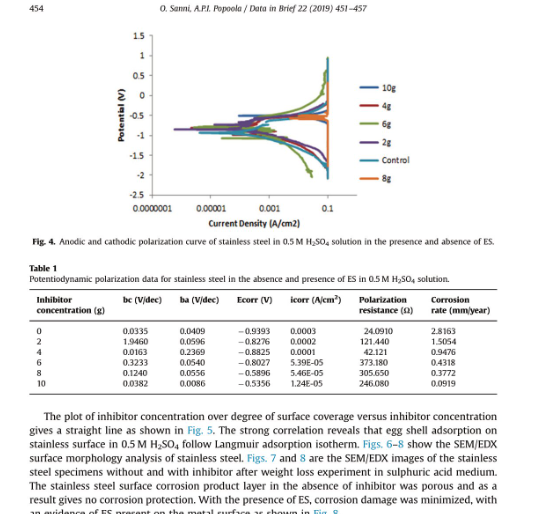
다음은 Table Transformer 를 이용하기 위해 API 를 호출하는 코드임
- Request 객체를 보면 여러 파라미터가 있음. 여기서 pdf_infer_table_structure 이 파라미터는 테이블 정보를 뽑아내라는 뜻이고, skip_infer_table_types 는 스킵할 테이블 타입을 넣으라는 뜻임. 우리의 예시에서는 스킵하지 않을거니까 넣으면 안됨.
filename = "example_files/embedded-images-tables.pdf"
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(
files=files,
strategy="hi_res",
hi_res_model_name="yolox",
skip_infer_table_types=[],
pdf_infer_table_structure=True,
)
try:
resp = s.general.partition(req)
elements = dict_to_elements(resp.elements)
except SDKError as e:
print(e)
tables = [el for el in elements if el.category == "Table"]
tables[0].text
테이블 정보는 다음과 같을 거임:
'Inhibitor Polarization Corrosion be (V/dec) ba (V/dec) Ecorr (V) icorr (AJcm?) concentration (g) resistance (Q) rate (mmj/year) 0.0335 0.0409 —0.9393 0.0003 24.0910 2.8163 1.9460 0.0596 .8276 0.0002 121.440 1.5054 0.0163 0.2369 .8825 0.0001 42121 0.9476 s NO 03233 0.0540 —0.8027 5.39E-05 373.180 0.4318 0.1240 0.0556 .5896 5.46E-05 305.650 0.3772 = 5 0.0382 0.0086 .5356 1.24E-05 246.080 0.0919'
이런 테이블 정보를 가지고 Python 에서 HTML 로 보는 코드는 다음과 같다:
table_html = tables[0].metadata.text_as_html
from io import StringIO
from lxml import etree
parser = etree.XMLParser(remove_blank_text=True)
file_obj = StringIO(table_html)
tree = etree.parse(file_obj, parser)
print(etree.tostring(tree, pretty_print=True).decode())
IPython 에서 HTML Display 를 통해서도 볼 수 있음.
from IPython.core.display import HTML
HTML(table_html)
그래서 테이블 정보는 어떻게 쓰느냐 한다면 이 정보를 가지고 LLM 에게 요약을 하도록 해서 RAG 에서 검색해서 사용할 수 있는거임.
LangChain 의 예시 코드는 다음과 같다:
- load_summarize_chain 을 주고 문서를 주면 알아서 잘 요약해서 결과를 반환해준다.
from langchain_openai import ChatOpenAI
from langchain_core.documents import Document
from langchain.chains.summarize import load_summarize_chain
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
chain = load_summarize_chain(llm, chain_type="stuff")
chain.invoke([Document(page_content=table_html)])
Input Document 에 대해서 Output 결과는 다음과 같다:
{'input_documents': [Document(page_content='<table><thead><th>Inhibitor concentration (g)</th><th>be (V/dec)</th><th>ba (V/dec)</th><th>Ecorr (V)</th><th>icorr (AJcm?)</th><th>Polarization resistance (Q)</th><th>Corrosion rate (mmj/year)</th></thead><tr><td></td><td>0.0335</td><td>0.0409</td><td>—0.9393</td><td>0.0003</td><td>24.0910</td><td>2.8163</td></tr><tr><td>NO</td><td>1.9460</td><td>0.0596</td><td>—0.8276</td><td>0.0002</td><td>121.440</td><td>1.5054</td></tr><tr><td></td><td>0.0163</td><td>0.2369</td><td>—0.8825</td><td>0.0001</td><td>42121</td><td>0.9476</td></tr><tr><td>s</td><td>03233</td><td>0.0540</td><td>—0.8027</td><td>5.39E-05</td><td>373.180</td><td>0.4318</td></tr><tr><td></td><td>0.1240</td><td>0.0556</td><td>—0.5896</td><td>5.46E-05</td><td>305.650</td><td>0.3772</td></tr><tr><td>= 5</td><td>0.0382</td><td>0.0086</td><td>—0.5356</td><td>1.24E-05</td><td>246.080</td><td>0.0919</td></tr></table>')],
'output_text': 'The table provides data on the corrosion rate and polarization resistance for different inhibitor concentrations. The corrosion rate ranges from 2.8163 mm/year to 0.0919 mm/year, with the highest corrosion rate observed at an inhibitor concentration of 0.0335 g and the lowest at a concentration of 5 g. The polarization resistance ranges from 24.0910 Q to 246.080 Q, with the highest resistance observed at an inhibitor concentration of 0.0335 g and the lowest at a concentration of 5 g.'}
6. Build Your Own RAG Bot
여기서는 Data preprocessing 을 실제로 이용해서 PDF, PPT, Markdown 파일을 전처리해서 Vector STore 에 적재한 후 RAG 를 이용한 질문-답변 봇을 만드는 실습을 해본다.
먼저 기본 라이브러리를 다운로드하자.
# Warning control
import warnings
warnings.filterwarnings('ignore')
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.chunking.title import chunk_by_title
from unstructured.partition.md import partition_md
from unstructured.partition.pptx import partition_pptx
from unstructured.staging.base import dict_to_elements
import chromadb
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
)
처리할 문서들에 대해서 하나씩 살펴보자. PDF, PPT, Markdown 순이다.
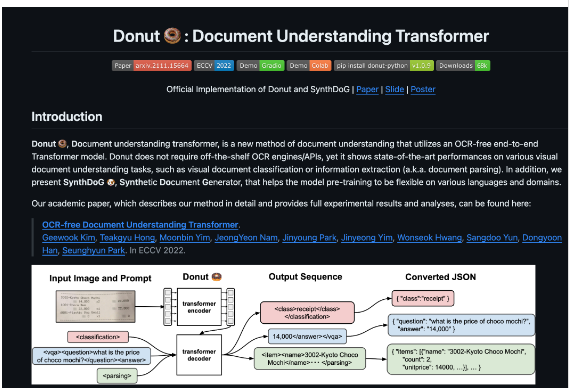
PDF 파일부터 전처리 해보자. 코드는 다음과 같다:
filename = "example_files/donut_paper.pdf"
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(
files=files,
strategy="hi_res",
hi_res_model_name="yolox",
pdf_infer_table_structure=True,
skip_infer_table_types=[],
)
try:
resp = s.general.partition(req)
pdf_elements = dict_to_elements(resp.elements)
except SDKError as e:
print(e)
pdf_elements[0].to_dict()
출력 결과:
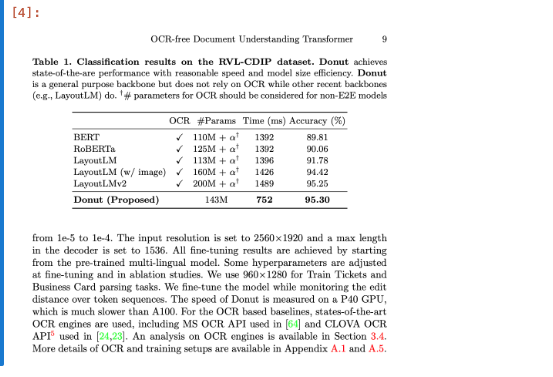
{'type': 'Title',
'element_id': '59a9f0edd370eaa8c5c59cd9256e63bd',
'text': 'OCR-free Document Understanding Transformer',
'metadata': {'filetype': 'application/pdf',
'languages': ['eng'],
'page_number': 1,
'filename': 'donut_paper.pdf'}}
PDF 파일에서 테이블 내용만 추출하는 코드:
tables = [el for el in pdf_elements if el.category == "Table"]
table_html = tables[0].metadata.text_as_html
RAG 에 사용할 데이터로는 다음과 같은 레퍼런스 데이터는 필요가 없음. 그래서 이를 필터링해야한다.

Reference 내용은 필터링하는 코드는 다음과 같음:
reference_title = [
el for el in pdf_elements
if el.text == "References"
and el.category == "Title"
][0]
references_id = reference_title.id
pdf_elements = [el for el in pdf_elements if el.metadata.parent_id != references_id]
다음과 같은 Header 에 대한 내용도 그렇게 필요하지는 않을거임 그래서 이것도 필터링해야한다.

헤더를 필터링하는 코드는 다음과 같음:
pdf_elements = [el for el in pdf_elements if el.category != "Header"]
Powerpoint 와 Markdown 은 라이브러리를 이용해서 간단하게 전처리 할 수 있다:
filename = "example_files/donut_slide.pptx"
pptx_elements = partition_pptx(filename=filename)
filename = "example_files/donut_readme.md"
md_elements = partition_md(filename=filename)
그 다음 이렇게 만든 elements 들을 Chunk 로 만들어서 Vector Store 에 적재하자. Chunking 을 만드는 건 Chunk_by_title 함수를 통해서 (새로운 title 이 등장하게 되면 새로운 Chunk 시작하는 전략) 을 쓴다.
elements = chunk_by_title(pdf_elements + pptx_elements + md_elements)
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
documents = []
for element in elements:
metadata = element.metadata.to_dict()
del metadata["languages"]
metadata["source"] = metadata["filename"]
documents.append(Document(page_content=element.text, metadata=metadata))
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 6}
)
다음은 LagngChain 에서 Prompt 와 Chain 을 만들어서 질문을 하는 코드다.
- 여기서는 ConversationalRetrievalChain 을 최종적인 체인으로 이용했고, 사용자가 한 질문에 대해 좀 더 구체적인 질문을 만들도록 하는 question_generator_chain 을 사용한다, 그리고 해당 질문에 대한 문서를 찾아와서 답변을 만들고 병합하는 load_qa_with_sources_chain 도 이용한다.
from langchain.prompts.prompt import PromptTemplate
from langchain_openai import OpenAI
from langchain.chains import ConversationalRetrievalChain, LLMChain
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
template = """You are an AI assistant for answering questions about the Donut document understanding model.
You are given the following extracted parts of a long document and a question. Provide a conversational answer.
If you don't know the answer, just say "Hmm, I'm not sure." Don't try to make up an answer.
If the question is not about Donut, politely inform them that you are tuned to only answer questions about Donut.
Question: {question}
=========
{context}
=========
Answer in Markdown:"""
prompt = PromptTemplate(template=template, input_variables=["question", "context"])
llm = OpenAI(temperature=0)
doc_chain = load_qa_with_sources_chain(llm, chain_type="map_reduce")
question_generator_chain = LLMChain(llm=llm, prompt=prompt)
qa_chain = ConversationalRetrievalChain(
retriever=retriever,
question_generator=question_generator_chain,
combine_docs_chain=doc_chain,
)
qa_chain.invoke({
"question": "How does Donut compare to other document understanding models?",
"chat_history": []
})["answer"]
그리고 Vector Store 를 만들 때 필터링 검색이 되도록 만들 수도 있다.
filter_retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1, "filter": {"source": "donut_readme.md"}}
)
filter_chain = ConversationalRetrievalChain(
retriever=filter_retriever,
question_generator=question_generator_chain,
combine_docs_chain=doc_chain,
)
filter_chain.invoke({
"question": "How do I classify documents with DONUT?",
"chat_history": [],
"filter": filter,
})["answer"]'Generative AI > Data' 카테고리의 다른 글
| A Survey on Data Synthesis and Augmentation for Large Language Models (0) | 2025.01.18 |
|---|---|
| Does Synthetic Data Generation of LLMs Help Clinical Text Mining? (0) | 2025.01.17 |
| Data-centric Artificial Intelligence: A Survey (0) | 2024.11.05 |
| Data-Centric AI (0) | 2024.11.03 |
| Function-calling and data extraction with LLMs (0) | 2024.08.09 |