Abstract:
- 이 논문은 SG-ICL (Self-Generated In-Context Learning) 이라는 개념을 소개하는 논문임. In-Context Learning 은 주어진 예시를 통해서 새로운 작업을 이해해서 수행하는 방법을 말함. 하지만 ICL 은 주어진 데모에 크게 의존하는 경향이 있고, 예시를 직접 만들어야한다는 비용이 있음. 이 SG-ICL 은 이러한 문제를 해결하기 위한 방법으로 LLM 이 자동으로 예시를 만들어서 ICl 을 수행하는 기법임.
- 이렇게 하는 것만으로도 Zero-shot 보다 성능이 잘나오고, 실제 예시를 0.6 개 넣은 것만큼의 성능이 나온다고 한다. 또한 ICL 은 외부 예시에 크게 의존적이라 결과가 안정적으로 나오지 않고 분산이 높다는 특징이 있는데, 이 방법은 안정적인 성능이 나온다고 함.
Introduction:
- 언어 모델의 크기가 커짐에 따라서 주어진 작업을 더 잘하기 위한 파인 튜닝 비용이 커지는 문제점이 있음. (조정해야하는 파라미터가 많으니까.)
- 이러한 파인 튜닝 비용이 커지는 문제를 해결하기 위해서 다양한 기법이 등장헀는데, Adapter, LoRA, In-Context Learning (ICL) 등이 있음.
- ICL은 몇 가지 입력-레이블 쌍, 즉 데모스트레이션을 조건으로 하여 주어진 작업을 더 잘 해결할 수 있도록 모델을 학습시키는 방식임.
- 하지만 이 방식은 데모스트레이션의 선택에 크게 의존하며, 어떤 데모스트레이션을 선택하느냐에 따라 성능이 크게 달라진다.
- 많은 연구들이 ICL의 이러한 문제점을 해결하기 위해 노력해왔음:
- 데모스트레이션의 순서 민감성 문제를 다룬 연구(Lu et al., 2021)
- 서로 다른 데모스트레이션 선택에 따른 성능 변동성을 줄이기 위한 컨텍스트 캘리브레이션 방법(Zhao et al., 2021),
- 데모스트레이션 선택을 위한 샘플 검색 방법(Rubin et al., 2021)
- 테스트 입력과 높은 상관관계를 가진 데모스트레이션을 선택하면 성능이 향상된다는 연구(Liu et al., 2022)
- 이러한 기존 연구들에 영감을 받아, 논문은 다음과 같은 두 가지 연구 질문을 제시함:
- 훈련 데이터셋에 대한 의존성을 제거할 수 있을까?
- 입력과 데모스트레이션 간 높은 상관관계를 가진 데모스트레이션을 어떻게 생성할 수 있을까?
- 이를 해결하기 위해서 Self-Generated In-Context Learning (SG-ICL) 라는 새로운 방법을 제안함. 이 방법은 PLM의 생성 능력을 활용하여 데모스트레이션을 생성하는 방식임. (PLM 은 Pre-trained Language Model 을 말함.)
- SG-ICL은 크게 두 가지 단계로 구성된다:
- Self-generation step: 현재 테스트 입력과 클래스 정보를 조건으로 하여 PLM이 각 클래스에 맞는 데모스트레이션을 생성함. 이 과정에서는 간단한 수동으로 설계된 템플릿을 사용해 조건을 부여한다. 이를 통해 생성된 데모스트레이션은 테스트 입력과 높은 상관관계를 가지며, ICL에 적합한 데모스트레이션을 제공함.
- Inference step: 앞서 생성된 데모스트레이션을 사용하여 ICL을 수행하는 단계로, 이 과정에서 더 이상 훈련 데이터나 훈련 데이터에서 선택한 데모스트레이션이 필요하지 않게된다.
SG-ICL Process Overview:

SG-ICL의 구체적인 방법론:
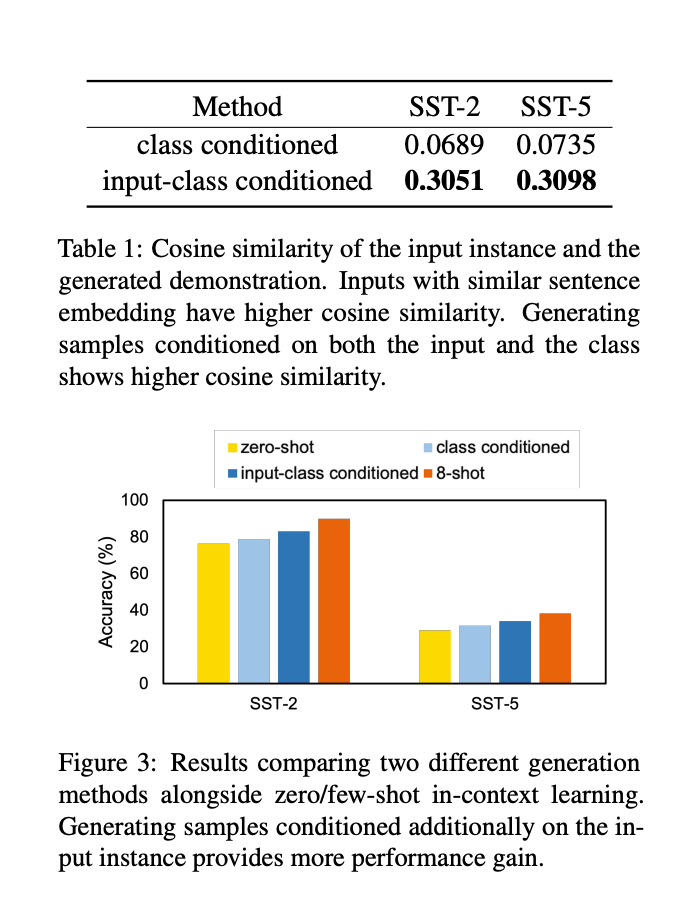
- 예시를 생성할 때 생성할 클래스에만 조건을 거는게 아니라, 입력에도 조건을 거는 방법이 더 낫지 않을까? 라는 생각에 기반해서 실험을 해봤다고 함.
- 입력 인스턴스와 유사한 예시를 ICL 로 주는게 성능이 더 잘나오니까, 단순하게 예시를 생성하는 방법이 아니라 입력과 유사한 예시를 만들도록 하는 방법을 소개하는 것. 유사한 예시를 만들고 이를 추론 단계에서 포함시키면 성능이 더 잘나온다는 건 발견했으니까.
- 다음 표를 보면 예시를 생성할 때 입력을 주었을 때가 주지 않았을 때보다 훨씬 유사한 예시를 생성한다는 걸 볼 수 있고, 성능적으로도 더 나은 걸 볼 수 있음.
- 그리고 SG-ICL 로 생성한 예시 개수에 따라 성능 변화도 비교해보았다고 하는데 7~8 개를 추가하는게 나아보인다고 함.

'Generative AI > Prompt Engineering' 카테고리의 다른 글
| Unified Demonstration Retriever for In-Context Learning (0) | 2024.10.04 |
|---|---|
| Finding Support Examples for In-Context Learning (0) | 2024.10.04 |
| Selective Annotation makes Large Language Models Better Few-shot Learners (0) | 2024.10.03 |
| Large Language Models do In-Context Learning Differently (0) | 2024.10.03 |
| Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations (0) | 2024.10.03 |