Kafka 를 사용하면서 메시지 처리량을 늘리기 위해 가장 간단한 접근 방법은 파티션 수를 늘리는 것이다.
그러나 이런 방법 이외에도 Parallel Consumer 를 이용해서 처리량을 늘리는 방법도 있다.
1. 단순 파티션 수를 늘리면 생기는 비용:
- 브로커의 로그 파일 관리 비용 증가
- 브로커에 여러 파티션들을 관리하게 되므로 장애가 났을 때 더 취약한 구조가 된다.
- 브로커에 저장되는 메시지는 복제되야하니까 디스크 사용량도 증가된다.
2. Parallel Consumer란 무엇인가:
Parallel Consumer란 단일 파티션에 여러 컨슈머 스레드를 사용하여 파티션을 늘리지 않고 동시 처리량을 증가시키기 위해 만들어진 라이브러리이다.
여러개의 컨슈머 스레드들이 파티션에 붙어서 메시지들을 가지고 오는 방식이다.
3. Parallel Consumer 의 Offset 처리 방식:
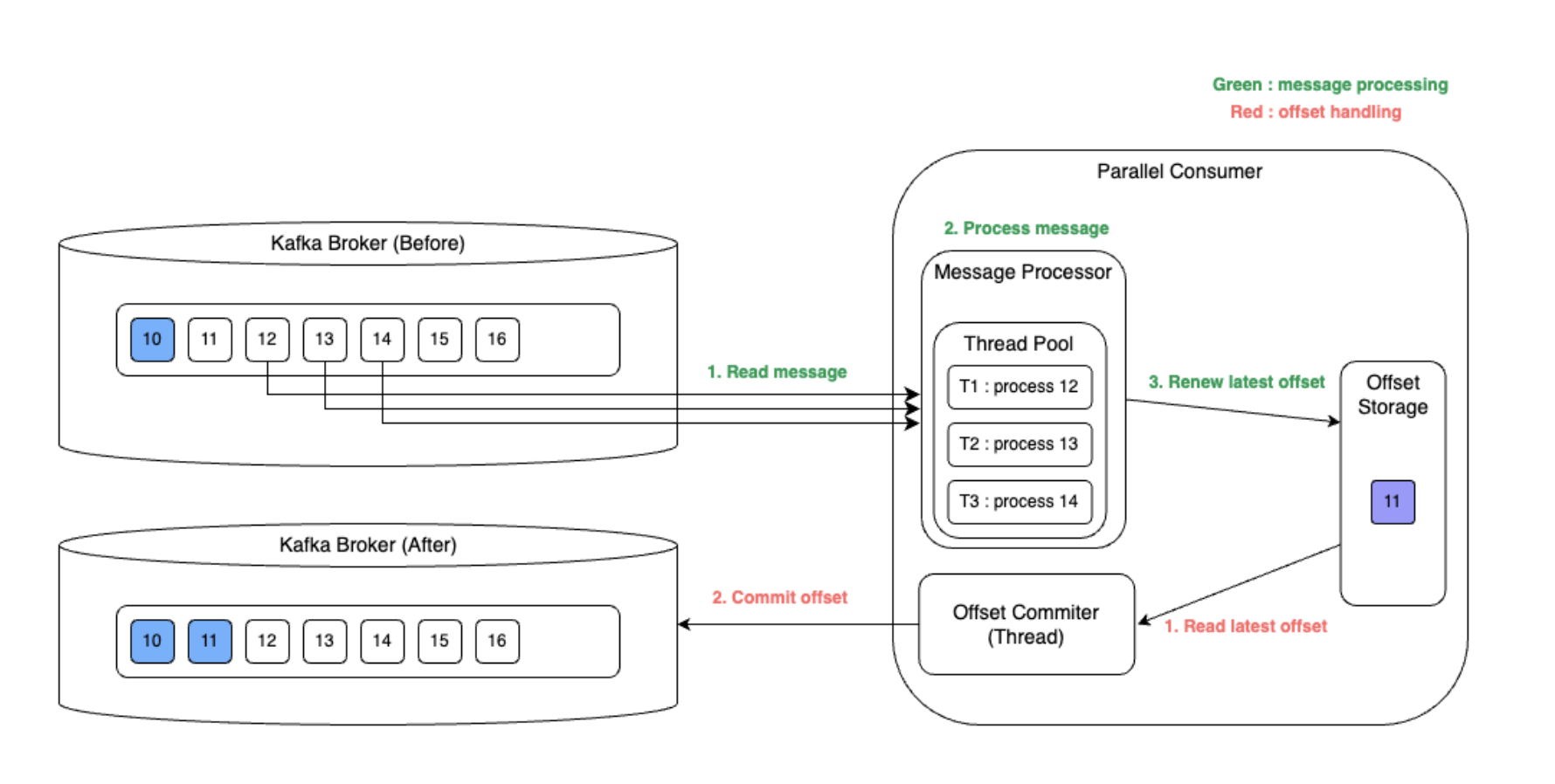
- 파티션 메시지를 여러 스레드에서 가지고 와서 처리한다.
- 커밋은 매번 메시지가 처리될 때마다 하는 것이 아니라 주기적으로 비동기식으로 처리한다. 주기적으로 그 시점에 완료된 마지막 메시지를 가지고 커밋하며, 이 커밋은 이전 메시지들이 모두 완료된 메시지여야한다. 예시로 12, 13, 14번 메시지가 병렬 컨슈머에 의해 처리가 시작되고 12, 14번 메시지는 처리되었으나, 13번 메시지는 아직 처리되지 않았더라면 마지막 메시지는 12가 된다.
4. Parallel Consumer의 순서 보장 방식:
Parallel Consuemer 에서도 메시지 처리 순서를 보장할 수 있다. 이 처리 방식은 Partition, Key, Unordered 로 분류할 수 있는데 Partition 방식이 가장 엄격한 방식이며 Unordered 방식이 가장 느슨하다.
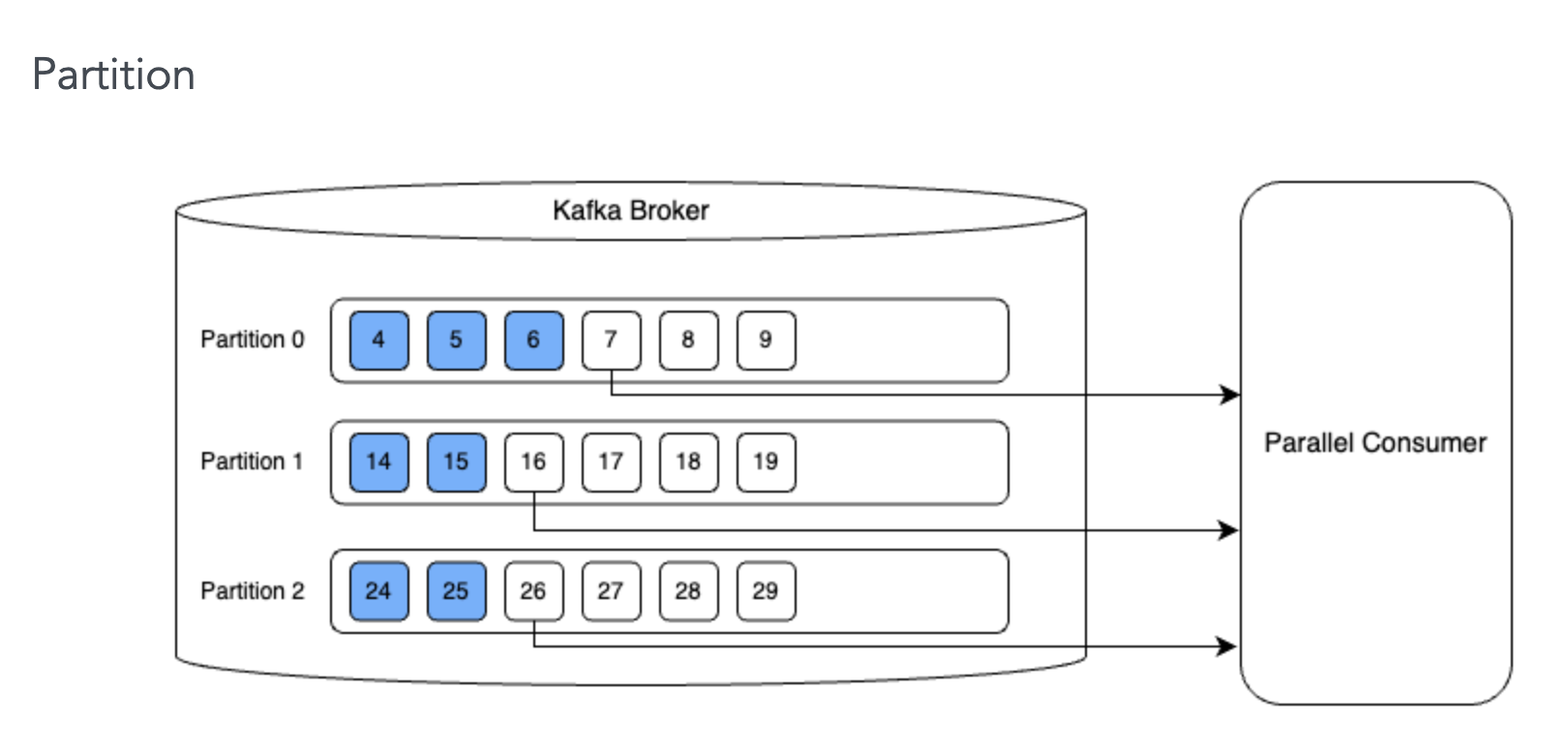
- Partition 방식은 기존 카프카 처리 방식과 크게 다르지 않다. 파티션 단위로 메시지 처리에 순서를 보장하는 방식이다.
- 다만 이 방식은 하나의 어플리케이션에서 여러개의 파티션을 받아서 처리할 수 있다는 장점이 있다.
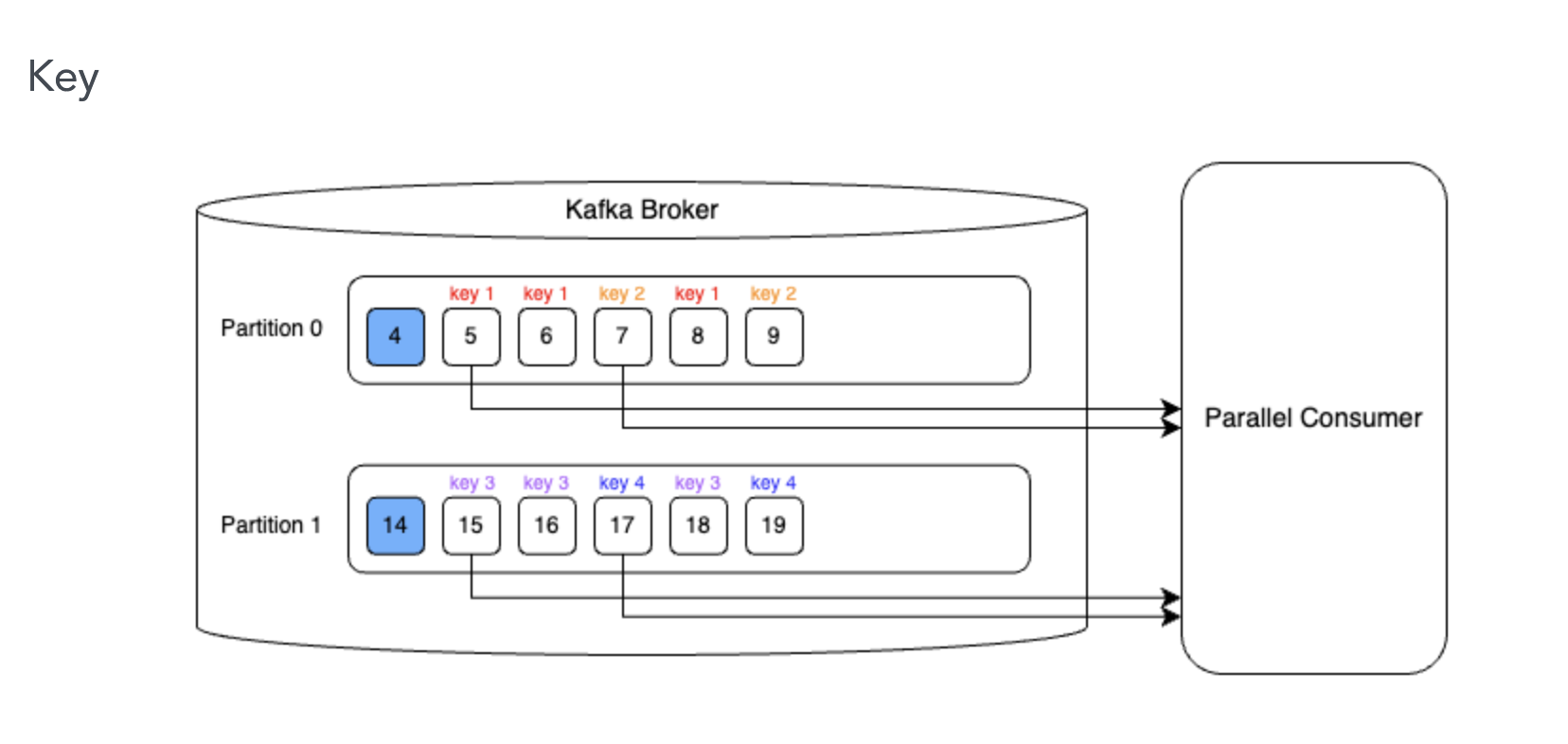
Key방식은 하나의 파티션 내에서 Key 를 기준으로 메시지 순서를 보장한다. 즉 같은 Key 를 가진 메시지들은 순서대로 처리됨을 보장할 수 있다. 내부적으로 파티션 내의 메시지들은 Key 별로 Shard 로 나눠져서 처리된다.
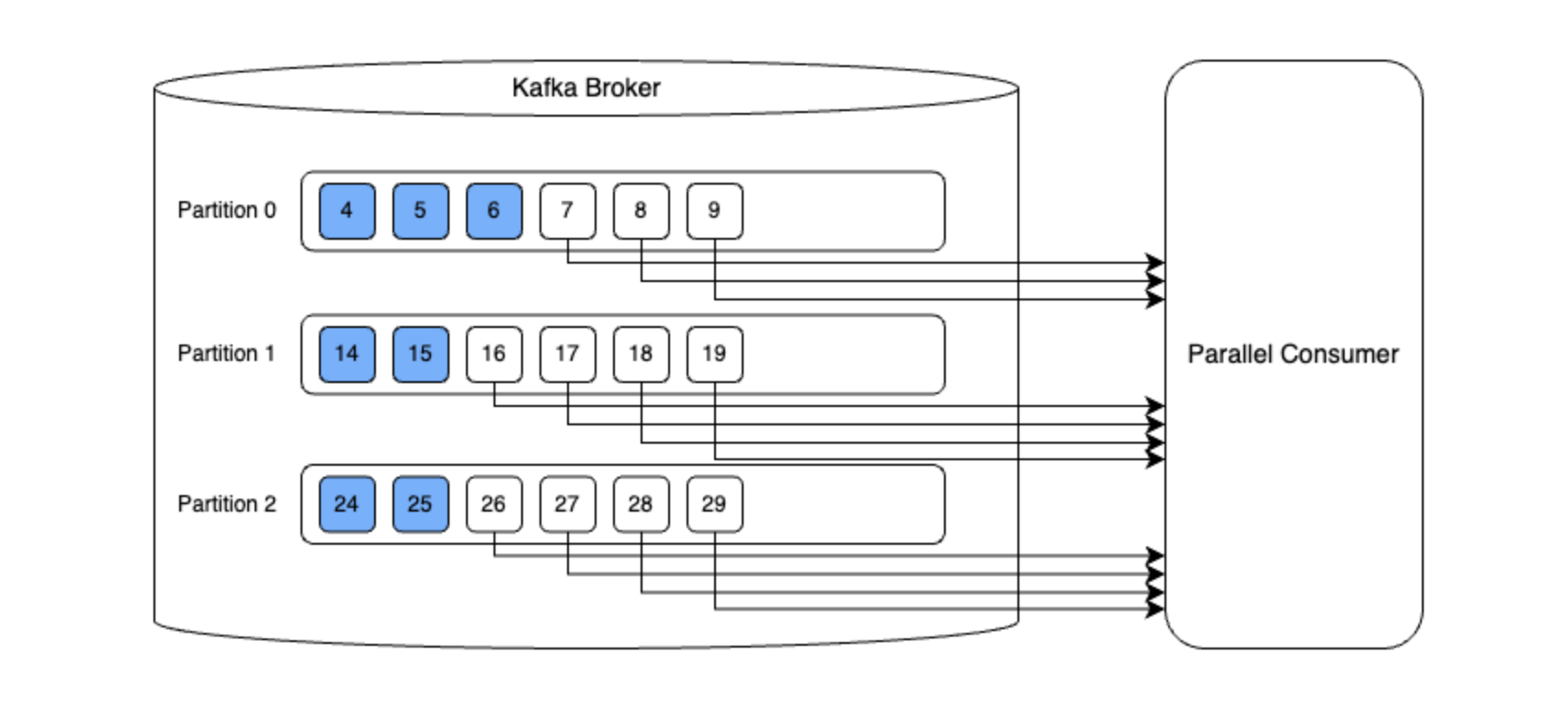
Unordered방식은 메시지 처리에 순서를 보장하지 않는다. 단순 병렬로 처리하기 때문에 가장 성능이 좋다.
5. Parallel Consumer 의 아키텍처
- 네이버의 Log&Metric 조직에서는 라이브러리를 도입하기 전에는 어떤 라이브러리가 구조로 이뤄져있는지, 실제 내부 코드는 어떤지, 코드로 인한 버그는 없는지 이런 것까지 검사를 한다.
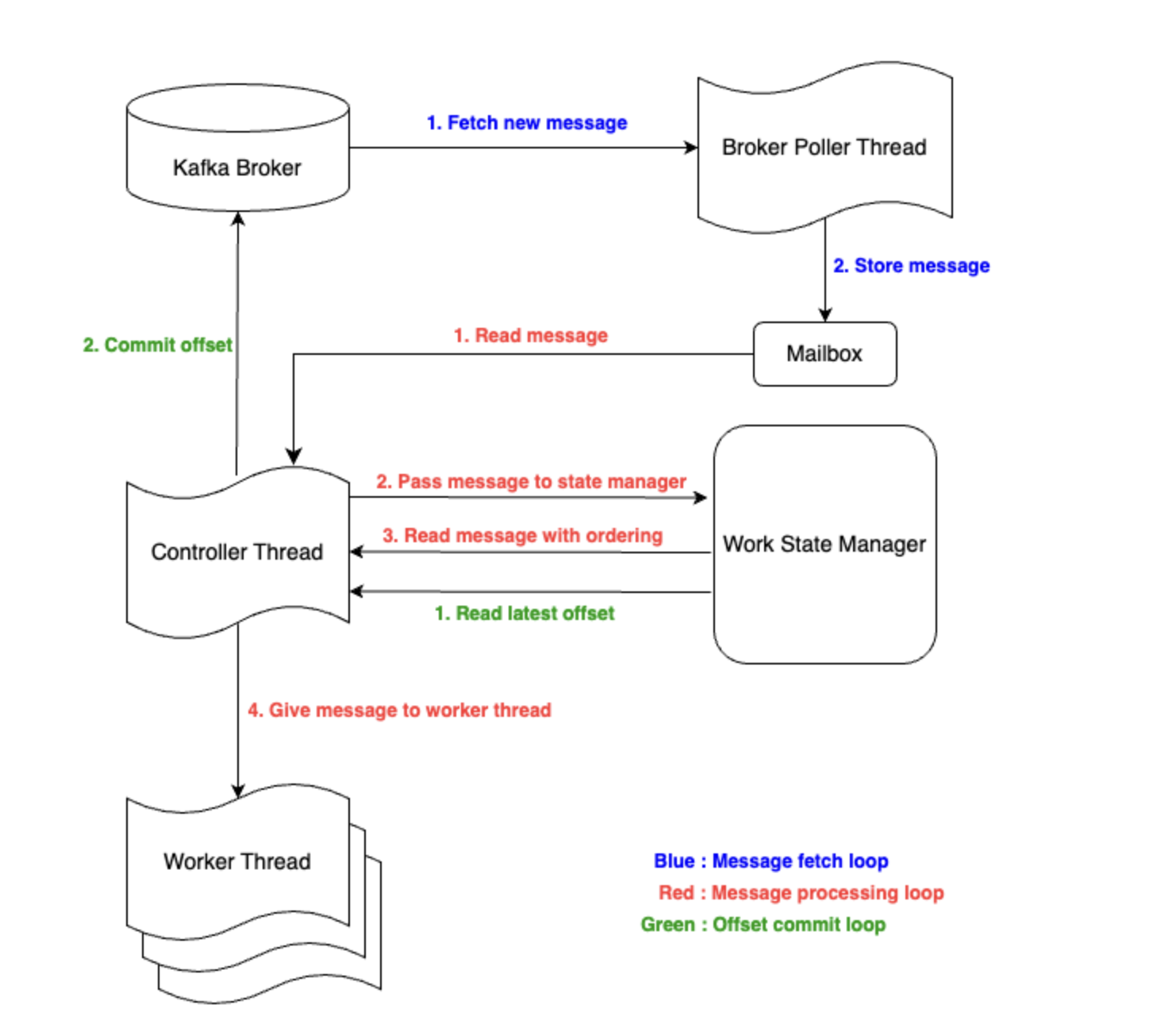
Parallel Consumer에는 Broker Poller Thread와 Controller Thread라는 2개의 중요한 스레드와 실제 사용자 코드를 처리하는 Worker Thread Pool, 그리고 오프셋 저장소인 Work State Manager 가 있다.
Broker Poller Thread는 실제 Kafka Broker와 통신하는 스레드로, 메시지를 가져와서 Mailbox에 저장한다.
Controller Thread는 실제 메인 로직으로, Mailbox에서 메시지를 가져와서 Worker Thread에 전달하는 작업 및 메시지 커밋을 담당한다.
Worker Thread Pool은 실제 사용자가 등록한 작업을 하는 스레드로, Controller Thread가 전달한 메시지를 처리한다.
Work State Manager는 처리한 오프셋 및 순서 보장을 고려하여 다음에 처리될 메시지를 관리한다.
- Controller Thread 가 메시지를 읽어와서 Worker Thread 에게 할당을 해야할텐데 메시지 처리에 순서를 보장하려면 어디까지 현재 처리했는지에 대한 상태 정보를 알아야하니까 이것에 대한 기록을 담는 듯하다.
- 브로커에 커밋을 할 때 커밋해야 할 메시지들을 가지고 오고, 처리는 되었지만 아직 이전 메시지가 처리되지 않아서 커밋은 못하는 메세지에 대한 메타 정보들과 아직 처리되지 못한 메시지들이라는 메타 정보를 관리하는 용도로 Work State Manager 는 쓰인다.
중복 메시지 처리 방지
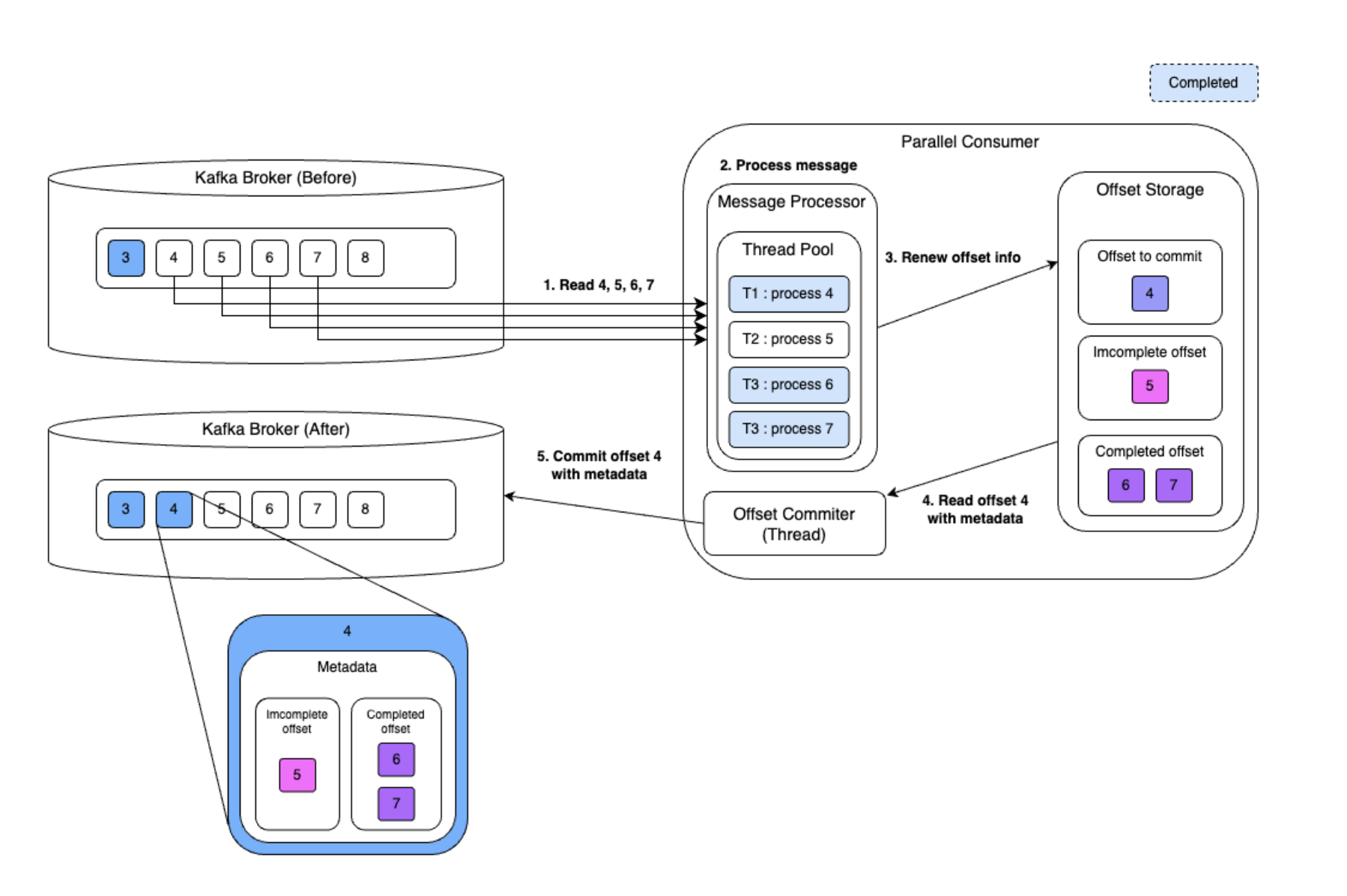
커밋을 할 때 처리한 메시지들을 분류해놓는다.
- 이전 메시지들까지 모두 처리헀음을 보장하는 offset (실제 커밋 단위)
- Parallel Consumer 에 의해서 처리는 되었으나 아직 이전 버전의 메시지는 처리되지 않아서 커밋이 될 수 없는 경우에 보관하는 Completed Offset
- 아직 Parallel Consumer 에 의해 처리되지 못한 메시지는 incompleted offset
이렇게 보관하므로 장애가 발생하고 다시 처리가 되야하는 경우에 incompleted offset 에서만 데이터를 가지고 오면 된다.
References:
'Apache Kafka' 카테고리의 다른 글
| Kafka 에서 신뢰성을 주는 방법 (0) | 2023.12.28 |
|---|---|
| Kafka Consumer 에서 커밋을 하는 방법 (0) | 2023.12.27 |
| Kafka Producer Client Internals (0) | 2023.12.27 |
| Kafka Consumer 관련 기타 정리 (0) | 2023.12.27 |
| 카프카 브로커 운영체제 튜닝하기 (0) | 2023.12.27 |