This articles is is a summary based on the reference to The GraphRAG Manifesto: Adding Knowledge to GenAI
Current limitations of GenAI:
- Autoregressive Large Language Models (LLMs) alone are not sufficient for many useful applications.
- Techniques like Retrieval-Augmented Generation (RAG) and fine-tuning have limitations.
- These methods increase the probability of correct answers but don't guarantee certainty or provide context.
The Knowledge Graph approach:
- It emphasizes the importance of organizing information as "things, not strings."
- This approach is now being applied to GenAI to overcome current limitations.
The drawback of both RAG and fine-tuning is that they do not always ensure that the LLM has the necessary context?
- The drawback of both RAG (Retrieval-Augmented Generation) and fine-tuning is not just about ensuring necessary context, but more fundamentally about guaranteeing correct answers and providing explanations for those answers
- To summarize, it is as follows:
- Increased probability, not certainty: RAG and fine-tuning "increase the probability of a correct answer for many kinds of questions. However neither technique provides the certainty of a correct answer.
- Lack of context and connection: These techniques often "lack context, color, and a connection to what you know to be true."
- Limited explainability: "These tools don't leave you with many clues about why they made a particular decision."
Why is this approach using a Knowledge Graph more effective than using simple RAG?
- Structured representation of information:`1
- Knowledge Graphs organize information as "things, not strings," which allows for a more meaningful representation of data and their relationships.
- This structure helps in understanding context and connections between different pieces of information.
- Enhanced context and understanding:
- Unlike simple RAG, which might lack context, GraphRAG can provide richer context by leveraging the relationships and properties defined in the knowledge graph.
- Improved answer quality.
Introduction of GraphRAG:
- GraphRAG combines knowledge graphs with traditional RAG techniques.
- It involves calling a knowledge graph in addition to a vector index.
Wait, Graph?
Let’s be clear that when we say graph, we mean something like this:

Two Types of Knowledge Representation: Vectors & Graphs
two types of knowledge representation used in AI systems:
- vectors
- graphs
Vector-based representation:
- Used in typical RAG systems
- Converts text into numerical arrays (vectors)
- Useful for finding conceptually similar text through similarity calculations
- Limitations:
- Difficult to interpret the content of a vector
- Lacks context and relationships between concepts
- Cannot easily represent complex, multidimensional information
Why does a vector-based representation provide less context richness? I think it ensures quite a bit of context richness through similarity calculation
- Similarity vs. Explicit Relationships:
- Vector similarity provides a measure of how close concepts are in a high-dimensional space, which can indicate relatedness.
- However, this similarity doesn't explicitly define the nature of the relationship between concepts.
- Granularity of Information:
- Vectors provide a holistic representation of a concept or piece of text.
- Knowledge graphs can represent individual facts, properties, and relationships at a more granular level.
- Directional Relationships:
- Vector similarity is typically symmetrical (A is as similar to B as B is to A).
- Knowledge graphs can represent asymmetrical or directional relationships (A is a type of B, but B is not a type of A).
Graph-based representation (Knowledge Graphs):
- Declarative or symbolic representation of information
- Represents concepts and their relationships explicitly
- Advantages:
- Understandable by both humans and machines
- Can be queried, visualized, annotated, and modified
- Provides context and relationships between concepts
- Represents a "world model" for a specific domain
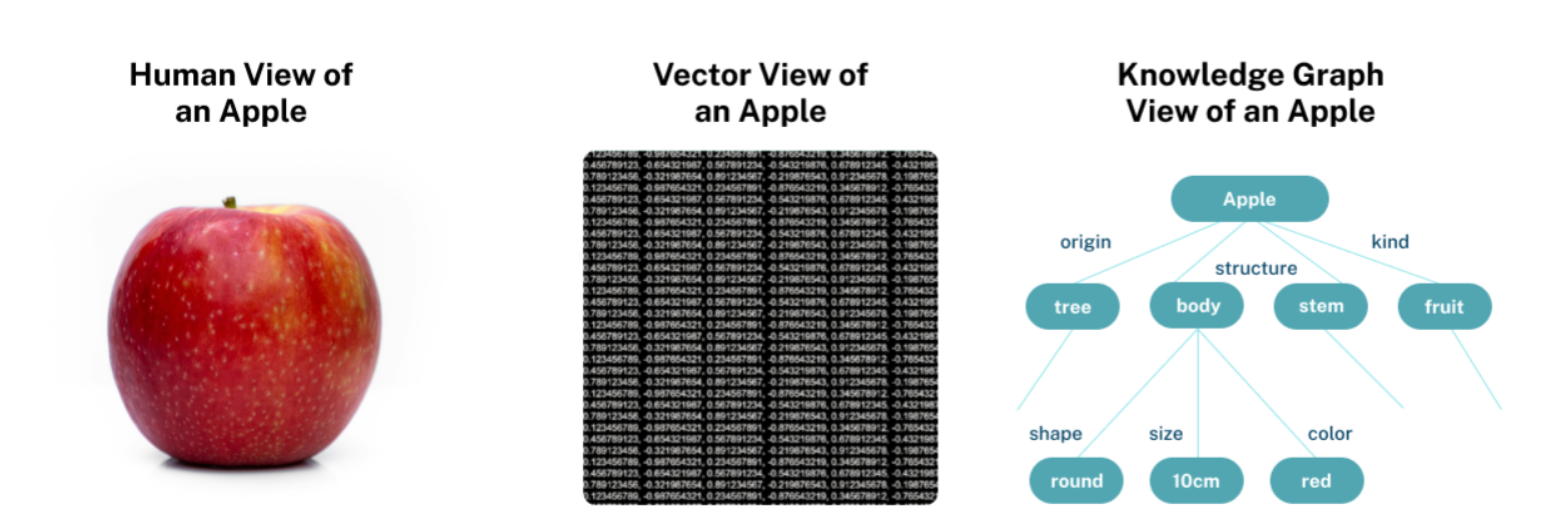
Comparison using an "apple" example:
- Human representation: Complex and multidimensional, difficult to fully capture
- Vector representation: An array of numbers encoding the essence of the concept
- Graph representation: Explicit representation of the apple and its relationships to other concepts
GraphRAG Pattern
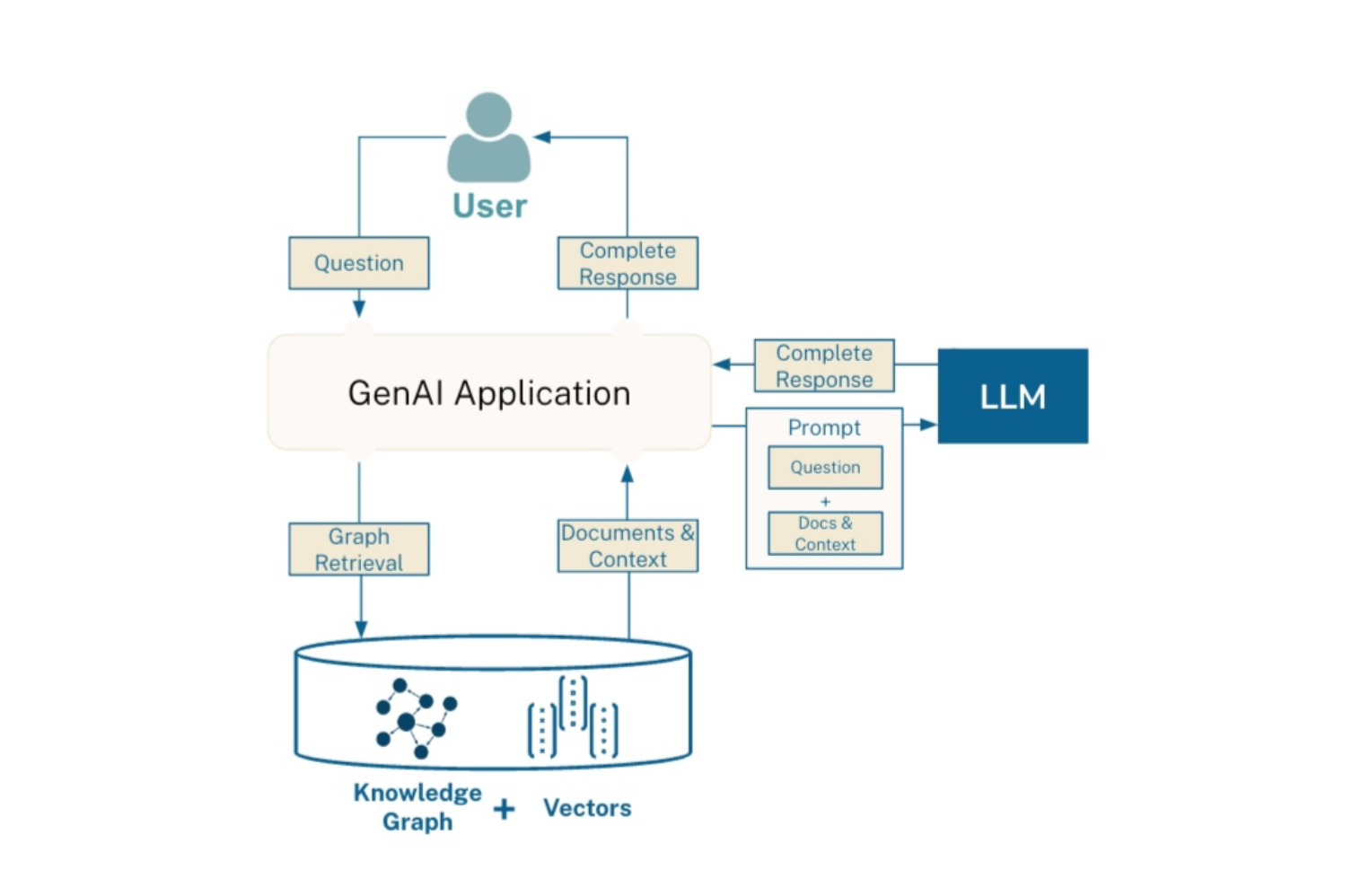
GraphRAG Overview:
- It combines graph-based and vector-based retrieval methods.
- The process involves triggering a graph query, which may include a vector similarity component.
Data Storage Options:
- Graphs and vectors can be stored in two ways:
- a) Separately in distinct databases
- b) Together in a graph database like Neo4j that also supports vector search
Common GraphRAG Pattern: The article outlines a typical process for using GraphRAG, which consists of three main steps
- a) Initial Search:
- Use vector or keyword search to find an initial set of nodes in the graph.
- This step helps to identify relevant starting points in the knowledge graph.
- b) Graph Traversal:
- From the initial nodes, traverse the graph to retrieve information about related nodes.
- This step leverages the explicit relationships in the graph to gather contextually relevant information.
- c) Optional Re-ranking:
- Use a graph-based ranking algorithm like PageRank to re-order the retrieved documents.
- This can help prioritize the most relevant or important information based on the graph structure.
GraphRAG Lifecycle
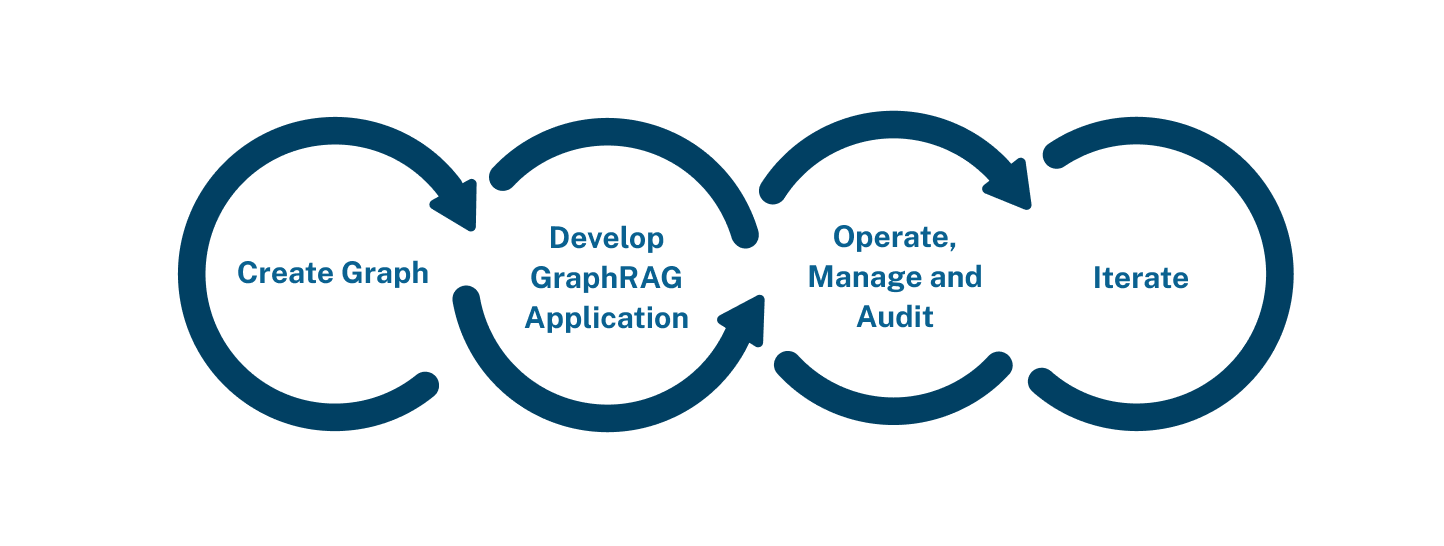
GraphRAG Lifecycle:
- It follows a similar pattern to traditional RAG applications.
- The main difference is an additional "create graph" step at the beginning.
Graph Creation:
- This step is comparable to chunking documents and loading them into a vector database in traditional RAG.
- Recent advances in tooling have made graph creation relatively simple.
- it will dive deeper into graph creation later.
Advantages of Graph-based Approach:
- a) Iterative Development:
- You can start with a "minimum viable graph" and expand it over time.
- b) Easy Evolution:
- Once data is in a knowledge graph, it's easier to add more types of data.
- This allows for "data network effects," where the value of the data increases as more related data is added.
- The quality of data can be improved, enhancing application results.
- c) Rapid Improvement:
- The tooling for graph creation is advancing quickly, making the process increasingly easier.
Why GraphRAG?
these benefits into three main areas:
- Runtime/Production Benefits:
- This suggests that GraphRAG can provide more precise and comprehensive information during actual use of the application.
- Development Time Benefits:
- This indicates that while there might be an initial investment in creating the knowledge graph, it pays off in terms of easier development and maintenance of the application.
1: Higher Accuracy & More Useful Answers
GraphRAG improved accuracy of LLM responses by 3x across 43 business questions.
Microsoft Research: Identified two main problems with baseline RAG
- a) Difficulty in connecting disparate pieces of information
- b) Poor performance in understanding summarized semantic concepts over large data collections or single large doucment.
LinkedIn Case Study:
- people have been finding with GraphRAG is that not only are the answers more accurate, but they are also richer, more complete, and more useful
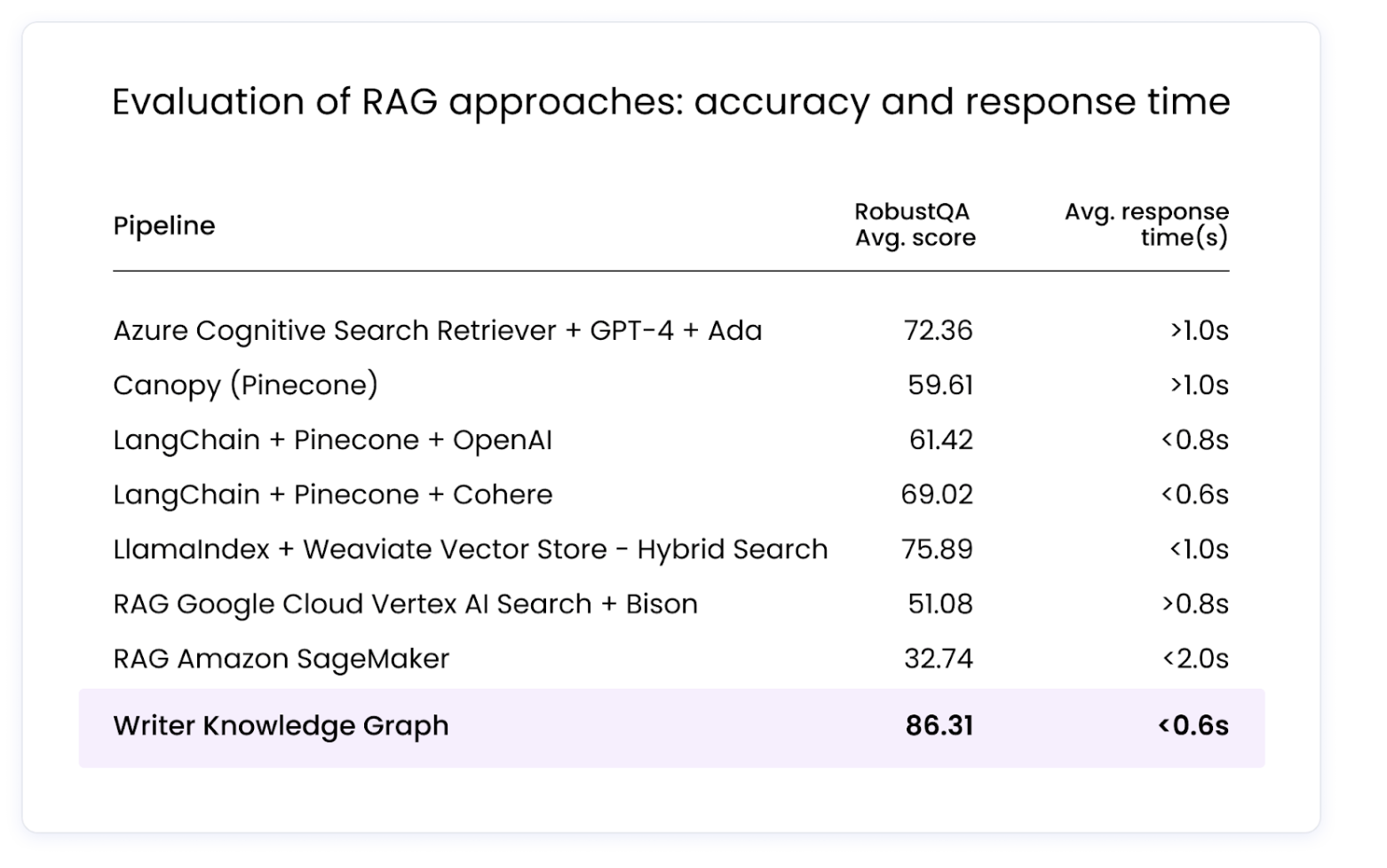
Writer's RAG Benchmarking Report:
- Based on the RobustQA framework
- Compared Writer's GraphRAG-based approach to other competitive tools
- Results:
- GraphRAG scored 86%
- Competitive tools scored between 33% and 76%
- GraphRAG achieved this higher score with equivalent or better latency (response time)
Knowledge Graph Creation

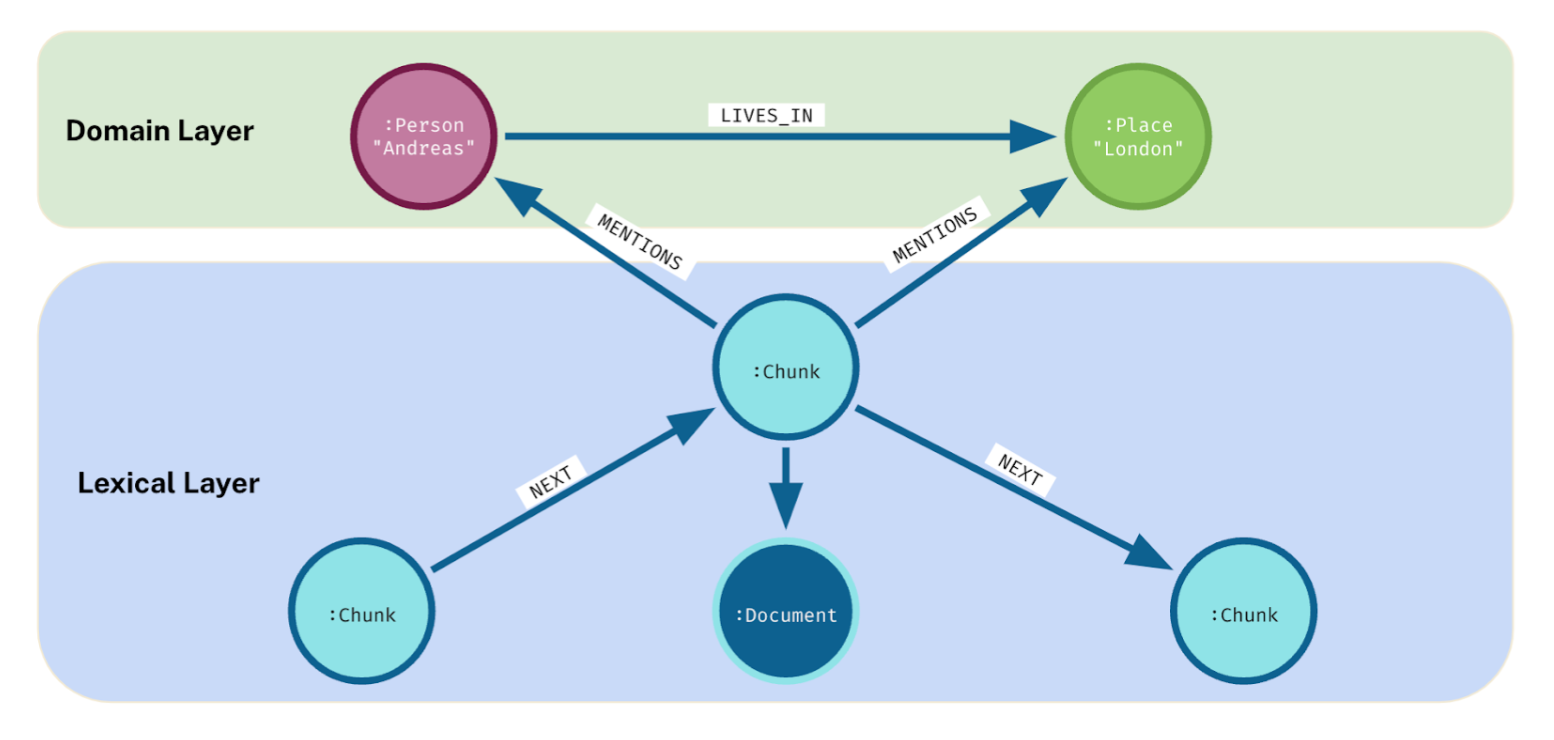
Domain Graph:
- Represents the world model relevant to the application
- Shows relationships between entities in the domain
Lexical Graph:
- Represents document structure
- Basic form has nodes for each chunk of text
- Can be expanded to include relationships between chunks, document objects, chapters, sections, etc.
Combining Graphs:
- Domain and lexical graphs can be combined for a more comprehensive representation
Creating Lexical Graphs:
- Described as relatively easy
- Involves simple parsing and chunking strategies
Creating Domain Graphs:
- Depends on the data source (structured, unstructured, or both)
- Tooling for creating graphs from unstructured data is improving rapidly
Working with Knowledge Graphs
GraphRAG Frameworks:
- There's a growing number of frameworks available for implementing GraphRAG, including:
- LlamaIndex Property Graph Index
- Langchain's Neo4j integration
- Haystack's integration
Graph Construction Tools:
- Neo4j Importer: A tool with a graphical UI for mapping and importing tabular data into a graph.
- Neo4j LLM Knowledge Graph Builder (v1): Mentioned earlier, this tool automates graph creation from various unstructured data sources.
Conclusion: GraphRAG is the Next Natural Step for RAG
Limitations of Current Approaches:
- Word-based computations and language skills in LLMs and vector-based RAG provide good results.
- However, for consistently great results, there's a need to go beyond just strings.
GraphRAG as the Next Step:
- GraphRAG is presented as the natural progression from vector-based RAG.
- It combines word models with world models (knowledge graphs) for improved performance.
My Conlcusion
GraphRAG ideally seems clearly advantageous.
Where would applying GraphRAG be most effective:
- It is considered useful for an LLM to take into account various contextual materials when making inferences
- For example, consider buying and selling stocks. You would need to consider various aspects such as financial statements, competent management, whether it is a bull or bear market, wheather company have innovative technology, and whether the price is low
GraphRAG raises concerns regarding latency, but it should be capable of performing various searches.
It seems advantageous to use it in integration with existing search systems.
'Generative AI > RAG' 카테고리의 다른 글
| Prompt Compression and Query Optimization (0) | 2024.08.10 |
|---|---|
| Choosing the right embedding model for your RAG application (0) | 2024.08.06 |
| What is a Sparse Vector? How to Achieve Vector-based Hybrid Search (0) | 2024.07.10 |
| Hybrid Search (0) | 2024.07.10 |
| Searching for Best Practices in Retrieval-AugmentedGeneration (0) | 2024.07.09 |