SELECT 문장은 데이터를 가지고 올 수 있는 방법이 다양하다. 그리고 그 방법마다 성능의 차이가 나는 경우가 꽤 있으므로 어떻게 동작하는지 파악하는게 중요하다.
1. SELECT 절의 처리 순서
일반적인 SELECT 문장은 다음 요소들을 모두 포함하고 있다.
- SELECT, FROM, WHERE, JOIN, GROUP BY, HAVING, ORDER BY, LIMIT

SELECT 절이 처리되는 과정은 FROM 절에 서브쿼리인 인라인 뷰가 사용되지 않는다면 크게 두 가지이다.
- 첫 번째 처리 방법 순서:
- (1) WHERE + JOIN
- (2) GROUP BY
- (3) DISTINCT
- (4) HAVING
- (5) ORDER BY
- (6) LIMIT
- 두 번째 처리 방법 순서:
- 조인을 할 때 드라이빙 테이블을 먼저 정렬할 수 있는 경우 (조인 후 정렬은 데이터 사이즈가 크니까 더 비효율적일 수 있음) + GROUP BY 절이 없는 경우
- (1) WHERE
- (2) ORDER BY
- (3) JOIN
- (4) LIMIT
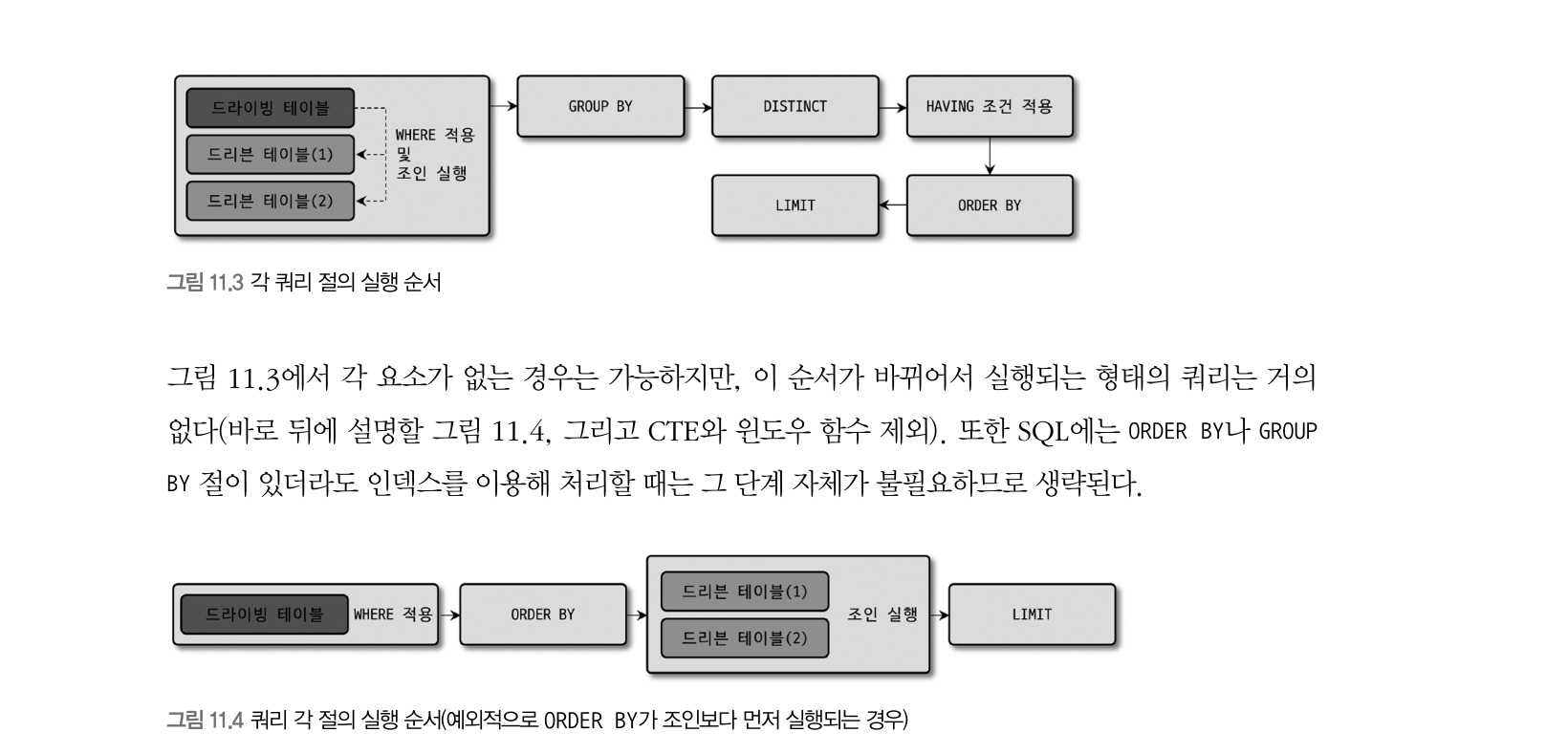
이 실행 순서를 벗어나려면 FROM 절에 서브쿼리를 사용한 인라인 뷰를 이용해야한다.
다음 예제는 FROM 절의 인라인 뷰로 ORDER BY 가 가장 마지막에 실행된다.
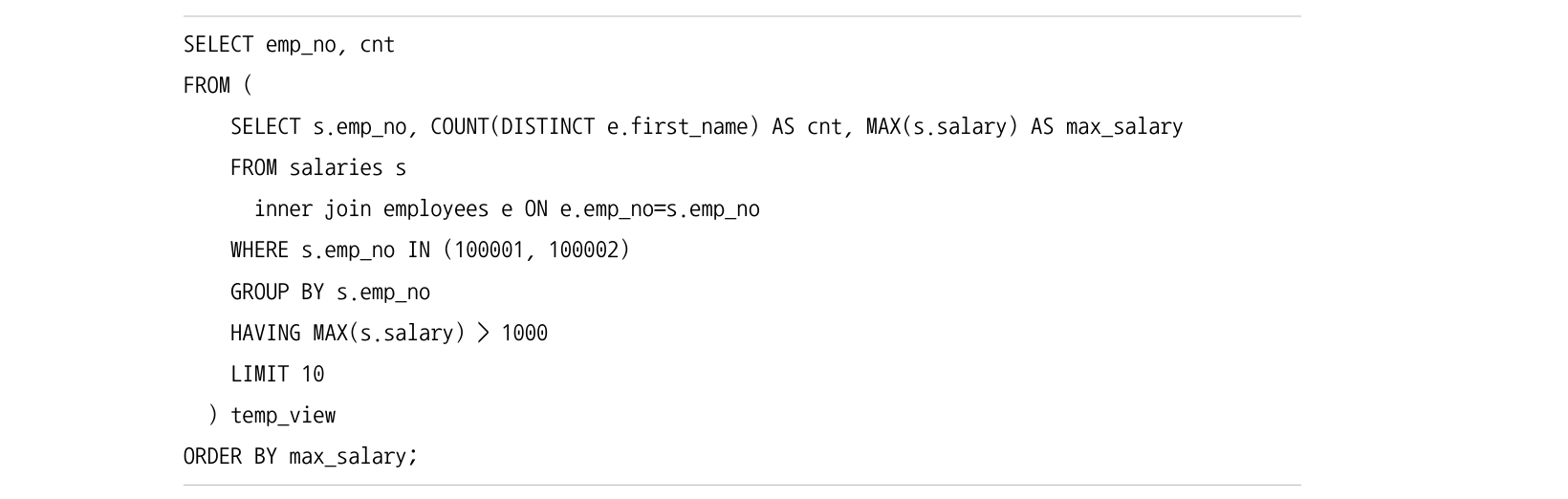
MySQL 8.0 에서는 WITH 절이라는 것도 도입되었는데 이게 사용되면 가장 먼저 사용될 것이다.
WITH 절은 단독 테이블을 읽거나, 조인되는 테이블을 읽을 때 미리 임시 테이블에 기록하기 위해서 사용된다.
2. WHERE 절과 ORDER BY 절, GROUP BY 절에서의 인덱스 사용
2.1 인덱스를 사용하기 위한 기본 규칙
인덱스는 크게 WHERE 절, ORDER BY 절 그리고 GROUP BY 절에서 사용할 수 있다. (DISTINCT 절에서도 사용할 수 있다.)
여기서는 이 절들에 인덱스를 사용하지 못하는 경우에 대해서 소개한다.
인덱스는 다음과 같은 조건일 때 사용할 수 없다:
- 인덱스 칼럼과 비교되는 칼럼을 가공 또는 변환이 필요할 때
- 위의 설명과 동일한데, 인덱스 칼럼과 비교되는 칼럼의 타입이 다를 때
예를 들면 다음과 같은 쿼리는 salary 칼럼을 가공해야해서 인덱스를 사용할 수 없다.
SELECT * FROM salaries WHERE salary * 10 > 150000
인덱스 칼럼을 가공해서 인덱스에서 사용하는 경우 인덱스 풀스캔으로 처리될 수 있다.
그럴 수 밖에 없는 이유가 인덱스와 값을 비교해서 가지고 오는 것은 스토로지 엔진이 담당하는데 가공하는 로직은 MySQL 엔지에서 가지고 있을 것이다.
그래서 스토로지 엔진은 자신이 필터링하지 못하고 MySQL 엔진에게 데이터를 모두 전달할 수 밖에 없다.
그럼 만약 인덱스의 칼럼과 비교되는 대상이 해시 함수와 (= MD5()) 와 같이 변환 함수를 적용할 수 밖에 없다면 어떻게 해야할까?
MySQL 5.7 부터는 가상 칼럼 (Virtual Column) 과 저장 칼럼 (Stored Column) 을 이용할 수 있는데 이들을 이용하는 것도 방법이다.
- MySQL 8.0 에서는 함수 기반 인덱스를 사용할 수 있는데 이는 테이블 구조에 새로운 가상 칼럼을 추가하는 형태가 아님. 함수식을 바탕으로 인덱스를 만드는 것. 대신에 인덱스를 이용해서 검색할 때 인덱스 생성과 똑같은 함수식을 사용해야만한다. 아니면 인덱스가 사용되지 않을 것.
매커니즘은 인덱스 칼럼 값에 변환을 적용한 것을 새로운 칼럼으로 만들고 인덱스를 추가하는 것이다. 동적이든, 정적이든.
- 가상 칼럼 (Virtual Column):
- 물리적으로 저장되지 않는 칼럼이다. 레코드를 읽기 전에 동적으로 만든다.
- 저장 칼럼 (Stored Column):
- 물리적으로 저장되는 칼럼 + 기존 칼럼을 변환해서 새로 저장하는 것이다.
저장 칼럼/가상 칼럼을 사용하는 예시는 다음과 같다:
ALTER TABLE your_table
-- 저장 칼럼 생성
ADD COLUMN hash_value VARBINARY(32) AS (MD5(your_column)) STORED,
-- 가상 칼럼 생성
ADD COLUMN hash_value VARBINARY(32) AS (MD5(your_column)) VIRTUAL;
ADD INDEX idx_hash (hash_value);-- 인덱스를 사용하지 않는 쿼리
SELECT * FROM your_table WHERE MD5(your_column) = 'some_hash_value';
-- 인덱스를 사용하는 쿼리
SELECT * FROM your_table WHERE hash_value = 'some_hash_value';
2.2 WHERE 절의 인덱스 사용
WHERE 절에서 인덱스를 사용할 경우에는 인덱스를 생성할 때 명시한 칼럼들의 순서대로 인덱스에 정렬되어 있다는 사실을 알고 쿼리를 설계해야안다.
이를 알고 있어야 내 쿼리에서 인덱스에서 조금만 탐색하면 되는지, 아니면 많은 범위를 탐색해야 하는지 예측할 수 있기 때문이다.
상황을 가정해보자. 인덱스가 복합 칼럼으로 구성되어 있을 때 인덱스를 생성할 때 명시한 칼럼의 순서대로 정렬되어 있다.
선행 칼럼이 카디널리티가 높은 값 (= 칼럼에 유니크한 데이터 분포가 많은 경우) 으로 유지되어 있고 이를 동등 검색 ('=') 을 사용할수 있다면 인덱스에서 검색할 량이 압도적으로 줄어들면서 검색이 될 것이다.
그런데 선행 칼럼이 비교 조건으로 검색을 주로 한다면 많은 범위의 레인지 스캔이 발생할 수 있다.
더 최악은 선행 칼럼이 조건절에 없는 경우인데 이는 인덱스 풀스캔을 유발할 수 있다. 그래서 이것보다는 더 낫다고 생각해 실행 계획은 테이블 풀스캔으로 처리할 수 있다.
즉 인덱스를 생성할 때 명시한 선행 칼럼을 사용해서 탐색할 범위를 줄여주지 않는다면 효과적인 레인지 스캔을 할 수 없다.
다음 예시처럼 WHERE 절과 OR 을 같이 쓰는 경우에도 인덱스를 사용하지 못할 수 있다:
- OR 절은 독립적인 쿼리들이 생성된다.
- 아래의 예시에서 인덱스는 (last_name, first_name) 으로 구성되어 있다.
- OR 절을 바탕으로 first_name 으로 검색하는 쿼리와 last_name 으로 검색하는 쿼리 두 가지가 있다고 생각하면 된다.
- last_name 기반의 쿼리는 인덱스 선행 칼럼이 있으므로 인덱스 레인지 스캔을 할 수 있다.
- 그러나 first_name 기반의 쿼리는 인덱스의 선행 칼럼이 없는 것이니까 인덱스 풀스캔을 요구하게 된다. 이것보다는 테이플 풀스캔이 여기서는 더 나은 선택이라서 테이블 풀스캔으로 진행이 될 것이다.
- 물론 항상 테이블 풀스캔이 발생하는 건 아니다. first_name 으로만 구성된 인덱스가 있다면 index merge 를 고려해볼 수 있다.
- 그리고 여기서는 적용되지 않을 예시겠지만 선행 칼럼이 카디널리티가 낮은 값이라면 index skip scan 도 선택이 되볼만하다.
SELECT * FROM employees
WHERE first_name='kart' OR last_name='poly;
추가로 MySQL 8.0 부터는 인덱스를 생성할 때 정렬 방향 또한 오름차순/내림차순을 선택할 수 있다:
ALTER TABLE ... ADD INDEX ix_col1234 (col_1 ASC, col_2 DESC, col_3 ASC, col_4 DESC);
2.3 GROUP BY 절의 인덱스 사용
GROUP BY 절에 명시된 칼럼이 인덱스를 구성하는 칼럼의 순서와 맞다면 인덱스를 사용해서 GROUP BY 절을 처리할 수 있다.
다음 예시는 GROUP BY 에 인덱스를 사용하지 못하는 예시다.
- 인덱스가 (col_1, col_2, col_3, col_4) 로 구성되어 있다.
- 인덱스에 명시된 순서와 GROUP BY 에 명시된 순서가 달라서 그렇다.

정리하자면 인덱스를 사용하지 못하는 경우는 인덱스 생성에 명시한 순서와 다른 경우 와 인덱스를 구성하는 칼럼을 중간에 뺀 경우 가 있겠다.
- 인덱스 생성에 명시한 순서의 후행 칼럼은 빼먹어도 된다. 다만 중간 요소를 뺴먹으면 안되긴한다
반대로 다음 예시는 GROUP BY 에 인덱스를 사용할 수 있는 예시다:

그리고 WHERE 절과 GROUP BY 절을 같이 사용하고 있는 경우에 GROUP BY 절에 사용하고 있는 인덱스의 선행 칼럼을 WHERE 절에서 동등 조건으로 처리하고 있다면 이는 GROUP BY 절에서 생략해도 된다.
예시는 다음과 같다:

그러나 WHERE 절에 있는 인덱스 선행 칼럼이 만약 비교 조건으로 검색되고 있다면 GROUP BY 절에서 이를 생략하면 안된다.
2.4 ORDER BY 절의 인덱스 사용
GROUP BY 절에서 인덱스를 사용할 수 있는 조건과 차이점은 거의 없다. 유일한 차이점은 정렬은 정렬 방향 (= 오름차순, 내림차순) 이 있다는 것이다.
인덱스를 구성하는 복합 칼럼의 정렬 방향이 다 오름차순인데, 중간의 녀석만 내림차순으로 정렬을 할 경우에는 인덱스를 사용할 수 없다.
2.5 WHERE 절과 ORDER BY (또는 GROUP BY) 절의 사용
같이 쿼리에 사용될 때 케이스는 다음과 같다:
- WHERE 절과 ORDER BY 절이 같은 인덱스를 사용할 수 있는 경우:
- 좋은 조합이다. 검색도 제일 빠를 것이다.
- WHERE 절에는 인덱스를 사용할 수 있으나 ORDER BY 절에는 인덱스를 사용 못하는 경우:
- 인덱스 검색 후 Sort Buffer 를 이용해 정렬을 처리한 후 나갈 것이다. 정렬 데이터의 크기가 작다면 문제 없다.
- WHERE 절에는 인덱스를 사용할 수 없으나 ORDER BY 절에는 인덱스를 사용할 수 있는 경우:
- ORDER BY 절의 인덱스 풀스캔을 하면서 WHERE 절의 필터링을 할 것이다.
- 대량의 데이터를 정렬해서 내보내는 경우라면 꽤 괜찮은 쿼리일 수 있다.
- WHERE 절의 인덱스와 ORDER BY 절의 인덱스가 서로 다른 경우에는?
- WHERE 절의 인덱스만 사용되거나 정렬 데이터가 많아서 정렬이 더 중요한 작업 같다면 ORDER BY 절의 인덱스를 사용할 것이다.
또 다음과 같이 WHERE 절과 ORDER BY 절을 같이 사용하는데 인덱스의 칼럼을 일부 까먹으면 같이 사용되지 못할 수 있다:

2.6 GROUP BY 절과 ORDER BY 절의 사용
GROUP BY 절과 ORDER BY 절에서 모두 같은 인덱스를 이용해야지 인덱스가 적용된다.
둘 중 하나의 절만 인덱스를 이용할 수 있다면 인덱스를 이용하지 못한다고 한다.
이에 대해 이해가 안가서 레퍼런스를 통해 찾아보려고 하는데 잘 나오지 않는다. (이후에 직접 쿼리를 짜서 확인을 해봐야 할듯)
ORDER BY 에서 인덱스를 이용하지 못해도 GROUP BY 에서는 인덱스를 이용할 수 있는 것 아닌가?
- 예시로 인덱스를 검색하면서 집계를 하고 집계 함수를 통해서 출력하는 칼럼을 ORDER BY 로 하면 인덱스를 이용할 수 있는 것 아닌가?
2.7 WHERE 절과 ORDER BY 절 그리고 GROUP BY 절의 인덱스 사용
다음 흐름도에 정리가 되어있다:
- WHERE 절에서 인덱스를 사용할 수 있는 경우 GROUP BY 나 ORDER BY 에서 인덱스를 모두 써야 같이 인덱스가 써진다.
- GROUP BY 와 ORDER BY 가 같이 인덱스를 사용할 수 있는지 여부는 세트로 묶여서 판단된다. (하나라도 못쓰이면 인덱스가 안써짐)

3. WHERE 절의 비교 조건 사용시 주의사항
3.1 NULL 값과 비교할 때
MySQL 은 다른 DBMS 와 다르게 NULL 값을 인덱스에 저장할 수 있고, 인덱스에서 비교하면서 검색할 수 있다.
(다른 DBMS 에는 NULL 값을 알 수 없는 값으로 인식해서 비교할 수 없다고 판단하기도 한다는 듯.)
인덱스에서 NULL 값과 비교할 때 사용할 수 있는 방법은 두 가지이다:
- IS NULL 연산자 이용하기
- ISNULL() 함수 이용하기
함수를 이용하는 구문은 가공을해서 비교하는 거니까 조심해야한다. 인덱스를 풀스캔 방식으로 처리될 수도 있다. 그래서 IS NULL 연산자를 이용하는게 좋아보인다.
다음 예시에서 첫 번째와 두 번째는 to_date 칼럼의 인덱스를 레인지 스캔으로 잘 사용되지만 세 번째와 네 번째 SQL 문은 인덱스 풀스캔이 사용된다.
SELECT * FROM titles WHERE to_date IS NULL;
SELECT * FROM titles WHERE ISNULL(to_date);
SELECT * FROM titles WHERE ISNULL(to_date)=1;
SELECT * FROM titles WHERE ISNULL(to_date)=0;
3.2 문자열 칼럼과 숫자 칼럼을 비교할 때
각 칼럼과 비교 대상의 타입을 일치시켜주면 된다.
3.3 날짜 비교
MySQL 에는 날짜와 관련된 타입이 많다. 다음은 그 예시다:
- DATE (오로지 날짜만 알려주는 타입)
- DATETIME (날짜 + 시간을 알려주는 타입
- TIMESTAMP (DATETIME 을 타임스탬프 값으로 알려주는 타입)
- TIME (오로지 시간만 알려주는 타입
3.3.1 DATE 또는 DATETIME 과 문자열 비교:
문자열은 기본적으로 자동으로 DATE 또는 DATETIME 으로 변환되서 비교되어진다. 그래서 Date 칼럼의 인덱스 사용에 크게 문제 없다.
문자열이 날짜 포맷과 달라서 명시적으로 변환을 해야한다면 STR_TO_DATE() 를 사용하자.
그런데 DATETIME 이나 DATE 타입의 칼럼을 DATE_FORMAT 으로 문자열로 변환해서 비교하는 경우에는 인덱스를 사용하지 못할 수 있다. (칼럼의 값은 가공하거나 변환하면 인덱스에 쓰이지 못한다.)
다음 예시들은 DATE 칼럼에서 인덱스를 사용하지 못하는 예시이다.

3.3.2 DATE 와 DATETIME 을 비교:
DATE 는 자동으로 DATETIME 으로 변환되어서 비교된다는 사실을 알아야한다.
즉 "2023-11-09" 의 DATE 타입은 DATETIME 과 비교될 때 "2023-11-09 00:00:00" 으로 변환되어진다.
3.3.3 DATETIME 과 TIMESTAMP 를 비교:
타입을 맞춰줘서 비교를 해야한다.
DATETIME 칼럼의 값과 비교한다면 TIMESTAMP 값을 FROM_UNIXTIME() 으로 DATETIME 으로 변환시켜주어야 하며, TIMESTAMP 칼럼의 값과 비교한다면 DATETIME 의 값을 UNIX_TIMESTAMP() 함수를 이용해서 타임스탬프로 변환시켜서 비교해야한다.
3.3.4 Short-Circuit Evaluation
Short-Circuit Evaluation 을 이용해서 쿼리의 성능을 높일 수 있다.
Short-Circuit Evaluation 은 대부분의 프로그래밍 언어에서 지원하는 기능인데, 다음 예시처럼 if 조건절이 두 개로 구성되어 있다면 두 번째 조건은 첫 번째 조건이 통과되어야만 실행된다.
즉 첫 번째 조건을 통과하기 엄격한 조건으로 둔다면, 두 번째 조건이 실행되는 것을 막아서 성능적인 이점을 누릴 수 있다.
Short-Circuit Evaluation 으로 성능 향상을 일으키는 예제는 다음과 같다:
- WHERE CONVERT_TZ ... 와 관련된 조건으로만 검색 했을 때 24만건 정도의 데이터가 나온다. 그러나 WHERE to_date < '1985-01-01 로만 검색했을 땐 데이터가 없다.
- 즉 조건 절에 WHERE to_date < '1985-01-01 을 먼저 명시할 경우에 불필요한 WHERE CONVERT_TZ ... 조건 검사를 수행하지 않아도 된다.


Short-Circuit Evaluation 에 대해서 알고 있어야 하는 사실로는 인덱스를 사용할 때이다.
WHERE 조건절에서 인덱스를 사용할 수 있는 경우에는 그게 조건절에 앞에 있던, 뒤에 있던 신경 쓰지 않는다. 그냥 인덱스를 사용해서 검색한다.
그렇지만 WHERE 절에 인덱스를 사용하는 조건절과 인덱스를 사용할 수 없는 조건절이 여러개가 있다면 Short-Circuit Evaluation 을 고려해야만 한다.
다음 예시는 WHERE 절에서 인덱스가 있을 때 Short-Circuit Evaluation 를 적용해서 성능 향상을 이루는 예시다.
- 인덱스는 first_name 칼럼으로 이용된다.
- e.last_name='Aamodt' 조건을 서브쿼리보다 앞에 두도록해서 불필요한 서브쿼리를 줄여서 성능 향상을 이룬다.
- SHOW STATUS LIKE Handler% 명령을 내렸을 때 출력하는 값에 대한 설명은 다음과 같다:
- Handler_read_first:
- 인덱스의 첫 번째 항목을 읽는 작업의 수를 나타냅니다. 이 값이 높으면 많은 풀스캔이 발생하고 있다는 신호이다.
- Handler_read_key:
- 인덱스를 사용하여 행을 읽는 요청의 수를 나타냅니다. 일반적으로 이 값이 높은 것은 인덱스가 효과적으로 사용되고 있음을 의미한다.
- Handler_read_next:
- 키 순서로 다음 행을 읽는 요청의 수를 나타낸다. 인덱스 스캔 중에 이 수치가 증가한다.
- Handler_read_rnd_next:
- 데이터 파일에서 다음 행을 읽는 작업의 수를 나타낸다. 순차적 스캔을 할 때 증가한다.
- Handler_write:
- 쓰기 처리를 한 작업의 수를 말한다.
- SELECT 절을 처리하는 중에도 증가할 수 있다. 임시 테이블을 기록하거나, 서브쿼리를 사용하는 경우 결과를 캐싱하기 위해서, 또는 내부 최적화 매커니즘 때문에도 발생할 수 있다고 한다.



- Handler_read_first:
4. LIMIT N
LIMIT 절은 쿼리의 결과 집합 중 상위 일부만 가지고 올 수 있도록 하는 방법이다.
LIMIT 절을 이용할 경우 쿼리의 모든 실행을 기다리지 않고 반환해야 할 데이터의 개수만 충족할 수 있으면 더 이상의 쿼리는 실행하지 않아도 되기 때문에 성능적으로 도움이 된다.
다음 예시는 LIMIT 절만 있을 때, GROUP BY, DISTINCT, ORDER BY 그리고 약간의 복잡한 쿼리에서 LIMIT 절이 어떻게 동작하는지를 보여주는 예시다:
- 첫 번째 예시는 풀테이블 스캔을 하다가 10건의 집합을 찾으면 쿼리 실행을 멈춘다.
- 두 번째 예시는 first_name 칼럼에 인덱스를 이용할 수 있느냐, 없느냐에 따라 다르다.
- 인덱스를 이용할 수 있으면 인덱스를 읽으면서 집계가 10건이 되는 순간에 멈춘다.
- 인덱스를 이용할 수 없다면 풀테이블 스캔을 하면서 집계가 모두 끝나야 LIMIT 절을 적용할 수 있을 것이다.
- 세 번째 예시도 인덱스를 사용할 수 있느냐에 따라 다르다.
- 인덱스를 이용해서 읽다가 10건의 결과 집합을 만드는 순간 멈출 수 있다.
- 인덱스를 이용할 수 없더라도 유니크한 칼럼만 가져오면 되니까 풀테이블 스캔을 하면서 10건이 충족되면 멈추면 된다.
- 네 번째 예시는 WHERE 절과 ORDER BY 절에 사용되는 칼럼이 다르다. 즉 하나의 칼럼에서만 인덱스가 이용될 수 있을 것이다.
- 이 경우에는 WHERE 절에서 인덱스갓 사용되서 검색을 한 후 필터링 된 결과 집합을 ORDER BY 에 따라서 정렬을 수행할 것이다. 아마도 대부분의 정렬이 끝난 후에야 10건의 결과 집합을 만들 수 있을 것이다.
- WHERE 절과 ORDER BY 절에서 같은 인덱스 칼럼을 이용할 수 있다면 결과는 더 빠르게 반환될 수 있을 것이다.

LIMIT 절을 사용할 때 주의해야 할 건 데이터를 읽은 후에 대부분의 데이터는 버리도록 쿼리가 작성될 수 있다는 것이다:
예를 들어서 LIMIT 200000, 10 이렇게 쿼리를 작성하면 20만건의 데이터는 버리고 그 이후의 10건만 결과로 가져오겠다는 뜻이다.
주로 웹페이지의 쿼리를 작성할 때 이렇게 되는 경우가 많다.
LIMIT 에서 데이터를 버리도록 설정하지 말고 WHERE 절에서 불필요한 데이터를 안읽도록 조건을 계속 엄격하게 수정되도록 하는 것이 낫다.
예시는 다음과 같다:
- salary 칼럼과 emp_no 범위를 계속해서 변경하면서 읽어야 하는 데이터의 수를 줄이는 것이다.

5. COUNT()
MyISAM 스토로지 엔진에서는 레코드 개수를 메타 정보로 가지고 있어서 COUNT 절이 굉장히 빨랐지만, InnoDB 에서는 이를 별도로 가지고 있지 않아서 레코드를 읽으면서 세어봐야한다.
그래서 가능하면 COUNT 절로 전체 레코드를 읽는 쿼리는 작성하지 않는게 좋다.
(아무리 인덱스만 읽어서 반환하는 커버링 인덱스를 사용해도 부담이다.)
주로 COUNT 절은 웹페이지의 전체 게시물 수를 보여주기 위해서 사용되는 경우가 많은데 그냥 페이지에서 "이전" 버튼과 "다음" 버튼만 두는 것을 권장한다고 함.
그리고 COUNT(*) 절로 단순하게 레코드의 수만 판단하는 경우에 LEFT JOIN 이나 ORDER BY 절은 필요 없는 경우가 많으니까 지우자.
추가로 COUNT(col) 절에 칼럼의 값을 넣게 되면 NULL 인 칼럼의 개수는 무시한다. 이를 알고 사용하자.
6. JOIN
JOIN 을 하는 드라이빙 테이블과 드리븐 테이블 중 인덱스를 하나의 테이블만 사용할 수 있을 때, 왜 드리븐 테이블에서 인덱스를 사용하는게 효과적일까?
비용으로 비교하면 쉬울 것이다.
- 드라이빙 테이블에 인덱스를 사용하는 경우:
- 드라이빙 테이블의 인덱스 스캔 + 드라이빙 테이블 레코드 수만큼의 조인 (= 드라이빙 테이블 레코드 수 만큼의 드리븐 테이블의 풀스캔)
- 드리븐 테이블에 인덱스를 사용하는 경우:
- 드라이빙 테이블의 풀스캔 + 드라이빙 테이클의 레코드 수 만큼의 조인 (= 드리븐 테이블의 인덱스 스캔)
드리븐 테이블에 인덱스가 있는게 더 비용적으로 싸다. 아무래도 드라이빙 테이블의 레코드 수만큼의 드리븐 테이블의 풀스캔이 너무 비싼 비용이다보니.
그리고 레코드 수가 적은 쪽이 드라이빙 테이블로 선택되는 이유도 이러한 비용적인 측면이 있다:
결국 드라이빙 테이블의 레코드 수만큼 드리븐 테이블에서의 탐색이 되는거라서 드리븐 테이블 탐색을 최적화 하는게 중요하다.
- 드리븐 테이블은 매번 인덱스 수직적 스캔 + 인덱스 레인지 스캔을 드라이빙 테이블의 레코드마다 반복하게 된다.
- 레코드 수가 적은 쪽을 드라이빙 테이블로 설계한다면 드리븐 테이블로의 조인 수가 더 적을 것이다. 즉 드리븐 테이블의 인덱스 수직적 스캔의 비용은 더 적어질 것이다.
- 대신 드리븐 테이블의 인덱스 레인지 스캔이 더 많이 발생할 수 있다. (드리븐 테이블은 레코드 수가 많은 쪽으로 선택이 되는거니까)
- 그러나 인덱스 수직적 스캔이 비용이 더 크다고 생각한다. 이는 메모리에 없을 수 있으니까.
6.1 JOIN 칼럼의 데이터 타입
JOIN 을 하는 두 타입이 다를 경우에 인덱스를 사용하지 못할 수도 있다. 그래서 타입을 맞춰야한다.
하지만 다음처럼 두 타입이 달라도 자동으로 변환을 해줘서 인덱스 이용에 무리가 없기도 한다:
- CHAR 타입과 VARCHAR 타입의 비교는 괜찮다.
- INT 타입과 BIGINT 타입의 비교는 괜찮다.
- DATE 타입과 DATETIME 타입의 비교는 괜찮다.
6.2 OUTER JOIN 의 성능과 주의사항
INNER JOIN 을 할 수 있는 경우인데도 OUTER JOIN 을 하는 것은 성능적으로 안좋을 수 있다.
그 이유는 OUTER JOIN 의 경우에는 LEFT JOIN 으로 가리키는 테이블의 경우에는 드라이빙 테이블이 될 수 없기 때문이다.
드라이빙 테이블은 레코드 수가 적을수록 조인에 유리하다.
그러므로 실행 계획이 올바른 드라이빙 테이블을 정할 수 있게 함부로 LEFT JOIN 을 남발하지 말자.
그리고 OUTER JOIN 을 잘못쓰면 INNER JOIN 으로 변경되기도 한다.
다음과 같이 OUTER JOIN 을 사용하고 있는데 WHERE 절에 조인을 사용하는 테이블의 조건을 쓰면 자동으로 INNER 조인으로 변경된다.
SELECT *
FROM employeees e
LEFT JOIN dept_manager mgr ON mgr.emp_no=e.emp_no
WHERE mgr.dept_no='d001';
하지만 OUTER JOIN 을 사용하고 있을 때 WHERE 절에 조인을 사용하는 테이블의 조건을 써도 되는 경우가 있다.
이는 안티 조인 (ANTI JOIN) 을 작성하는 쿼리에서 OUTER JOIN 을 사용할 때 그렇다.
SELECT *
FROM employeees e
LEFT JOIN dept_manager mgr ON mgr.emp_no=e.emp_no
WHERE mgr IS NULL
6.3 JOIN 과 외래키
외래키를 사용하는 칼럼만 조인을 사용할 수 있는 건 아니다.
외래키를 사용하는 이유는 무결성 때문이다.
외래키를 사용하고 있는 칼럼은 반드시 해당 테이블에 존재하고 있어야한다.
6.4 지연된 조인 (Delayed Join)
지연된 조인 기법은 조인을 하고 나서 커진 데이터로 GROPU BY 절과 ORDER BY 절을 처리하지 말고 조인 순서를 변경해서 드라이빙 테이블에서 GROUP BY 절과 ORDER BY 절을 먼저 처리하는 기법이다. 이 방법은 LIMIT 절이 있을 때 더욱 효과적이다.
지연된 조인 기법이 항상 더 나은 방식이 아니다. 이는 GROUP BY 와 ORDER BY 를 처리한 것을 임시 테이블에 기록해놓고, 임시 테이블을 읽으면서 조인을 하는 것이기 떄문이다.
- 그래서 LIMIT 절이 있으면 효과적이다. 조인의 수 자체가 줄어들 수 있기 때문에
다음 예시는 조인을 하고나서 GROUP BY 절과 ORDER BY 절을 수행한다.
- 실행 계획을 보면 처리 과정은 다음과 같다:
-
- employees 테이블에서 emp_no BETWEEN 10001 AND 13000 조건을 검색한다.
- 검색 된 데이터를 salaries 테이블과 조인을 한다.
- GROUP BY 와 ORDER BY 절을 처리한다. (임시 테이블 사용)
- LIMIT 으로 상위 10건을 반환한다.
-

다음 예시는 지연된 조인을 이용하도록 쿼리르 변경했다:
- 실행 계획을 보면 처리 과정은 다음과 같다:
-
- salaries 테이블을 emp_no BETWEEN 10001 AND 13000 을 검색한다.
- 검색 된 데이터를 GROUP BY 와 ORDER BY 처리한다. (임시 테이블 사용)
- LIMIT 으로 상위 10건을 반환한 뒤 임시 테이블 (derived2) 에 기록한다.
- 임시 테이블 (derived2) 를 읽으면서 employees 테이블과 조인한다.
-

정리해보자. 지연된 조인으로 변경했을 때 얻었던 이점과 잃은 점은 다음과 같다:
- 장점:
- 조인을 하고나면 데이터는 데이터는 커진다. 즉 조인과 집계 처리도 더욱 느려질 것인데 지연된 조인은 미리 이 처리를 다 했다.
- LIMIT 절로 인해서 조인을 몇 건만 하면 된다.
- 단점:
- 임시 테이블을 기존보다 한 번 더 쓴다. 그러나 LIMIT 절로 인해서 메모리에 충분히 올려놓을 수 있다.
각각의 장단점이 있기 때문에 벤치마킹이 필요할 것 같다.
6.5 레터럴 조인 (Lateral Join)
FROM 절의 서브쿼리는 외부 테이블의 칼럼을 참조할 수 없다. 그러나 레터럴 조인이 등장하면서 이게 가능해졌다.
외부 테이블의 칼럼을 참조함으로써 테이블 전체를 가지고 오지 않아도 된다.
그리고 FROM 절의 서브쿼리니 레터럴 조인도 임시 테이블에 기록될 것이다.
6.6 실행 계획으로 인한 정렬 흐트러짐
조인의 과정을 생각해보면 드라이빙 테이블에서 읽은 순으로 정렬이 되어 있다고 생각할 수 있다.
그러나 해시 조인이 사용되면 정렬이 되어있지 않을 수도 있다고 함.
그래서 정렬 결과를 원한다면 명시적으로 ORDER BY 절을 추가하라고 한다.
7. GROUP BY
GROUP BY 절은 특정 칼럼을 기준으로 집계하고, 집계된 값을 하나의 레코드로 출력하게 해주는 연산자이다.
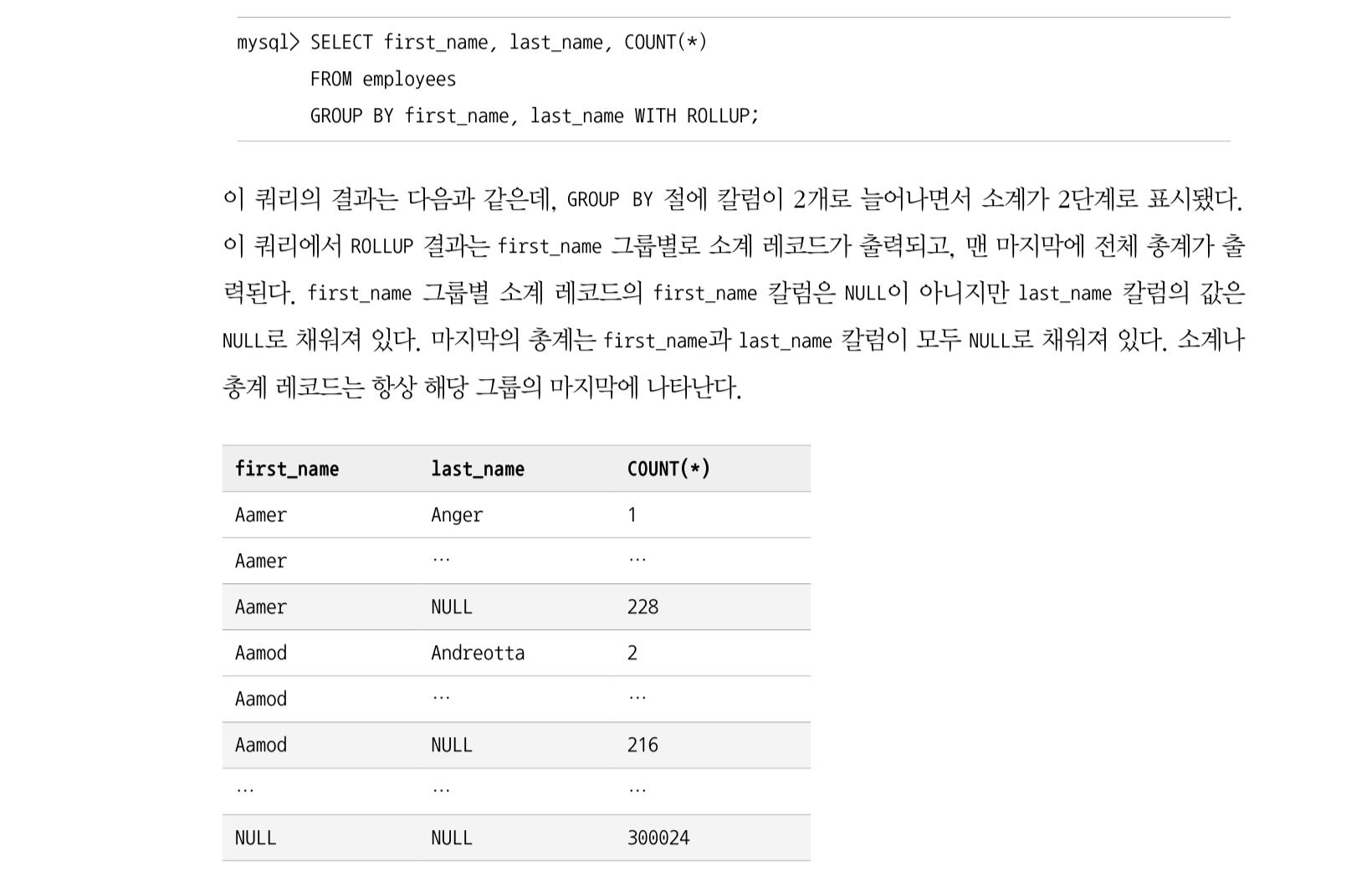
7.1 WITH ROLLUP
GROUP BY 절과 WITH ROLLUP 연산자를 같이 사용할 경우에 집계를 한 대상의 전체 개수를 부여준다. (= 이를 Grand Total 이라고 함)
예시로 보면 간단하다. 다음 SQL 문에서 WITH ROLLUP 구문이 있으면 마지막 행인 NULL 로 표시되면서 집계를 한 대상의 전체 개수가 표시된다.

GROUP BY 절에 집계 칼럼이 두 개인 상태에서 WITH ROLLUP 을 할 경우 각 집계를 한 기준 마다 총 개수가 표시된다.
7.2 레코드를 칼럼으로 변환해서 조회하기
GROUP BY 로 집계했을 때 출력되는 레코드를 칼럼들로 변환해서 쓰는 방식을 말한다.
잘은 모르겠지만 OLAP 환경에서는 이렇게 변환하는 경우가 꽤 있는 것 같다.
방식은 간단한데 FROM 절에 GROUP BY 로 집계를 해서 임시 테이블에 기록해놓고, 주 쿼리에 CASE WHEN ... THEN ... END 구절과 집계 함수를 이용해서 레코드를 칼럼으로 변환시킨다.
예시는 다음과 같다:
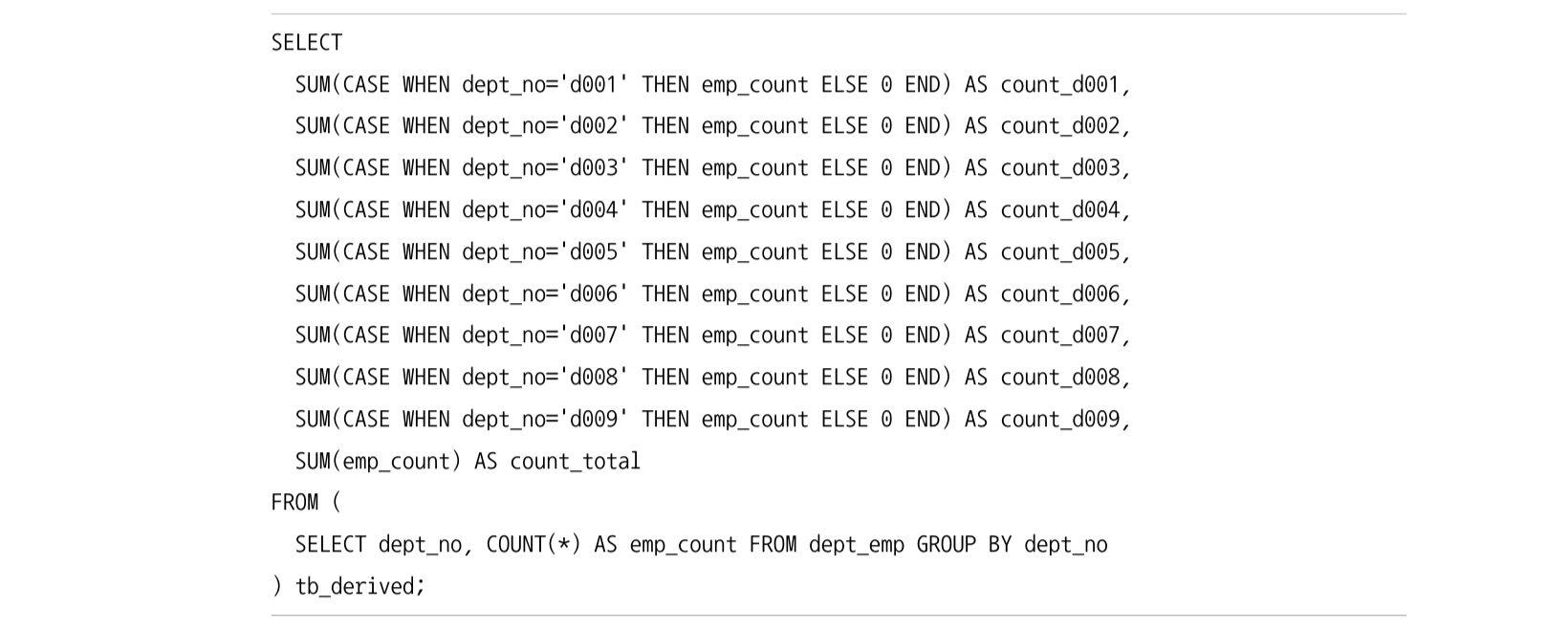

7.3 하나의 칼럼을 여러 칼럼으로 분리시키기
레코드를 칼럼으로 변환하는 방식처럼 집계 함수와 CASE WHEN ... THEN ... END 구문을 이용해서 하나의 칼럼을 여러 칼럼으로 분리시키는 방법이다.
예시는 다음과 같다:


8. ORDER BY
MySQL 이 인덱스를 이용해서 정렬된 키를 읽어서 자동으로 정렬 작업이 수행한 것이 아니라 의도적으로 정렬 작업을 수행하였다면 EXTRA 칼럼에 Using Filesort 라는 메시지가 출력된다.
이는 데이터 사이즈가 작다면 메모리에서만 정렬을 수행하겠지만, 데이터 셋이 크면 내부 임시 테이블을 디스크에 기록을 해놓고 정렬을 수행해나간다.
정렬을 메모리 수준에서만 했는지, 디스크에서 했는지 알고 싶다면 다음과 같이 MySQL 서버의 상태 변수값 Sort_merge_passes 를 조사하면 된다.
- Sort_merge_passes 는 디스크에서 저장된 정렬된 레코드들을 최종 정렬을 위해서 병합할 때마다 숫자가 증가하는 변수 값이다. 즉 이 값이 0보다 크다면 디스크를 이용한 것.
- Sort_range 라는 변수도 있는데 이는 인덱스 레인지 스캔을 통해서 정렬을 한 경우에 증가하는 값이다.
- Sort_rows 라는 변수는 풀테이블 스캔을 통해서 정렬을 한 경우에 증가하는 값이다.
8.1 ORDRR BY 사용법 및 주의사항
ORDER BY 는 하나 이상의 칼럼을 가지고도 정렬할 수 있다.
그리고 정렬할 때 각 칼럼에 오름차순인지, 내림차순인지 명령을 내릴 수 있다.
ORDER BY 2 이렇게 숫자를 기반으로 정렬을 할 수 있다. 이 경우에는 2번째 칼럼을 이용해서 정렬을 하게 된다.
ORDRR BY "last_name" 이렇게 문자열을 기반으로 정렬을 하라는 명령은 무시된다. 즉 정렬에 사용되지 않는다.
8.2 함수나 표현식을 이용한 정렬
MySQL 8.0 에서는 함수 기반의 인덱스를 사용할 수 있다.
(함수 기반의 인덱스는 칼럼의 값을 변형해서 인덱스를 구축할 때 사용한다. 즉 디스크에 저장됨.)
그래서 함수 기반의 인덱스를 사용하는 경우 다음과 같이 ORDER BY 절에 함수를 사용해서 정렬하도록 명령 내릴 수 있다.
MySQL 8.0 이전에는 연산의 결과를 인덱스에 이용하기 위해서 가상 칼럼 (Virtual Column) 을 추가하고 해당 Virtual Column 에 인덱스를 추가하는 식으로 사용했다.
9. 서브쿼리
MySQL 의 서브쿼리는 사용된 위치에 따라서 구별된다:
- SELECT
- FROM
- WHERE
사용된 위치에 따라 최적화도 달라진다.
9.1 SELECT 절에 사용된 서브쿼리
SELECT 절에 사용된 서브쿼리에서 신경쓸 것은 인덱스를 적절하게 사용하는지만 생각하면 된다.
그리고 SELECT 절에 서브쿼리를 쓰는 경우에는 스칼라 서브쿼리인 경우 (= 1개의 칼럼과 1개의 레코드) 에만 사용할 수 있다.
즉 여러개의 레코드를 가져오거나, 칼럼을 2개이상 가져오는 쿼리는 실패한다.
스칼라 서브쿼리에만 사용할 수 있기 때문에 여러 칼럼을 참조하기 위해서 다음과 같이 SELECT 절에 서브쿼리를 여러개 쓰기도 한다.
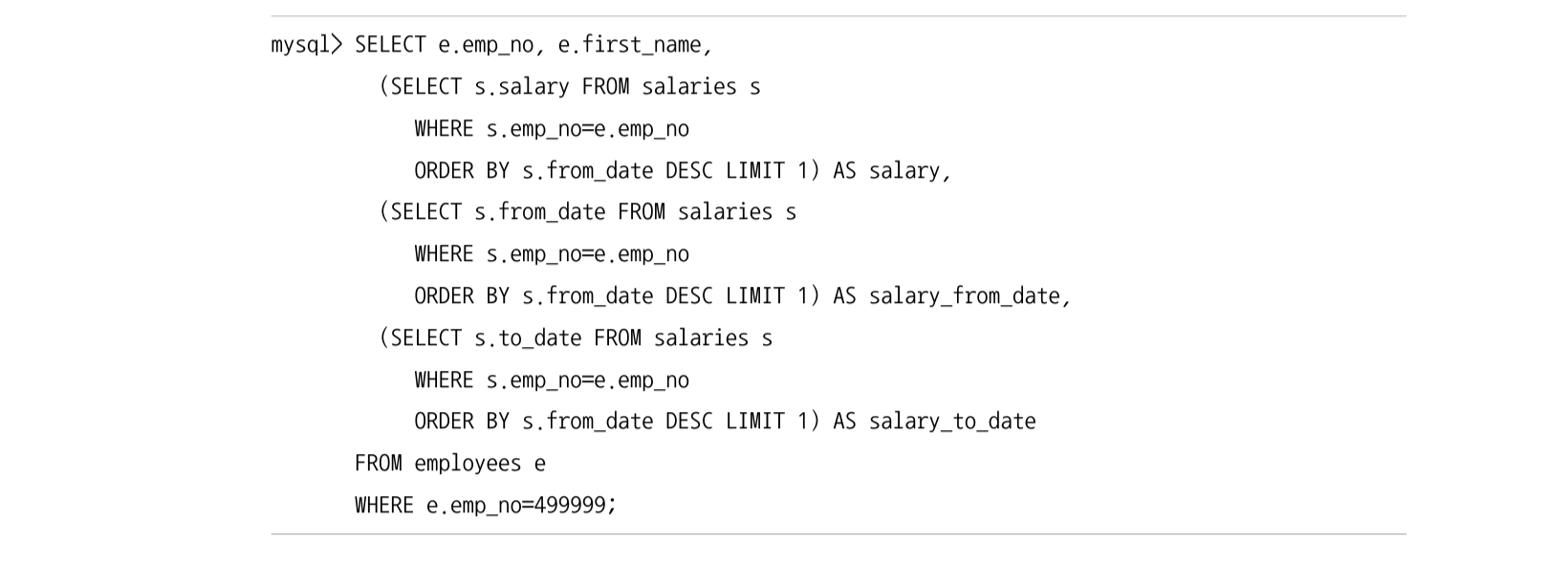
그러나 MySQL 8.0 에서는 레터럴 조인 (Lateral Join) 을 이용할 수 있으므로 FROM 절에 서브쿼리로 조건에 맞는 하나만 가져오면 된다. 이게 더 효율적이다.
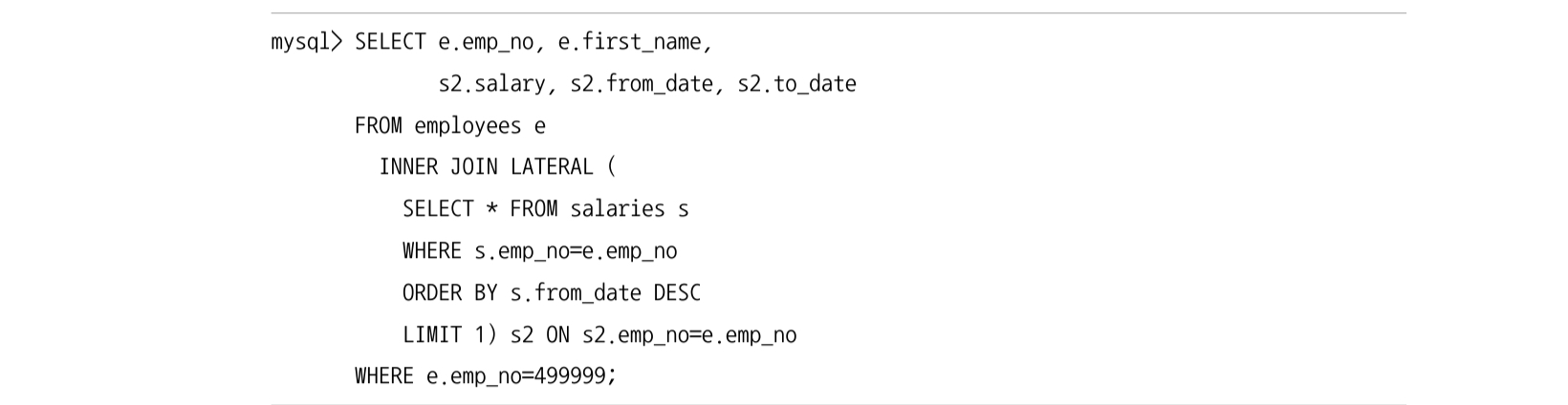
9.2 FROM 절에 사용된 서브쿼리
MySQL 5.7 이전에는 FROM 절의 서브쿼리는 모두 임시 테이블을 통해서 작성되었다.
그러나 5.7 부터는 서브쿼리를 외부 쿼리와 통합되도록 하는 최적화를 적용할 수 있다.
하지만 모든 쿼리가 외부 쿼리와 통합할 수 있는 건 아니다.
다음 조건에 해당되는 서브쿼리는 외부 쿼리와 통합할 수 없다:
- 집합 함수를 사용하는 경우
- DISTINCT
- GROUP BY 와 HAVING
- LIMIT
- UNION
- SELECT 절에 사용된 서브쿼리
- 사용자 변수 사용
- 서브쿼리에는 ORDER BY 가 있으나 외부 쿼리에는 GROUP BY 나 DISTINCT 가 있는 경우 (서브쿼리의 ORDER BY 가 의미가 없어져서 합칠 수 없다.)
9.3 WHERE 절에 사용된 서브쿼리
WHERE 절에 사용된 서브쿼리는 다음 3가지 종류로 나눠서 살펴보겠다:
- 동등 비교 또는 크다 작다 비교
- IN(subQuery)
- NOT IN (subQuery)
9.3.1 동등 비교 또는 크다 작다 비교
MySQL 5.5 이전 버전에서는 다음과 같은 동등 비교에 서브쿼리가 있는 경우에 주 테이블이 풀스캔하면서 서브쿼리가 실행되었다.

다행히 MySQL 5.5 부터는 서브쿼리를 먼저 실행하고 주 테이블이 실행하도록 하면서 최적화가 수행됨.
- 서브쿼리를 먼저 실행하면서 WHERE 절에 사용할 상수로 변환시킨다.

9.3.2 IN(subQuery)
MySQL 에서 WHERE 절과 IN(subQuery) 를 사용하는 식의 쿼리를 세미조인이라고 한다.
세미조인의 뜻은 조인을 수행하진 않지만 조인 결과가 있는지, 없는지 정도만을 확인한다는 뜻임.
세미조인에 대한 최적화는 MySQL 8.0 으로 오면서 많이 이뤄졌다:
- 테이블 풀 아웃 (Table Pull-out)
- 퍼스트매치 (FirstMatch)
- 루스 스캔 (LooseScan)
- 구체화 (Materialization)
- 중복 제거 (Duplicate weed out)
9.3.3 NOT IN (subQuery)
NOT IN (subQuery) 형태의 쿼리를 안티 조인이라고 한다.
안티 조인은 A 테이블에는 있지만 B 테이블에는 없는 데이터를 조회할 때 쓰인다.
NOT IN (subQuery) 과 같은 쿼리를 일반적으로 처리하면 없는지 살펴보기 위해서 풀스캔으로 처리된다.
그러나 NOT EXISTS 방식으로 최적화가 되면 이를 Outer Join 형식으로 풀어서 최적화를 수행할 수 있다.
아니면 Materialization 을 이용한 최적화도 있다.
10. 윈도우 함수 (Window Function)
GROUP BY 와 Window Function 의 차이점:
- GROUP BY 는 명시된 칼럼을 기준으로 집계해서 하나의 레코드를 만든다. 이로 인해서 원본 행이 하나로 합쳐진다는 특징이 있다.
- Window Function 은 GROUP BY 처럼 레코드에서 다른 레코드를 참조할 수 있다. 참조한 레코드를 집계 할 수 있고, 참조한 레코드의 범위를 지정할 수도 있다. 그리고 집계한 값이 원본 행에 영향 없이 별도의 칼럼으로 출력할 수 있다.
- 이 함수는 'OVER()' 절과 함께 사용하며 'PARTITION BY' 와 'ORDER BY' 등으로 윈도우를 정의할 수 있다.
- 'OVER()' 은 전체 레코드 집계를 어떻게 구분해서 집계할건지 설명하는 칼럼이다. 그냥 단순하게 'OVER()' 을 쓰면 전체 레코드를 집계한다.
- 'PARTITION BY' 는 전체 레코드 집계를 어떤 칼럼을 기준으로 나눠서 구분할 건지 명시한다. 명시한 칼럼의 값을 기준으로 집계를 구분해서 수행한다.
- 'ORDER BY' 는 출력할 때 정렬할 칼럼을 명시한다.
먼저 GROUP BY 예시를 보자:
SELECT department, SUM(sales) as total_sales
FROM sales
GROUP BY department;| department | total_sales |
|------------|-------------|
| A | 250 |
| B | 450 |
Window Function 의 예시를 보자:
SELECT id, department, date, sales,
SUM(sales) OVER (PARTITION BY department ORDER BY date) as cumulative_sales
FROM sales;| id | department | date | sales | cumulative_sales |
|----|------------|------------|-------|------------------|
| 1 | A | 2023-01-01 | 100 | 100 |
| 2 | A | 2023-01-02 | 150 | 250 |
| 3 | B | 2023-01-01 | 200 | 200 |
| 4 | B | 2023-01-02 | 250 | 450 |
10.1 윈도우 함수의 실행 순서
윈도우 함수가 언제 실행되는지 알아야한다. 그래야 나의 예상과 맞게 쿼리가 동작할 것이기 때문이다.
윈도우 함수는 다음 순서에 따라서 실행된다:
- WHERE, FROM, GROUP BY, HAVING 절이 끝난 이후에 윈도우 함수가 실행되고, SELECT, ORDER BY, LIMIT 전에 윈도우 함수는 실행된다.

만약 이 순서를 깨고 싶다면 FROM 절에 서브쿼리를 사용하면 된다. 그러면 해당 쿼리가 먼저 실행될 것이니까.
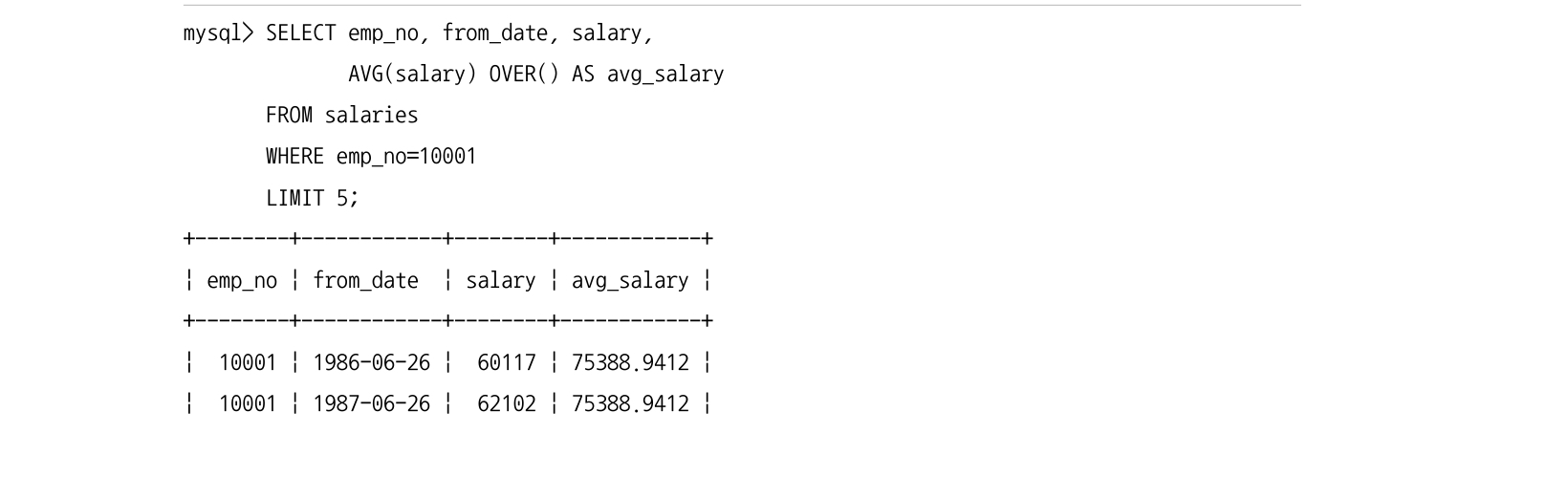
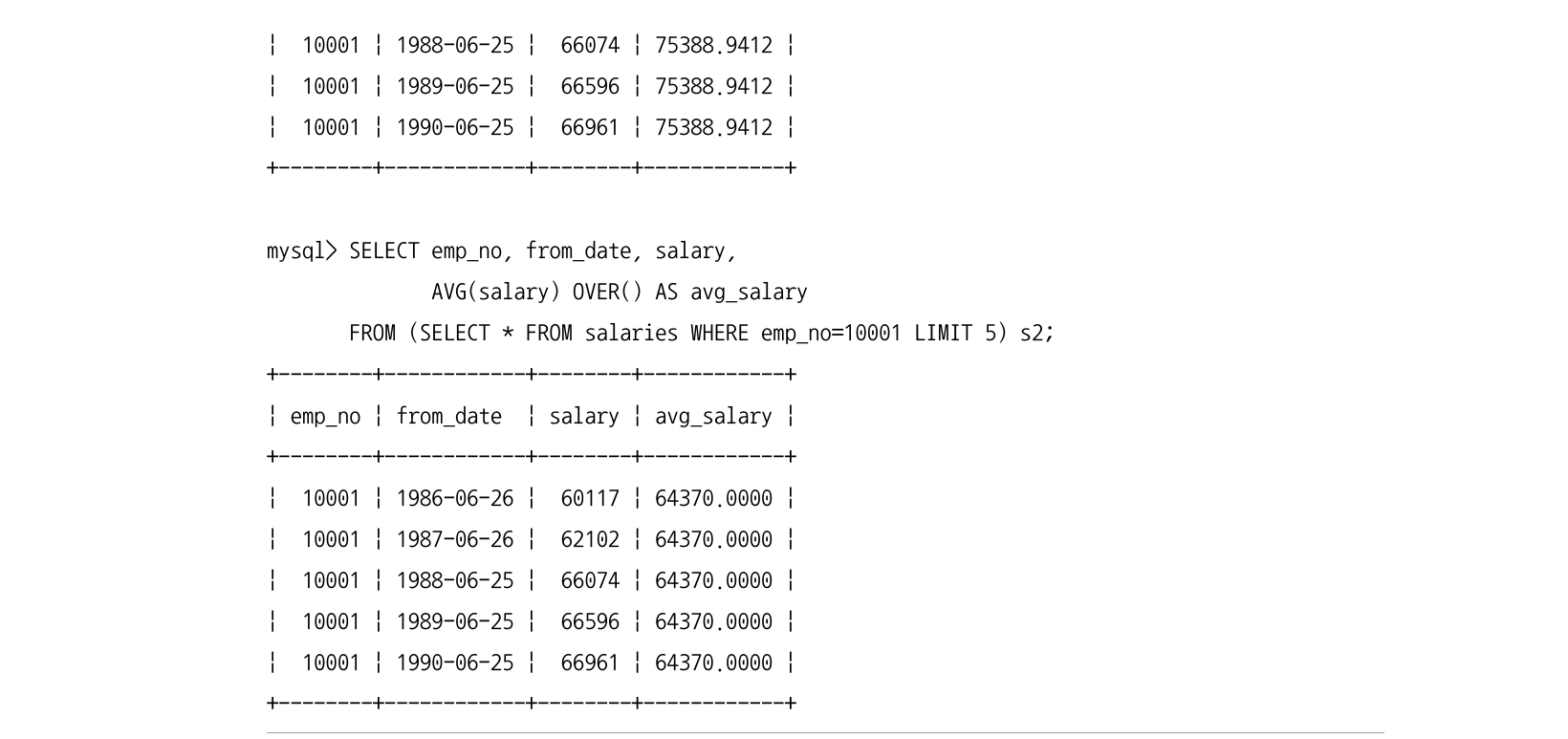
다음 두 쿼리는 LIMIT 절을 주 쿼리에서 쓴 것과, FROM 절의 서브쿼리에서 쓴 것들이다. 결과가 다르다.
- 주 쿼리에서 쓴 것들은 윈도우 함수가 전체 레코드에서 집계 처리를 한 후 LIMIT 으로 5건을 가져온다.
- 서브쿼리에서 쓴 것은 전체 레코드의 집계가 아니라 5건에서만 윈도우 함수가 적용된다.
10.2 윈도우 함수 기본 사용법
Window Function 을 사용할 때 고려해야 할 점은 다음과 같다:
- 어떤 집계 함수를 사용할 것인가? (다른 레코드를 참조해서 어떤 계산을 할 것인가)
- 레코드 집계 칼럼과 범위:
- 단순히 'OVER()' 만 사용하면 전체 레코드를 집계한다.
- 추가로 'PARTITION BY' 를 사용하면 특정 칼럼을 기준으로 집계를 구분한다.
- 'PARTITION BY' 에 추가로 'FRAME' 을 사용하면 집계의 범위도 설정한다. (e.g 현재 로우를 기준으로 앞뒤로 5건씩만 사용해서 집계를 하겠다. 이런 것)
- 정렬 기준
예시들로 보자. 다음은 직원들의 입사 순서 조회 쿼리다:
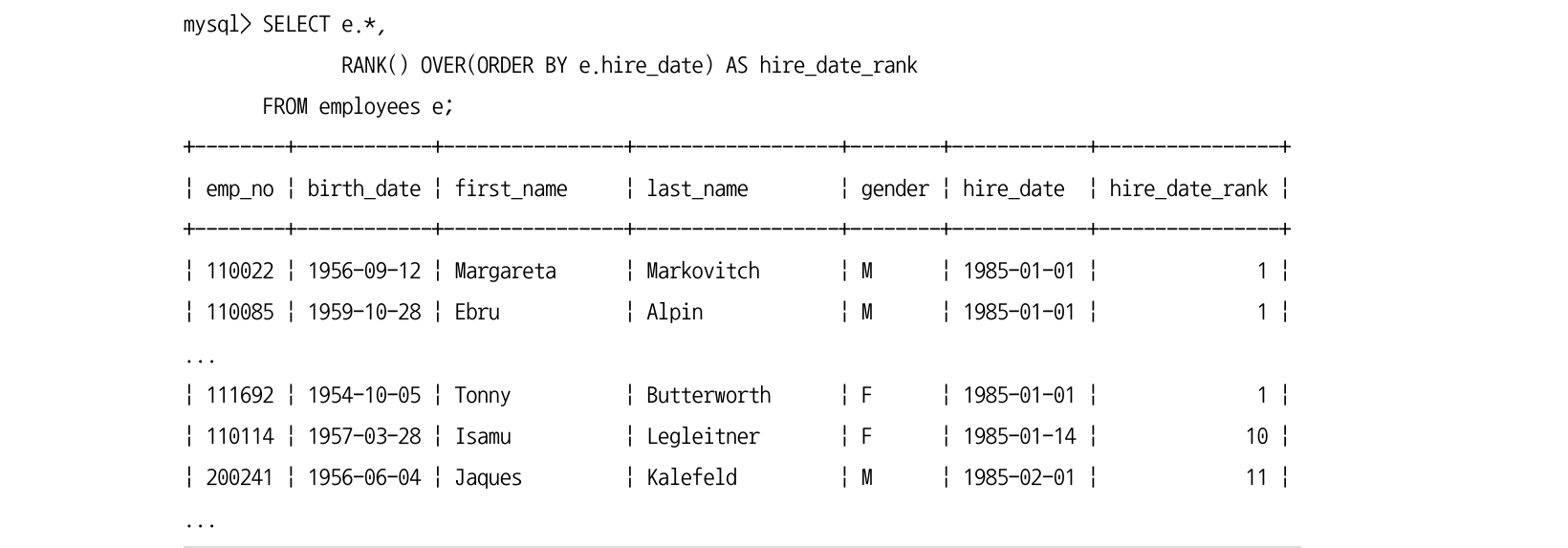
다음 예시는 부서별로 입사 순서를 매기고자 하는 쿼리다:

10.3 윈도우 함수 종류
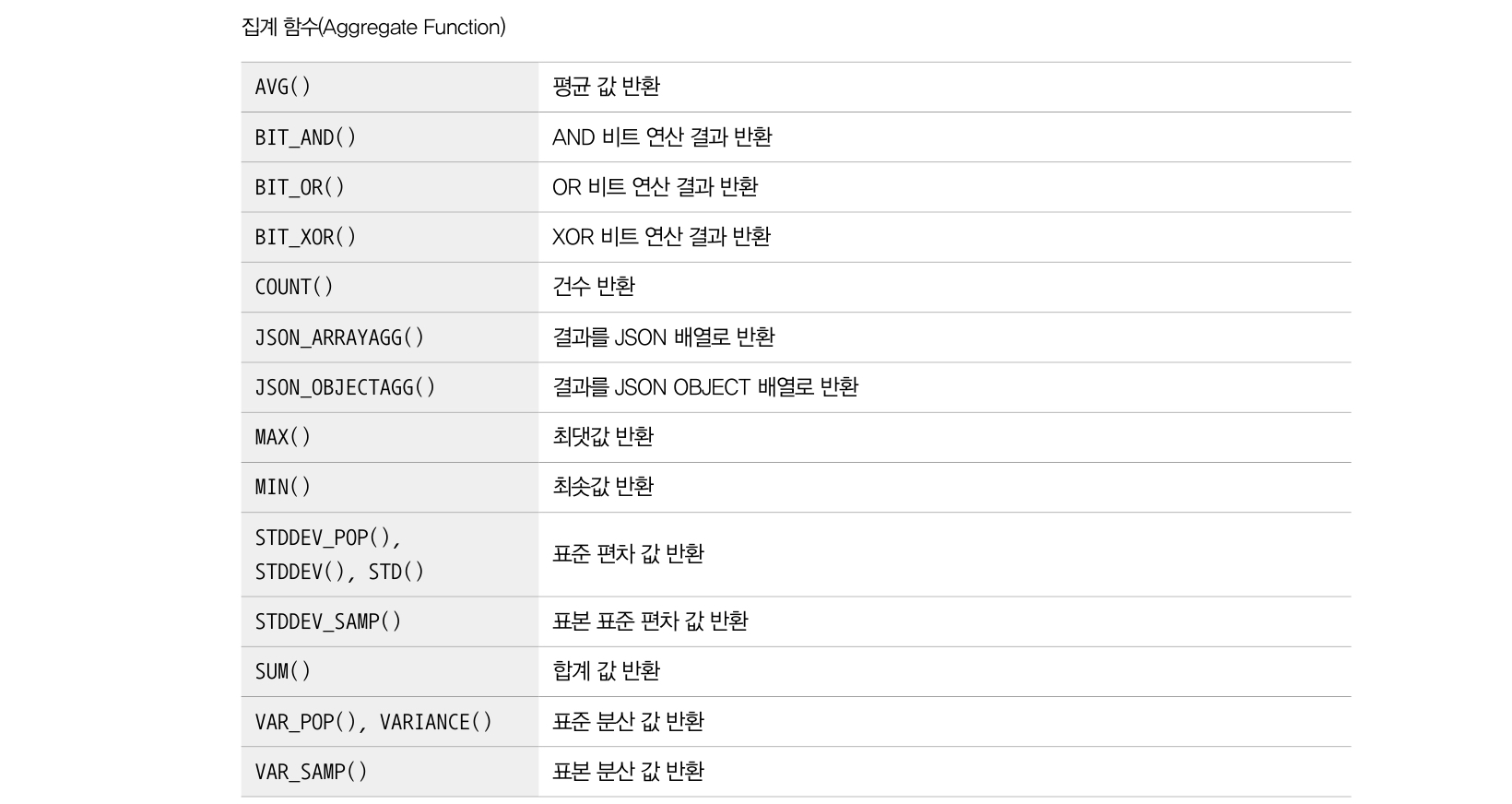
다음은 집계 함수 종류이다.

10.4 윈도우 함수 성능
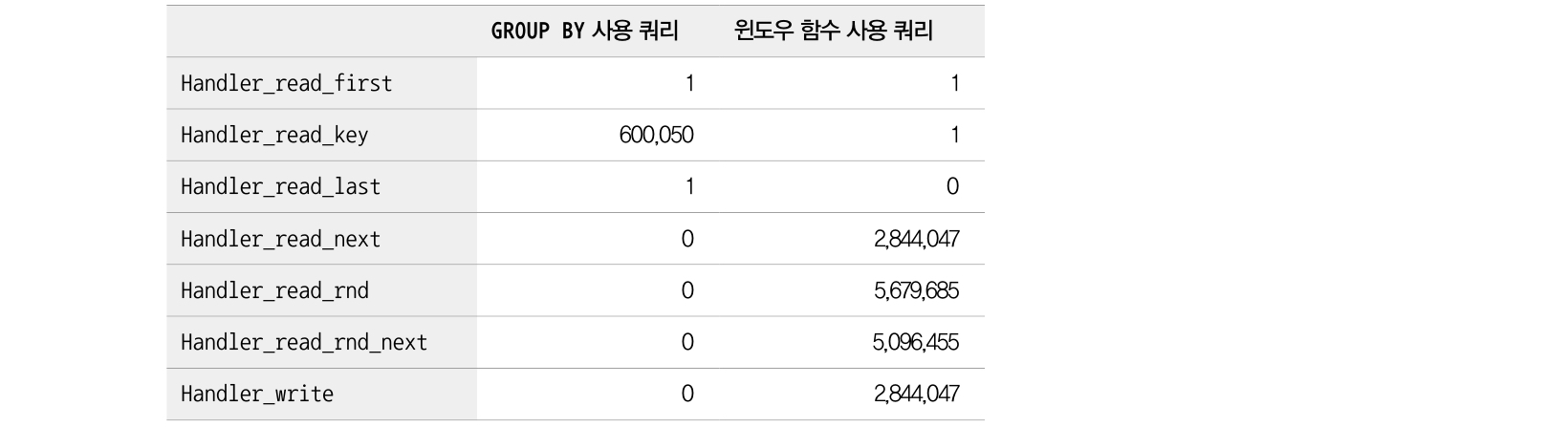
다음은 GROUP BY 절과 Window Function 의 성능을 비교한 쿼리 에시다:
- GROUP BY 절은 인덱스 루스 스캔을 이용해서 최적화가 된 것이다.
- 그러나 윈도우 함수는 Using Filesort 같은 메시지가 있는 걸 보니 인덱스를 효율적으로 이용하지 못하는 듯하다.
- Handler 변수를 통해서 내부적으로 인덱스가 얼마나 사용되었는지 알 수 있다.


MySQL 8.0 에 윈도우 함수가 처음으로 도입되서 그런지 아직 최적화가 부족한 것 같다.
11. 잠금을 사용하는 SELECT
MySQL 에서는 SELECT 절을 사용할 때 다른 세션에서 변경하지 못하게 잠금을 걸 수 있다.
잠금을 걸 수 있는 방식은 두 가지가 있고, 잠금 레벨이 다르다:
- FOR SHARE:
- 읽기 잠금으로 다른 세션에서 읽기 요청은 되나 수정은 안되도록 잠근다.
- FOR UPDATE:
- 쓰기 잠금으로 다른 세션에서 읽기도 안되고 쓰기도 안된다.
SELECT 로의 잠금은 트랜잭션의 AUTO COMMIT 모드에서는 사용할 수 없다.
11.1 잠금 테이블 선택
다음과 같이 조인을 하는 쿼리에서 단순히 FOR UPDATE 명령을 내리면 조인을 수행하는 모든 테이블이 잠긴다:

그래서 특정 테이블만 잠그려면 다음과 같이 OF 을 붙혀서 잠금 테이블을 명시해야한다.

11.2 NOWAIT & SKIP LOCKED
잠금 때 NOWAIT 옵션을 붙히면 레코드가 잠겨져서 대기를 해야하는 상황에서 기다리지 않고 에러를 던지도록 할 수 있다.
대기하는 시간은 시스템 변수인 innodb_lock_wait_timeout 으로 결정되는데 기본 값은 50초이다.
웹어플리케이션에서 50초동안 기다리게 하는 것은 올바르지 않으니 필요하다면 NOWAIT 설정을 하자.
잠글 때 SKIP LOCKED 옵션을 붙이면 잠겨진 레코드는 읽지 않고 Skip 하게 되면서 SELECT 절을 실행한다.
이는 선착순 쿠폰 발급과 같은 시나리오에서 유용하게 동작하게 할 수 있다.
쿠폰 시나리오는 다음과 같다:
- 하나의 쿠폰은 한 사용자만 사용 가능하다.
- 쿠폰의 개수는 1000개로 제한되어 있으며, 선착순으로 발급한다.
쿠폰의 스키마는 다음과 같다;

다음 쿼리처럼 단순히 FOR UPDATE 를 날리면 트랜잭션이 하나씩 처리되게 되면서 기다리게된다.
그래서 SKIP LOCKED 가 없었을 때는 REDIS 와 같은 것들을 이용하기도 했다.

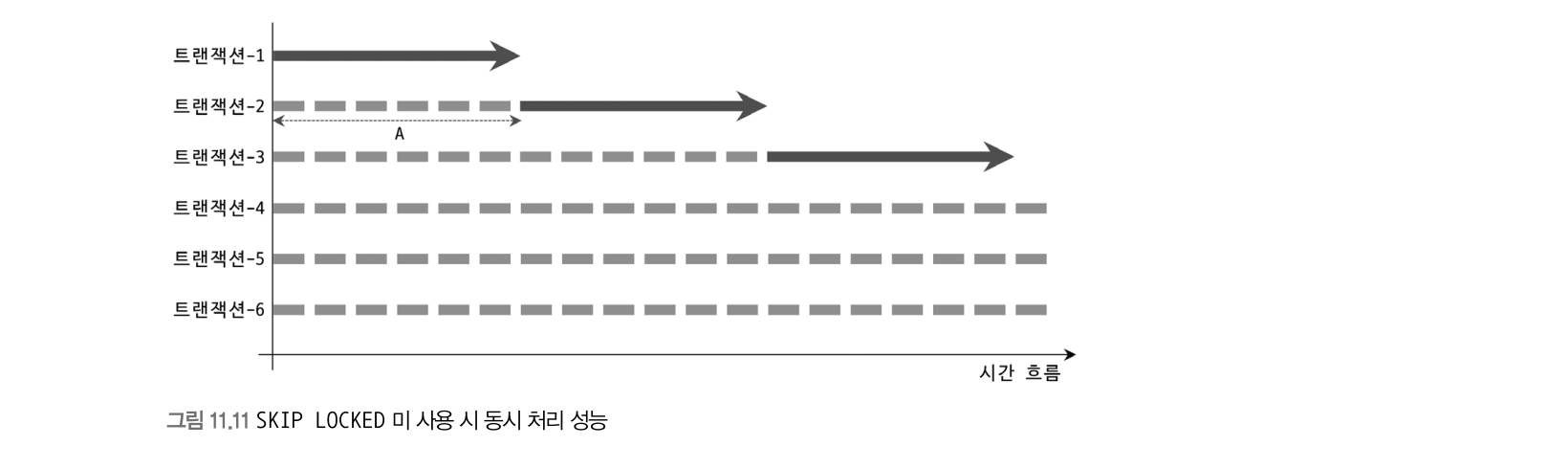
그러나 SKIP LOCKED 를 붙히면 사용자에게 발급되어야 할 잠겨진 쿠폰은 생략되면서 쿠폰 발급을 동시성있게 처리하게 될 수 있다.

'MySQL' 카테고리의 다른 글
| MySQL 고급 최적화 (0) | 2023.11.24 |
|---|---|
| MySQL 실행 계획 분석: filtered 칼럼 (0) | 2023.11.07 |
| MySQL 실행 계획 분석: row 칼럼 (0) | 2023.11.07 |
| MySQL 실행 계획 분석: ref 칼럼 (0) | 2023.11.07 |
| MySQL 실행 계획 분석: key_len 칼럼 (0) | 2023.11.07 |