Abstract:
- 언어 모델의 추론 능력을 향상시키기 위한 새로운 방법인 DIVERSE(Diverse Verifier on Reasoning Step)를 소개함.
- 기존에는 CoT 기법이 주로 활용되었음.
- 여기서 제안하는 DIVERSE 기법의 특징은 다음과 같다:
- 다양한 프롬프트 생성: 동일한 질문에 대해 여러 가지 추론 경로를 탐색할 수 있도록 다양한 프롬프트를 생성해서 추론을 생성
- 검증기를 통한 필터링: 가중 투표 방식을 사용하여 잘못된 답변을 걸러내는 검증기(Verifier) 를 적용
- 단계별 검증: 전체 추론 체인이 아닌 각 추론 단계를 개별적으로 검증하여 정확도를 높임.
- 이 기법의 결과는 다음과 같음:
- 최신 언어 모델인 code-davinci-002를 사용하여 DIVERSE를 평가한 결과, 여덟 개의 추론 벤치마크 중 여섯 개에서 새로운 최고 성능을 달성했다고 함.
- GSM8K에서의 문제 해결률이 74.4% 에서 83.2% 로 향상됨.
Introduction:
- 이전에는 LLM 추론 능력을 향상 시키는 기법으로 CoT + SC 조합을 이용했었음.
- 이 논문에서 제안하는 DIVERSE 기법은 단일 프롬프트에서 샘플링하는 것 뿐 아니라 프롬프트 자체를 다양화하여 여러 가지 추론 경로를 탐색하는 방법임.
- 이는 서로 다른 프롬프트가 다양한 사고 방식을 유도할 수 있으며, 올바른 답변은 이러한 변화에 대해 견고해야 한다는 가설에 기반한다. ("모든 길은 로마를 통한다")
- 이렇게 생성된 각 추론 경로는 검증기(verifier) 를 통해서 품질이 평가됨. 아무래도 모든 추론 경로가 동일하게 신뢰되는 건 아니기 때문임.
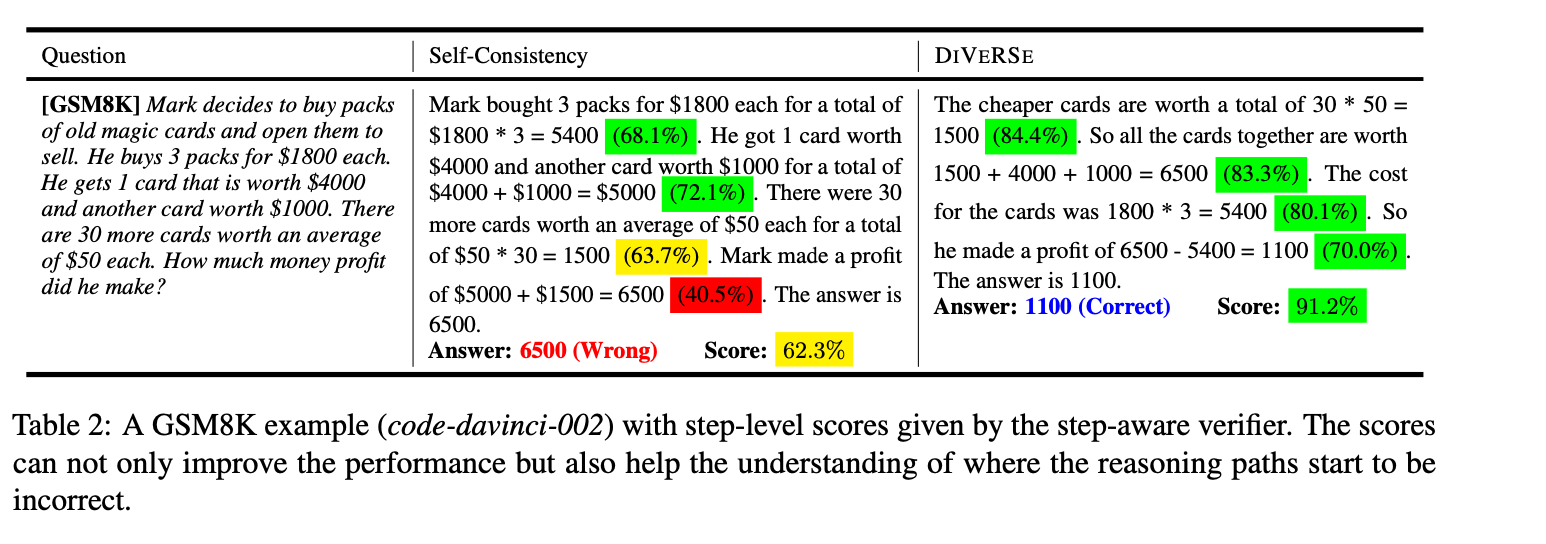
- 이런 검증기 뿐 아니라 단계 인식 검증기 (Step-Aware Verifier) 를 사용해서 각 추론 경로의 단계를 세밀하게 평가함.
- 즉 두가지의 검증기(verifier) 를 사용한다. 검증기(verifier) 추론 경로 중 더 신뢰되는 걸 가중 투표(weighted voting) 하는 방식으로 사용되고, 단계 인식 검증기 (Step-Aware Verifier) 는 추론 경로의 각 단계를 세밀하게 평가하는 방식으로 사용된다.
- 이 기법의 실험 결과는 유의미하게 성능 향상을 이끌었다고 함:
- GSM8K: 74.4% → 83.2%
- AsDiv: 81.9% → 88.7%
- MultiArith: 99.3% → 99.8%
- SVAMP: 86.6% → 87.0%
- SingleEq: 79.5% → 94.9%
- CLUTRR: 67.0% → 95.9%
- 연구 데이터는 공개적으로 이용 가능하며, https://github.com/microsoft/DiVeRSe 를 참고.
Diverse Verifier on Reasoning Step:
- Diverse Prompt:
- 언어 모델로부터 보다 다양한 추론 경로를 이끌어내기 위해 다양한 프롬프트를 사용함.
- Self Consitency 는 모든 프롬프트에 사용할 수 있는 범용성이 있지만 생성된 추론 경로의 다양성을 제한하기도 함.
- 그래서 여기서 소개하는 Diverse Prompt 는 각 질문마다 M₁개의 서로 다른 프롬프트를 무작위로 선택해서 사용함.
- 그리고 각 프롬프트에 대해 샘플링 디코딩을 사용하여 M₂개의 추론 경로를 생성한다.
- 결과적으로는 질문마다 M = M₁ × M₂개의 다양한 추론 경로를 얻을 수 있음.
- 이렇게 다양한 경로로 생성되도 "결과적으로 정답은 같을 것", "모든 길은 로마를 통한다" 라고 가정하고 이렇게 탐색을 하는거임. (교차 검증을 통해서 정확도를 높이는 것)
- Voting Verifier:
- 여러 추론 경로로부터 더 나은 최종 답변을 도출하기 위해 훈련된 투표 검증기 (Voting Verifer) 를 사용함.
- 질문과 후보 추론 경로를 입력으로 받아, 해당 추론 경로가 올바른 답변으로 이어질 확률을 추론하는 역할을 한다.
- 훈련에 사용할 데이터로는 각 학습용 질문에 대해 연쇄적 사고(chain-of-thought) 추론을 사용하여 여러 후보 추론 경로를 생성한 것을 사용한다.
- 레이블링으로는 최종 답변이 실제 정답과 일치하는 추론 경로는 긍정적(positive) 예시로 간주해서 사용하고, 그렇지 않은 추론 경로는 부정적(Negative) 예시로서 사용한다.
- 이전 SC 에서는 단순한 다수결 투표를 이용해서 다양한 예측을 결합했었음. 이 방법은 대부분의 추론 경로가 잘못된 경우, 소수의 올바른 추론 경로를 반영하지 못하는 문제점도 있다.
- 여기서 제안하는 투표 검증기(voting verifier) 는 각 경로의 품질 (신뢰도) 를 고려해서 가중 투표하는 식으로 진행됨.
- 다양한 추론 경로에서 나오는 답변을 후보 답변으로 고려하고, 각 답변의 확률을 곱해서 더한다. 이렇게해서 각 후보 답변의 점수가 계산되는데 이 점수가 가장 높은게 최종 답변으로 선택됨.
- 예시로 보자:
- 질문: “7 × 8의 결과는 무엇인가요?”
- 다양한 추론 경로:
- a) 추론 경로: “7 × 8은 54입니다.”, 최종 답변: 54, 검증기 확률: 0.2
- b) 추론 경로: “7과 8을 곱하면 56이 됩니다.” , 최종 답변: 56, 검증기 확률: 0.9
- c) 추론 경로: “계산하면 7 × 8 = 54입니다.”, 최종 답변: 54, 검증기 확률: 0.1
- d) 추론 경로: “7에 8을 곱하면 56입니다.” , 최종 답변: 56, 검증기 확률: 0.85
- e) 추론 경로: “7 곱하기 8은 54입니다.” , 최종 답변: 54, 검증기 확률: 0.05
- 후보 답변: 54, 56
- 54 의 점수: 0.2 + 0.1 + 0.05 = 0.35
- 56 의 점수: 0.9 + 0.85 = 1.75
- 최종 답변: 56
- 단순히 답변의 빈도로 투표하는 것이 아니라, 각 추론 경로의 신뢰도를 반영하여 투표함.
- 따라서 소수의 올바른 추론 경로가 있더라도, 검증기의 높은 확률로 인해 최종 답변에 선택될 수 있음.
- 이는 다수의 잘못된 추론 경로로 인해 올바른 답변이 무시되는 문제를 완화할 수 있다.
- Step-aware Voting Verifier:
- 투표 검증기를 더욱 향상시키기 위해 각 추론 단계의 정확성을 검증하는 역할임.
- 이것도 훈련되는 Verifier 이다.
- 추론 경로는 여러 단계로 구성될 수 있음. 일부 단계는 틀릴 수 있고, 잘못된 추론 경로에서도 일부 단계는 여전히 유용할 수도 있음.
- 이러한 관찰을 기반으로 각 단계의 정확성을 활용하여 기존의 투표 검증기를 단계 인식 투표 검증기로 확장하는 기법임.
- 단계별 정확성을 모델에 반영하기 위해, 확장된 손실 함수를 도입함:
- L = L0 + α · L1,
- L: 전체 손실 함수
- L0: 기존의 손실 함수로, 전체 추론 경로의 정확성을 평가함.
- L1: 단계별 보조 손실 함수로, 각 추론 단계의 정확성을 평가함.
- α: L0 와 L1 사이의 균형을 조절하는 하이퍼파라미터.
- 확장된 손실 함수는 전체 추론 경로의 정확성과 각 단계별 추론 경로의 정확성을 결합한 값임.
- Step-aware Voting Verifier 를 훈련시키기 위해선 각 추론 경로의 단계가 모두 올바른지, 아니면 잘못된게 있는지 평가해서 레이블을 생성하는 과정도 필요하다:
- 추론 경로에서 한 단계가 잘못되었다면, 그 이후 단계는 모두 잘못된 단계로 간주할거임.
- 양성 (Positive) 추론 경로는 최종 답변이 정답과 일치하는 추론 경로를 말함. (인간 평가자를 통해서 올바른 최종 답변을 가진 추론 경로는 중간 단계도 모두 올바름을 확인 했다고 함.)
- 부정적 추론 경는 최종 답변이 정답과 일치하지 않는 추론 경로를 말함.
- 최종 정답의 일치 유무로 양성 추론 경로와 부정적 추론 경로를 구별한다.
- 부정적 추론 경로는 양성 추론 경로와 비교한다. 의미적으로 동등하다면 (같은 중간 결과를 생성하거나, 논리적으로 동일한 의미를 가지거나) 각 단계는 유효함을 판단함. 같은 의미를 가진 단계가 없다면 그 이후 모든 단계는 잘못된 것으로 간주한다.
- 이런 판단하는 모델은 roberta-large-mnli 모델을 사용했다고 함.
실험 결과:
- Table 1 은 전체적인 실험 결과를 보여주며, DIVERSE 기법을 두 가지 주요 베이스라인과 비교:
- Greedy Decode: 단일 추론 경로를 탐욕적으로 디코딩하는 방법
- Self-Consistency: 100개의 추론 경로를 샘플링한 후, 다수결 투표를 통해 최종 답변을 선택하는 방법
- DIVERSE는 최근의 강력한 베이스라인보다 유의미하고 일관된 성능 향상을 가져왔음.

결과 분석:
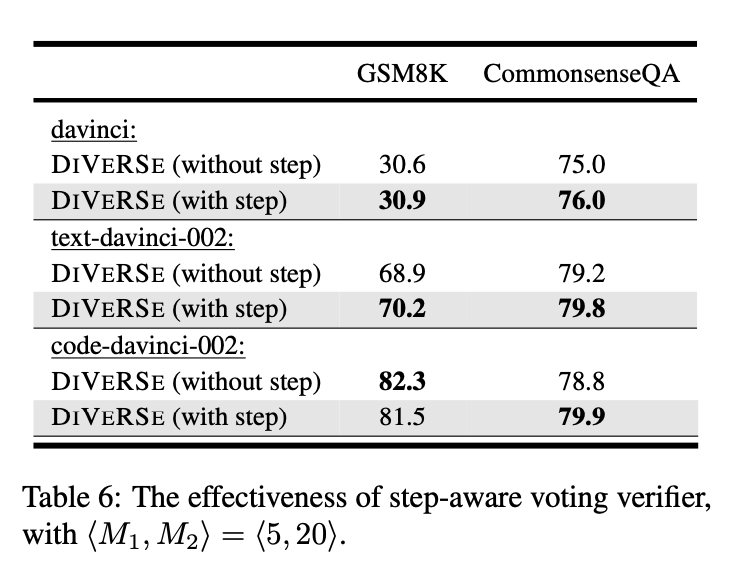
- 다양한 프롬프트와 추론 경로를 함께 다양화함으로써(M₁ = 5개의 프롬프트, M₂ = 20개의 추론 경로), Wang 등(2022c)의 샘플링 디코딩 접근법(M₁ = 1개의 프롬프트, M₂ = 100개의 추론 경로)보다 일관되게 성능이 향상되었다고 함. (이거는 둘 다 다수결 투표 매커니즘만 사용했을 떄도 성능 차이가 났다고 함.)
- 다양한 추론 경로로부터 합의를 도출하기 위해 세 알고리즘을 비교해봤다고 함 (다수결 투표(majority voting), 검증기(verifier), 투표 검증기(voting verifier)) 여기서 투표 검증기가 가장 성능이 좋았다고 한다.
- 단계 인식 검증기를 사용해보기도 하고, 사용안해보기도 해봤다고 함. 그렇게 큰 성능 차이는 나지 않지만 대부분의 실험에서 단계 인식 검증기를 사용하면 성능이 향상된다고 함.
- 얼마나 다양한 출력이 필요한가?:
- 적어도 50개의 추론 경로를 사용하는 것이 성능 향상에 효과적이며, DIVERSE 기법은 다양한 출력 수에 걸쳐 안정적으로 우수한 성능을 보였다고 함.
- 얼마나 많은 학습 데이터가 필요한가?
- DIVERSE는 검증기(verifier)를 훈련하기 위해 추론 경로가 포함된 데이터셋이 필요함.
- 학습 데이터의 크기를 75% 감소(1,000개에서 250개로) 시켜도, 성능은 약 2% 정도만 감소했다고 함.
- 이는 DIVERSE가 비교적 적은 양의 데이터로도 효과적으로 작동함을 보여준다.
- 동일한 추론 경로를 사용할 때 투표 검증기는 다수결 투표보다 높은 성능을 보여줌.
- 투ㅍ를 사용하지 않은 검ㅁ증기는 성능이 크게 감소했다고 함.
- 예시 수의 영향:
- GSM8K 데이터셋에서 k = 3, 5, 8개의 예시를 사용하여 실험을 해봤다고 함.
- 프롬프트에 8개의 예시를 포함하면 정확도가 83.2% 까지 올랐다고 한다.
- 프롬프트에 더 많은 예시를 포함하면 모델의 성능이 향상되며, 특히 8개의 예시를 사용할 때 가장 높은 정확도를 달성했다고 한다.
Limitations and Conclusion:
- DIVERSE는 다양한 프롬프트를 구성하기 위해 잘 주석된 추론 경로를 가진 더 많은 레이블된 데이터가 필요함.
- DIVERSE가 최종 답변의 정확성을 크게 향상시킬 수 있지만, 언어 모델이 생성한 추론 경로가 100% 신뢰할 수 있다고 보장 불가.
- 이는 추론(inference)에 더 많은 시간과 비용이 소모됨.
'Generative AI > Prompt Engineering' 카테고리의 다른 글
| Learn DSPy using Docs (0) | 2024.11.28 |
|---|---|
| To CoT or Not to CoT? Chain-of-Thought Helps Mainly on Math and Symbolic Reasoning (0) | 2024.11.17 |
| Answering Questions by Meta-Reasoning over Multiple Chains of Thought (0) | 2024.11.16 |
| Large Language Models Cannot Self-Correct Reasoning Yet (0) | 2024.11.16 |
| Universal Self-Consistency for Large Language Model Generation (0) | 2024.11.16 |