Abstarct:
- 대형 언어 모델(LLMs)이 산술 추론 작업에서 단계별 연쇄 추론(Chain-of-Thought, CoT) 프롬프트를 사용하여 좋은 성능을 보였지만, 추론 과정에서 사실적 일관성 (Factual consistency) 를 유지하는데는 어려움을 겪는다고 함.
- 사실적 일관성 (Factual consistency) 이라는 건 LLM이 문제를 이해하고 이를 기반으로 추론하는 과정에서 원래 문제의 조건과 세부 사항을 정확히 반영하는 걸 말함. 그러니까 문제의 요구사항과 조건을 뺴먹지 않고, 원하지 않았던 조건을 또 환각으로 만들어내지 않는 걸 말함.
- RCoT 의 대략적인 작동 과정은 다음과 같다:
- a) 문제 재구성: 먼저 LLM에게 생성된 솔루션을 기반으로 원래 문제를 재구성하도록 요청
- b) 비교 및 감지: 재구성된 문제와 원래 문제를 세밀하게 비교하여 솔루션에서의 사실적 불일치를 찾아냄.
- c) 수정 안내: 감지된 불일치를 바탕으로 세밀한 피드백을 생성하여 LLM이 솔루션을 수정하도록 도움.
- 실험 결과, RCOT는 표준 CoT, Self-Consistency, Self-Refine 등의 기존 방법에 비해 일곱 개의 산술 데이터셋에서 성능 향상을 보였다고 함.
- 그리고 수동으로 작성된 세밀한 피드백은 LLM의 추론 능력을 크게 향상시켰다고 한다. 이는 세밀한 피드백의 중요성을 나타내기도 함.
Introduction:
- LLMs는 조건을 환각(hallucinate)하거나, 조건을 간과(overlook)하거나, 질문을 잘못 해석(misinterpret)하는 경향이 있음.
- 기존 연구들은 CoT의 성능을 향상시키기 위한 다양한 방법을 제안했지만, 사실적 일관성 문제를 직접적으로 다루는 연구는 부족했음. 가장 관련 있는 연구로는 Self-Verification이 있는데, 이는 조건과 답변을 교환하여 답변의 정확성을 검증하지만, LLM이 솔루션을 수정하도록 유도하는 세밀한 피드백을 제공하기는 어려웠음.
- 이에따라 저자들은 Reversing Chain-of-Thought (RCoT) 라는 기법을 소개함. RCoT는 LLM이 생성한 솔루션에서 사실적 불일치를 감지하고 수정하는 데 초점을 맞추며, 특히 조건 환각, 조건 간과, 질문 오해에 대한 문제를 해결한다.
- RCoT의 주요 과정은 다음과 같음:
- 문제 재구성: LLM이 생성한 솔루션을 기반으로 새로운 문제를 재구성
- 불일치 감지: 재구성된 문제와 원래 문제를 세밀하게 비교하여 사실적 불일치를 감지
- 수정 안내: 감지된 불일치를 세밀한 피드백으로 구성하여 LLM이 솔루션을 수정하도록 도움.
- 실험 결과:
- RCoT는 GSM8k, AQuA, SVAMP, AddSub, ASDiv, Date, SingleEq 등 7개의 산술 추론 데이터셋에서 기존의 강력한 베이스라인보다 뛰어난 성능을 보임.
- 인간이 작성한 세밀한 피드백은 LLM의 추론 능력을 크게 향상시켰으며, 예를 들어 ChatGPT는 GSM8k에서 94.6%의 정확도를 보였다고 함.
- 이는 자동으로 생성된 피드백과 인간이 작성한 피드백 간의 차이를 보여주며, 세밀한 피드백의 자동 생성 방법을 더욱 탐구할 필요성을 강조하기도 함.
조건 간과의 예시:
문제: 오늘의 회의는 내일인 1924년 10월 16일 오전 11시로 재조정되었습니다. 오늘로부터 1년 전의 날짜는 언제입니까?
ChatGPT의 연쇄 추론:
현재 날짜는 1924년 10월 16일입니다. 오늘로부터 1년 전의 날짜를 찾으려면 현재 연도에서 1년을 빼면 됩니다. 따라서 정답은 1923년 10월 16일입니다. ✗- 여기서 모델은 “내일인 1924년 10월 16일”이라는 중요한 조건을 간과하고, 현재 날짜를 잘못 파악하여 오답을 냈음.
질문 오해의 예시:
문제: 동굴은 1218피트 깊이이고 그들은 이미 849피트에 있습니다. 그들이 17의 속도로 이동하고 있다면, 동굴의 끝까지 얼마나 더 가야 합니까?
ChatGPT의 연쇄 추론:
먼저 현재 위치에서 동굴의 끝까지 얼마나 남았는지 계산해야 합니다...... 따라서 그들은 동굴의 끝까지 369피트를 더 내려가야 합니다. 다음으로, 그들이 그 거리를 17의 속도로 이동한다면 얼마나 걸리는지 계산해야 합니다...... 따라서 동굴의 끝까지 도달하는 데 22의 시간이 걸릴 것입니다. ✗- 여기서 모델은 원래 질문인 “얼마나 더 가야 합니까?“에 대한 답변을 했지만, 추가로 “얼마나 시간이 걸리는지”를 계산하여 오답을 내었음.
조건 환각의 예시:
문제: 나무 다리는 최대 5000파운드를 견딜 수 있습니다. 동일한 상자 각각 15파운드를 실은 배달 트럭이 다리를 건널 것입니다. 운전자와 빈 트럭의 합산 무게는 3755파운드입니다. 다리의 중량 한도를 초과하지 않으면서 트럭에 최대 몇 개의 상자를 실을 수 있습니까?
ChatGPT의 연쇄 추론:
먼저 운전자와 빈 트럭의 무게를 최대 중량에서 빼야 합니다...... 각 상자의 무게가 16파운드(내용물 15파운드와 상자 1파운드)라고 가정하면...... 따라서 트럭에 최대 77개의 상자를 실을 수 있습니다. ✗- 여기서 모델은 문제에 없는 “상자의 무게가 1파운드 더 있다”는 조건을 환각하여 잘못된 답변을 도출함.
Related Work:
- 사실적 일관성 문제를 해결하는 관련 연구로 Self-Verification(Wang et al., 2023), REFINER(Paul et al., 2023), Reflexion(Shinn et al., 2023) 등이 있었지만 각각 한계가 있었음:
- Self-Verification:
- 이진적인 피드백만 제공하여 세밀한 수정 지침을 주기 어려움.
- REFINER:
- 외부에서 훈련된 모델이 필요함.
- Reflexion:
- 환경 피드백이 필요한데, 이는 산술 추론 분야에서 얻기 어려움.
- 산술 추론 분야는 수학적 연산과 논리적 사고를 필요로 하는 문제를 말함. (e.g "어떤 사람이 하루에 5개씩 사과를 먹고 있다면, 일주일 동안 총 몇 개의 사과를 먹을까?")
- (Reflexction 의 환경 피드백은 뭐고, 왜 이게 산술 추론 분야에서 얻기 어려울까? 논문을 봐야할듯)
- 이에 비해 RCoT는 LLM 자체를 활용하여 사실적 일관성에 대한 세밀한 피드백을 생성하고, 중간 추론 단계의 오류를 해결함.
- Self-Verification:
- RCoT는 리버스 엔지니어링(reverse engineering) 개념에서 영감을 받았다고 함. 리버스 엔지니어링은 머신러닝에서 다양한 용도로 사용된다:
- 모델 프라이버시 평가: 모델의 프라이버시 안전성을 평가하기 위해 역방향 방법을 사용
- 모델 인버전: 신경망의 입력 정보를 재구성하거나 내부 작동 방식을 밝히는 데 사용
- 하이퍼파라미터 추정: 모델의 하이퍼파라미터나 구조를 추정하는 데 활용
- 이러한 연구들은 주로 딥러닝 모델의 내부를 해석하는 데 초점을 맞추고 있지만, RCoT는 LLM이 생성한 솔루션에서 발생하는 사실적 불일치를 자동으로 감지하고 수정하는데 초점을 맞춤.
- 리버스 엔지니어링은 끝에서부터 거슬러올라가면서 문제의 원인을 파악하거나, 시스템의 동작 과정을 이해하는 기법이다. 이것과 같이 RCoT 는 모델의 답변에서 시작에서 사실적 불일치를 검증하는 기법임.
Reversing Chain-of-Thought (RCoT):

- RCoT 의 목적은 사실적 불일치(factual inconsistency) 를 감지하고 수정하여 LLM의 추론 능력을 향상시키는 거임.
- 구체적으로 다루는 사실적 불일치의 유형은 다음과 같다:
- 조건 환각(condition hallucination): 문제에 없는 조건을 모델이 생성하는 경우.
- 조건 간과(condition overlooking): 문제의 중요한 조건을 모델이 놓치는 경우.
- 질문 오해(question misinterpretation): 모델이 질문을 잘못 이해하는 경우.
- RCoT의 전체 과정:
- a) 문제 재구성(Problem Reconstruction):
- LLM이 생성한 솔루션 c 를 기반으로 원래 문제 Q 를 재구성하여 \hat{Q} 를 만듬
- 이는 모델이 문제를 제대로 이해했는지 검증하는 단계
- 이를 위해 수동으로 작성한 지시문과 인-컨텍스트 예제를 사용한 재구성 프롬프트를 제공한다.
- b) 세밀한 비교(Fine-grained Comparison):
- 원래 문제 Q 와 재구성된 문제 \hat{Q} 를 세밀하게 비교하는 단계
- 이 과정을 통해 조건 환각, 조건 간과, 질문 오해를 감지한다.
- 원래 문제 Q 와 재구성된 문제 \hat{Q} 를 단순하게 비교하는 건 효과적이지 않을거임. 이미 많은 정보를 포함하고 있으니, 따라서 문제를 체계적으로 비교하기 위해서 분해해서 비교함. 즉 LLM에게 Q 와 \hat{Q} 를 각각 조건의 리스트 L_Q = [L_1^Q, \dots, L_m^Q] , L_{\hat{Q}} = [L_1^{\hat{Q}}, \dots, L_n^{\hat{Q}}] 로 분해하도록 요청함.
- 이렇게 분해한 후 Q 와 \hat{Q} 의 차이를 찾기 위해, 두 조건 리스트 L_Q 와 L_{\hat{Q}} 가 동일한지 확인한다.
- 구체적으로 각 L_i^Q 에 대해 L_{\hat{Q}} 로부터 추론 가능한지 LLM에게 묻는다. 만약 추론이 불가능하다면 만들어진 솔루션이 조건이 간과되었을 수 있음.
- 그리고 반대로 각 L_j^{\hat{Q}} 에 대해 L_Q 로부터 추론 가능한지 묻는다. 만약 불가능하다면 환각된 조건일거임.
- 이런식으로 비교를 함.
- 그리고 질문 비교를 한다. LLM이 질문을 잘못 해석할 수 있으므로 Q 와 \hat{Q} 에서 묻는 질문이 동일한지 비교함. 이를 통해서 질문을 잘못 해석한게 있는지 찾아낸다. 일반적으로 문제당 하나의 질문만 있으므로, 이 비교는 한 번만 수행하면 됨.
- c) 세밀한 피드백 및 수정(Fine-grained Feedback and Revision):
- 감지된 사실적 불일치를 기반으로 세밀한 피드백을 생성
- 이 피드백을 통해 LLM이 솔루션을 수정하도록 안내한다.
- 만약 세밀한 비교를 통해 사실적 불일치가 감지되지 않는다면, 원래 LLM이 생성한 솔루션이 올바르다고 가정함.
- 반대로, 사실적 불일치가 감지되었다면, LLM이 솔루션을 수정할 수 있도록 세밀한 피드백을 제공한다.
- 이 피드백은 다음과 같은 구조로 구성됨:
- 첫째, 솔루션이 정확하지 않음을 명시
- 둘째, 감지된 사실적 불일치를 상세히 나열. 이는 어떤 조건이 간과되었는지, 어떤 조건이 환각되었는지, 또는 질문을 어떻게 오해했는지를 구체적으로 지적.
- 셋째, LLM에게 이러한 불일치를 고려하여 솔루션을 수정하도록 요청
- a) 문제 재구성(Problem Reconstruction):
RCoT - Prompt Template:

실험 설정 및 결과 분석:
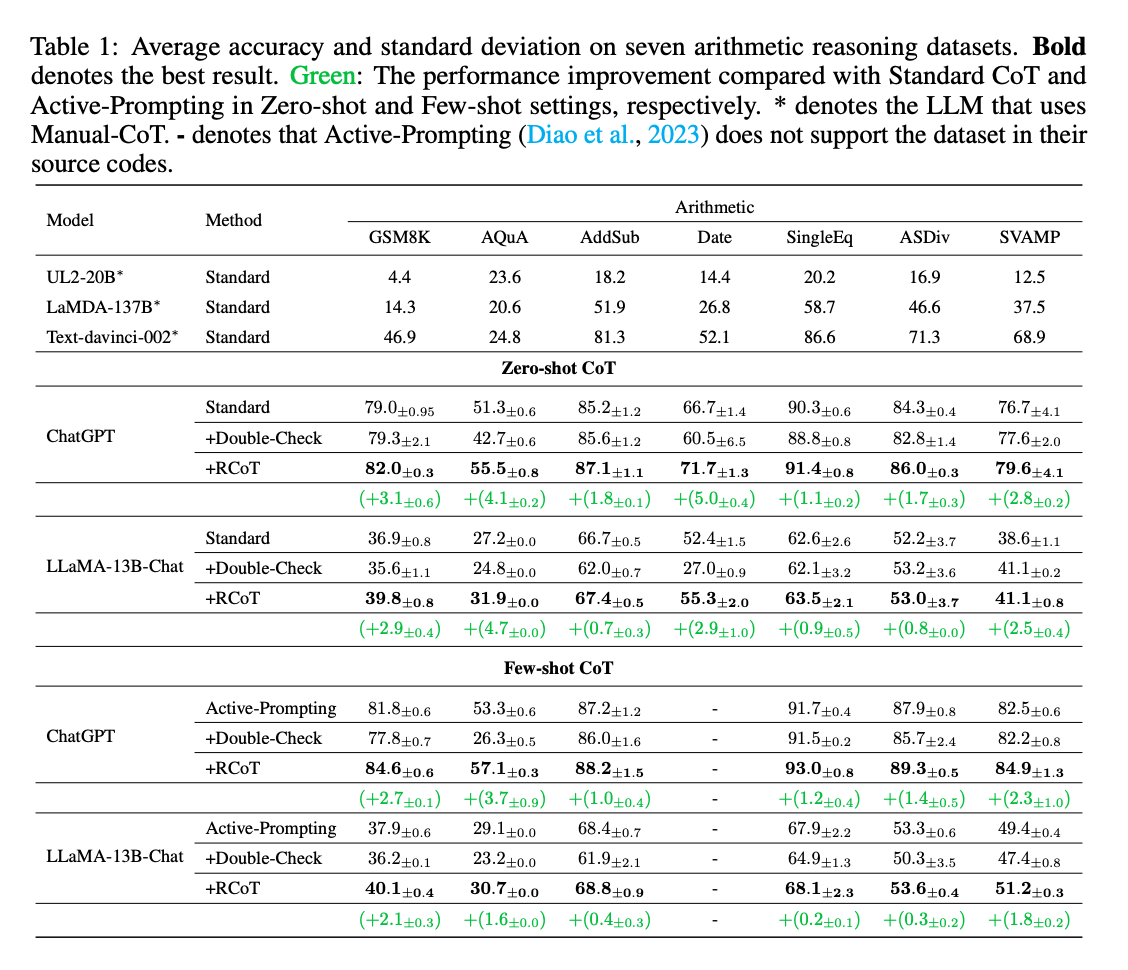
- 실험의 주요 목표:
- RCoT가 산술 추론에 도움이 된다는 것: 자동으로 조건 환각, 조건 간과, 질문 오해를 감지하고 수정함으로써 LLM의 산술 추론 능력을 향상 시킬 수 있는지
- 사실적 일관성에 대한 세밀한 피드백이 중요하다는 것: LLM이 스스로 솔루션을 수정하는 데 있어 세밀한 피드백이 핵심적인 역할을 하는지
- 세밀한 비교가 고품질의 세밀한 피드백을 구성하는 데 필수적이다는 것: 정확한 오류 감지와 수정 지침을 제공하기 위해서는 세밀한 비교 과정이 필요한 지
- 실험 설정(Experiment Setting):
- 난이도가 다양한 7개의 산술 데이터셋을 사용하여 RCoT를 평가
- GSM8k (고급 산술 문제), AQuA (산술 문제의 질의 응답), SVAMP (산술 문제 변형), ASDiv (다양한 산술 문제), Date (날짜 계산 문제), SingleEq (단일 방정식 문제)
- 사용된 모델로 ChatGPT 와 LLaMA-13B-Chat(오픈소스)
- 비교 대상 방법들:
- Chain-of-thought (CoT)
- Active-Prompting
- Double-Check: LLM에게 자신의 답변을 확인하도록 요청하지만, 답이 맞는지 여부를 지적하지는 않는 방법
- Self-Consistency (SC)
- Self-Refine (Madaan et al., 2023): 반복적인 피드백과 수정 과정을 통해 답변을 개선하는 것
- 실험 결과 내용:
- RCoT는 7개의 산술 데이터셋에서 일관되게 표준 CoT와 Double-Check 방법보다 뛰어난 성능을 보임.
- RCoT는 복잡한 추론을 요구하는 어려운 작업에서 더 큰 이점을 제공함.
- RCoT는 SC와 유사한 성능을, 약 1/3의 비용으로 달성함.
- RCoT와 SC를 결합하면, 모든 베이스라인을 능가하여 7개의 산술 데이터셋에서 84.5%의 높은 정확도를 달성함.
- 실험 결과는 Self-Refine가 산술 추론에 적합하지 않다는 기존의 결론을 확인할 수 있었음
- Self-Refine가 두 번째 수정 이후 솔루션이 올바르다고 주장하는 경향이 있다고 함.
- 피드백이 또 중요한 역할을 한다고 함. RCoT 로 감지한 사실적 불일치를 LLM 에게 알리지 않으면 성능이 떨어진다는 이유, 또 사실적 불일치 여부와 관계없이 “You should double-check your answer.“ 라는 메시지만 주게되면 성능이 여기서 더 떨어진다고 함.
- 문제를 재구성한 이후 비교할 떄도 그냥 비교하는 것보다는 세밀하게 하나씩 비교하는게 훨씬 높은 성능을 보여준다고 함. 문제 분해와, 조건 비교, 질문 비교 이 모든 것들이 중요하다고 한다.
- 사실적 불일치에서 주로 하는 실수는 Hallucinating 이였고, 잘 찾는 것도 Hallucinating 이 였음.
'Generative AI > Prompt Engineering' 카테고리의 다른 글
| Large Language Models are Better Reasoners with Self-Verification (0) | 2024.11.14 |
|---|---|
| Reflexion: Language Agents withVerbal Reinforcement Learning (0) | 2024.11.14 |
| Self-Refine: Iterative Refinement with Self-Feedback (0) | 2024.11.13 |
| Language Models (Mostly) Know What They Know (0) | 2024.11.13 |
| Large Language Models can self-improve (0) | 2024.11.13 |