https://www.anthropic.com/research/building-effective-agents
What are agents?:
- 에이전트에 대한 정의에 대해 고민해보자. 어떤 사람들은 에이전트를 “오랜 시간 동안 자율적으로 작동하며, 복잡한 업무를 달성하기 위해 여러 도구를 사용하는 완전 자율 시스템”이라고 봄.
- 또 다른 사람들은 “미리 정해진 워크플로우(업무 절차)에 따라 움직이는 시스템”도 에이전트라고 ,ㅁ
- Anthropic 에서는 Agent 를 나눠서 폭넓게 “워크플로우”와 “에이전트”라는 두 형태의 시스템으로 보고, 이 둘에 대해 Agentic system 이라고 부른다 (이 둘은 시스템 설계 구조 측면에서 좀 다르다고 함):
- 워크플로우(workflows):
- 미리 정해진 코드 로직이나 절차에 따라 LLM(대규모 언어 모델)과 도구들이 조율되는 시스템을 가리킴
- 즉, 시스템의 처리 흐름이 사전에 정해져 있고, LLM이 어떤 도구를 언제 어떻게 사용하는지도 어느 정도 결정되어 있음.
- 에이전트(agents):
- 반면에, LLM이 스스로 어떤 과정을 거칠지를 동적으로 결정하고, 필요한 도구도 자율적으로 선택・사용하면서 작업을 수행하는 시스템을 가리킴.
- 즉, LLM이 작업을 진행하는 “방법”과 “순서” 전반을 통제하고, 그 과정에서 어떤 도구를 쓸지, 어떤 단계를 거칠지도 자체적으로 결정할 수 있음.
- 워크플로우(workflows):
- 이후 부록(Appendix 1)에서는 이 두 시스템을 활용해 고객들이 실제로 가치를 얻고 있는 사례를 소개하겠다고 함.
When (and when not) to use agents:
- 가장 단순한 솔루션을 우선적으로 택하라:
- 애플리케이션을 구축할 때는 최소한의 복잡성으로 원하는 기능을 달성하는 것이 중요하다.
- 먼저 요구사항을 파악하는게 가장 중요.
- 에이전트적 시스템은 편리해 보이지만, 복잡성을 높여서 “추가적인 비용과 지연(latency)을 감수해야 하는 경우” 도 생김.
- 따라서 에이전트 시스템이 무조건 좋은건 아님.
- 에이전트적 시스템이 주는 트레이드오프(Trade-off):
- 에이전트적 시스템(워크플로우, 혹은 에이전트)은 “더 나은 업무 수행 능력”을 제공할 수 있지만, 그 대가로 “지연 시간(latency)과 비용(cost)”이 늘어날 수 있음.
- 워크플로우 vs. 에이전트 선택 기준:
- 워크플로우:
- 미리 정의된 절차가 있으므로, “예측 가능하고 일관성 있는 결과”를 낼 수 있음.
- 구체적이고 반복적인 업무(잘 정의된 작업)에 적합함.
- 에이전트:
- LLM이 자유롭게 의사결정을 내리고 도구를 활용하므로, “유연성" 이 높음.
- 복잡한 시스템에서 모델이 주도적으로 설계해야 하는 경우 적합함.
- 사람과 같이 더 발전해야 하는 시스템, 단발성이 아닌 시스템도 에이전트가 더 나을듯 (지식과 경험을 축적할 수 있으니)
- 에이전트 시스템은 작업의 결과물이 분산이 클 거 같은데?
- 에이전트 시스템도 일종의 작업 처리 가이드라인을 제공해줄 수 있을거임. (지식을 참고하는 것으로부터)
- 그리고 CoT 기반의 계획을 작성하고, 평가하고, 선택하고 하는 매커니즘으로 극복가능하다.
- 모델을 파인튜닝해서 지식을 전가하는 방법도 있고, 계획을 세우는 프롬프트를 보다 자세하게 적는 것도 도움이 될 것.
- 에이전트 시스템의 의사결정이 사람이 미리 설계한 워크플로우보다 뛰어난 경우가 있을까?
- 바로 위의 답을 보면 충분히 가능할듯. 이렇게되면 워크플로우 설계가 훨씬 간단한게 아니라면 Agent 를 도입하는게 나을듯.
- 워크플로우:
When and how to use frameworks:
- 에이전트 시스템 구현에 도움이 되는 다양한 프레임워크:
- LangGraph (LangChain)
- Amazon Bedrock AI Agent Framework
- Rivet (드래그 앤 드롭 방식으로 LLM 워크플로우를 만들 수 있는 GUI)
- Vellum (또 다른 GUI 툴로 복잡한 워크플로우를 빌드・테스트 가능)
- 이러한 프레임워크들은 LLM 호출, 툴 정의 및 파싱, 여러 단계(Chaining) 연결 등 반복적・저수준 로직을 간소화해줌.
- 프레임워크 사용 시 주의점:
- 추상화로 인해 디버깅이 어려움.
- 불필요한 복잡성을 유발할 수 있음.
- 먼저 LLM API 를 직접 이용해보는게 도움이 될 수 있음.
- 프레임워크가 제공하는 기능을 100% 파악하기 전에는, 라이브러리 내부 동작(“under the hood”)에 대한 잘못된 가정을 하게 되어 오류를 일으키기 쉬움
Building blocks, workflows, and agents
실제 운영환경(프로덕션)에서 자주 쓰이는 에이전트 시스템 패턴을 단계별로 설명할거임:
- 기본 빌딩 블록 – 강화된(augmented) LLM
- 간단한 합성(Compositional) 워크플로우
- 자율 에이전트(Autonomous agents)
Building block: The augmented LLM:

- Agent 시스템의 기본 요소인 강화된(augmented) LLM 에 대해 먼저 보자.
- 에이전트 시스템을 구성할 때, 가장 핵심이 되는 요소는 “단순한 LLM”이 아니라, 검색/도구/메모리 기능이 결합된 강화된(augmented) LLM 임.
- 이 LLM은 스스로 필요에 따라 검색 쿼리를 생성해 정보를 찾거나, 특정 도구를 활용하거나, 필요한 정보를 메모리에 저장하는 등의 행동을 할 수 있음.
- LLM 의 한계를 극복할 수 있음. (계산 능력, 최신 정보 조회와 이를 바탕으로 환각 감소, 맥락 정보 잊음 등)
- Anthropic의 Model Context Protocol을 예시로 언급하는데, 이는 외부 도구나 서비스와 LLM을 간단히 연결하기 위한 규약(프로토콜) 도 언급함. 이걸 쓰면 제3서드파티 도구도 LLM 과 연결하기 쉬울거라고 함.
Workflow: Prompt chaining:
- 작업을 여러 단계로 쪼개서 각 단계마다 LLM을 호출하고, 중간 단계에서 검증(gate) 과정을 둠으로써 정확도를 높이는 방법.
- 아무래도 LLM 은 한번에 하나의 작업만 하면 좋으니까
- 즉 Decomposed 처리를 할 수 있고, LLM 출력이 제대로 된 결과인지 확인하는 Gate 를 둬서 작업의 정확도를 높일 수 있음.
- 언제 Prompt chaining을 쓰면 좋을까?
- 작업이 명확하게 단계별로 나누어질 수 있을 때
- 각 단계에서 독립적인 검증이 가능할 때
- 최종 작업의 정확도가 지연시간보다 중요할 때
- 예시:
- 마케팅 카피 작성 후 번역:
- 1단계: 카피를 영어로 작성 (LLM 호출)
- 2단계: 작성된 카피의 문체, 용어 등을 검증 (프로그래밍적 게이트)
- 3단계: 검증된 카피를 다른 언어로 번역 (LLM 호출)
- 문서 구조(아웃라인) 작성 → 검증 → 본문 작성:
- 1단계: 주제에 대한 개요(아웃라인) 작성 (LLM 호출)
- 2단계: 개요를 기준으로 내용이 빠진 부분은 없는지, 일정 기준에 부합하는지 등 검사 (프로그래밍 로직)
- 3단계: 최종 확정된 아웃라인을 토대로 본문 작성 (LLM 호출)
- 마케팅 카피 작성 후 번역:
Workflow: Routing:
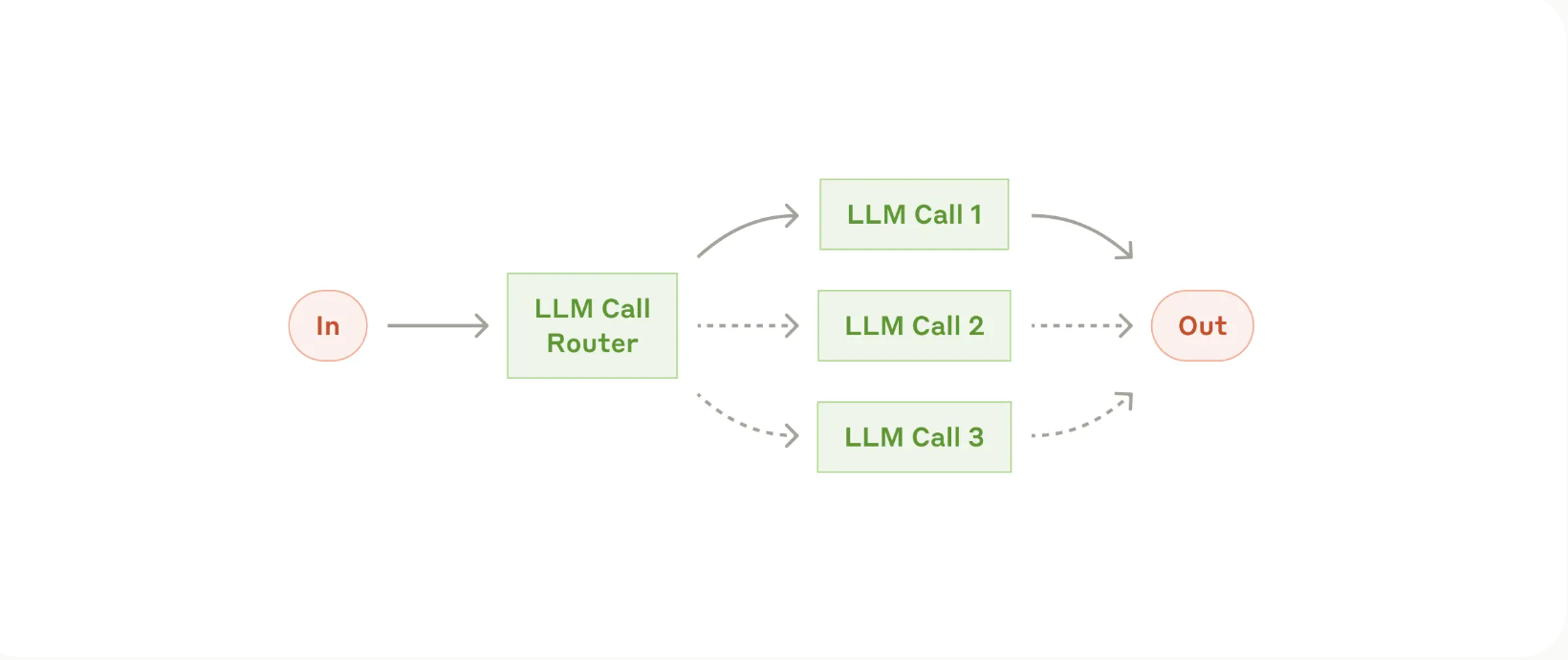
- Routing의 개념:
- 먼저 사용자 입력(또는 어떤 형태의 요청)을 특정 범주로 분류하는 걸 말함.
- LLM 을 이용할수도, 전통적인 머신러닝 모델을 이용할수도, 휴리스틱한 기준을 이용할수도 있음.
- 이렇게 Routing 한 이후 적합한 모델, 적합한 프롬프트, 적합한 워크플로우를 이용해서 처리하는 거임.
- 예: “일반 문의”는 FAQ 시스템으로 보내고, “환불 요청”은 결제 시스템으로 연결하며, “기술지원”은 전문 엔지니어 혹은 기술 문서를 활용하도록 설계.
- 언제 Routing이 유용할까?
- 복잡한 업무에서 서로 다른 처리 방식이 필요한 경우
- 예: 고객 서비스 요청을 분석했을 때, “결제 관련 문의”와 “기술 관련 문의”에 적용되는 솔루션, 프로세스, 답변 스크립트가 완전히 다를 수 있음.
- 정확한 분류가 가능한 상황:
- Routing은 올바른 프로세스로 연결해야 의미가 있으므로, 분류 정확도가 보장돼야 함.
- 서로 다른 모델을 효율적으로 활용:
- 예: 단순하고 자주 등장하는 질의는 가벼운(더 저렴하고 빠른) 모델로 처리하고, 복잡하고 드문 질의만 고성능(더 비용이 드는) 모델에 보내는 구조로 비용과 속도를 최적화할 수 있음.
- 예시:
- 고객 서비스 문의 라우팅:
- 입력을 LLM 또는 분류 모델로 분석해 “일반 문의”, “환불 요청”, “기술 지원” 등으로 카테고리화.
- 각 카테고리에 따른 후속 절차(워크플로우, 프롬프트, 툴) 가 다르게 구성됨.
- 모델 선택 최적화:
- 쉽고 흔한 질문: 저비용 모델(예: Claude 3.5 Haiku)
- 어렵고 드문 질문: 고성능 모델(예: Claude 3.5 Sonnet)
- 고객 서비스 문의 라우팅:
- 복잡한 업무에서 서로 다른 처리 방식이 필요한 경우
Workflow: Parallelization:
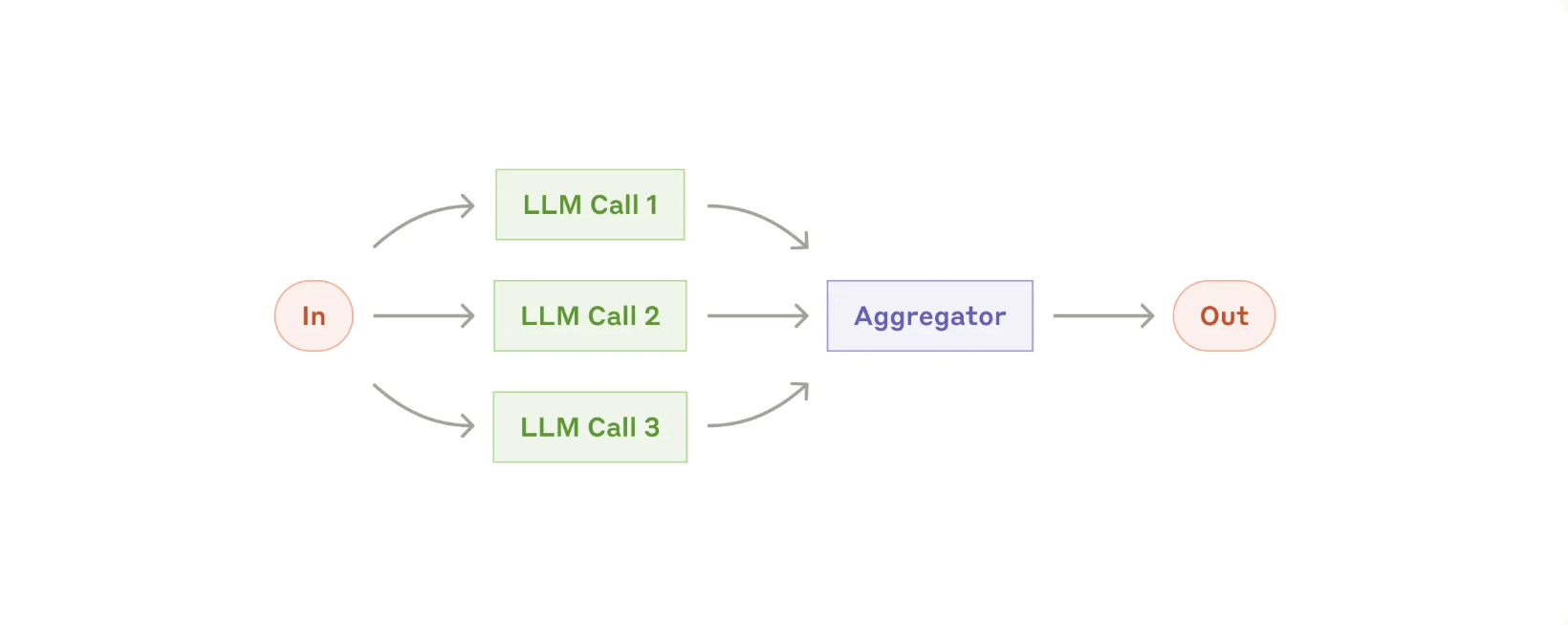
- 여러 LLM 호출을 동시에 진행하여, 필요한 결과를 병합(aggregation)하거나 결론을 내리는 구조.
- 패턴:
- (1) 섹셔닝(Sectioning):
- 작업을 여러 독립된 하위 작업으로 나눈 뒤, 각각을 동시에 수행하고 최종적으로 합치는 것.
- 예: 여러 챕터가 있는 문서를 분할 처리 → 각 챕터의 작업이 끝난 뒤 결과를 합치는 방식.
- (2) 보팅(Voting):
- 동일한 작업을 여러 번 실행하여 여러 답변을 얻은 후, 이를 조합하거나 투표를 통해 최종 결론을 내리는 것.
- 예: 여러 LLM 프롬프트로 코드 취약점을 점검 → 최종적으로 다수결 혹은 특정 기준을 만족하면 취약점으로 판정.
- (1) 섹셔닝(Sectioning):
- 언제 병렬화 워크플로우를 사용하면 좋을까?
- 독립적인 하위 작업을 나누어 병렬 처리하면 처리 속도가 빨라야 하는 상황에서 유리합니다.
- 예: 대규모 문서 여러 개를 한꺼번에 요약해야 하는 경우, 각 문서를 병렬로 처리.
- 다양한 관점이나 여러 번 시도가 필요하여, 결과의 정확도를 높이고 싶을 때 좋습니다
- 예: 코드 리뷰를 여러 시각에서 수행해서 높은 신뢰도를 달성하고 싶은 경우.
- 섹셔닝(Sectioning)의 예시
- 가드레일(Guardrails)과 핵심 응답 분리:
- 예: 사용자의 질문을 처리하는 LLM과, 질문 내용을 검열(부적절성 판단)하는 LLM을 서로 다른 인스턴스로 분리해 동시 처리.
- 이유: 하나의 LLM에 “답변 생성 + 검열 로직”을 함께 시키는 것보다, 분리된 LLM이 각자 주어진 임무에 집중하도록 설계하는 편이 성능이 나은 경우가 많음.
- LLM 성능 평가(Automating evals):
- 각각 다른 기준(예: 정확성, 창의성, 논리적 일관성 등)에 대해 서로 다른 LLM 호출이 평가를 수행.
- 이후 평가 결과를 합산하여 총평을 얻음.
- 가드레일(Guardrails)과 핵심 응답 분리:
- 보팅(Voting)의 예시:
- 코드 취약점 점검:
- 같은 코드 스니펫에 대해 여러 LLM 프롬프트를 동시에 실행해, 각각 취약점을 찾게 함
- 과반수 이상 혹은 투표율이 일정 기준 이상이면 취약 코드로 판단.
- 부적절 컨텐츠 감지:
- 하나의 LLM 호출에만 의존하기보다는, 여러 번 LLM에 질문(프롬프트)을 달리 하거나 다른 모델에 던져서 부적절성 여부를 확인
- 다양한 관점(예: 윤리적 측면, 규정 준수 측면, 연령 제한 측면 등)에서 검토한 뒤, 결과를 종합하여 의사결정을 내림.
- 코드 취약점 점검:
- 독립적인 하위 작업을 나누어 병렬 처리하면 처리 속도가 빨라야 하는 상황에서 유리합니다.
Workflow: Orchestrator-workers:
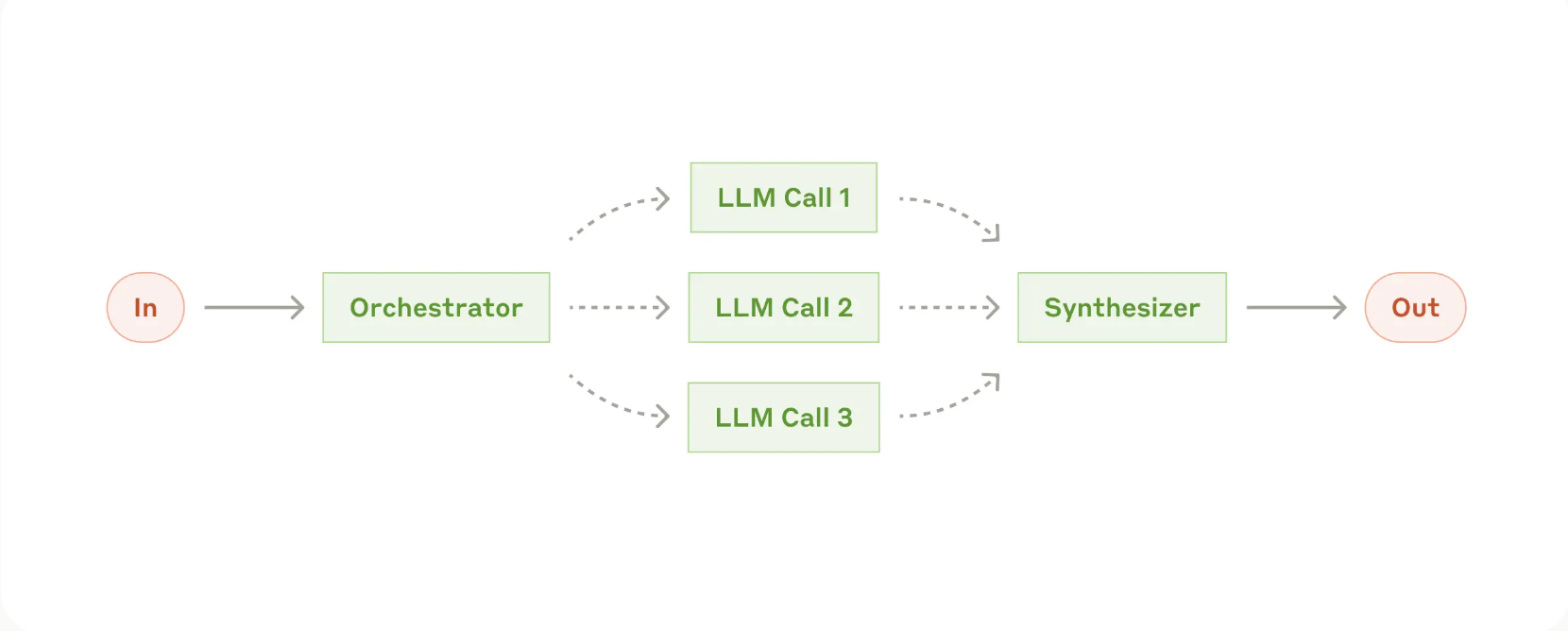
- 오케스트레이터(Orchestrator) 역할을 하는 중앙 LLM이 과제를 동적으로 분해하고, 적절한 워커(Worker) LLM에게 각각의 하위 과제를 할당한 뒤, 결과를 종합해 최종 답안을 도출하는 방식
- 언제 이 워크플로우가 유용할까?
- 사전에 정확한 하위 과제를 예측할 수 없는 복잡한 작업 (오케스트레이터의 판단이 한번 작업 분해가 필요한 경우)
- 예: 코딩 작업에서, 어느 파일을 수정해야 하고, 어떤 로직을 수정해야 할지 미리 고정하기 어렵습니다. 문제 상황에 따라 수정 범위가 달라질 수 있으므로, 동적으로 과제를 나누는 구조가 필요함.
- 병렬화(Parallelization) 와 유사한 면이 있으나 사전에 하위 작업이 정해지진 않았음. 입력 상황에 따라 오케스트레이터가 실시간으로 작업을 분할한다는 점이 다름.
- 예시:
- 코딩 작업:
- 사용자가 “앱에 새로운 기능을 추가해 달라”고 요청할 경우, 오케스트레이터 LLM이 “어떤 파일을 수정해야 하고, 어떤 함수가 필요하며, 어떻게 구현해야 하는지”를 동적으로 결정.
- 결정된 후 과제를 여러 워커 LLM에게 분배하여 각각 코드를 수정하거나 생성하게 한 뒤, 최종 결과물을 합쳐서 완성
- 검색 및 정보 분석:
- 여러 소스(문서, 웹사이트 등)에서 정보를 추려야 하는 복잡한 검색 작업에 사용.
- 오케스트레이터가 “어느 소스에서 무엇을 찾아야 하는지”를 판단하고, 워커 LLM들이 각 소스에서 정보를 가져와 요약/분석하게끔 지시함.
- 돌아온 요약/분석 결과를 오케스트레이터가 모아서 결론을 도출함.
- 코딩 작업:
- 사전에 정확한 하위 과제를 예측할 수 없는 복잡한 작업 (오케스트레이터의 판단이 한번 작업 분해가 필요한 경우)
Workflow: Evaluator-optimizer:
- 한 개의 LLM이 결과물(응답)을 생성하면, 다른 LLM이 그 결과물을 평가하고 피드백을 주고 개선하는 과정을 반복하는 구조임.
- 언제 이 워크플로우가 유용할까?
- 명확한 평가 기준이 존재하고, 이를 통해 결과물을 점진적으로 개선할 수 있을 때
- 예: 문학 번역 시 표현의 뉘앙스, 품질 기준이 어느 정도 정해져 있고, 평가자가 그 기준에 따라 수정 요청을 줄 수 있음.
- 여러 번의 반복을 통해 결과물을 개선하는 과정이 실제로 가치가 클 때
- LLM이 처음부터 완벽한 결과를 내지 못하더라도, 피드백을 통해 점차 개선 가능
- 즉, 평가자 LLM의 조언이 “실질적인 향상”을 가져올 만한 작업에 적합합니다.
- 예시:
- 문학 번역:
- Optimizer LLM이 번역 초안을 만든 뒤, Evaluator LLM이 “이 부분에서 문화적 뉘앙스가 잘 살지 않았다”, “이 표현이 원문 의도를 제대로 살리지 않는다” 등 구체적인 피드백을 제공.
- Optimizer LLM이 이 피드백을 반영하여 번역문을 재작성. 필요하면 이를 여러 번 반복.
- 복잡한 검색(Information Gathering) 과정:
- Optimizer LLM이 현재까지 찾은 정보를 정리해 제시.
- Evaluator LLM이 “아직 부족한 점이 있다”, “이 주제에 대해 더 탐색해야 할 영역이 있다” 같은 판단을 내려, 추가 검색 방향을 제안.
- Optimizer LLM이 추가 검색을 수행하고 결과물을 업데이트 → Evaluator가 또 평가 → 반복.
- 문학 번역:
- 명확한 평가 기준이 존재하고, 이를 통해 결과물을 점진적으로 개선할 수 있을 때
Agents:
- 에이전트는 LLM이 도구(툴)와 상호 작용하며, 지속적으로 작업 계획을 세우고 실행 결과(피드백)를 받아 다음 단계를 결정하는 형태의 자율 시스템을 말함.
- 에이전트의 작동 방식:
- 명령(또는 대화)를 통해 작업 이해:
- 사용자가 에이전트에게 원하는 작업을 명확하게 전달하거나, 인터랙티브하게 질의응답을 통해 작업 정의가 이루어짐
- 계획 수립 및 자율 실행:
- 에이전트는 필요한 작업 단계를 스스로 계획(Reasoning & Planning)하고, 필요한 경우 도구(툴)를 선택해 사용.
- 환경 피드백 획득:
- 각 단계에서 ‘툴을 사용한 결과’, ‘코드 실행 결과’, ‘데이터 조회 결과’ 등 환경적 정보를 다시 수집하여 진행 상황을 판단.
- 휴먼 피드백과 체크포인트(선택적):
- 특정 체크포인트마다 사람이 개입해 에이전트의 작업을 검토하거나 승인할 수 있음.
- 또한, 막히는 부분(블로커)이 발생하면 사용자에게 추가 정보를 요청할 수도 있음.
- 작업 종료:
- 작업이 완료되면 종료. 혹은 반복 횟수나 시간 제한 같은 스톱 조건(Stopping condition)이 도달하면 자동으로 중단.
- 명령(또는 대화)를 통해 작업 이해:
- 에이전트는 LLM이 스스로 다음 단계를 결정한다는 점이 핵심임.
- 프로그래밍된 워크플로우(Workflows)처럼 작업 순서가 사전에 고정된 것이 아니고, 작업 진행 중간중간 상황에 따라 유연하게 결정함.
- 그래서 예측 불가능한 작업 흐름에 유용하고, 단발성의 작업이 아니고 계속해서 발전해서 처리해야하는 경우에도 유용
- 많은 작업을 자동화할 수 있다는 점도 유용하다.
- 주의사항 및 트레이드오프:
- 비용 증가 & 오류 누적:
- 에이전트는 여러 차례 LLM을 호출하며 도구를 사용하는 과정이 반복되므로, API 호출 비용과 처리 시간이 늘어남.
- 작은 실수(오류)가 여러 단계에 누적될 가능성도 있으므로, 오류 방지 대책을 마련해야 한다.
- 샌드박스 & 가드레일:
- 에이전트를 실제 프로덕션 환경에 바로 투입하기 전에, 테스트 전용 환경(샌드박스) 에서 충분히 시험하는 것을 권장
- 에이전트가 접근할 수 있는 자원(예: 파일, DB, 외부 API)과 의사결정 범위를 적절히 제한(Guardrails) 하면, 위험성과 오류 범위를 제어할 수 있음.
- 툴셋(toolset) 설계:
- 에이전트가 사용하는 도구가 명확하게 정의되고, 문서화가 잘 되어 있어야 함.
- 에이전트는 단순히 LLM일 뿐이고, 실제 연산(코딩, 검색, 파일 편집 등)은 각각의 도구가 수행하므로, 도구별 입출력과 사용 규칙을 꼼꼼히 설계·문서화해야한다.
- 스톱 조건(Stopping condition):
- 무한 루프나 불필요한 반복 실행을 막기 위해, “최대 몇 번까지 시도한다”, “예외 상황 발생 시 중단한다” 등의 조건을 설정해 두는 것이 일반적임.
- 비용 증가 & 오류 누적:
- 언제 에이전트를 쓰면 좋을까?:
- 작업 프로세스를 사전에 명확히 ‘하드코딩’할 수 없는 경우
- 예: 버그 수정, 리팩토링처럼 수정 범위가 상황마다 크게 달라지는 작업
- 방대한 검색 작업, 새롭게 떠오르는 문제 상황(Unknown unknowns) 등
- LLM의 의사결정에 대한 기본적인 신뢰가 있고 여러 번의 호출과 도구 사용을 감수할 만큼 가치가 있을 때 (비용/시간 대비 편익이 높을 경우)
- 예시:
- 코딩 에이전트:
- 여러 파일에 걸쳐 변경사항이 필요한 SWE(소프트웨어 엔지니어링) 작업을 처리.
- 사용자가 “새 기능을 추가해 달라”라고 하면, 에이전트가 수정할 파일과 수정 내용을 스스로 파악해 각각 도구(코드 편집 등)를 사용.
- 컴퓨터 사용 시나리오:
- LLM(Claude 등)이 실제 컴퓨터 시스템에 접근해, 파일 검색, 인터넷 검색, 문서 편집 등을 직접 수행.
- 도중에 파일이 없거나 권한이 없으면 사용자에게 문의(휴먼 피드백)하고, 다양한 명령을 스스로 실행.
- 코딩 에이전트:
- 작업 프로세스를 사전에 명확히 ‘하드코딩’할 수 없는 경우
Appendix 1: Agents in practice:
- 에이전트(Agents)를 실제로 적용하고 있는 사례 두 가지 사례 소개
- 고객 지원(Customer Support):
- 기능 결합: 채팅 + 도구(툴) 사용
- 고객 지원은 기본적으로 대화(챗봇) 를 통해 진행되지만, 동시에 고객 정보 조회, 주문 이력 확인, 환불 처리 같은 액션이 필요함.
- 에이전트는 툴(예: 데이터베이스, CRM, 결제 시스템)과 통합되어, 필요한 정보를 가져오고, 자동으로 티켓을 업데이트하거나 환불을 처리할 수 있음.
- 지원 요청은 열린 대화 흐름이지만, 외부 데이터와 시스템에 접근해야만 충분한 답변이 가능하므로, 에이전트가 자신의 도구를 알맞게 사용해 문제를 해결.
- 성공 여부는 “사용자가 원하는 해결책(해결 방안)으로 문제를 마무리했는가?”로 명확히 측정할 수 있음.
- 일부 기업은 usage-based pricing(성과 기반 과금) 모델로, 에이전트가 실제로 문제를 ‘성공적으로 해결’했을 때만 비용을 청구한다고 함. 그정도로 높은 신뢰를 보여줌.
- 정리: 에이전트가 “대화 + 작업(액션) 수행”을 통합적으로 처리하면서, 환불이나 티켓 업데이트 같은 구체적인 조치를 자동으로 수행.
- 기능 결합: 채팅 + 도구(툴) 사용
- 코딩 에이전트(Coding Agents):
- 에이전트가 코드 작성・수정을 자율적으로 수행하고, 자동화된 테스트 결과를 피드백 삼아 반복해서 개선할 수 있음.
- 예: GitHub 이슈나 Pull Request에 대해, 에이전트가 해당 지시 사항만 보고 필요한 파일 변경, 새 함수 작성 등을 진행.
- 예: Anthropic에서 자체 개발한 에이전트는, SWE-bench Verified 벤치마크의 GitHub 이슈를 오직 Pull Request 설명만 보고도 해결 가능
- 다만, 자동화 테스트로 기본적인 기능은 검증 가능하지만, 시스템 전반의 복잡한 요구사항이나 아키텍처적 일관성은 사람(개발자)의 최종 검수가 여전히 필요.
- 정리: LLM의 자율적 코드 작성・수정을 자동 테스트를 통해 빠르게 검증하고, 부족한 부분은 반복적인 피드백 루프로 개선.
- 그리고 둘 다 명확한 성공 기준(문제 해결 여부)이 존재. (이런 비싼 시스템을 구축할 이유이기도 함)
Appendix 2: Prompt engineering your tools:
- 에이전트가 사용할 도구(tools)를 어떻게 ‘프롬프트 엔지니어링(설계)’하면 좋은지를 다룸.
- 즉 LLM(Claude 등)이 외부 서비스나 API를 활용할 때 필요한 도구 정의를 어떻게 구성해야 에이전트가 더 효율적이고 오류 없이 사용할 수 있는지에 대한 구체적인 조언을 제공함.
- 도구의 이름, 파라미터, 입력/출력 형식, 예시 사용법 등을 프롬프트에 상세히 기술해야지 에이전트가 정확히 사용할거임.
- 구체적인 조언:
- 동일 액션을 여러 포맷으로 표현할 때의 고려사항:
- 여기서 액션(action)이란, 예컨대 ‘파일 수정’이 될 수도 있고, ‘코드 생성’이 될 수도 있으며, 이를 Diff 형태로 제시하느냐, 전체 파일 재작성 형태로 제시하느냐, Markdown vs. JSON 등 어떤 출력 포맷으로 표현하느냐 등을 의미
- 모델이 처리해야 할 “추가적인 작업(Overhead)”이 얼마나 되는가? 를 고려해야한다.
- Diff 작업의 경우:
- LLM이 “몇 번째 줄부터 몇 번째 줄까지 수정한다”는 식으로 정확한 줄 번호와 수정 범위를 지정해야 함.
- 예: @@ -31,7 +31,7 @@ 와 같이 Diff 헤더를 작성할 때, 수정할 줄의 개수(또는 범위)를 미리 계산해야 하는데, 이는 LLM에게 추가적인 인지 부담이 됨.
- 만약 코드가 매우 길거나, 수정 범위가 넓어지면 줄 번호 계산 오류가 발생하기 쉬우므로, 모델 차원에서 실수가 늘어날 위험이 있음.
- 전체 파일 재작성:
- LLM이 기존 파일을 통째로 다시 써서 제시하므로, 줄 번호 계산을 신경 쓸 필요가 없음.
- 다만, 파일 크기가 커질수록 그 내용을 전부 재작성해야 하므로, 토큰 사용량이 커지고 응답이 방대해질 수 있음.
- JSON vs. Markdown:
- JSON 안에 코드를 넣으려면, \n, " 등 이스케이프(escape) 문자를 처리해야 함.
- Markdown 코드블록(...) 형태는 모델이 인터넷상의 예시에서 자주 봐서 비교적 자연스럽게 작성하지만, JSON은 이스케이프 처리에서 실수가 발생하기 쉬움.
- 즉 JSON으로 주고받으면 구조화가 명확하여 자동 파싱이 쉽지만, 모델이 이스케이프 처리에서 틀릴 가능성이 늘어남.
- 결론적으로, 어떤 포맷을 채택하느냐에 따라 LLM이 감당해야 하는 “추가 작업(Overhead)”이 달라지고, 이는 곧 오류 가능성 및 토큰/비용 증가와 연결됨.
- 모델이 학습했던 단순한 포맷과 형식을 적용하는게 중요.
- Diff 작업의 경우:
- HCI(Human-Computer Interface)만큼 ACI(Agent-Computer Interface)에도 신경 쓰기:
- 도구 설계 시, 모델 입장에서 생각:
- “이 파라미터 이름, 설명만 보고 어떻게 쓰는지 바로 알 수 있을까?” 를 생각해보는 것.
- 사람에게 API 제공 시 “좋은 문서화, 예시, 에러 케이스 안내”가 필요한 것처럼, 모델에게도 동일하게 제공.
- 포카-요케(Poka-yoke) 방식을 이용하라는 것. (= 사람이 실수하기 어렵도록 프로세스나 설계 자체를 바꿔버리는 것)
- 여기서는 도구(툴)를 정의할 때 모델이 실수를 저지를 가능성을 원천적으로 줄일 수 있도록 파라미터 이름, 형식, 인수 구조 등을 설계하라는 뜻임.
- 예: 상대경로(relative path) 대신 절대경로만 허용하도록 바꿔, 경로 혼동을 없앤다.
- 예: 잘못된 타입의 인수를 넣으면 자동으로 거부되도록 입력 형식을 엄격하게 만든다.
- 도구 설계 시, 모델 입장에서 생각:
- 동일 액션을 여러 포맷으로 표현할 때의 고려사항:
- 정리:
- 도구(툴) 정의는 에이전트 개발의 핵심임.
- 모델이 쉽게 이해하고 오류를 범하지 않을 포맷을 신중히 선택해야 함
- 간결하고 직관적인 파라미터 네이밍, 명확한 문서화, 사용 예시 제공, 실수 방지용 설계 등을 통해, 모델이 도구를 자연스럽게 활용할 수 있음.
'Generative AI > Agent' 카테고리의 다른 글
| Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs (0) | 2024.12.30 |
|---|---|
| Google Cloud Vertex AI Agent Builder (0) | 2024.12.30 |
| StateFlow: Enhancing LLM Task-Solving through State- Driven Workflows (0) | 2024.12.29 |
| AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation (0) | 2024.12.29 |
| LLM Agents Course (4) Enterprise Trends for Generative AI (0) | 2024.12.28 |