https://developer.nvidia.com/blog/curating-trillion-token-datasets-introducing-nemo-data-curator/
NeMo Data Curator 등장:
- 최근 연구에서는 Chinchilla 및 LLaMA 모델을 통해 모델 파라미터 수와 훈련 토큰 수를 동일한 비율로 확장해야 최적의 성능을 얻을 수 있음이 입증되었습니다.
- 이를 통해 이전 최첨단 모델들은 토큰 수가 충분하지 않아 "미달 훈련(under-trained)" 상태였다고 함.
- 결론적으로 LLM 개발에는 더 방대한 데이터 세트가 필수적이며, 기존보다 훨씬 큰 규모(수조 토큰)의 데이터가 필요해졌습니다.
- 하지만 대규모 데이터 세트를 구축하기 위한 소프트웨어나 도구는 대부분 공개되지 않았거나 확장성이 부족합니다. 그리고 LLM 개발자들은 자체적인 데이터 처리 파이프라인을 구축해야 하며, 이는 시간과 비용을 크게 증가시킵니다
- NVIDIA는 위 문제를 해결하기 위해 NeMo Data Curator를 개발 및 공개했습니다. 이 도구는 수조 토큰 규모의 다국어 데이터 세트를 효율적으로 정제할 수 있도록 설계되었습니다.
NeMo 주요 기능:
- MPI(Message-Passing Interface)와 Dask를 활용해 수천 개의 CPU 코어에서 병렬 처리를 지원합니다.
- MPI: 고성능 컴퓨팅(HPC) 환경에서 분산 작업을 조율하는 표준 라이브러리. 다중 노드 간 통신을 표준화하여 병렬 작업 조율.
- Dask: Python 기반 병렬 처리 프레임워크로, 대규모 데이터 분산 처리에 최적화됨.
- NeMo Data Curator는 CPU 코어 수 증가에 따른 선형 확장성을 실험으로 증명함:
- 기술적 기반은 MPI 와 Dask 를 이용한 데이터 분할 및 병렬 처리, 비동기 작업 스케줄링, 메모리 관리임.
- 그리고 GPU 기술을 이용하면 훨씬 더 빨리 줄일 수 있다고 함:
- CPU: 20개 노드(노드당 48코어, 188GB RAM) → 37시간 소요.
- GPU: 4개 DGX A100 노드(노드당 8x 80GB GPU) → 3시간 소요.
- 세분화된 데이터 처리 파이프라인 지원:
- 데이터 다운로드: 다양한 소스에서 데이터 수집.
- 텍스트 추출: HTML, PDF 등 비정형 데이터에서 텍스트 추출
- 정제 및 재구성: 불필요한 포맷 제거, 일관된 구조로 변환.
- 품질 필터링: 노이즈 데이터 제거(예: 의미 없는 텍스트, 저품질 콘텐츠).
- 중복 제거: 정확 또는 유사 중복 문서 제거(Document-Level Deduplication)
Data-curation pipeline 소개:
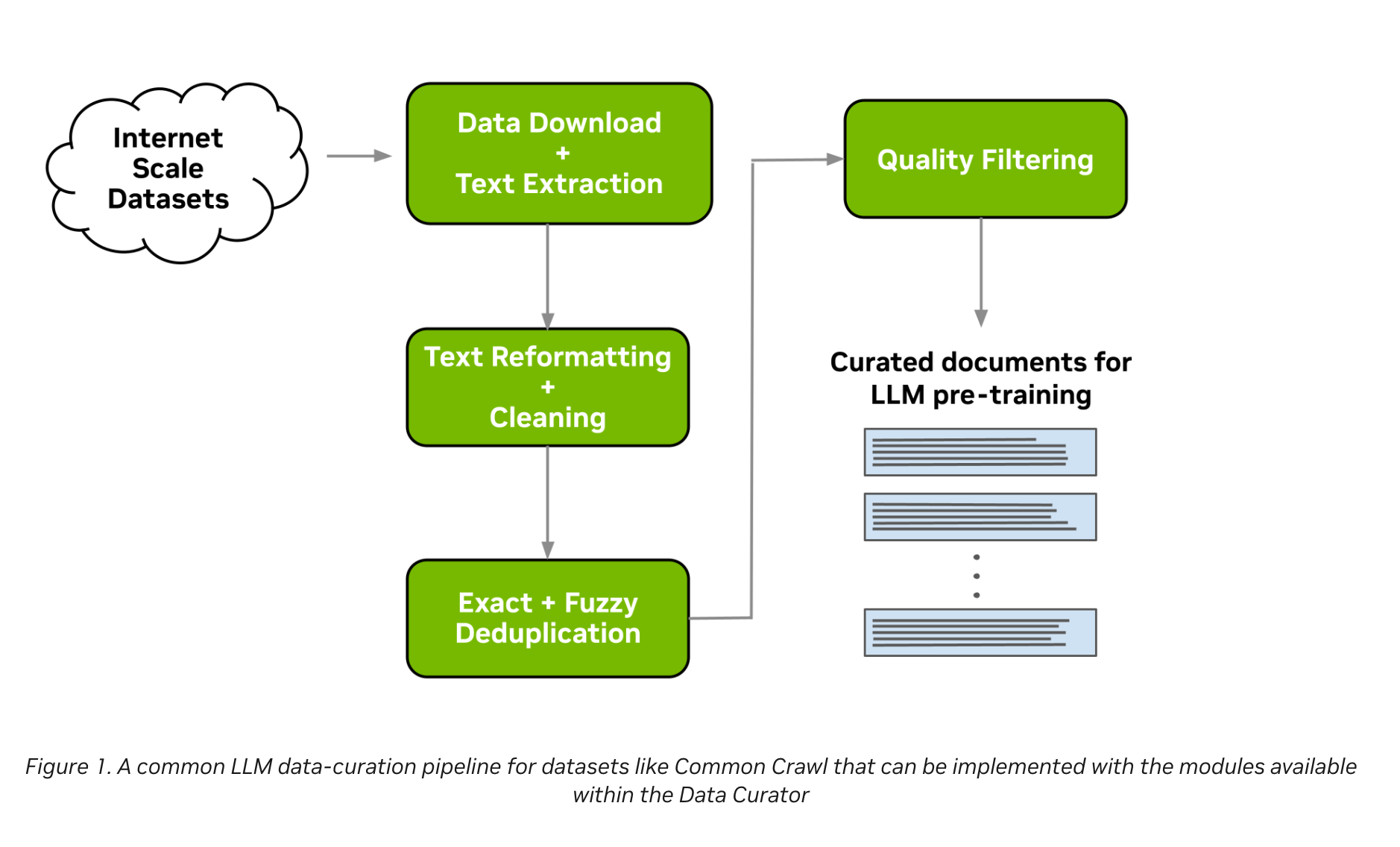
- NeMo Data Curator의 데이터 정제 파이프라인을 단계별로 상세히 설명하며, 각 단계의 기술적 구현과 성능 최적화 방법을 소개.
- 전체 파이프라인은 대규모 데이터를 체계적으로 처리해 LLM 훈련에 적합한 고품질 데이터셋을 생성하는 데 초점을 맞춥니다
- 전체 파이프라인 개요:
- 웹 크롤링 데이터(Common Crawl 등)를 다운로드 → 텍스트 추출 → 정제 → 중복 제거 → 품질 필터링을 거쳐 LLM 훈련에 필요한 데이터로 변환.
- 확장성과 효율성을 위해 MPI와 Dask를 활용해 수천 개의 CPU/GPU 코어에서 병렬 처리가 가능하다는게 장점.
- Scaling Language Models: Methods, Analysis & Insights from Training Gopher
- GPU 가속을 통해 대용량 데이터 처리 시간을 시간 단위로 단축합니다(기존 일 단위 대비).
- 단계별 설명:
- (1) 데이터 다운로드 및 텍스트 추출:
- 입력 데이터 소스: Common Crawl, Wikidumps, ArXiv 등에서 미리 크롤링된 웹 페이지 URL 목록을 사용합니다
- 대규모 병렬 처리: MPI와 Python Multiprocessing을 결합해 수천 개의 비동기 작업자를 실행합니다.
- 유연성: 사용자 정의 다운로드/추출 함수를 지원하여 다양한 데이터 소스 처리 가능
- 출력 형식: 추출된 텍스트는 JSONL 파일로 저장됩니다.
- (2) 텍스트 재구성 및 정제:
- Unicode 오류 수정: ftfy 라이브러리를 사용해 텍스트 디코딩 오류를 자동으로 복구합니다.
- 텍스트 정규화: 공백, 특수 문자, 대소문자 등을 일관된 형식으로 표준화합니다.
- 중복 제거 효율화: 정규화를 통해 문서 중복 검출 정확도(recall)를 향상시킵니다.
- (3) 문서 수준 중복 제거:
- 중복 문서는 LLM의 성능 저하 (일반화 능력 감소, 생성 다양성 부족)를 유발합니다.
- 기술적 접근:
- 정확 중복 제거(Exact Deduplication):
- 각 문서의 128비트 해시 값을 계산 → 동일한 해시를 가진 문서 그룹에서 하나만 남기고 제거.
- 유사 중복 제거(Fuzzy Deduplication):
- MinHashLSH 알고리즘 활용:
- 문서마다 MinHash 생성 → Locality-Sensitive Hashing(LSH)으로 유사한 문서를 그룹화 함.
- 그룹 내 문서 유사도 계산 → 임계값 이상의 중복 문서 제거.
- 코사인 유사도 기법에 비해 계산 효율성이 뛰어나다는게 장점임. 그래서 대규모 데이터에 적합할 것.
- 문서마다 MinHash 생성 → Locality-Sensitive Hashing(LSH)으로 유사한 문서를 그룹화 함.
- MinHashLSH 알고리즘 활용:
- 정확 중복 제거(Exact Deduplication):
- RAPIDS 프레임워크를 이용해 GPU에서 중복 제거 작업을 가속화합니다.
- CPU(20개 노드, 37시간) vs. GPU(4개 DGX A100 노드, 3시간) → 12배 속도 향상.
- 비용 절감 효과: CPU 대비 20배 빠르고 5배 저렴
- GPU 기반 중복 제거 기능은 향후 NeMo Data Curator 버전에 추가될 예정입니다
- (4) 문서 품질 필터링:
- 문제점: 웹 크롤링 데이터에는 URL, 상용구 텍스트, 반복 문자열 등 저품질 콘텐츠가 다량 포함됩니다.
- 해결 방법:
- 휴리스틱 필터 사용:
- 사용자가 정의한 규칙(예: 특수 문자 비율, 문장 길이, 언어 감지)을 적용해 저품질 문서 제거.
- 언어 데이터 필터:
- 분류기(Classifier) 또는 휴리스틱 기반 필터를 사용해 고품질 텍스트만 선별합니다(참고 연구).
- Scaling Language Models: Methods, Analysis & Insights from Training Gopher
- 분류기 기반 필터 사용:
- 고품질 텍스트 데이터 (예: 위키 피디아, 전문 도메인 문서) 와 저품질 텍스트 (예: 스팸, 무의미한 콘텐츠) 를 레이블링해서 분류기를 훈련시키는 방법을 말함.
- BERT 와 RoBERT 같은 사전 훈련된 언어 모델을 이용해서 분류를 함.
- 휴리스틱 필터 사용:
- (1) 데이터 다운로드 및 텍스트 추출:
배경지식: MInHashLSM 알고리즘
- (1) 문서를 단어 또는 n-gram 으로 변환:
- 예: 문서 A = {a, b, c}, 문서 B = {a, b, d}
- (2) 이렇게 단어 집합을 구성한 후 해시 함수 적용:
- 문서 A 기준 = {h(a), h(b), h(c)} 가 생성될 것.
- (3) 해시 값 중 최소 값을 MinHash 로 선택, 그리고 이를 K번 반복해서 버킷에 할당
- 같은 버킷에 있는 건 K 개의 겹침 해시값이 있는 거고 확률상 이게 중복된 문서일 수 있다고 가정함.
- (4) 이런 중복 판단은 빠르지만 거짓 양성일 수 있으니 버킷 내 문서들끼리 Jaccard 유사도를 통해 비교:
- Jaccard 유사도 비교를 통해 임계값 (예: 0.8) 이상이면 중복이라고 판단. -> 유사도가 높은 문서 하나만 남기고 나머지 제거.
- Jaccard 유사도:
- 문서의 두 단어 집합에서 교집합/합집합 으로 계산한 걸 말함.
- 예: 문서 A = {a, b, c}, 문서 B = {a, b, d} 라면 Jaccard 유사도는 2/4 가 될거임.
'Generative AI > Data' 카테고리의 다른 글
| LLM Twin 프로젝트로 설명하는 데이터 수집 파이프라인 (0) | 2025.02.06 |
|---|---|
| 파인튜닝을 위한 데이터 합성 방법 정리 (0) | 2025.02.04 |
| NVIDIA: Synthetic Data Generation (0) | 2025.01.25 |
| What Makes Good Data For Alignment? A Comprehensive Study of Automatic Data Selection In Instruction Tuning (0) | 2025.01.25 |
| Alpagasus: Traning A better Alpaca with Fewer Data (0) | 2025.01.23 |