Generative AI
Q) Generative AI 의 정의는 뭔데? 인간이 만든 Content 에 대해 패턴을 파악해서 데이터를 생성할 수 있다는건가?
Generative AI는 기계 학습의 한 분야로, 주어진 데이터에서 패턴을 학습하여 새로운 데이터를 생성하는 능력을 가진 인공지능 시스템을 의미한다.
이러한 시스템은 입력 데이터를 기반으로 하여 인간이 만든 콘텐츠와 유사한, 하지만 완전히 새로운 콘텐츠를 생성할 수 있음.
Generative AI의 주요 특징:
- 데이터 이해: Generative AI는 다양한 데이터(텍스트, 이미지, 음악 등)에서 복잡한 패턴과 구조를 이해한다.
- 새로운 콘텐츠 생성: 학습된 패턴을 바탕으로 완전히 새로운 콘텐츠를 만들어내며, 이는 원본 데이터와 비슷하거나 완전히 새로운 형태일 수 있음.
Generative AI의 주요 기술:
- Generative Adversarial Networks (GANs): 두 네트워크가 상호 경쟁하면서 학습을 진행한다. 하나는 진짜와 같은 이미지를 생성하고, 다른 하나는 진짜와 가짜를 구분한다.
- Variational Autoencoders (VAEs): 데이터를 효율적으로 압축하고 재구성하여 새로운 데이터를 생성하는 방법임
- Transformers: 특히 텍스트 생성에서 강력한 성능을 보이며, GPT-3 같은 모델이 이에 속함.
Q) Parameter Efficient Fine Tuning(PEFT) 란?
대규모 언어 모델을 보다 효율적으로 특정 작업에 맞게 세부 조정하는 방법 중 하나임. 즉 Fine Tuning 중 하나의 방법
PEFT는 기본적으로 대규모 모델의 모든 매개변수를 재학습하지 않고, 소수의 추가적인 매개변수를 도입하거나 조정하여 특정 작업에 대한 모델의 성능을 향상시키는 기술이다.
PEFT는 모델의 복잡도와 학습 비용을 관리하는 데 있어 매우 유용함.
Transformer Networks
Q) 트랜스포머에서 Self-Attention 과 Mult-headed Self-attention 매커니즘이란?
Self-Attention"과 "Multi-headed Self-Attention" 매커니즘은 모델이 입력 시퀀스 내에서 각 단어 간의 관계를 이해하고 중요한 정보를 추출할 수 있도록 돕는 핵심 기술이다.
Self-Attention:
- Self-Attention 매커니즘은 입력 시퀀스 내의 모든 단어를 서로 비교하여, 각 단어가 시퀀스 내 다른 단어와 얼마나 관련이 있는지를 파악한다.
- 예를 들어, "The cat chased the mouse"라는 문장이 있을 때, "chased"라는 단어가 "cat"과 "mouse"와 어떻게 관련되어 있는지를 이해하는 것임.
- 이 과정은 각 단어에 대해 세 가지 벡터를 생성하여 수행된다.
- Query (Q) 벡터: 이 벡터는 주로 현재 단어가 다른 단어와 얼마나 관련이 있는지를 비교하는 데 사용된다.
- Key (K) 벡터: 다른 모든 단어에 대해 생성되며, 현재 단어의 Query 벡터와 비교된다.
- Value (V) 벡터: 실제로 정보를 담고 있는 벡터로, 각 단어에 대한 실제 정보를 나타낸다.
- 그러니까 Key 벡터가 단어를 나타내고 Query 벡터는 유사도 비교하고 싶은 단어라고 생각하면 됨.
- 이 벡터들은 입력 벡터로부터 생성되며, 각 단어의 Query 벡터는 다른 모든 단어의 Key 벡터와의 내적(dot product)을 통해 유사도 점수를 계산한다. 이 유사도 점수는 softmax 함수를 통해 정규화되어 각 단어가 시퀀스 내 다른 단어와 어떤 관계를 가지는지에 대한 가중치로 변환된다. 마지막으로, 이 가중치를 사용하여 Value 벡터들의 가중합을 계산하고, 이를 출력 벡터로 사용한다. 이 결과는 문장에서 각 단어가 어떤 단어와 더 관련이 깊은지를 반영한 출력을 생성한다.
Multi-headed Self-Attention:
- Multi-headed Self-Attention은 Self-Attention의 확장된 형태로, 다양한 "attention heads"를 사용하여 정보를 다양한 방식으로 병렬 처리한다. 그러니까 headed 는 문장을 바로바는 다양한 관점이나 차원을 제공하는거다.
- 예를 들어, 한 "head"는 문법적 관계를 중점적으로 파악하는 반면 다른 "head"는 의미적 관계를 더 깊게 파악할 수 있다.
- 각 "head"는 동일한 입력에서 다른 Q, K, V 벡터 세트를 생성하고, 각각의 세트는 서로 다른 관점에서 입력 데이터를 해석한다. 이러한 다양한 관점은 모델이 더 풍부한 정보를 학습할 수 있도록 돕는다.
- 모든 "head"에서 계산된 출력은 연결(concatenated)되고, 이는 최종 출력 벡터를 생성하기 위해 추가적인 투영층을 거친다. 이 과정을 통해 트랜스포머는 시퀀스 내 각 위치에서 중요한 정보를 효과적으로 포착하고, 이를 바탕으로 더 정확한 출력을 생성할 수 있다.
- 이러한 매커니즘은 특히 복잡한 문맥을 이해하거나, 문장 내 다양한 요소들 사이의 복잡한 상호작용을 모델링하는 데 유용하다.
Q) transformer 모델의 foundation 이 컴퓨터 비전 모델에도 많은 영향을 미쳤어?
맞다.
트랜스포머 모델의 기초적인 원리와 구조는 컴퓨터 비전 분야에도 많은 영향을 미쳤음. 처음에는 자연어 처리(NLP) 분야에서 주로 사용되었던 트랜스포머 모델이지만, 그 효율적인 정보 처리 방식과 유연성 때문에 비전 태스크에도 적용되기 시작됨.
트랜스포머 모델은 주로 Self-Attention 매커니즘을 사용하여 입력 시퀀스의 모든 요소 간 상호작용을 허용함. 이러한 특성이 비전 분야에서도 유용하다는 것이 밝혀지면서, 이미지를 여러 개의 패치로 나누고 각 패치를 트랜스포머 모델의 입력으로 사용하는 방식이 개발되었음.
- 그러니까 트랜스포머는 전체적인 맥락을 이해하는데 강력함. + 트랜스포머는 다양한 크기와 형태의 데이터에 적용할 수 있는 높은 유연성을 가짐 + 트랜스포머 구조는 입력의 길이나 크기에 관계없이 유사하게 작동할 수 있음.
Vision Transformer (ViT) 가 있음. ViT는 이미지를 일련의 패치로 분할하고, 각 패치를 NLP에서의 토큰처럼 처리하여 트랜스포머의 입력으로 사용한다 .
이 방법은 전통적인 CNN(합성곱 신경망)이 아닌 순수한 트랜스포머 구조를 사용하여 이미지를 분석하고, 패치 간의 복잡한 관계와 패턴을 학습할 수 있음.
Q) 많은 언어 모델중에서 나에게 적합한 걸 고르는 방법은 뭐야? Evaluation 을 해야하고, 사이즈를 고려해서 선택해야하는건가?
고려사항은 다음과 같다:
- 목표와 용도 이해하기:
- 언어 모델을 사용하고자 하는 주요 작업(번역, 요약, 문장 생성 등)을 명확히 해야한다. 언어 모델 각각은 특정 작업에 더 강한 강점을 가지고 있을 수 있음. (물론 모든 작업을 더 잘하는 언어 모델도 있을 수 있겠지)
- 번역을 위한 모델은 Google 의 BERT 나 Facebook의 M2M-100, 요약을 위한 모델은 OpenAI의 GPT-3, Google의 T5(Text-To-Text Transfer Transformer), 문장 생성 모델은 GPT-3 등이 있다.
- 그리고 작업에 필요한 언어 범위, 정확도, 응답 시간 등을 고려해야함.
- 모델 성능 평가:
- 대부분의 언어 모델은 다양한 벤치마크 데이터셋에서의 성능 평가 결과와 함께 제공된다. 이러한 결과를 검토하여 모델의 성능을 파악할 수 있다.
- 벤치마크는 특히 모델이 언어 이해, 추론, 생성 등의 여러 작업에서 얼마나 효과적인지를 보여줌.
- 벤치마크 기준은 다음과 같다:
- 자연어 이해 벤치마크 (NLU):
- GLUE (General Language Understanding Evaluation): 다양한 NLU 작업을 포함하는 벤치마크로, 문장 동의어 판별, 문장 관계 추론, 감정 분석 등을 포함한다.
- SuperGLUE: GLUE의 후속작으로 더 어려운 작업을 포함하며, 추론 능력과 더 복잡한 언어 이해를 평가한다.
- 기계 번역 벤치마크:
- BLEU (Bilingual Evaluation Understudy): 번역된 텍스트와 참조 번역 간의 단어와 구 구조의 일치를 평가한다.
- METEOR, ROUGE, TER: BLEU와 유사하게 번역 품질을 평가하지만 각각 다른 방식으로 유연성과 정확성을 측정한다.
- 질문 응답 및 대화 시스템 벤치마크:
- SQuAD (Stanford Question Answering Dataset): 특정 문단에서 질문에 대한 정답을 찾는 능력을 평가한다.
- CoQA (Conversational Question Answering): 대화 형식의 질문에 연속적으로 응답하는 모델의 능력을 평가한다.
- 텍스트 생성 벤치마크:
- Perplexity: 모델이 얼마나 잘 텍스트를 예측하는지 측정하는 통계적 지표입니다. 낮을수록 좋다.
- Human Evaluation: 텍스트의 자연스러움, 응집성, 정보성 등을 인간 평가자가 평가한다.
- 포괄적인 벤치마크:
- The Pile: 다양한 도메인과 주제를 포함한 크고 다양한 데이터셋을 기반으로 언어 모델의 성능을 평가한다.
- Commonsense Reasoning Benchmarks: 상식을 바탕으로 한 추론을 평가하며, 모델이 일상적인 지식을 얼마나 잘 이해하는지를 측정한다.
- 자연어 이해 벤치마크 (NLU):
- 사용자 자체 평가: 구체적인 사용 사례에 대해 모델을 평가하고 테스트하여, 실제 사용 환경에서의 효과를 측정하면 된다.
- 모델 사이즈와 자원 요구사항:
- 모델 크기: 모델의 크기가 클수록 일반적으로 성능은 좋아지지만, 더 많은 계산 자원과 메모리를 요구한다. 따라서 사용 가능한 하드웨어 리소스를 고려하여 선택해야 한다.
- 인프라 비용: 큰 모델은 유지 관리 비용도 높을 수 있다.
- 확장성과 유연성:
- 확장 가능성: 더 많은 데이터나 복잡한 요구 사항을 처리할 수 있는지 평가한다.
- 적응성: 특정 작업에 맞게 모델을 미세 조정할 수 있는지 여부를 확인한다.
Prompt, Completion, Inference:
- LLM 모델에 지시하는 명령을 프롬포트라고 하며, Context Window 라고도한다.
- 모델이 명령(or 질문) 을 받고 결과를 내는 걸 Compeletion 이라고 한다.
- 모델이 결과를 내는 행동을 하는 걸 Inference 라고 한다.
Text generation before transformers
Transformer 모델이 개발되기 전에는 주로 RNN(Recurrent Neural Network)과 그 변형인 LSTM(Long Short-Term Memory) 및 GRU(Gated Recurrent Units) 같은 모델이 자연어 처리 태스크에 널리 사용되었음.
RNN은 시퀀스 데이터를 처리하는 데 강점을 가지고 있어, 텍스트 같은 연속적인 데이터에 자주 쓰였습니다. 하지만 RNN은 몇 가지 중요한 문제점들을 가지고 있었다:
- RNN과 그 변형들도 충분히 큰 데이터셋과 복잡한 문제에 대해서는 어느 정도 성능을 보여주었지만, 모델의 규모를 크게 확장하더라도 성능 향상이 뚜렷하지 않았음. 이는 구조적인 한계 때문에 복잡한 문맥을 잘 이해하지 못하는 데 기인한다.
RNN 의 구조적인 한계:
- 장기 의존성 문제 (Long-term Dependencies Issue):
- RNN은 시퀀스의 각 요소를 차례로 처리하면서 이전 단계의 정보를 현재 단계에 전달한다. 이론적으로는 모든 과거 정보를 기억할 수 있지만, 실제로는 시퀀스가 길어질수록 초기 정보가 희미해지는 경향이 있음. 따라서, 입력 시퀀스에서 멀리 떨어진 위치에 있는 중요한 정보(예: 문장의 주제나 맥락을 결정하는 키워드)가 현재 단계의 예측에 충분히 반영되지 않을 수 있다. 이는 특히 복잡한 문장 구조나 긴 문장에서 다음 단어를 정확하게 예측하는 데 문제를 일으킬 수 있다.
- 그라디언트 소실 문제 (Vanishing Gradient Problem):
- RNN은 시퀀스를 처리할 때 그라디언트(모델의 가중치를 업데이트하는 데 사용되는 수치)가 네트워크를 거슬러 올라가면서 점점 작아지는 경향이 있다. 이 문제로 인해, 모델이 긴 시퀀스의 초기 부분에서 발생하는 오류에 대해 학습하기 어려워짐. 즉, 학습 과정에서 중요한 초기 정보가 사라지고, 이로 인해 모델이 시퀀스의 뒷부분에 과도하게 의존하게 되며, 결과적으로 초기 단어에 기반한 다음 단어 예측이 부정확해질 수 있다.
- 업데이트 병목현상 (Update Bottleneck):
- RNN은 각 시간 단계마다 순차적으로 계산을 수행하므로, 한 단계의 출력이 다음 단계의 입력으로 직접적으로 연결된다. 이 구조는 정보가 시간에 따라 손실될 가능성을 높이며, 모든 이전 정보를 효과적으로 유지하고 활용하는 데 한계를 가지게 한다. 특히, 시간이 지남에 따라 이러한 업데이트 병목현상은 정보의 흐름을 제한하고, 모델이 새로운 입력에 기반한 예측을 수행하는 데 필요한 적절한 컨텍스트를 형성하는 것을 방해할 수 있음.
트랜스 포머 모델을 소개한 Attention is All You Need 논문의 주요 특징:
- 어텐션 메커니즘 (Attention Mechanism):
- Transformer 모델의 핵심은 '어텐션 메커니즘' 임. 이는 모델이 입력 데이터의 다른 부분에 가중치를 두어 중요한 정보에 집중할 수 있도록 한다. 특히, '멀티-헤드 어텐션(Multi-Head Attention)'이라는 기법을 통해 다양한 위치에서 정보를 병렬적으로 집중적으로 처리할 수 있다.
- 순차적 연산의 제거:
- 기존의 RNN이나 LSTM은 입력 시퀀스를 순차적으로 처리해야 했으나, Transformer는 이러한 순차적 처리를 필요로 하지 않는다. 이는 입력 데이터 전체를 한 번에 처리함으로써 학습과 예측 과정에서 병렬 처리가 가능하게 되어, 효율성과 속도를 크게 향상시켰다.
- 스케일링 가능한 모델 구조:
- Transformer는 높은 수준의 병렬 처리 능력과 효율적인 학습 메커니즘으로 인해, 매우 큰 데이터셋과 복잡한 모델 구조에 적용 가능하며, 이를 통해 더 정교하고 깊은 학습이 가능하다.
Transformers architecture
트랜스포머 아키텍처의 특징:
- 문장 내의 모든 단어의 문맥과 관련성을 파악할 수 있다는 거임.
- 단순히 앞 뒤 단어의 맥락만 아는게 아니라 모든 단어와의 연관성을 파악할 수 있다는거.
- Transformer 는 RNN 과 달리 문장 내의 앞뒤 단어의 연관성만 파악하는게 아니라 모든 단어와의 연관성을 파악할 수 있음. 이를 Attention Mechanism 이라고 한다.
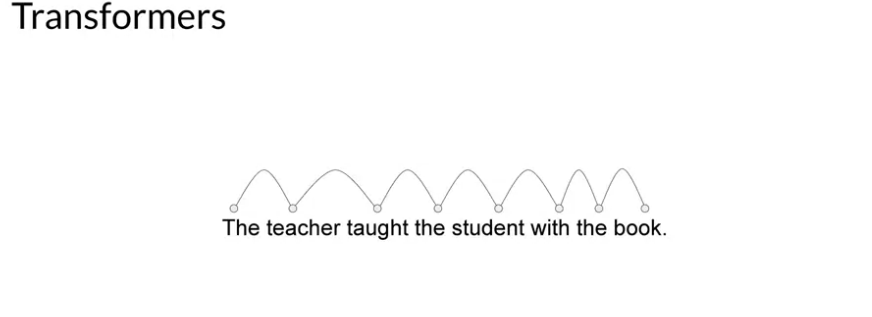

Self Attention 의 Attention Map:
- Attention Map 이라는건 어떤 단어가 문장내의 단어들과 얼마나 연관이 있는지 나타냄.

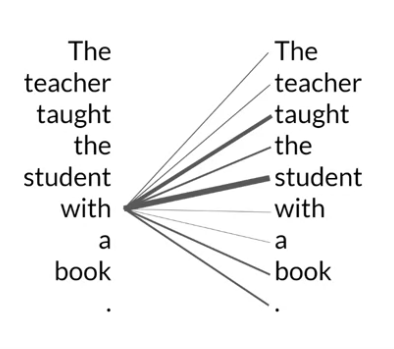
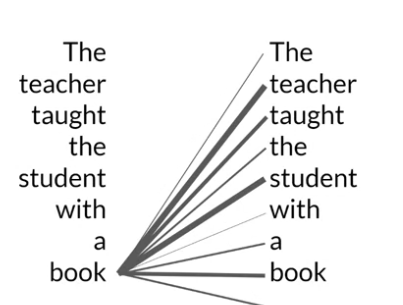

Trnasformer Architecture:
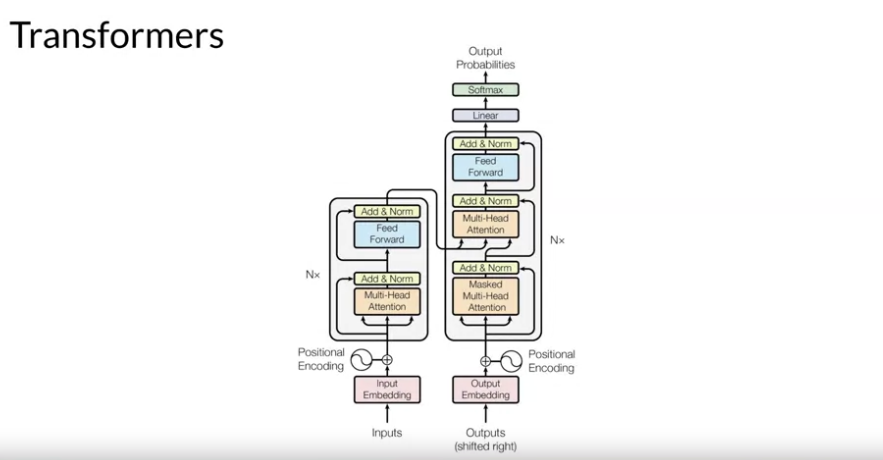
Transformer Architecture High Level View:
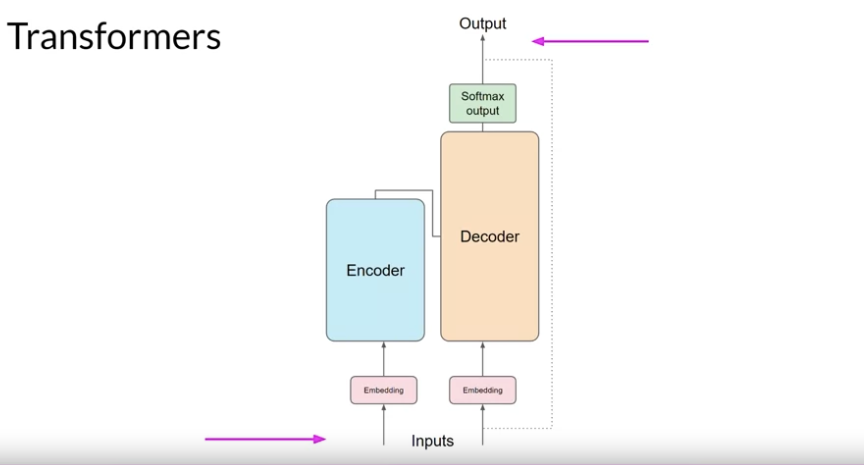
- Transformer 모델은 크게 두 부분으로 구성되어 있는데, 이는 Encoder 부분과 Decoder 부분임. 각 부분은 입력 데이터를 처리하고, 번역이나 텍스트 생성과 같은 작업을 수행하기 위해 서로 상호 작용한다.
-
- 입력과 임베딩 (Inputs and Embeddings):
- 입력: Transformer 모델은 텍스트 입력을 받는다. 이 텍스트는 먼저 토큰화되어 개별 단어나 문자 단위로 나누어진다.
- 임베딩: 각 입력 토큰은 임베딩 과정을 통해 고정된 크기의 벡터로 변환된다. 이 벡터는 해당 단어의 의미와 문맥적 정보를 수치적으로 표현하게 됨. 또한, 위치 인코딩(Positional Encoding)이 추가되어 각 단어의 순서 정보가 벡터에 포함되도록 한다. 위치 인코딩은 모델이 단어의 순서를 이해하는 데 중요한 역할을 한다.
- Positional Encoding 은 단어의 위치 값을 벡터로 나타낸 것. 단어의 위치에 따른 문맥 정보가 있으니까 이걸 이용한다.
-
- 인코더 (Encoder):
- 벡터로 변환된 텍스트는 멀티-헤드 어텐션 레이어를 통해서 여러 관점으로 텍스트 의미가 분석되고 벡터로 표현된다. 그리고 그걸 최종적으로 하나로 합쳐지는 벡터로 표현되는거임. 최종적으로 표현되는 벡터는 각 단어의 의미와 문맥의 의미가 풍부하게 표현되는거고.
- 구성: 인코더는 여러 개의 인코더 레이어를 쌓아 구성된다. 각 레이어는 주로 멀티-헤드 어텐션 메커니즘과 피드 포워드 신경망으로 구성된다.
- 멀티-헤드 어텐션: 이 메커니즘은 헤더에 있는 기준에 따라서 입력된 모든 단어 사이의 관계를 동시에 평가한다. 여러 개의 어텐션 "헤드"가 다양한 관점에서 정보를 수집하고 처리하여, 단어 간의 복잡한 의존성을 파악할 수 있게 한다. (12-100개의 레이어를 표준적으로 쓴다고 함.)
- 이 Self Attention 레이어가 학습해서 가중치가 매겨지는 곳임.
- 피드포워드 신경망: 어텐션 메커니즘을 통해 얻은 정보를 바탕으로, 각 단어에 대한 새로운 표현을 생성한다.
-
- 디코더 (Decoder):
- 구성: 디코더 역시 여러 개의 디코더 레이어로 구성된다. 각 레이어는 멀티-헤드 어텐션, 인코더-디코더 어텐션, 그리고 피드포워드 신경망을 포함한다.
- 멀티-헤드 어텐션: 디코더의 이 부분은 디코더 입력 사이의 내부 관계, 즉 이전에 생성된 출력들 간의 관계를 분석한다.
- 인코더-디코더 어텐션: 이 부분에서 디코더는 인코더의 출력을 참조하여 입력 문장과 현재 생성 중인 출력의 관계를 파악한다.
- 피드포워드 신경망: 최종적으로, 디코더는 모든 정보를 통합하여 다음 단어를 예측한다.
- 4. 출력 (Output):
- 소프트맥스 출력: 디코더의 마지막 레이어에서 생성된 각 단어의 벡터는 소프트맥스 레이어를 통해 실제 단어로 변환된다. 이 과정에서 모델은 가장 가능성 높은 다음 단어를 선택한다.
Q) 입력 텍스트를 토큰화를 해서 임베딩 하는 이유는?
머신러닝 모델은 숫자만 처리할 수 있다. 텍스트는 그래서 숫자로 변환시켜야함. 이게 tokenize 임.
변환되는 숫자는 내뱉을 수 있는 단어들을 숫자로 매핑된 딕셔너리에서의 위치를 나타낼거다.
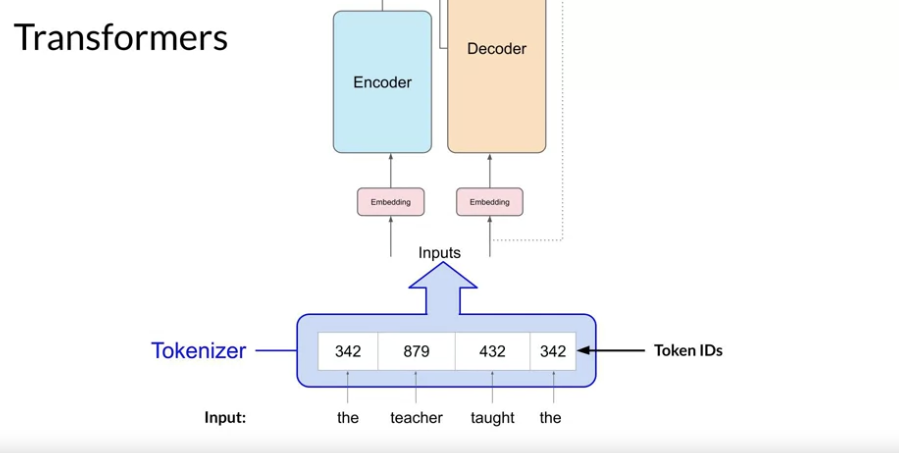
Tokenizer 의 방법은 많을 것.
- 일반적인 방법은 하나의 단어를 하나의 토큰과 매칭하는 방법이겠지만
- 다른 방법은 단어의 일부를 토큰과 매칭시키는 방법이다.
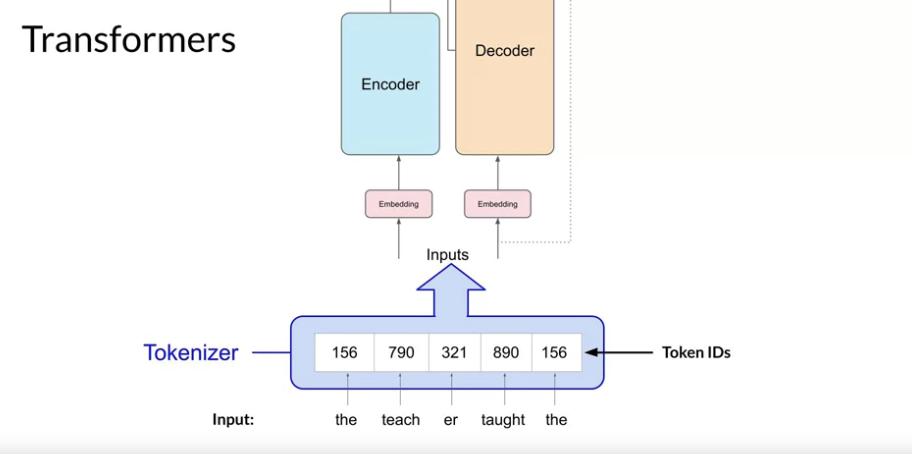
Q) 임베딩 된 이후에는 벡터로 변환되는거야? 벡터로 변환되면 단어의 의미와, 문맥을 표현할 수 있게 되는건가?
맞다.
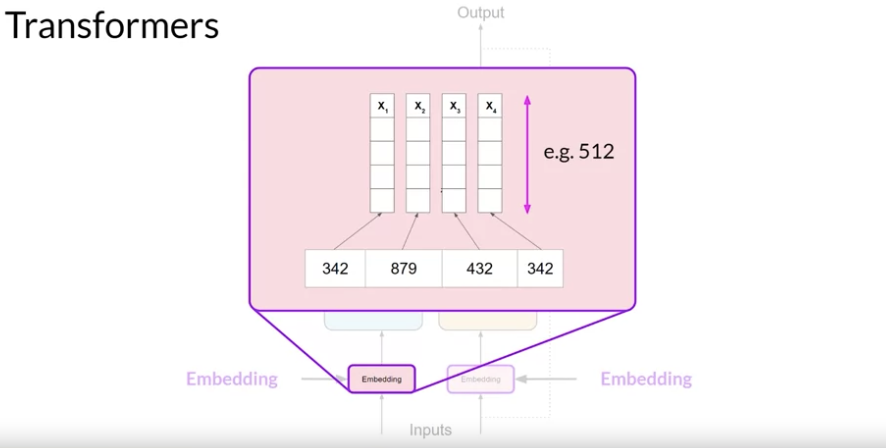
Transformer 모델에서 임베딩 과정은 입력된 단어들을 고정된 크기의 벡터로 변환하는 단계.
- 트랜스포머에서는 512개의 벡터 사이즈를 사용함. 이 벡터 크기는 벡터 차원을 말하며 각 단어를 나타내는 데 사용되는 특성이다. 즉 벡터 차원이 클수록 단어를 포착할 수 있는 다양성을 나타낸다.
유사한 의미를 가진 단어들은 벡터 공간에서 서로 가까운 위치에 배치되는 경향이 있음.
Transformer 모델의 임베딩에는 위치 인코딩(Positional Encoding)이 추가되어 각 단어의 위치 정보가 포함된다. 위치 인코딩은 입력 시퀀스 내에서 단어의 상대적 또는 절대적 위치를 모델에 제공하여, 문맥에 따라 단어의 의미가 어떻게 변할 수 있는지를 학습할 수 있게 돕는다. (즉 문맥적인 의미를 제공할 수 있게 됨.)
임베딩 과정에서 단어를 벡터로 변환하는 과정은 다음과 같다:
-
- 단어 토크나이징: 입력 텍스트는 먼저 토큰화 과정을 거쳐 개별 단어 또는 토큰으로 분리된다.
-
- 벡터 변환: 각 토큰은 사전에 정의된 임베딩 테이블을 통해 고차원의 벡터로 변환된다. 이 벡터는 초기에는 랜덤하게 할당되었다가, 모델 학습 과정에서 점차 최적화된다.
-
- 위치 인코딩 추가: 각 벡터에는 위치 인코딩이 추가되어, 모델이 단어의 순서와 문맥을 더 정확히 이해할 수 있게 된다.
Q) 벡터로 변환되는 과정은 Word2Vec 과 유사한거야?
맞다. 유사하다.
목적은 좀 차이가 있음:
- Word2Vec: 이 방식은 단어 간의 의미적 유사성을 포착하는 데 중점을 둠. 학습된 벡터는 단어 간 유사도 측정, 단어 클러스터링 등 다양한 NLP 작업에 활용될 수 있음.
- Transformer 임베딩: Transformer 모델의 임베딩은 해당 단어의 의미 뿐만 아니라 문장 내에서의 위치 정보를 함께 모델링함. 이는 모델이 전체적인 문맥을 이해하고, 문장의 의미를 합성하는 데 도움을 준다.
Q) Word2vec 이란? 단어를 임베딩하고 벡터로 표현한거야?
맞다.
Word2Vec은 단어를 벡터 형태로 표현하는 효과적인 방법 중 하나임.
대규모 텍스트 코퍼스에서 단어의 의미적 관계를 학습하여 각 단어를 고차원의 벡터로 변환한다.
Word2Vec의 목적은 텍스트 데이터를 수치적 형태로 변환하여, 컴퓨터가 이해할 수 있게 하는 거임.
이 벡터들은 단어 간의 의미적 유사성을 반영하므로, 자연어 처리(NLP) 작업에서 유용하게 사용된다.
Q) 다음 이미지처럼 트랜스포머에서 텍스트는 벡터로 변환된 후 왜 인코더와 디코더에 같이 입력되는거야? 인코더에만 입력되야하는거 아니야?

이 이미지에서 보이는 구조는 인코더와 디코더가 "같은 입력"을 받는 것처럼 보이지만, 실제로는 두 구성 요소의 입력이 다름:
- 인코더 입력: 인코더에 입력되는 것은 원본 텍스트(또는 소스 텍스트)의 임베딩된 벡터임. 이는 전체 문맥의 의미를 포착하고, 문장의 구조적 관계를 모델에 제공한다.
- 디코더 입력: 디코더에 입력되는 것은 타깃 텍스트(번역, 요약 등의 목표로 하는 텍스트)의 시작 부분 또는 이전에 디코더가 생성한 출력의 임베딩된 벡터임. 디코더는 이 입력을 사용하여 다음 단어를 예측하고, 이 과정을 반복하여 최종 출력을 생성한다.
예시: 영어 문장을 프랑스어로 번역하는 작업을 수행하는 Transformer 모델
- 입력 문장(영어): "How are you doing today?"
- 목표 문장(프랑스어): "Comment ça va aujourd'hui?"
인코더의 입력:
- 인코더는 원본 텍스트인 영어 문장을 입력으로 받는다. 각 단어는 먼저 토큰화되고, 그 다음에 각 토큰은 임베딩 레이어를 통해 고차원 벡터로 변환된다. 여기에 위치 인코딩이 추가되어 각 단어의 순서 정보가 벡터에 포함된다.
- 임베딩된 벡터 예시:
- "How" → [0.2, -0.1, 0.4, ...]
- "are" → [0.1, 0.3, -0.2, ...]
- "you" → [0.3, -0.2, 0.5, ...]
- "doing" → [0.0, 0.1, -0.3, ...]
- "today?" → [-0.1, 0.4, 0.2, ...]
- 이 벡터들은 인코더를 통해 Multi headed Self Attention Layer 로 들어가서 처리되어서 문장 전체의 의미를 포착한 컨텍스트 벡터로 변환된다:
- 인코더는 여러 개의 레이어를 통해 이 임베딩된 벡터들을 처리한다.
- 각 인코더 레이어는 멀티-헤드 어텐션 메커니즘과 피드포워드 신경망을 포함한다.
- 멀티-헤드 어텐션: 이 단계에서는 각 단어 벡터가 문장 내 다른 모든 단어 벡터와의 관계를 분석하여, 문맥에 따른 정보를 포착한다. 예를 들어, "How"는 "doing"과 "today?"와 관련성이 높게 평가될 수 있다. 이 과정을 통해 단어들 간의 의미적 관계와 문맥적 정보가 강화된다.
- 피드포워드 네트워크: 각 위치에서 어텐션의 결과를 받아 독립적으로 처리하여, 각 단어의 최종 컨텍스트 벡터를 생한다.
- 컨텍스트 벡터의 생성:
- 인코더의 마지막 레이어를 통과한 후, 각 단어에 대한 컨텍스트 벡터가 생성된다. 이 벡터들은 입력 문장의 각 단어가 전체 문장의 문맥 내에서 어떻게 기능하는지에 대한 정보를 포함한다.
- 예를 들어, 인코더를 거친 "How"의 컨텍스트 벡터는 다음과 같을 수 있다:
- "How" → [0.5, -0.3, 0.6, ..., -0.4] (이 벡터는 문맥적 의미를 더욱 풍부하게 반영된거라고 알면된다.)
- 이 컨텍스트 벡터들은 디코더로 전달되어 출력 문장의 생성에 사용된다.
디코더의 입력:
- 디코더는 타깃 텍스트인 프랑스어의 번역을 생성하는 데 필요한 입력을 받는다. 초기 입력으로는 일반적으로 시작 신호를 나타내는 특별 토큰(예: "[START]")이 사용됨. 이 토큰은 디코더가 출력 시퀀스를 생성하기 시작할 때의 시작점을 표시하는 데 사용된다. "[START]" 토큰은 디코더가 언제 출력을 시작해야 하는지 알려주는 신호로 작용하며, 모델이 어디에서 문장 생성을 시작해야 하는지를 명확히 한다.
- 디코더는 이러한 입력과 인코더에서 전달받은 컨텍스트 벡터를 사용하여, 각 단계에서 다음에 올 프랑스어 단어를 예측하고 생성한다.
- 마지막으로 출력은 소프트맥스 레이어를 통해서 다음 단어의 확률 분포로 변환된다. 이 확률 분포는 가능한 모든 단어에 대한 확률을 계싼한다.
- 디코더에서의 입력 처리 예시:
- 초기: "[START]" → [0.5, -0.4, 0.3, ...]
- 첫 번째 단어 생성 후: "Comment" → [0.2, 0.1, -0.3, ...]
- 두 번째 단어 생성 후: "ça" → [-0.2, 0.3, 0.1, ...]
- 계속해서 다음 단어를 생성하며 입력을 갱신합니다.
- 애초에 학습 시킬 때 "How are you doing today" 과 "[START] Comment ça va aujourd'hui?" 는 세트로 학습될 것.
Q) 피드 포워드 신경망은 뭔데? 그리고 이걸로 인한 단어에 대한 새로운 표현은 뭔데?
피드 포워드 신경망을 통해 생성된 새로운 표현은 해당 단어가 포함된 문장 내에서의 문맥적 의미를 더욱 풍부하게 반영한다.
예를 들어, 어텐션 메커니즘은 다른 단어와의 관계를 파악하여 문맥적 정보를 제공하지만, 피드 포워드 네트워크는 이 정보를 바탕으로 각 단어의 구체적인 특성과 역할을 더욱 세밀하게 조정한다. 결과적으로, 이러한 처리 과정을 통해 각 단어 또는 토큰의 최종 출력이 결정되며, 이는 전체 문장의 의미 해석이나 다음 단계의 처리(예: 디코더에서의 번역 또는 텍스트 생성)에 중요한 기반 정보를 제공한다.
Q) Transfomer 는 Self Attention Layer 가 여러개 있는 Multi-headed Self Attention Layer 가 있잖아. 그럼 각 레이어별로 출력이 다양한거 아닌가? 어떻게 최종적인 벡터를 생성하는거야?
Transformer 모델의 핵심 구성 요소 중 하나인 멀티-헤드 셀프 어텐션(Multi-Head Self-Attention)은 여러 개의 어텐션 "헤드"를 사용하여 다양한 관점에서 입력 데이터를 분석한다.
이 과정을 통해 모델은 더욱 풍부하고 다양한 정보를 추출할 수 있으며, 이를 종합하여 최종적인 벡터를 생성한다.
멀티-헤드 셀프 어텐션의 작동 원리:
- 분할된 헤드: 멀티-헤드 셀프 어텐션은 입력 벡터를 여러 "헤드"로 분할하여 처리한다. 각 헤드는 입력 벡터의 서로 다른 부분집합을 사용하여 독립적인 어텐션 계산을 수행한다. 이렇게 하면 모델이 다양한 서브 스페이스에서 정보를 동시에 학습할 수 있다.
- 여기서 서브 스페이스는 특정 데이터의 특성이나 패턴을 포착하는데 집중된 정보의 "부분 집합"을 의미한다.
- 어떤 헤드는 문장에서의 주요 주체(subjects)에 집중할 수 있으며, 다른 헤드는 동사(verbs) 또는 다른 문법적 요소에 집중할 수 있다.
- 이러한 방식으로, 각 헤드는 입력 데이터의 다양한 특성을 독립적으로 처리하며, 이들 각각은 입력 데이터의 서로 다른 서브 스페이스를 탐색한다.
- 독립적인 어텐션 계산: 각 헤드는 자신에게 할당된 입력 벡터 부분을 사용하여 독립적으로 어텐션 스코어를 계산한다. 이 계산은 '쿼리(Query)', '키(Key)', 그리고 '값(Value)' 벡터를 사용하여 이루어진다. 쿼리는 현재 위치의 벡터, 키는 다른 모든 위치의 벡터, 값은 해당 키와 관련된 데이터를 나타냅니다. 각 위치에서 쿼리와 모든 키 간의 유사도를 계산하고, 이를 소프트맥스 함수를 통해 정규화하여 어텐션 가중치를 얻는다.
- 가중치 적용 및 합성: 계산된 어텐션 가중치는 각각의 값 벡터에 적용된다. 이후 모든 값 벡터는 가중합되어 각 헤드에서 하나의 출력 벡터를 생성한다.
최종 벡터 생성:
- 헤드의 결과 병합: 각 헤드에서 생성된 출력 벡터는 다시 하나의 큰 벡터로 연결(concatenation)된다. 이 연결 과정은 각 헤드가 독립적으로 학습한 정보를 통합하여 전체적인 문맥을 더 잘 이해할 수 있도록 한다.
- 선형 변환: 연결된 벡터는 추가적인 선형 변환(Linear Transformation)을 통해 다시 원래 차원의 벡터로 조정된다. 이 단계는 모든 헤드의 정보를 최종적으로 통합하고, 다음 레이어(예를 들어, 피드포워드 신경망 레이어)로 전달하기 위해 필요하다.
Q) 멀티 헤드 어텐션 구조 안에 셀프 어텐션 레이어가 있는거지? 그리고 셀프 어텐션 레이어에서 출력을 매기기 위해 3가지 매트릭스인 쿼리, 키, 벨류가 있는거고.
멀티-헤드 어텐션 구조는 여러 개의 셀프 어텐션 레이어(헤드)를 포함하고 있으며, 각각의 셀프 어텐션 레이어는 쿼리(Query), 키(Key), 밸류(Value) 세 가지 매트릭스를 사용하여 작동한다.
셀프 어텐션 레이어의 작동 원리:
- 셀프 어텐션 레이어는 입력으로 들어온 벡터들(단어의 임베딩)을 기반으로, 각 단어가 문장 내 다른 단어들과 어떻게 상호작용하는지를 계산한다. 이 과정은 다음과 같은 단계를 포함한다.
-
- 입력 벡터 변환: 입력된 벡터들은 세 개의 다른 가중치 매트릭스를 통해 변환되어 쿼리, 키, 밸류 벡터를 생성한다. 각각의 벡터는 입력 벡터와 다른 가중치 매트릭스의 곱으로 계산된다.
- 쿼리 매트릭스 (W^Q): 입력 벡터를 쿼리 벡터로 변환
- 키 매트릭스 (W^K): 입력 벡터를 키 벡터로 변환.
- 밸류 매트릭스 (W^V): 입력 벡터를 밸류 벡터로 변환
-
- 어텐션 스코어 계산: 각 쿼리 벡터는 모든 키 벡터와의 상호작용을 평가하여 어텐션 스코어를 계산한다. 이 스코어는 주로 쿼리와 키 벡터 간의 내적(dot product)으로 계산되며, 결과적으로 각 쿼리에 대해 키들의 중요도를 나타내는 스코어 벡터가 생성된다.
-
- 가중 밸류 벡터 계산 및 합성: 계산된 어텐션 스코어는 각 밸류 벡터에 적용되어, 각 쿼리에 대응하는 가중 밸류 벡터의 가중합을 생성한다. 이렇게 함으로써 각 입력 벡터가 문장 전체의 문맥을 반영한 새로운 벡터로 변환된다.
- 어텐션 스코어가 중요성을 나타내고, 벨류 벡터는 단어의 정보 의미를 나타내는 벡터라고 알면된다.
-
Q) 트랜스포머 아키텍처의 디코더에 있는 소프트 맥스는 뱉을 수 있는 자연어 토큰 중 하나가 되는건가?
맞다.
Transformer 아키텍처의 소프트맥스(Softmax) 단계는 디코더의 매 출력 단계에서 사용된다.
소프트맥스는 디코더가 생성한 벡터(피드 포워드 신경망의 출력)를 입력으로 받아, 각 가능한 단어(토큰)에 대한 확률 분포를 계산한다.
이 과정을 통해 모델은 다음에 올 가장 가능성 높은 단어를 선택한다.
Q) Encoder 와 Decoder 에서 여러개의 레이어가 있는 이유는 뉴럴 네트워크의 레이어를 더 쌓는 이유와 동일한건가?
맞다.
Transformer의 Encoder와 Decoder에서 여러 개의 레이어를 사용하는 이유는 전통적인 심층 신경망에서 레이어를 여러 개 쌓는 이유와 유사하다.
각 레이어는 모델의 표현력과 추상화 능력을 증가시키는 데 기여하며, 이는 다음과 같은 몇 가지 주요 이유에 기반한다.
- 복잡한 표현 학습:
- 심층 신경망의 각 레이어는 입력 데이터에 대해 점차적으로 더 높은 수준의 추상화를 수행한다. Encoder와 Decoder의 각 레이어는 입력 정보를 받아 더 정교하고 복잡한 표현을 생성한다. 초기 레이어는 비교적 단순한 패턴이나 관계를 학습할 수 있으며, 깊이가 증가함에 따라 더 복잡한 패턴과 문맥적 관계를 모델링할 수 있다.
- 성능 향상:
- Transformer 모델에서 레이어를 추가하는 것은 모델이 입력 데이터의 문맥을 더 깊이 이해하도록 돕는다. 특히, 멀티-헤드 어텐션 메커니즘을 통해 각 레이어는 다양한 시각에서 정보를 처리하고 통합할 수 있어, 더욱 정확한 문맥 판단이 가능해진다.
Q) Transformer 에서 임베딩 값은 벡터 데이터베이스에 저장하는 임베딩과 동일한건가? 각 임베딩 값이 비슷하면 서로 연관이 있는 단어인가?
Transformer 에서의 임베딩과 벡터 데이터베이스에 저장되는 임베딩은 비슷해보이긴 하나 목적의 차이가 있다:
Transformer의 임베딩:
- 동적 업데이트: Transformer의 임베딩은 모델의 학습 과정 중에 계속해서 조정되고 최적화된다. 이는 입력 데이터와 태스크의 특성에 따라 변할 수 있으며, 매우 동적임.
벡터 데이터베이스의 임베딩:
- 데이터베이스에 저장되는 임베딩은 대개 변하지 않는다. 예를 들어, 특정 단어나 이미지 등의 표현이 한 번 벡터로 변환되어 저장되면, 이후에는 그 벡터가 변경되지 않는 것이 일반적이다.
Q) 트랜스포머 아키텍처에서 GPT-3 에서 GPT-4 로 올라간다는 건 구체적으로 뭐가 달라지는거지?
모델 크기와 파라미터의 증가:
- GPT-3는 약 1750억 개의 파라미터를 가지고 있습니다. GPT-4에서는 이보다 더 많은 파라미터를 사용할 것으로 예상됨.
- 파라미터 수의 증가는 모델이 더 많은 데이터를 학습하고, 더 복잡한 패턴과 의미를 이해할 수 있게 해준다. 모델 크기의 증가는 일반적으로 예측의 정확도를 향상시키지만, 계산 비용과 메모리 요구량도 크게 증가시킬것
파라미터란?
- 벡터 크기 증가: 각 단어의 임베딩 크기(차원 수)를 늘리는 것. 예를 들어, GPT-3에서 임베딩 벡터의 크기는 12288차원까지 늘어났을 수 있다. 이렇게 벡터 크기를 늘리면, 각 단어를 표현하는데 사용할 수 있는 정보의 양이 증가하며, 더 세밀한 언어적 뉘앙스를 모델링할 수 있음.
- 레이어의 수 증가: Transformer 모델의 깊이를 늘리는 것. 이는 각 레이어가 입력 데이터를 다루는 방식에 더 많은 추상화 레벨을 추가하고, 더 복잡한 언어 구조를 학습할 수 있도록 한다. 예를 들어, 더 많은 어텐션 레이어와 피드포워드 레이어를 추가함으로써 모델은 입력 데이터의 더 깊은 의미를 추출할 수 있다.
- 셀프 어텐션 레이어 매트릭스 크기 증가: 각 셀프 어텐션 레이어에는 쿼리, 키, 밸류를 위한 세 개의 가중치 매트릭스와 출력을 위한 가중치 매트릭스가 포함된다. 이 매트릭스들의 크기가 증가하면 전체 모델의 파라미터 수도 크게 증가할것.
- 멀티-헤드 어텐션 내에서의 확장:
- 헤드 수의 증가: 멀티-헤드 어텐션 구조에서 각 헤드는 입력 데이터의 서로 다른 특성을 학습한다. 헤드의 수를 늘리면 모델은 동시에 더 많은 데이터 특성을 포착할 수 있으며, 이는 성능 향상에 기여할 수 있다.
Self Attention 매커니즘을 정리해보자.
트랜스포머 모델에서 셀프 어텐션을 계산하는 과정을 설명하기 위한 예시:
"The cat sat on the mat." 이 문장을 트랜스포머 모델로 처리하는 과정을 단계별로 살펴보자.
- 입력 벡터 준비
- 각 단어("The", "cat", "sat", "on", "the", "mat")는 초기 임베딩 벡터로 표현됩니다. 이 벡터들은 단어의 기본 의미를 포함한다.
- Query, Key, Value 벡터 생성:
- 각 임베딩 벡터는 세 가지 벡터로 변환됩니다: Query 벡터(Q), Key 벡터(K), Value 벡터(V). 이 변환은 각각 다른 훈련된 가중치 행렬을 사용하여 수행된다.

- 연관도 점수 계산:
- 예를 들어, "cat"이라는 단어의 Query 벡터(Q2)를 사용하여 문장의 모든 단어의 Key 벡터(K1, K2, K3, ..., K6)와 내적 연산을 계산한다. 결과는 각 단어가 "cat" 과 얼마나 관련이 있는지를 나타내는 점수로 나타낸다.
- 소프트맥스 정규화:
- 계산된 점수는 소프트맥스 함수를 통해 정규화되어 각 단어의 점수가 확률로 변환됩니다. 이 확률은 "cat" 단어의 컨텍스트에서 각 단어의 중요도를 나타낸다.

- 가중치가 적용된 Value 벡터 계산:
- 각 Value 벡터(V1, V2, V3, ..., V6)는 해당 단어의 소프트맥스 점수에 따라 가중치가 적용됩니다. 가중치가 적용된 Value 벡터들은 모두 합산된다.
- 최종 벡터 생성:
- 합산된 Value 벡터는 "cat"이라는 단어의 최종 컨텍스트 벡터로 사용된다. 이 벡터는 "cat"의 의미와 문장 내에서의 연관성을 종합적으로 판단된 점수이다. 이 값이 높다면 문장 내에서 중요하다고 판단되는 단어일거임.
정리하자면 이렇다:

Multi headed attention 방법의 이점:
"멀티 헤드 어텐션" 메커니즘은 Self Attention 매커니즘을 개선해서 모델의 성능을 개선시키다:
- 멀티 헤드 어텐션은 모델이 문장 내 다양한 위치에 동시에 집중할 수 있도록 한다. 예를 들어, "The animal didn’t cross the street because it was too tired"라는 문장에서 "it"이 어떤 단어를 참조하는지 알아내고 싶다고 가정해보자. 단일 어텐션 메커니즘에서는 "it"이 주로 그 자체의 단어에 의해 지배될 수 있지만, 멀티 헤드 어텐션을 사용하면 "it"이 "animal"을 참조하는지, 아니면 다른 단어를 참조하는지를 다각적으로 파악할 수 있다.
- 멀티 헤드 어텐션은 모델에 여러 "표현 부공간(representation subspaces)"을 제공한다. 트랜스포머는 각 인코더 및 디코더에 대해 여러 세트의 Query, Key, Value 가중치 행렬을 사용하며, 트랜스포머는 일반적으로 여덟 개의 어텐션 헤드를 사용하므로, 여덟 개의 세트가 생성된다. 각 세트는 초기에 무작위로 초기화되며, 훈련을 통해 각 세트는 입력 임베딩 또는 하위 인코더/디코더에서 온 벡터를 다른 표현 공간으로 투영하는데 사용된다. 이런 구조는 모델이 동일한 정보를 다양한 관점에서 처리할 수 있게 해, 보다 풍부하고 다층적인 정보 해석을 가능하게 한다.

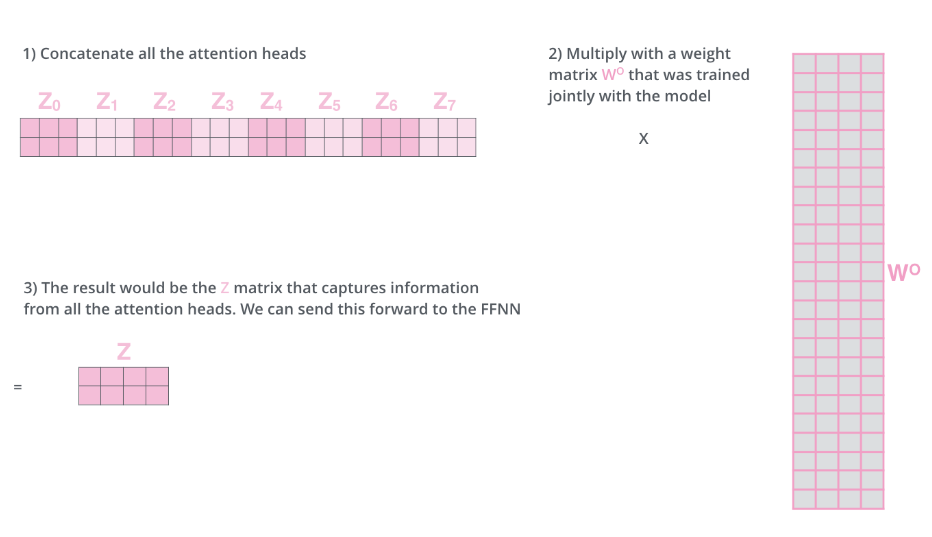
Q) Transfomer 는 8개의 encoder 와 decoder 세트로 인해서 8개의 최종 벡터를 내잖아. feed-forward layer 에 입력으로 던져줄 때는 하나의 최종 벡터로 결국 만들어야 할텐데 어떻게 결과를 내는거야?
트랜스포머 아키텍처에서 멀티 헤드 어텐션은 각각의 어텐션 헤드가 문장의 다른 측면을 병렬로 처리하여 여러 벡터를 생성한다.
그렇게 해서 생성된 각각의 벡터들은 최종적으로 하나의 벡터로 결합되어야한다.
이 과정은 멀티 헤드 어텐션의 결과물을 통합하고, 다음 단계인 피드-포워드 레이어로 전달하기 위해 필요하다.
아래는 결합 과정에 대한 설명이다:
-
- 각 헤드의 출력:
- 멀티 헤드 어텐션에서 각 헤드는 독립적으로 입력 벡터를 처리하여 출력 벡터를 생성한다. 이때 각 헤드는 서로 다른 가중치 행렬을 사용하여 Query, Key, Value 벡터를 생성하고, 이를 기반으로 어텐션 메커니즘을 수행한다. 결과적으로 각 헤드는 입력 데이터의 다른 특성을 강조한 출력 벡터를 만들어낸다.
-
- 출력 벡터의 결합:
- 각 헤드가 생성한 벡터들은 하나의 큰 벡터로 결합된다. 이 과정은 일반적으로 모든 헤드의 출력 벡터들을 연결(concatenation)하는 방식으로 이루어진다. 예를 들어, 각 헤드가 64차원의 벡터를 출력하고, 8개의 헤드가 있을 경우, 이들을 연결하면 512차원의 하나의 큰 벡터가 생성된다.
-
- 선형 변환:
- 단순히 벡터들을 연결하는 것만으로는 최종적으로 필요한 벡터 형태를 완성하지 못한다. 연결된 큰 벡터는 추가적인 선형 변환을 거치게 된다. 이 변환은 일반적으로 학습 가능한 가중치 행렬을 사용하여 수행된다. 이 행렬은 멀티 헤드 어텐션의 결과물을 적절한 차원과 형태로 조정하여, 다음 레이어인 피드-포워드 레이어에 적합하게 만들어준다.
-
- 피드-포워드 레이어로의 전달:
- 선형 변환을 거친 벡터는 이제 피드-포워드 레이어로 전달된다. 피드-포워드 레이어는 각 위치에서 동일하게 적용되는 완전 연결된(즉, 각 입력이 모든 출력에 연결된) 레이어로, 입력 벡터의 각 요소를 비선형적으로 변환하여 더 복잡한 특성을 추출할 수 있게 한다.


- 이 그림에서는 "it"라는 단어가 다른 단어들과 어떤 관계를 맺고 있는지 여러 색의 선으로 표시되어 있음. 각 선의 색은 다른 어텐션 헤드를 대표하며, 각 헤드는 특정 관점에서의 연관성을 측정함.
- 여기에서 보듯이, 하나의 어텐션 헤드는 "it"과 "animal" 사이의 연관성에 집중하고 있으며(주황색 선), 다른 헤드는 "it"과 "tired" 사이의 연관성에 주목하고 있음(녹색 선). 이는 "it"이 문장에서 "animal"을 가리킬 수도 있고, "tired"의 상태를 설명할 수도 있다는 것을 모델이 인식하고 있음을 의미한다.
- 멀티 헤드 어텐션의 이점 중 하나는 모델이 단일 헤드로는 얻을 수 없는 다양한 문맥적 정보를 포착할 수 있다는 것임. 이 예에서 "it"이라는 대명사가 문장 내에서 어떤 역할을 하는지, 또 어떤 단어를 참조하는지를 다각도로 파악할 수 있.
- 모든 어텐션 헤드의 결과는 결합되어 "it"의 최종적인 벡터 표현을 형성한다. 이 벡터는 "it"가 전체 문장 내에서 어떻게 기능하는지를 종합적으로 반영하며, 이 정보는 트랜스포머의 다음 단계로 전달된다.
Generating text with transformers
Q) 트랜스포머에서 다음 텍스트를 계속해서 예측하면 끝이 안나지 않나? 어떻게 텍스트 생성을 멈추는거지?
트랜스포머 아키텍처를 사용하는 모델은 입력된 텍스트에 기반하여 다음 텍스트를 예측하는 과정을 반복적으로 수행한다.
그렇지만 실제로 이러한 텍스트 생성이 무한정 계속되지는 않는다. 텍스트 생성을 멈추는 방법은 몇 가지가 있다:
- 최대 길이 설정: 생성할 텍스트의 최대 길이를 미리 정한다. 모델이 이 최대 길이에 도달하면 텍스트 생성을 멈춘다.
- 종료 토큰 (End Token): 특정 토큰을 생성 종료의 신호로 사용한다. 모델이 이 토큰을 생성하면 더 이상의 텍스트를 생성하지 않고 작업을 종료한다.
- 사용자 정의 규칙: 특정 조건이 충족될 때 생성을 멈추는 규칙을 설정할 수 있다. 예를 들어, 문맥상 논리적으로 완성된 문장이나 문단을 인식하여 생성을 중지할 수 있음.
Q) GPT-3 와 GPT-4 같은 경우는 어떤 학습 데이터 셋으로 트레이닝 된거야? 그리고 GPT-4 같은 경우는 파인튜닝도 된거지?
하나의 문장을 쪼개고 쪼개서 다음 단어는 뭐가 오는지 예측하는 식으로 학습 데이터를 구성하는 방법으로 학습 데이터를 구성함.
예를 들어, 문장 "The quick brown fox jumps over the lazy dog"를 가지고 학습을 할 때, 다음과 같은 입력과 타깃 쌍을 만들어 낼 수 있음:
- 입력: "The", 타깃: "quick"
- 입력: "The quick", 타깃: "brown"
- 입력: "The quick brown", 타깃: "fox"
- 입력: "The quick brown fox", 타깃: "jumps"
- 입력: "The quick brown fox jumps", 타깃: "over"
- 입력: "The quick brown fox jumps over", 타깃: "the"
- 입력: "The quick brown fox jumps over the", 타깃: "lazy"
- 입력: "The quick brown fox jumps over the lazy", 타깃: "dog
이렇게 Input 만 주어지면 알아서 레이블을 자동으로 생성해서 학습하는 방법을 자가지도 학습 (self-supervised learning) 이라고 한다.
Q) 트랜스포머 모델의 변형이 있다고 한다. 각각의 특징은?
BERT (Bidirectional Encoder Representations from Transformers):
- 특징 및 목적: BERT는 양방향 트랜스포머를 사용하여 문맥을 더욱 풍부하게 이해할 수 있다. 이는 문장 내의 모든 단어를 동시에 고려하여 각 단어의 표현을 학습합니다.
- 사용처: BERT는 주로 자연어 이해(NLU) 작업에 사용된다. 예를 들어, 질문 응답 시스템, 감정 분석, 명명된 엔티티 인식(NER) 등에 효과적이다.
GPT (Generative Pre-trained Transformer)
- 특징 및 목적: GPT는 왼쪽에서 오른쪽으로 텍스트를 생성하는 방식의 트랜스포머이다. 미리 대규모 데이터셋으로 학습한 뒤, 특정 작업에 맞게 파인튜닝하여 사용할 수 있다.
- 사용처: 텍스트 생성, 번역, 요약과 같은 작업에서 사용되며, 그 외에도 다양한 자연어 처리 작업에 활용된다.
RoBERTa (Robustly Optimized BERT Approach)
- 특징 및 목적: RoBERTa는 BERT의 변형으로, 더 많은 데이터와 더 긴 학습, 더 큰 배치 사이즈 등을 통해 BERT보다 성능을 개선하였음.
- 사용처: 자연어 이해 작업에서 높은 성능을 보이며, 다양한 벤치마크에서 상위 성능을 나타낸다.
T5 (Text-To-Text Transfer Transformer)
- 특징 및 목적: T5는 모든 NLP 작업을 텍스트 생성 문제로 변환하여 처리한다. 이 접근 방식은 다양한 작업에 하나의 일관된 모델을 사용할 수 있게 한다.
- 사용처: 번역, 요약, 질문 응답 등 거의 모든 NLP 작업에 사용할 수 있다.
ViT (Vision Transformer)
- 특징 및 목적: ViT는 이미지 처리를 위해 트랜스포머 구조를 적용한 최초의 모델 중 하나이다. 이미지를 패치로 나누어 이를 트랜스포머에 입력으로 사용한다.
- 사용처: 이미지 분류, 객체 인식 등의 컴퓨터 비전 작업에 사용된다.
구조로 나뉘면 다음과 같다:
- Encoder Only 모델:
- 구조는 주로 정보를 처리하고 이해하는 데 적합하다. 예를 들어, 문장의 의미를 분석하거나, 문서 분류, 감정 분석, 명명된 엔티티 인식 같은 자연어 이해(NLU) 작업에 사용된다.
- 대표적인 예: BERT와 RoBERTa 같은 모델이 이 범주에 속한다.
- Decoder Only 모델:
- 이 모델은 트랜스포머의 디코더 부분만을 사용한다. 디코더는 주로 생성적 작업에 최적화되어 있으며, 각 시점에서 이전에 생성된 출력을 참고하여 다음 출력을 생성한다.
- 주요 사용처: 텍스트 생성 작업에 주로 사용됩니다. 예를 들어, 자동 번역, 텍스트 요약, 챗봇 대화 생성 등이 있다.
- 대표적인 예: GPT 시리즈가 이 범주에 속한다.
- Encoder-Decoder 모델:
- 인코더와 디코더 모두를 포함한다. 인코더는 입력 데이터를 처리하고, 디코더는 이 처리된 정보를 바탕으로 출력을 생성한다.
- 이 구조는 입력과 출력 사이의 복잡한 관계를 모델링해야 할 때 유용하다. 예를 들어, 기계 번역에서 원문을 입력으로 받고 번역문을 출력으로 생성하거나, 이미지 캡셔닝에서 이미지를 분석하여 설명 텍스트를 생성하는 작업 등에 사용된다.
- 대표적인 예: Google의 Transformer 모델, Facebook의 BART, Google의 T5 등이 이 범주에 속한다.
Q) Decoder Only 모델이 왜 텍스트 생성을 잘하는거야? Encoder-Decoder 모델이 더 잘한다고 생각했는데, 문장을 더 잘 이해했으니까 텍스트 생성도 더 잘해야하는거 아님?
Decoder Only 모델은 오직 생성에 초점을 맞추고 있음. 입력 문자열이 주어졌을 때 다음 텍스트는 무엇인지 작업에 특화되어 있기 때문에 생성된 텍스트가 더 자연스러운거임.
Decoder Only 모델은 텍스트를 이해하는 구성요소가 없긴하다. 질문같은 텍스트가 주어졌을 때 다음 단어는 뭐가 올까를 학습을 극한으로 한거임. 그래서 답변이 작성되게 되는거.
그러니까 모델은 '이해'하기보다는 입력된 텍스트에 따라 통계적으로 가능성 높은 출력을 생성하는거.
Prompting and Prompt Engineering
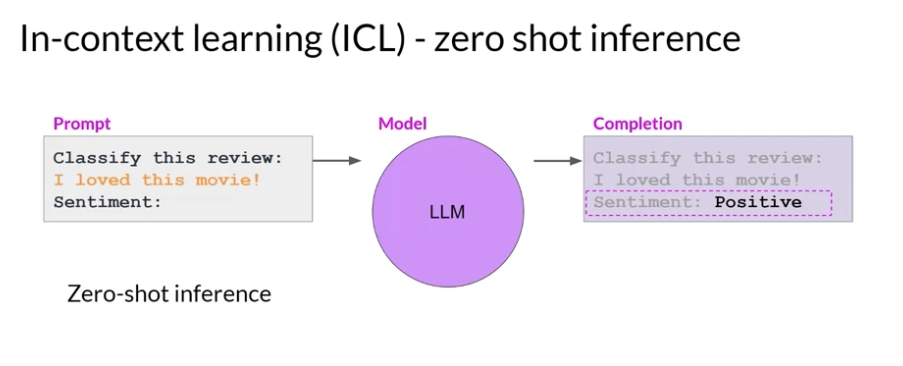
그냥 LLM 모델에게 질문을 하게 되면 원하는 답변을 얻지 못할 확률이 높다. 그래서 기본적으로 사용하는 방법은 In-context Learning 임:
- 프롬프트 내에 특정 예시들을 포함시키는 방식임. 그래서 모델이 이전에 본 예시들을 바탕으로 새로운 입력에 대한 반응을 생성하도록 돕는다.
- 여기서 더 나아가면 few-shot 프롬포트 기법으로 모델에게 몇 개의 예시를 추가적으로 넣어줘서 답벼능ㄹ 작성하도록 만들 수 있다.
In-context learning 예시 (zero-shot):
In-context learning 예시 (few-shot)
Review classification examples:
1. classify this review: "The acting was subpar, and the plot was predictable." sentiment: Negative
2. classify this review: "An absolute masterpiece, I was thoroughly impressed!" sentiment: Positive
classify this review: "I love this movie!" sentiment:예시를 더 넣을수록 일반적으로 더 잘 작동한다. 그럼에도 불구하고 원하는 기대수준에 도달하지 못했더라면 그때는 파인튜닝을 해야한다.
- 예시를 무한적 넣는건 힘드니까 그럼. Context Window 사이즈는 제한되어 있기 때문임.
Generative Configuration
Greedy vs Random sampling
- Greedy 방식의 예측: 출력 Softmax 함수에서 확률이 가장 높은 값이 출력됨. 문제는 같은 단어가 계속 반복되서 좀 창의적으로 대답할 수 없ㅇ므.
- Random 방식의 예측: 가장 높은 확률의 단어를 선택하는게 아니라, 확률대로 단어가 선택될 수 있는 방식임. 대신에 이 방식은 너무 창의적이라 갑자기 딴소리를 할 수 있게 되는거임.
모델이 다음 단어를 예측하는데 영향을 주는 파라미터들:
- Max new tokens: Maximum number of tokens a model can generate
- Sample top K: Random 샘플링을 적용할 떄 그래도 합리성을 주도록 만드는 파라미터임. top-k 개 중에서 랜덤으로 고르도록 만드는 설정
- Sample top P: 모델이 다음 단어를 예측할 때, 누적 확률이 p 이하가 되는 단어들만 고려하는 방법임. 확률이 높은 단어들부터 시작해서 누적 확률이 p에 도달할 때까지 단어들을 선택지에 포함시킨다.
- Temperature: 모델이 선택할 확률 분포에 영향을 준다. 높은 값일수록 랜덤성이 강해짐. 확률 분포를 더 평평하게 만들거나 더 뾰족하게 만드는 데 기여한다.
Generartive AI project Lifecycle
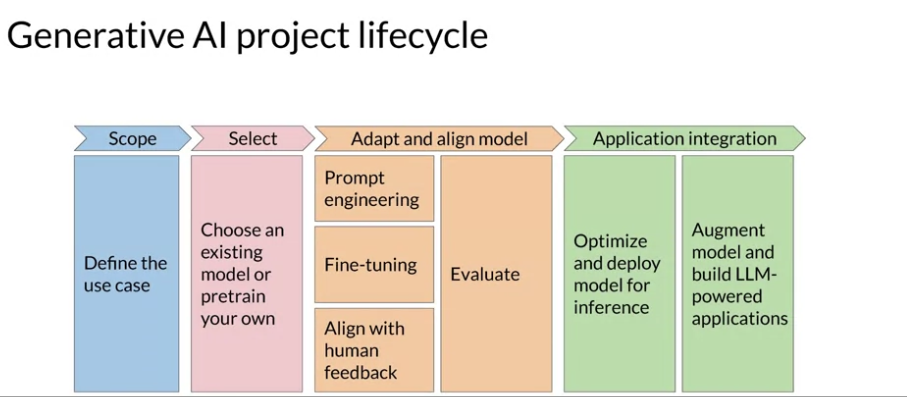
- Define the use case: LLM 은 다양한 일을 할 수 있을건데, 여기서 어떤 일을 원하는지 정하는 단계 (e.g Essay Writing, Summarization, Translation, Information retrieval, Invoke APIs and actions)
- Select: Traning 해서 모델을 사용할건지, 기존에 base 모델을 사용할건지 결정해야함. 그리고 모델 Size, Architecture, Performance 등을 고려해야한다:
- Size: 모델의 크기를 말하며, 이는 파라미터 수로 측정됨. 큰 모델은 더 많은 메모리를 가지고, 더 좋은 성능을 가질 거고, 계산이 더 오래 걸린다.
- Architecture: 각 작업마다 적합한 모델이 있다. 텍스트 생성과 대화형 AI 에서는 GPT 시리즈, 요약에서는 BART, T5, 번역에서는 T5, 문장 및 문서 분류에서는 BERT 등이 있을 것. 그러나 최근 GPT 가 나온 걸 보면 그냥 GPT 쓰면 될 듯.
- Performance: 모델이 자연어와 관련된 작업에서 얼마나 잘하는지를 나타내는 지표임.
- Adapt and align model:
- In Context Learning 을 이용한 Prompt Engineering 부터 시작하면 된다.
- 이렇게해도 부족하다면 FIne-tuning 을 하면 됨.
- 추가적인 파인튜닝 기법으로 Reinforcement learning with human feedback 이 있음. 이건 사람의 피드백을 활용하여 모델의 행동을 개선하고, 특정 작업에 대한 성능을 높이는 것을 목표로 하는거임.
- 이렇게 모델의 성능이 꽤 잘 나온다고 판단하면 evaluation 과정을 통해 평가해야함. evalutaion 과정과 모델의 성능을 개선하는 과정은 반복적이다라는 걸 알고 있어야함.
- Optimzied and deploy model for inference:
- 모델을 배포하는 과정임. 신뢰성을 보장해야하고, 좋은 사용자 경험을 제공해야한다.
- 모델을 배포하는 방식으로 사용할 수도 있지만, API 를 사용하는 방식도 있기는 할거임.
- Augment model and build LLM-powered applications:
- 사용자의 피드백을 수집하고 이를 기반으로 모델을 개선할 수 있는 피드백 루프를 구축해야한다.
- 모델이 잘못된 답변을 제공한 경우, 이를 교정하기 위해 새로운 데이터나 보충 데이터를 사용해 모델을 추가 학습 시킬 수 있는 프로세스를 구축해야함.
- 필요하다면 보조 모델을 이용할 수도 있음.
- 그리고 모델이 잘못된 답변을 제공할 경우를 대비한 에러 핸들링 메커니즘을 구축해야함.
- 모델의 성능을 지속적으로 모니터링할 수 있도록도 해야함.
- 모델이 불확실한 경우, 추가 정보를 요청하는 질문을 사용자에게 요청할 수 있도록도 할 수 있어야함.
Pre-training large language models
LLM 모델을 선택하는 방법은 크게 두 가지가 있음:
- 이미 존재하는 Foundation 모델에서 시작하기:
- 많은 오픈소스에 존재하는 모델로부터 시작하는 걸 말한다. (허깅 페이스나 Pytorch 커뮤니티에 이런 모델들이 있으니 써라고 함.)
- 처음부터 모델을 만들기
Model 을 제공해주는 Hubs 를 이용할 때의 장점:
- MOdel 에 대한 여러가지 정보를 제공해준다. 이를 바탕으로 우리 작업에 적합한 모델을 사용하면 됨.
- Model Details: 모델이 어느 유스 케이스에 적합한지, 모델의 제약 사항은 뭔지
언어 모델의 종류는 트랜스 포머의 변형에 따라서 다름:
- Encoder Only
- Decoder Only
- Encoder Decoder Model
Encoder Only Model
- 모델이 입력 문장에서 무작위로 일부 단어를 마스킹(masking)하고, 마스킹된 단어를 예측하도록 학습한다.
- 마스킹 된 단어를 예측하기 위해서 문장을 앞에서 읽고, 뒤에서 읽고 하면서 문장의 모든 문맥을 파악하는 능력을 가짐.
- 그래서 문맥을 이해해야하는 작업에 유리하다. (e.g Sentiment Analysis, Named Entity Recognition, Word classification)
- NER (Named Entity Recognition) 은 텍스트에서 특정 유형의 고유 명사를 식별하고 분류하는 것을 말함. "Barack Obama was born in Hawaii and was the president of the United States." 에서 인물, 장소를 뽑는 것.
- BERT 나 ROBERT 에서 주로 사용함.
Decoder Only Model:
- 모델이 주어진 단어 시퀀스에서 다음 단어를 예측하도록 학습한다.
- 학습할 때 주어진 단어들을 바탕으로 다음 단어를 예측하니까 단방향으로 문맥을 이해한다.
- Text Generation 에 적합하다. 다양한 작업에 유리함.
- GPT 시리즈가 이 계열이다.
Encoder + Decoder Model:
- 텍스트의 일부 구간을 마스킹하고, 이를 예측하는 방식으로 모델을 학습시킴. 이 방법은 특히 T5(Text-To-Text Transfer Transformer) 모델에서 사용된다.
- Span Corruption은 입력 텍스트에서 연속된 단어 구간(스팬, span)을 무작위로 선택하고, 그 구간을 마스킹한 후, 모델이 이 마스킹된 부분을 예측하도록 학습시키는 방법임. 이 과정에서 모델은 문맥을 이해하고, 마스킹된 부분의 원래 내용을 복원하는 능력을 향상시킨다.
- Span Corruption 은 연속된 단어 구간을 마스킹하므로, 모델이 더 큰 문맥을 이해하고, 긴 텍스트 구조를 학습하는 데 효과적임. 이게 Masked Language Modeling (MLM) 와의 차이점.
- 그래서 번역이나, 요약 작업, 질문 응답에 적합하다.
Span vs MSM:
- 세밀한 언어 이해가 필요한 작업(예: 문장 수준의 정밀한 분석)에서는 MLM이 유리할 수 있음.
- 문맥적 연속성이 중요한 작업(예: 긴 문장 이해, 문장 생성)에서는 Span Corruption이 더 적합할 수 있다.
Q) Model Hubs 에 있는 모델들은 학습 방법들이 달라? 그리고 이런 차이가 모델이 특정 작업에 유리하게 만드는거야?
맞다.
Q) LLM 에서 pre-training 은 뭔데?
기본 언어 이해 능력을 습득하는 것.
문법, 구문, 어휘, 의미 등 언어의 다양한 측면을 학습하고, 문맥에서 단어와 문장의 의미를 이해하고 예측할 수 있는 능력을 기르고, 다양한 주제와 도메인에 걸친 텍스트를 학습하여 넓은 범위의 언어 지식을 습득할 수 있다.
Computional challenges of training LLMs
LLM 을 트레이닝 시킬 때 가장 자주 만나는 문제는 OutofMemory 에러임.
하나의 파라미터 기준으로 고려해야하는 메모리 사이즈:
- 1 Parameter = 4Byte Float type.
- Model Parameter (Weight): 4 Bytes per parameter
- Adam optimizer: 8 Bytes per parameter (옵티마이저의 상태 정보를 말함)
- Gradients: 4 Bytes per parameters (Gradient Value 를 저장하는 것)
- Activation and temp memory: 8 Bytes per parameters (Activation Values 를 저장하는 거임.)
LLM 훈련 트레이닝에서 메모리 사이즈를 줄이는 방법:
- Quantization 32 비트의 부동 소수점 타입을 쓰지 말고, 16비트나 8비트 타입을 쓰는 방법이다.
- 32비트 float 타입의 값: 3.141592 는 16비트 float 타입의 값을 쓰면 3.140625 로 될 것.
- BFloat16 타입도 있다. FP32와 비교했을 때 지수 부분은 동일하지만 (둘 다 8비트), 가수 부분은 23비트에서 7비트로 줄어듬. BFloat16은 FP32와 동일한 지수 부분을 가지므로, 표현할 수 있는 숫자의 범위가 넓다는 장점이 있다.
- INT 형만 필요하다면 INT8 비트를 쓰는 방법도 있다.
대규모 모델의 학습:
- 500B 의 파라미터를 가진 모델의 경우에는 12,000 GB 메모리가 필요할텐데, 이제는 하나의 장비로는 부족해진다.
- 이 경우에는 Distriubuted Computing Techinique 를 이용함.
Efficient Multi-GPU Compute Strategies
DDP:
- DDP는 PyTorch에서 제공하는 데이터 병렬 학습 프레임워크로, 여러 GPU와 여러 노드에서 모델을 병렬로 학습시키는 방법임. 각 프로세스가 동일한 모델을 복사하여 각기 다른 미니 배치를 처리하고, 모든 프로세스가 그래디언트를 교환하여 모델 파라미터를 동기화함.
- DDP는 여러 GPU와 여러 노드를 사용하여 딥러닝 모델을 병렬로 학습시키는 데 유용하다.
- 작동 방식:
-
- 모델 복사: 각 GPU에 동일한 모델의 복사본을 할당한다.
-
- 데이터 분할: 입력 데이터를 여러 미니 배치로 나누어 각 GPU에 할당한다.
-
- 로컬 업데이트: 각 GPU가 자신의 미니 배치에 대해 순전파(forward pass) 및 역전파(backward pass)를 수행한다.
-
- 그래디언트 동기화: 각 GPU에서 계산된 그래디언트를 서로 교환하고 평균을 구하여 모든 GPU의 모델 파라미터를 동기화한다.
-
- 파라미터 업데이트: 동기화된 그래디언트를 사용하여 모델 파라미터를 업데이트한다.
-
- 주요 기능:
- DDP는 그래디언트를 동기화할 때 통신 비용을 최소화하도록 최적화 할 수 있다.
- 여러 노드와 여러 GPU에서 효율적으로 작동할 수 있도 할 수 있음.
- GPU 장애나 네트워크 문제 발생 시 견고하게 동작함.
Q) DDP 는 각 모델을 GPU 에 복사해서 사용하는거니까, LLM 학습에는 유용하지 않겠네? LLM 은 모델이 너무 크니까?
맞다.
모델의 복사본을 각 GPU에 할당하여 병렬로 학습하는 방식이기 때문에, 모델 크기가 매우 큰 대규모 언어 모델(LLM)에는 직접적으로 적용하기 어려움.
따라서, LLM을 훈련할 때는 DDP보다는 모델 병렬화(Model Parallelism)와 혼합된 형태의 접근이 필요하다.
Model Parallelism 는 모델 자체를 여러 GPU에 걸쳐 분할하여 각 GPU가 모델의 일부만을 처리하도록 하는 방법임.
예를 들어, 모델의 각 레이어를 여러 GPU에 분산시키거나, 각 GPU가 모델의 일부 파라미터를 담당하도록 하는 방법임.
PyTorch에서는 torch.distributed 모듈과 torch.nn.parallel 모듈을 사용하여 모델 병렬화를 구현할 수 있음.
큰 모델에서 병렬적으로 학습하는 기법인 Fully Sharded Data Parallel:
- FSDP는 PyTorch의 데이터 병렬화 기법 중 하나로, 모델 파라미터, 그래디언트, 옵티마이저 상태를 각 GPU에 분산시켜 메모리 사용을 최소화함.
- 이를 통해 매우 큰 모델도 단일 GPU의 메모리 한계를 넘어 훈련할 수 있음.
- 이건 Zero Redundancy Optimizer (ZeRO) 라는 기법에 의거한다.
- 작동 방식:
-
- 파라미터 샤딩: 모델 파라미터를 여러 GPU에 걸쳐 샤딩하여 저장한다. 각 GPU는 모델의 일부 파라미터만을 저장하고 나머지 파라미터는 필요할 때만 통신하여 사용한다.
-
- 옵티마이저 상태 샤딩: 옵티마이저의 상태(예: 모멘텀, RMSprop의 제곱 평균 등)를 샤딩하여 메모리 사용을 줄인다.
-
- 그래디언트 동기화: 역전파 동안 각 GPU는 자신의 그래디언트를 계산하고, 모든 GPU 간에 그래디언트를 통신하여 동기화한다.
-
- 파라미터 모드: 파라미터가 필요할 때만 메모리에 로드되며, 사용되지 않을 때는 해제되어 메모리를 절약한다.
-
Zero Redundancy Optimizer (ZeRO):
- 매우 큰 모델을 효과적으로 학습하기 위해 개발된 메모리 최적화 기법임.
- ZeRO는 파라미터, 그래디언트, 옵티마이저 상태를 샤딩하여 각 GPU의 메모리 사용을 최소화하고, 대규모 모델을 단일 GPU 메모리 한계를 넘어 학습할 수 있게 한다.
- ZeRO는 세 가지 주요 단계로 나눌 수 있다:
- ZeRO Stage 1: Optimizer State Partitioning
- ZeRO Stage 2: Gradient Partitioning
- ZeRO Stage 3: Parameter Partitioning
- ZeRO의 작동 방식:
- ZeRO Stage 1: Optimizer State Partitioning
- 옵티마이저 상태를 각 GPU에 분산 저장한다. 각 GPU는 전체 옵티마이저 상태 중 일부만을 저장하며, 업데이트 단계에서 필요한 부분만 통신한다.
- 이를 통해 옵티마이저 상태로 인한 메모리 사용을 크게 줄일 수 있따.
- ZeRO Stage 2: Gradient Partitioning
- 그래디언트를 각 GPU에 분산 저장한다. 각 GPU는 전체 그래디언트 중 일부만을 계산하고 저장하며, 동기화 단계에서 필요한 부분만 통신한다.
- ZeRO Stage 3: Parameter Partitioning
- 모델 파라미터를 각 GPU에 분산 저장한다. 각 GPU는 전체 파라미터 중 일부만을 저장하며, 순전파(forward pass) 및 역전파(backward pass) 단계에서 필요한 부분만 로드하여 사용한다.
- ZeRO Stage 1: Optimizer State Partitioning
Scaling laws and compute-optimal models
Model 의 성능을 올리는 일반적인 방법:
- Dataset 의 수를 늘리는 것
- Model 의 파라미터 수를 늘리는 것.
Model 을 훈련시킬 때 고려해야 할 요소로는 Compute Budegt 이 있다. 데이터의 수가 클수록, 모델의 크기가 클수록 예산이 더 많이 들어가기 때문임.
Compute budget for training LLMs:
- petaflops/s-day:
- 1 Petaflops는 1초 동안 10^15(1,000조) 부동소수점 연산을 수행할 수 있는 능력을 의미함.
- Petaflops/s-day는 이를 하루(24시간) 동안 사용하는 경우의 총 연산량을 의미한다.
- 대부분 모델 훈련에서의 손실 함수 계산과 역전파 알고리즘도 부동 소수점 연산을 사용함.
- NVIDIA v100s 가 8개 있으면 1 petaflops 를 달성할 수 있고, NVIDIA A100 GPU 가 2개 있으면 이를 달성할 수 있다.
가장 가성비 좋게 Model 을 훈련시키려고 하면 어느 정도가 적합할까?
- 더 많은 컴퓨팅 리소스를 사용하면 모델이 더 좋아지는 건 명확하다. 그러나 어느 시점 이후로는 비용 효율적이 아닐 수 있음.
- 관련된 여러 논문이 있다:
- Training Compute-Optimal Large Language Models
- 논문은 모델 훈련에 사용되는 계산 자원을 최적화하여 주어진 계산 예산 내에서 최대 성능을 달성하는 방법을 탐구함.
- 그러니까 큰 모델인데 주어진 예산에 의해 데이터 셋에 덜 학습되었더라면 더 작은 모델을 이용해서 동일한 성능을 달성할 수 있다는 논문임.
- 연구진은 모델 크기, 데이터셋 크기, 계산 자원 간의 관계를 설명하는 스케일링 법칙(scaling laws)을 제시한다. 여기서는 주어진 계산 예산 내에서 최적의 모델 크기를 결정하는 방법을 제시하는데 연구 결과, 너무 큰 모델은 계산 자원을 비효율적으로 사용하게 되고, 너무 작은 모델은 충분한 성능을 발휘하지 못하게 될거임.
- 논문에서는 모델 파라미터 수에 대한 데이터셋 크기의 비율이 약 20:1이 이상적이라는 결론을 도출했음. 모델의 성능을 최대화하기 위해, 데이터셋 크기는 모델 파라미터 수의 약 20배 정도가 되어야 한다는 것.
- Training Compute-Optimal Large Language Models
Pre-training for domain adaption
일반적으로 존재하는 LLM 을 사용하는 것보다 모델을 사전 훈련을 하는게 더 좋은 경우도 있다:
- 특정한 도메인에 특화된 언어를 쓰고, 표현을 해야하는 경우에 해당됨.
- 기존 LLM 은 Medical 이나 Legal 과 같은 분야의 데이터 셋으로 학습이 덜되어 있을 거니까 말하고 표현하는데 어색할 수 있을거임.
이 예시로 BloombergGPT 가 있음.
- 51% 의 financial Data 를 이용해서 학습했고, 49% 의 Public 일반 텍스트 데이터로 학습했음.
- 자세한 건 논문을 참고하면 됨. BloombergGPT: A Large Language Model for Finance
Q) 특정 도메인에 특화된 작업을 언어 모델에게 시키고 싶다면 모델을 처음부터 Pre-training 하는게 좋아? LLM 을 파인튜닝 하는 것보다?
싱황에 따라 다르다.
일반적으로 Fine tuning 이 비용 효율적임. 그러나 대량의 데이터가 있고, 도메인에 대해 특화를 진짜 시키고 싶다면 Pre-training 이 효율적일 수 있음.
LLM은 이미 대규모 데이터셋으로 훈련되어 언어의 일반적인 패턴과 구조를 잘 이해하고 있기 때문에 이를 바탕으로 특정 도메인에 특화된 데이터로 Fine-tuning을 하면, 그 도메인에 특화된 지식을 습득하면서도 기본적인 언어 능력을 유지할 수 있을거임.
Pre-training:
- 장점: 모델이 특정 도메인에 최적화될 수 있음.
- 단점: 엄청난 계산 자원과 시간, 대량의 데이터를 필요로 함. 일반적인 언어 모델을 처음부터 훈련시키는 것은 매우 비용이 많이 들고 복잡한 작업임.
Fine-tuning:
- 장점: 이미 대규모 일반 도메인에서 학습된 모델을 특정 도메인에 맞게 추가 학습시킴으로써 시간과 계산 자원을 절약할 수 있음. Fine-tuning은 일반적으로 상대적으로 적은 데이터와 자원으로도 좋은 성능을 얻을 수 있음.
- 단점: 도메인에 맞는 충분한 양질의 데이터를 확보해야 함.
Q) BloombergGPT 는 왜 파인튜닝보다 Pre-training 을 선택했을까?
금융 데이터가 대량으로 있어서 Pre-training 이 더 성능이 좋다고 판단한듯.
'Generative AI' 카테고리의 다른 글
| LLM In Production (feat: Project Pluto) (0) | 2024.05.26 |
|---|---|
| Generative AI with LLMs: Week 2 (0) | 2024.05.23 |
| LLM 어플리케이션 아키텍처 (1/2) (0) | 2024.04.30 |
| LangChain Chat with Your Data (0) | 2024.04.25 |
| LangChain for LLM Application Development (0) | 2024.04.15 |