소프트웨어는 비즈니스 변화에 맞춰서 변경을 하기 쉬운 구조로 만드는게 좋다. 이를 Evolvability 라고 부른다.
때로는 새로운 기능의 추가가 데이터의 변화를 야기하기도 한다.
데이터의 변화는 데이터베이스의 스키마를 변화시킬 것이고 이에따라 어플리케이션에서도 코드에도 변화가 일어나야 할 것이다.
중요한 건 이러한 스키마의 변경은 동시에 일어나지 않는다는 것이다.
그래서 스키마는 한쪽만 변경되서 다른 쪽에서는 데이터를 읽어올 수 없는 문제가 생길 수도 있다.
즉 스키마를 변경할 때 신경써야할 것은 하위 호환성 (Backward compatibility) 와 상위 호환성 (Forward compatibility) 이다.
- 하위 호환성은 새로운 코드가 오래된 스키마의 데이터를 문제없이 읽을 수 있는 것을 말한다.
- 상위 호환성은 오래된 코드가 새로운 스키마의 데이터를 문제없이 읽을 수 있는 것을 말한다.
여기서는 여러가지 Binary Encoding 과 Schema Evolution 이 일어날 때 상위 호환성과 하위 호환성을 지키는 방법에 대해서 다룬다.
1. Encoding 의 정의
먼저 Program 에서 사용하는 데이터의 종류는 크게 두 가지로 나뉜다:
- In-memory 에서 여러 Data Structure 로 표현될 수 있는 데이터들. 이런 데이터의 목적은 최적의 CPU 연산을 위해서 사용한다.
- File 로 저장하거나 Network 로 데이터를 보낼 때 사용하는 데이터들. 이런 데이터는 sequence of bytes 로 표현된다.
Encoding 은 여기서 Network 를 통해 데이터를 보낼 때 연속된 바이트들로 표현하기 위해서 사용된다.
2. JSON, XML, CSV 등의 Text Format
데이터를 교환할 때 자주 사용하는 Data Format 으로는 JSON 과 XML 그리고 CSV 가 있다.
이 방식의 Text Format 문제점은 다음과 같다:
- XML 과 CSV 는 String 과 Integer 를 구별 못한다. 그래서 Integer 를 String 으로 사용하기 때문에 더 많은 Byte 를 사용할 것이다.
- JSON 은 Integer 와 Floating-point number 을 구별하지 못한다. 그리고 2^53 을 넘는 숫자를 표현하기 어렵다.
- 이유는 JSON 은 Javascript 의 Number 를 이용해서 숫자를 표현하는데 이 최대 값이 2^53 - 1 임
- 트위터의 API 경우에 트윗의 id 가 2^53 을 넘는 경우가 있다고 한다. 그래서 JSON 으로 넘겨줄 때 문자열로 표현된 Id 로 전달해준다고 함.
- JSON 과 XML 은 Unicode Character String 에 적합하지만 Binary String (= Encoding 없는 단순 바이너리) 은 표현할 수 없다.
- Binary String 으로 표현하기 위해서 Base64 와 같은 인코딩 기법을 이용한다고 함. 이 방식으로하면 데이터의 사이즈는 33% 증가한다.
- Base64 인코딩은 8비트 중에 6비트만 사용해서 인코딩한다. 즉 24비트 (3바이트) 의 데이터 전송을 위해서 4바이트가 필요하게 되니까 33% 증가하는 것.
- 이진 데이터는 원본 그대로 보내기 어렵다. 이 데이터를 받는 프로그램에서 이 데이터를 자체적으로 해석할 여지가 있기 때문에. 예시로 이메일 서비스에서 0x00, 0x0A, 0x0D 와 같은 바이트가 온다면 줄바꿈으로 인식해버린다.
- Binary String 으로 표현하기 위해서 Base64 와 같은 인코딩 기법을 이용한다고 함. 이 방식으로하면 데이터의 사이즈는 33% 증가한다.
이런 단점이 있음에도 JSON 같은 경우는 표현하기 쉬운 구조라서 데이터를 주고받을 때 자주 사용한다.
3. Binary Encoding
JSON 과 같은 데이터를 네트워크를 통해서 전송할 때 텍스트 기반의 인코딩인 UTF-8 같은 것이 사용된다.
텍스트 기반의 인코딩을 사용했을 때 바이너리 인코딩과 비교했을 때 다음과 같은 단점이 있다:
- 파싱 속도가 느리다 즉 직렬화/역직렬화 처리가 느리다:
- 바이너리 형식의 데이터는 미리 정해진 바이트 길이와 형식으로 데이터를 보내서 한번에 여러 바이트들을 consume 하는게 가능하나, 텍스트 기반의 인코딩에서는 문자열의 끝이나 구분자를 찾기 위해서 하나씩 순차적으로 바이트를 읽어야한다.
- 데이터의 사이즈가 크다:
- 불필요한 데이터를 첨부해야한다. JSON 기준으로는 ('{', ',', '}', '[', ']')
- 숫자를 문자열로 인코딩을 하니까 바이트의 사이즈가 더 커진다.
텍스트 기반의 인코딩은 이러한 단점이 있지만 인간이 읽기 쉽고, 별다른 툴 없이 디버깅하기도 쉽기 때문에 많이 사용된다.
그러나 조직 내에 있는 시스템끼리 데이터를 교환한다면 데이터 포맷을 좀 더 Compact 하고 Parsing 하는데 빠른 Encoding 을 사용하는 것이 좋다. (다루는 데이터가 클수록 이 효과는 점점 커질 것이다.)
이제부터는 Binary Encoding 들에 대해서 하나씩 알아보자.
3.1 Message Pack
JSON 데이터를 Binary 로 Encoding 하기 위해서 등장했다.
Message Pack 은 JSON 의 불필요한 데이터를 제외하고, 각 타입에 맞는 최적의 바이트를 사용해서 표현된다.
그러나 FIeldName 과 같은 바이트가 같이 전송되서 효율적으로 데이터 사이즈를 줄일 수 없다.
예시는 다음과 같다.
- 다음 JSON 데이터는 텍스트로 인코딩하면 81바이트가 나온다.
- 그러나 Message Pack 으로 인코딩을 할 경우 66바이트가 나온다.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
3.2 Thrift and Protocol Buffer
Thrift 와 Protocol Buffer 도 Binary Encoding 을 하는 라이브러리다.
이 방식의 인코딩은 Message Pack 과 달리 스키마를 필요로 한다.
스키마에서 중요한 사실은 다음과 같다:
- Field 에 번호가 있다. 이는 Field Tag 라고 부르며 Field 를 식별하기 위해서 사용된다. FieldName 대신에 사용되며 더 적은 바이트를 네트워크로 전송할 수 있다는 장점이 있다.
- 필드는 'required’ 와 ‘optional’ 로 구분되어 있다는 것이다. 이건 이후에 상위 호환성과 하위 호환성 주제를 다룰 때 자세하게 설명한다.
Thrift 스키마 예시:

Protocol Buffer 스키마 예시:

Thrift 는 Binary Encoding 과 이를 더 경량화한 Compact Encoding 을 지원한다. 하나씩 살펴보자.
예제는 아래의 JSON 을 이용한다:
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
Thrift 의 Binary Encoding:
- 중요한 건 FieldName 을 전송하는 대신에 Field Tag 를 전송한다. (Field Tag 가 더 적은 바이트를 사용할 수 있다.)
- 실제 필요한 정보들은 Field Type, Field Tag, 실제 Data Byte, (Option) Byte Length, (Option) List Byte 이다.
- 원본 JSON 은 81바이트지만, Binary Protocol 로 Encoding 하면 59바이트로 줄어든다.
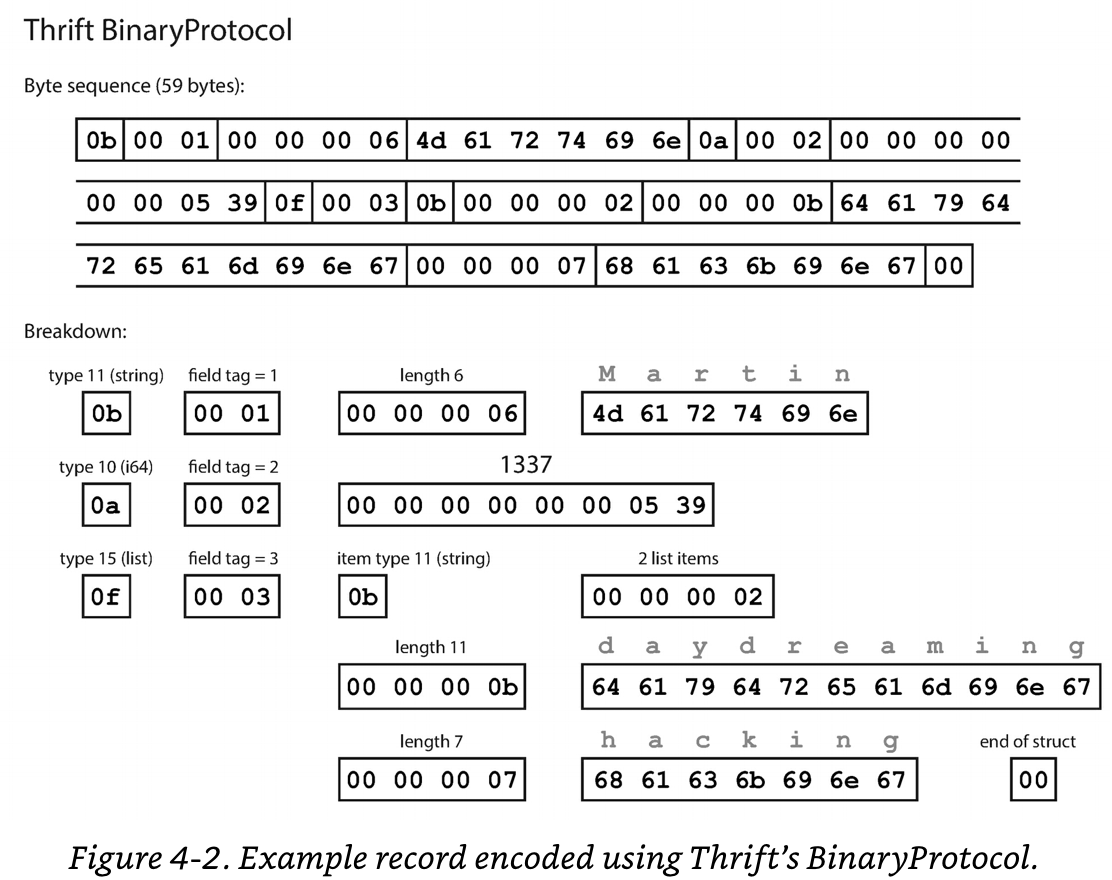
Thrift 의 Compact Encoding:
- Field Tag 와 Field Type 을 합쳐서 더 작은 바이트로 관리할 수 있게한다;
- 숫자를 표시할 때 가변 길이로 최적의 바이트를 사용할 수 있게 한다. (이는 VB Compression 과 유사해보인다.)
- 숫자를 표현하는데 바이트가 더 필요하다면 바이트의 맨 앞 비트가 0 이고 다음 바이트를 읽게한다.
- 숫자를 표현하는데 더이상의 바이트가 필요하지 않다면 바이트의 맨 앞 비트가 1이고 바이트를 더 읽지 않는다.
- Compact Protocol 로 Encoding 을 할 경우 34바이트까지 줄일 수 있다:

Protocol Buffer:
- Protoco Buffer 로 인코딩을 할 경우 33바이트로 줄어든다.
- Protocol Buffer 는 Thrift 와 달리 Field Type 으로 List 타입이나 Array 타입 같은 것이 없다.
- 여러개의 요소가 올 수 있는 유형의 타입이라면 Field Tag 를 반복해서 사용한다. 이렇게 사용하는 이유는 스키마에서 기존 필드를 List 유형의 필드로 변환시킬 수 있다는 점 떄문이다. 즉 스키마에서 필드 변경에 유연함을 주기 위해서이다.
- 새로운 필드가 List 로 변경된다면 새로운 스키마를 가진 코드에서는 데이터는 하나의 요소를 담는 List 로 읽어올 수 있다.(이는 하위 호환성을 만족한다.)
- 오래된 스키마를 가진 코드에서 List 타입인 새로운 스키마를 가진 데이터가 온다면 마지막 요소의 데이터로 값이 세팅되면서 읽어올 수 있다. (이는 상위 호환성을 만족한다.)
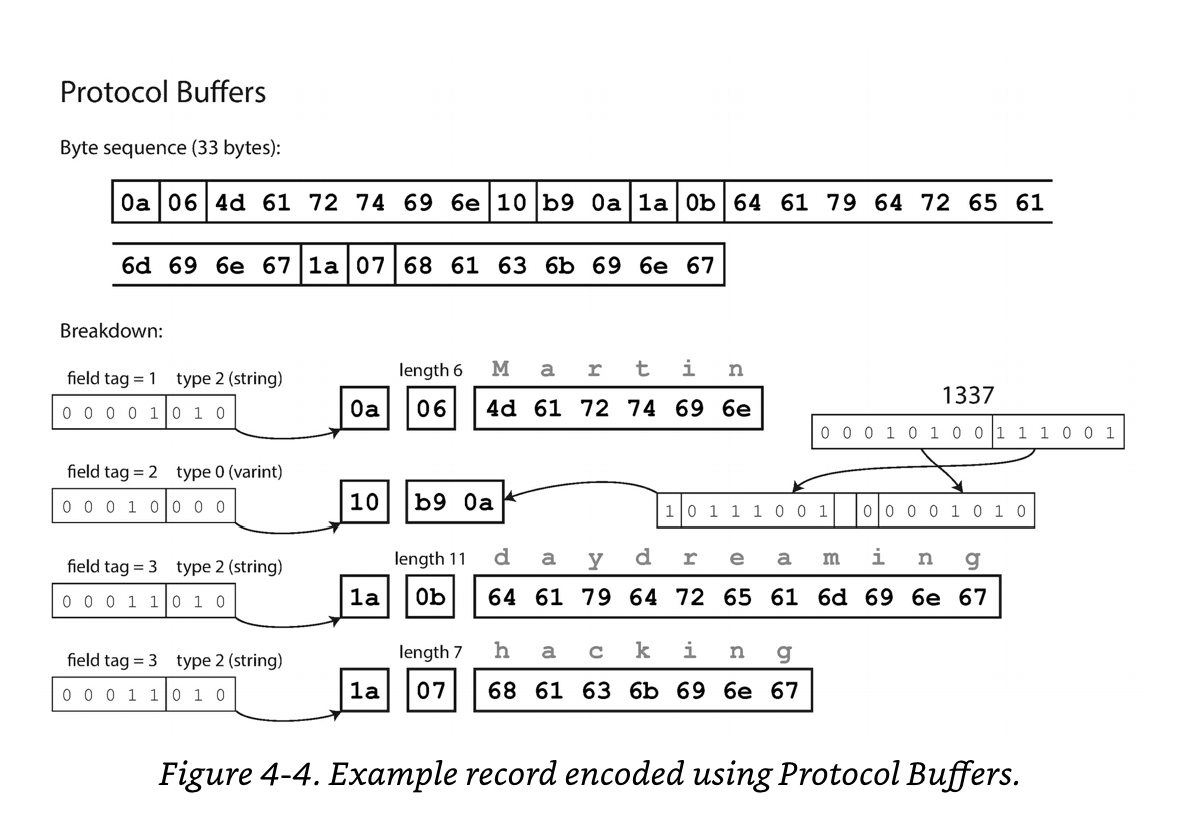
- 여러개의 요소가 올 수 있는 유형의 타입이라면 Field Tag 를 반복해서 사용한다. 이렇게 사용하는 이유는 스키마에서 기존 필드를 List 유형의 필드로 변환시킬 수 있다는 점 떄문이다. 즉 스키마에서 필드 변경에 유연함을 주기 위해서이다.
3.2.1 Field tags and schema evolution
Thrift 와 Protocol Buffer 는 스키마가 계속해서 업데이트 되는 상황 (= Schema Evolution) 에서 상위 호환성과 하위 호환성을 어떻게 유지할 수 있을까?
Thrift 와 Protocol Buffer 모두 스키마를 사용하고 스키마의 필드는 Field Tag 로 구별된다.
Field Tag 의 값이 변경된다면 읽는 쪽에서 정상적으로 데이터를 읽기 힘들 것이다. 즉 상위 호환성과 하위 호환성 모두 지켜지지 않을 것이다.
필드를 추가할 경우:
- 새롭게 추가되는 필드가 있다면 단순히 새로운 Field Tag 를 스키마에 붙혀서 데이터를 전송하게 된다면 이를 오래된 스키마를 가진 읽는 쪽에서는 내가 가지지 않은 Field Tag 니까 무시할 것이다. 그래서 상위 호환성은 쉽게 지킬 수 있다.
- 그러나 새로운 스키마를 가진 쪽에서 오래된 스키마를 가진 데이터를 읽게 될 경우에 새로 추가된 필드의 데이터가 없을 것이라서 읽을 수 없다. 그러므로 이 경우에 대응하기 위해서 필드를 추가할 때는 기본 값을 설정해 놓거나 필드를 추가할 때 ‘required’ 로 추가하지 않고 ‘optional’ 로 추가를 하면 된다.
- 필드는 'required' 또는 'optional' 로 설정할 수 있다. 'required' 는 반드시 있어야 하는 데이터를 말하며, 이 데이터가 존재하지 않을 경우에 에러를 낸다. 'optional' 은 데이터가 존재하지 않으면 무시한다. (Protocol Buffer 3 부터는 'required' 개념이 사라졌다. 모두 optional' 임)
필드를 삭제할 경우:
- 'required' 로 명시한 필드는 지울 수 없다. 'optional' 로 선택한 필드만 지울 수 있다.
3.3 Avro
Apache Avro 는 Hadoop 진형에서 Thrift 를 검토하다가 맞지 않아서 자체적으로 만든 Binary Encoding 기법이다.
JSON 데이터를 바이너리로 인코딩 헀을 때 가장 Compact 하게 나온다는 특징이 있다.
가장 Compact 한 이유로는 Avro 도 스키마를 사용하지만 Field Tag 와 Data Type 에 대한 바이트가 없다. Byte Length 와 실제 데이터에 대한 Byte 만 있다.
예시로 보자.
아래의 JSON 데이터를 Avro 로 표현하면 다음과 같다:
- 하나씩 JSON 데이터, Avro Schema, Avro Schema 로 쓴 바이트들이다.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
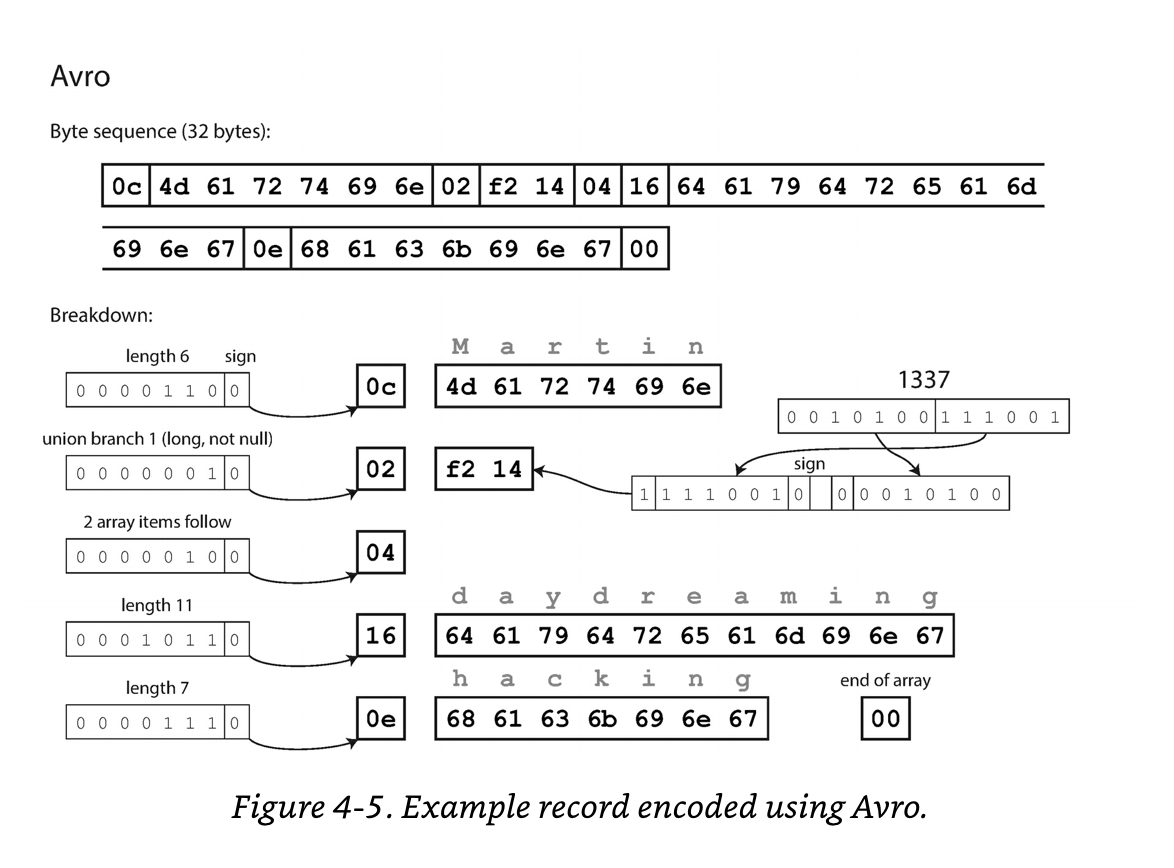
필드에 대한 메타 바이트들이 없는데 어떻게 이 바이트들을 읽을 수 있을까?
- 얼핏보면 스키마의 순서대로 바이트로 표현해서 decoding 할 때 순서대로 읽으면서 스키마에 따라 매핑을 해줘야하는 것처럼 보인다.
Avro 가 최소한의 바이트만 있어도 되는 이유는 읽을 때 이 바이트로 기록했던 Writer Schema 도 가져오기 때문이다.
Writer Schema 대로 바이트를 순서대로 기록했고, 이 정보를 바탕으로 읽는다. 그리고 읽을 때 읽는 쪽은 자신의 Reader Schema 가 있을 것인데 이것에 매핑하면서 읽는다.
- 즉 Writer Schema 를 참고해서 데이터를 해석하고 Reader Schema 에 맞게 매핑하면 된다.
- Writer Schema 와 Reader Schema 는 서로 동일할 필요는 없다. 읽고나서 Reader Schema 대로 할당만 할 수 있으면 된다.
- 읽는 쪽에선 여러 스키마 버전 중 하나의 Reader Schema 를 가지고 있을 것이다.

3.3.2 Schema evolution rules
Avro 에서 스키마 추가/제거 할 때 상위/하위 호환성을 지키는 방법:
- Avro 는 ‘Required’ 와 ‘optional’ 필드가 없다. 그래서 default value 를 적극적으로 이용해야지 호환성을 다룰 수 있다.
- 필드를 추가할 때는 기본 값이 있는 필드를 추가해야한다.
- 필드를 제거할 때는 기본 값이 있는 필드를 제거해야한다.
Avro 에서 필드 타입을 변경하는 건 되지만 상위 호환성과 하위 호환성을 고려해야한다:
- Int -> String 으로 변경시켰다면 하위 호환성이 깨질 위험이 있다.
Avro 는 필드 이름을 바탕으로 Wrtier Schema 에서 읽은 데이터를 Reader schema 에 매핑하니까 이름을 변경하는 것은 조심해야한다.
3.3.3 But What is the writer Schema’s
Writer Schmea 를 가져오는 방법은 다양하다:
- Large File with lots of records:
- 하둡에서 사용되는 가장 사용되는 방법.
- 파일의 시작 부분에 스키마를 명시해두고, 파일에 해당 스키마를 통해 수백만개의 데이터들은 인코딩되서 저장되어 있다.
- Database with individual written records:
- 각 레코드마다 사용된 스키마가 다를 수 있으니까, 데이터베이스에 저장된 레코드마다 사용된 스키마 Id 도 같이 저장해두는 것이다.
- 가장 일반적으로 사용할 수 있다.
- Sending records over a network connection:
- Avro 를 이용한 RPC protocol 로 데이터를 주고 받을 때 사용하는 방식이다.
- 네트워크 커넥션을 맺을 때 Schema 를 주는 것임.
- 매번 인코딩 된 데이터 하나하나마다 스키마를 같이 보내는 방법은 그렇게 좋지는 않을 것이다. Schema 도 꽤 사이즈가 크니
기존의 Protocol Buffer 와 Thrift 는 코드 상으로 Schema 를 유지하고 있었다면 이는 Schema 를 조회하는 방법이 다양하다.
3.3.4 Dynamically generated schemas
Protocol Buffer 와 Thrift 는 Field Tag 를 지정해줘야하고 아마 수동으로 지정할 것이다.
그에 반해서 Avro 는 Field Tag 없이 스키마를 생성할 수 있다.
그래서 자동으로 스키마를 생성할 수 있다는 장점이 있다.
스키마를 동적으로 매번 생성해야하는 작업을 주기적으로 한다면 Avro 가 나을 수 있다.
- 예시: 데이터베이스의 데이터들을 바이너리 형식으로 dump 를 뜨는 경우.
Avro 의 경우에 인코딩 된 데이터에 적용한 스키마만 알고 있다면 디코딩하는 건 쉽다. 그래서 스키마가 시간이 지나서 변경되더라도 데이터를 관리하는 측면에서는 장점이 있다고 생각한다.
'Distributed System' 카테고리의 다른 글
| 데이터베이스 소개 및 개요 (0) | 2024.04.03 |
|---|---|
| 분산 시스템에서 워크플로우를 관리하는 방법 (0) | 2023.11.23 |
| 분산 시스템에서 데이터를 엑세스하는 방법 (0) | 2023.11.22 |
| 마이크로서비스의 통신 방식 (0) | 2023.11.22 |
| 분산 시스템에서 Strong Consistency 와 Eventually Consistency (0) | 2023.11.22 |