
Q) LLM 에 fine tuning 을 잘못하면 catastrophic forgetting 문제가 발생해?
맞습니다.
LLM(대형 언어 모델)을 파인 튜닝할 때 catastrophic forgetting 문제가 발생할 수 있습니다.
이는 모델이 새로운 데이터에 적응하는 동안 기존에 학습한 정보나 지식을 잃어버리는 현상을 말합니다.
특히, 대형 언어 모델은 매우 복잡하고 다양한 정보를 담고 있기 때문에 잘못된 방식으로 파인 튜닝할 경우 이런 문제가 발생할 가능성이 큽니다.
catastrophic forgetting 문제를 막기 위한 방법은 여러 가지가 있습니다.
-
- Regularization Techniques (정규화 기법):
- Elastic Weight Consolidation (EWC): 이 기법은 모델의 중요한 파라미터가 크게 변화하지 않도록 가중치에 제약을 가하는 방법입니다. 이를 통해 모델이 기존에 학습한 정보를 유지할 수 있게 합니다.
- L2 정규화: 가중치가 지나치게 커지는 것을 방지하여 모델이 과적응(overfitting)되는 것을 막고 기존 지식을 유지하도록 도와줍니다.
- Replay Methods (재학습 기법)
- Experience Replay: 이전에 학습한 데이터를 일부 저장해 두고 파인 튜닝 중에 주기적으로 재학습시킵니다. 이를 통해 모델이 기존 지식을 잊지 않도록 합니다.
- Generative Replay: 생성 모델을 사용하여 이전에 학습한 데이터를 생성하고 이를 파인 튜닝 과정에서 사용합니다.
Q) 잘 알려진 파인 튜닝은 크게 두 가지 방법이 있어? 하나는 Instruction Fine-tuning 이고, 다른 하나는 Parameter Efficient fine-tuning (PEFT)
맞습니다.
각 방법은 특정 목적과 상황에 맞게 모델을 최적화하는 데 사용됩니다.
Instruction Fine-tuning:
- Instruction Fine-tuning은 모델이 주어진 명령이나 지시에 따라 더 나은 성능을 발휘하도록 조정하는 방법입니다. 이 방법은 모델이 특정 작업이나 도메인에 더 적합하게 만들기 위해 사용됩니다
- 특징:
- 데이터 중심: 모델이 특정 태스크를 더 잘 수행하도록 대규모의 도메인 특화 데이터셋을 사용하여 학습합니다.
- 전이 학습: 모델이 이전에 학습한 일반적인 언어 지식을 유지하면서 특정 태스크에 대한 성능을 향상시킵니다.
- 적용 사례: 질의 응답 시스템, 텍스트 생성, 번역 등 특정 태스크에 특화된 모델을 만들 때 사용됩니다.
- 예시:
- GPT-3 Fine-tuning: OpenAI의 GPT-3 모델을 특정 도메인(예: 법률 문서, 의료 기록)이나 태스크(예: 고객 지원 챗봇)에 맞게 파인 튜닝하여 더 정확한 결과를 도출하게 합니다.
Parameter Efficient Fine-tuning (PEFT):
- PEFT는 모델 전체를 조정하지 않고 일부 파라미터만 조정하여 효율적으로 모델을 파인 튜닝하는 방법입니다. 이는 주로 대규모 모델에서 사용되며, 모델의 파라미터 수가 너무 많아서 전체를 학습시키는 데 비용이 많이 들 때 효과적입니다.
- 특징:
- 효율성: 전체 모델을 조정하지 않고 일부 중요한 파라미터만 조정하여 학습 비용을 절감합니다.
- 메모리 절약: 전체 모델을 학습시키지 않기 때문에 메모리 사용량을 줄일 수 있습니다.
- 신속한 학습: 파라미터의 일부만 학습시키므로 학습 시간이 단축됩니다.
- 기법:
- Adapter Layers: 모델의 특정 층에 어댑터 레이어를 추가하여 새로운 태스크를 학습할 때 이 층들만 조정합니다.
- LoRA (Low-Rank Adaptation): 저차원 근사법을 사용하여 모델의 일부 파라미터만 조정합니다.
- Prefix Tuning: 입력 토큰 시퀀스 앞에 프리픽스 벡터를 추가하여 모델의 출력 결과를 조정합니다.
- BERT Adapter: BERT 모델의 특정 층에 어댑터를 추가하여 특정 태스크(예: 감성 분석, 이름 인식)에 맞게 파인 튜닝합니다. 이를 통해 원래 모델의 성능을 크게 손상시키지 않고도 새로운 태스크에 대해 높은 성능을 유지할 수 있습니다.
Q) Reinforcement Learning from Human Feedback 도 파인 튜닝 기법 아닌가?
맞습니다.
파인 튜닝 기법 중 하나로, 모델이 인간의 피드백을 통해 학습하도록 하는 방법입니다.
이 기법은 특히 모델의 출력을 인간의 기대에 더 잘 맞추기 위해 사용됩니다.
RLHF는 모델이 사람의 피드백을 기반으로 학습하는 강화 학습 기법입니다.
이는 일반적으로 언어 모델을 보다 안전하고 유용하게 만들기 위해 사용됩니다.
이 기법은 기본적으로 모델의 행동을 평가하고 보상하는 인간의 피드백을 이용해 모델을 향상시킵니다.
주요 요소:
- Human Feedback Collection:
- 설명: 모델이 생성한 출력에 대해 인간 평가자들이 피드백을 제공합니다. 이 피드백은 보상 신호로 사용되어 모델의 행동을 개선합니다.
- 방법: 인간 평가자들이 모델의 출력을 평가하여, 긍정적 또는 부정적인 피드백을 제공합니다.
- Reward Model:
- 설명: 인간의 피드백을 기반으로 보상 모델을 학습합니다. 보상 모델은 모델의 출력이 얼마나 좋은지를 예측하는 역할을 합니다.
- 방법: 인간의 피드백 데이터를 사용하여 보상 함수를 학습합니다.
- Reinforcement Learning:
- 설명: 보상 모델을 사용하여 언어 모델을 강화 학습합니다. 모델은 보상 신호를 최대화하기 위해 학습합니다.
- 방법: Proximal Policy Optimization (PPO) 등과 같은 강화 학습 알고리즘을 사용하여 모델을 최적화합니다.
- 예시
- ChatGPT: OpenAI의 ChatGPT는 RLHF를 사용하여 대화 모델을 학습합니다. 사용자의 피드백을 기반으로 모델의 응답 품질을 향상시키고, 부적절한 응답을 줄입니다.
Q) LoRA 도 파인 튜닝 기법 중 하나 아닌가?
맞습니다.
LoRA는 대규모 언어 모델을 효율적으로 파인 튜닝하기 위해 고안된 방법으로, 모델의 일부 파라미터만 조정하여 학습 비용을 절감하고 성능을 최적화합니다
그러니까 모델을 경량화 하면서도 특정 테스크에 강하게 만드는 방법임.
주요 개념
- 저차원 근사:
- 설명: 모델의 고차원 파라미터를 저차원 행렬로 근사하여 학습합니다. 이렇게 하면 학습해야 하는 파라미터 수가 크게 줄어듭니다.
- 방법: 모델의 고차원 파라미터 행렬을 두 개의 저차원 행렬의 곱으로 분해합니다. 이 저차원 행렬들만 학습하게 됩니다.
- 효율성:
- 장점: 전체 파라미터를 학습하지 않으므로 메모리 사용량과 계산 비용이 줄어듭니다.
- 적용: 대규모 모델을 특정 태스크에 맞게 효율적으로 조정할 때 유용합니다.
- 과정
- 모델 파라미터 분해:
- 모델의 고차원 파라미터 𝑊 를 두 개의 저차원 행렬 𝐴 와 𝐵 로 분해하여 𝑊 ≈ 𝐴 × 𝐵 형태로 표현합니다.
- 이 두 저차원 행렬 𝐴 와 𝐵 만 학습시키는 방식입니다.
- 학습 및 조정:
- 저차원 행렬 𝐴 와 𝐵 를 학습하면서 원래 모델의 성능을 유지하거나 개선합니다. 학습 후, 𝑊 ≈ 𝐴 × 𝐵 로 계산된 파라미터를 사용하여 모델의 출력을 생성합니다.
- 모델 파라미터 분해:
Instruction fine-tuning
LLM 을 파인튜닝 하는 기법 중 하나인 Instruction fine-tuning 에 대해 살펴보는 시간임.
기존에 우리는 Language Model 이 더 잘 작동하는 방법으로 zero-shot, few-shot 프롬포트에 대해 알아봤었음.
이런 방식의 문제점은 크게 두 가지가 있다:
- Incontext learning 은 항상 올바르게 작동하지 않는다. 이렇게 예시를 넣어주더라도 잘 작동하지 않을 수 있다는거임.
- 예시를 넣는다는 건 귀중한 Context Window 공간을 차지한다는 뜻이다. 여기에 더 좋은 정보들을 넣어줄 수 있는데도 불구하고.
이런 문제를 해결하기 위해서 우리는 fine-tuning 을 적용할 수 있음.
Fine-tuning 이란:
- Pre-training 과 마찬가지로 지도 학습 계열임.
- [Prompt, Completion] 을 쌍으로 많은 데이터를 넣어서 학습을 추가로 시켜서 새로운 종류의 작업을 더 잘하게 만드는 기법이다.
- 대부분의 파인 튜닝은 Instruction Fine-tuning 을 말한다고 알면됨. 이게 가장 잘 알려져있다.
Instruction Fine-tuning 예시:
- 다음 이미지 처럼 특정 명령과 대답을 쌍으로 줘서 학습시키는 걸 말함. 이 이미지에서는 감정 분석을 더 잘하도록 명령을 내리고 있음.
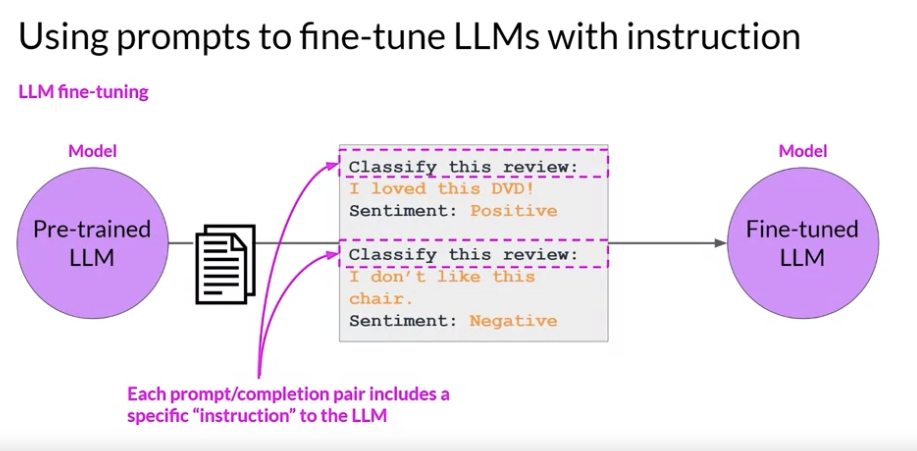
Instruction Fine-tuning:
- LLM 모델의 모든 가중치가 업데이트 되는 방식이다. 그래서 full fine-tuning 이라고도 불린다.
- 그래서 완전히 새로운 모델도 탈바뀜되어서 나오는 것이기 때문에 훨씬 학습에 비용이 많이 들어간다.
그래서 Instruction Fine-tuning 을 하기 위해선 어떻게 해야하는데?
-
- 먼저 훈련시키고 싶은 작업에 맞게 데이터를 준비해야한다. 대량의 데이터가 필요함:
- 다행이 Sample Prompt instruction template 을 가면 원하는 작업에 맞게 훈련시킬 수 있는 프롬포트 템플릿과 데이터들을 얻을 수 있다고함.
- 다음 이미지가 그 예시 중 하나.

-
- 모은 테스트 데이터를 분할한다. 훈련용, 검증용, 테스트용 이렇게.
- 해당 데이터를 가지고 학습시킨다. LLM 이 만든 Completion 과 Label 을 비교하고, 손실 함수의 손실을 최소하할 수 있곘끔 Backpropagation 과정을 통해 모델의 파라미터를 업데이트 하는거임.
- 검증용 데이터를 바탕으로 모델이 잘 작동하는지 확인하고 마지막으로 학습이 끝나면 테스트용 데이터로 얼마나 잘 작동하는지 성능을 측정하면 됨.
Q) Instruction Fine-tuning 을 할 때 테스트 데이터로 성능은 어떻게 측정하는거지? 단순 텍스트 생성 Completion 작업이 아니라면 성능을 측정하기 어렵잖아. 이 평가 작업에서도 LLM 을 써서 하는건가? 제대로 답변했는지 검토하는 LLM 을 써서.
Task 에 따라서 성능 측정 방법은 많음.
성능 측정 방법:
- 정확성(Accuracy) 측정:
- 정답과 비교: 모델의 출력이 미리 정의된 정답(ground truth)과 얼마나 일치하는지 평가합니다.
- 적용 예: 텍스트 분류, 감정 분석, 질문 응답 등에서 정확성 척도를 사용하여 성능을 평가합니다.
- 정밀도(Precision), 재현율(Recall), F1 점수:
- 정밀도: 모델이 예측한 긍정 사례 중 실제로 긍정인 비율.
- 재현율: 실제 긍정 사례 중 모델이 올바르게 예측한 비율.
- F1 점수: 정밀도와 재현율의 조화 평균.
- 적용 예: 이진 분류 또는 다중 클래스 분류 문제에서 사용.
- BLEU, ROUGE 점수:
- BLEU: 기계 번역과 같은 텍스트 생성 작업에서 생성된 텍스트와 참조 텍스트 간의 일치 정도를 평가.
- ROUGE: 요약 작업에서 생성된 요약과 참조 요약 간의 일치 정도를 평가.
- 적용 예: 번역, 요약, 텍스트 생성 작업.
- Mean Squared Error (MSE), Mean Absolute Error (MAE):
- 설명: 수치 예측 작업에서 예측 값과 실제 값 간의 차이를 측정.
- 적용 예: 회귀 분석 작업.
- Human Evaluation:
- 설명: 인간 평가자가 모델의 출력을 직접 평가하여 품질을 측정.
- 적용 예: 텍스트 생성, 대화형 AI 응답 평가
- MMLU(Massive Multitask Language Understanding):
- 설명: 대규모 언어 모델의 성능을 평가하기 위한 방법 중 하나로, 다양한 도메인과 태스크에서 모델의 이해력과 처리 능력을 측정하는 데 사용됩니다. MMLU는 특히 모델의 범용성을 평가하는 데 유용합니다. MMLU는 여러 가지 다른 주제와 태스크에 걸쳐 모델의 성능을 평가하는 방법입니다. 이를 통해 모델이 단일 태스크가 아닌 여러 태스크에 대해 얼마나 잘 수행하는지 확인할 수 있습니다. 예로 MMLU는 과학, 역사, 수학, 언어, 기술 등 다양한 주제를 포함합니다.
Fine-tuning on a single task
Fine-tuning 은 500~1000개 정도의 데이터로만 해도 놀랄 정도의 성능 향상을 이뤄냄.
그러나 주의해야할 건 Catastrophic forgetting 문제임.
이 문제는 Instruction fine-tuning 에서만 발생하는 문제로 원하는 작업은 더 잘하게 되지만 다른 작업에는 취약해지는 문제가 발생한다는거임.
Catastrophic forgetting 문제는 대부분의 경우에 신경쓰지 않아도 될거임. 기본적으로 우리는 하나의 작업만 더 잘하면 되니까. 다른 작업은 좀 못해도 괜찮은거지.
그치만 여러 작업에 LLM 이 능통해야한다면 mutliple task 로 파인 튜닝을 해야함. 여러 테스크와 관련된 예제를 학습시키는거지.
이에 필요한 데이터는 50~100,000 데이터 셋 정도 있어야 한다고 함.
아니면 PEFT (Parameter Efficient Fine-tuning) 을 하는 방법도 있음. 이건 기존 오리지널 LLM 의 파라미터를 건드리지 않고 추가적인 레이어를 둬서 구체적인 작업에 더 강하게 만드는 방법임.
Multi-task instruction fine-tuning
Multi-task Instruction fine-tuning 을 통해서 모델은 한 가지 일만 잘하는게 아니라 여러가지 일을 잘하게 만들 수 있음.
- 그러나 이 방식으로 추가 학습을 시키려면 데이터가 많이 들어간다. 50~100,000 데이터 셋 정도가 필요함.
대표적으로 이 파인튜닝을 하는 방법으로 FLAN (Fine-tuned LAnguage Net) 이 있음:
fine-tuning 을 더 잘하게 만드는 요소로는 프롬포트 템플릿이 있음:
- 아래 이밈지와 같이 작업에 따른 여러 개의 질문 요소가 많을수록 더 잘 일반화를 잘한다고함.
- FLAN-T5 는 Multi-task Instruction Fine-tuning 을 T5 모델에 적용했을 때 불리는 이름임.

Modal evaluation
LLM 을 평가하는 지표들:
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- BLEU (Bilingual Evaluation Understudy)
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
- 주로 텍스트 요약 작업의 성능을 평가하기 위해 개발된 메트릭입니다
- 다양한 변형이 있으며, 요약된 텍스트가 원본 텍스트와 얼마나 일치하는지를 측정합니다. ROUGE의 여러 변형 중 대표적인 것은 다음과 같습니다:
- ROUGE-N:
- 설명: 생성된 텍스트와 참조 텍스트 간의 N-그램 일치도를 기반으로 평가합니다.
- 예시: ROUGE-1은 단어 단위, ROUGE-2는 2-그램 단위 일치도를 측정합니다.
- ROUGE-L:
- 설명: 생성된 텍스트와 참조 텍스트 간의 최장 공통 부분열(Longest Common Subsequence, LCS)의 길이를 기반으로 평가합니다.
- 장점: 단어 순서도 고려하여 평가할 수 있습니다.
- ROUGE-W:
- 설명: LCS 기반 평가에서 가중치를 부여하여 중요한 단어의 일치를 강조합니다.
- ROUGE-N:

ROUGE Clipping:
- ROUGE 메트릭을 계산할 때 사용할 수 있는 기법 중 하나로, 반복된 N-그램의 영향을 제한하여 평가의 공정성을 높이는 방법입니다. 이는 특히 ROUGE-N (N-그램 기반) 변형에서 자주 사용됩니다.
- 기본 ROUGE-N:
- ROUGE-N은 생성된 텍스트와 참조 텍스트 간의 N-그램 일치도를 측정하는 메트릭입니다.
- N-그램이 생성된 텍스트와 참조 텍스트에서 각각 얼마나 자주 나타나는지를 비교합니다.
- Clipping:
- Clipping은 참조 텍스트에서 N-그램이 나타나는 최대 빈도 이상으로 생성된 텍스트에서 그 N-그램을 과대 평가하지 않도록 제한하는 방법입니다.
- 이를 통해 생성된 텍스트에서 동일한 N-그램이 과도하게 반복되어 점수를 부풀리는 현상을 방지합니다.
- 왜 ROUGE Clipping이 필요한가?
- 공정성 향상: 동일한 N-그램이 반복되는 경우, 단순히 반복된 N-그램을 많이 포함하는 생성 텍스트가 과도하게 높은 점수를 받지 않도록 합니다.
- 평가의 신뢰성 증가: Clipping을 통해 다양한 표현을 사용하고 참조 텍스트와의 실제 유사성을 더 정확하게 반영할 수 있습니다.
BLEU (Bilingual Evaluation Understudy):
- 주로 기계 번역의 성능을 평가하기 위해 개발된 메트릭입니다. 번역된 텍스트가 참조 번역 텍스트와 얼마나 일치하는지를 측정합니다. BLEU의 주요 특징은 다음과 같습니다:
- N-그램 Precision:
- 설명: 생성된 텍스트와 참조 텍스트 간의 N-그램 일치도를 측정합니다.
- 예시: BLEU-1은 단어 단위, BLEU-2는 2-그램 단위, BLEU-4는 4-그램 단위 일치도를 측정합니다.
- Brevity Penalty:
- 설명: 생성된 텍스트가 지나치게 짧은 경우 점수를 낮추기 위해 도입된 페널티입니다.
- 장점: 텍스트 길이를 적절히 유지하도록 유도합니다.
ROUGE 와 BLEU 의 한계:
- 문장 순서 무시: ROUGE는 주로 N-그램 기반이기 때문에, 단어의 순서가 조금만 달라져도 점수가 낮게 나올 수 있습니다.
- 의미 이해 부족: 단순한 단어 일치를 기반으로 하기 때문에, 의미가 비슷한 다른 표현에 대해 낮은 점수를 줄 수 있습니다.
- 부정어 처리 문제: 문장 내에 부정어(not) 등이 포함되어 의미가 완전히 달라지는 경우에도 높은 점수를 받을 수 있습니다.
그래서 대안 메트릭으로 METEOR (Metric for Evaluation of Translation with Explicit ORdering) 와 BERTScore 그리고 BLEURT 등이 있음.
METEOR (Metric for Evaluation of Translation with Explicit ORdering):
- BLEU의 한계를 보완하기 위해 개발된 번역 평가 메트릭입니다
- BLEU가 단순한 단어 일치를 기반으로 평가하는 데 비해, METEOR는 여러 가지 추가적인 요소를 고려하여 평가합니다.
- Synonymy: 동의어를 인식하고 평가에 반영합니다.
- Stemming: 단어의 어근을 비교하여 평가합니다.
- Paraphrase Matching: 다른 형태의 표현도 동일한 의미로 간주합니다.
- Word Order: 단어의 순서를 고려하여 평가합니다.
- 장점:
- 의미적 유사성을 더 잘 반영하여 평가할 수 있습니다.
- 다양한 형태의 표현을 인식하여 평가의 정확성을 높입니다.
- 단점:
- 계산 비용이 높을 수 있습니다.
- 너무 많은 요소를 고려하여 복잡도가 증가할 수 있습니다.
BERTScore
- 사전 학습된 BERT 모델을 사용하여 생성된 텍스트와 참조 텍스트 간의 의미적 유사성을 평가하는 메트릭입니다.
- 기능:
- Contextual Embeddings: BERT 모델을 사용하여 문맥적 임베딩을 생성하고 비교합니다.
- Precision, Recall, F1 Score: 생성된 텍스트와 참조 텍스트의 임베딩 벡터 간의 유사도를 기반으로 Precision, Recall, F1 Score를 계산합니다.
- 장점:
- 단어의 의미와 문맥을 더 잘 반영하여 평가합니다.
- 기존의 N-그램 기반 메트릭보다 의미적 유사성을 더 정확하게 측정할 수 있습니다.
- 단점:
- BERT 모델을 사용하는 데 따른 계산 비용이 높습니다.
- BERT 모델의 성능에 따라 평가 결과가 좌우될 수 있습니다.
BLEURT (Bilingual Evaluation Understudy with Representations from Transformers):
- BLEURT는 사전 학습된 Transformer 모델을 사용하여 생성된 텍스트와 참조 텍스트 간의 의미적 유사성을 평가하는 메트릭입니다
- BLEURT는 BERTScore와 유사하지만, 더 많은 사전 학습과 미세 조정을 거쳐 평가 성능을 향상시킵니다.
- 기능:
- Pre-trained Model: 대규모 코퍼스로 사전 학습된 모델을 사용하여 평가합니다.
- Fine-tuning: 추가적인 데이터로 미세 조정하여 특정 태스크에 맞게 최적화합니다.
- Semantic Similarity: 문맥적 의미와 유사성을 기반으로 평가합니다.
- 장점:
- 의미와 문맥을 더 잘 반영하여 평가합니다.
- 다양한 태스크에 대해 높은 평가 성능을 보입니다.
- 단점:
- 사전 학습 및 미세 조정에 따른 높은 계산 비용이 발생할 수 있습니다.
- BERTScore와 마찬가지로, 모델의 성능에 따라 평가 결과가 좌우될 수 있습니다.
Bentchmarks
Huggingface 의 LLaMa3 로 보는 벤치마킹 자료: Base Pretrained Models vs Instruction Tuned Models
Base pretrained models:
- 모델이 기본적으로 사전 학습(pretraining)만 수행된 상태에서의 성능을 나타냅니다. 이 단계에서는 모델이 일반적인 언어 이해 능력을 갖추고 있지만, 특정 태스크에 최적화되지 않았습니다.
Instruction tuned models:
- 모델이 특정 태스크에 맞게 파인 튜닝된 후의 성능을 나타냅니다. 이 단계에서는 모델이 특정 작업에 대한 성능을 향상시키기 위해 추가 학습(instruction tuning)을 받았습니다.
Base pretrained models:
- MMLU (5-shot): 다양한 주제에 대한 모델의 전반적인 이해력 평가.
- AGIEval English (3-5 shot): 일반 인공지능의 영어 이해 능력 평가.
- CommonSenseQA (7-shot): 일반 상식 기반 질문에 대한 모델의 응답 능력 평가.
- Winogrande (5-shot): 단어의 의미와 문맥 기반 텍스트 이해 능력 평가.
- BIG-Bench Hard (3-shot, CoT): 어려운 문제 해결 능력 평가.
- ARC-Challenge (25-shot): 과학 질문에 대한 기계 독해 능력 평가.
- TriviaQA-Wiki (5-shot): 위키백과 기반 퀴즈 질문 응답 능력 평가.
- SQuAD (1-shot): 독해 능력 평가.
- QuAC (1-shot, F1): 대화형 독해 능력 평가.
- BoolQ (0-shot): 단답형 질문 응답 능력 평가.
- DROP (3-shot, F1): 수치적 추론과 정보 추출 능력 평가.
Instruction tuned models:
- MMLU (5-shot): 다양한 주제에 대한 모델의 전반적인 이해력 평가.
- GPoA (0-shot): 특정 태스크에서의 일반적인 성능 평가.
- HumanEval (0-shot): 프로그래밍 문제 해결 능력 평가.
- GSM-8K (8-shot, CoT): 수학 문제 해결 능력 평가.
- MATH (4-shot, CoT): 수학 문제 해결 능력 평가.


Q) 벤치마크 지표에 있는 5-shot, 7-shot 이런 건 뭐야?
모델이 주어진 태스크를 수행할 때 참조할 수 있는 예제의 수를 의미합니다. 이 용어들은 주로 Few-shot 학습과 관련이 있습니다.
Q) 만약 상담용 봇을 만든다고 한다면 어떤 평가 지표들을 보면 될까?
대화 품질 평가 (Conversation Quality Evaluation)
- BLEU, ROUGE 같은 지표는 정답과 얼마나 유사하게 답변을 작성하느냐인가임.
- BLEU (Bilingual Evaluation Understudy): 생성된 응답이 참조 응답과 얼마나 유사한지 평가. 주로 번역에서 사용되지만, 대화 응답의 유사성을 평가하는 데도 사용될 수 있습니다.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): 생성된 응답이 참조 응답과 N-그램 일치 정도를 기반으로 평가. 요약 및 대화 응답 품질 평가에 사용.
- METEOR (Metric for Evaluation of Translation with Explicit ORdering): 동의어와 어근 분석을 포함한 N-그램 일치 정도로 평가. 번역 및 대화 응답 평가에 유용.
- BERTScore: 생성된 응답과 참조 응답의 임베딩 벡터 간 유사성을 평가. 의미적 유사성을 잘 반영.
- Perplexity: 모델의 예측 확률의 불확실성을 측정. 낮을수록 모델이 더 유창하게 텍스트를 생성함.
대화 이해 및 추론 능력 (Conversation Understanding and Reasoning)
- MMLU (Massive Multitask Language Understanding): 다양한 주제와 태스크에 대한 모델의 전반적인 이해력을 평가. 상담 봇의 전반적인 이해력 평가에 유용.
- CommonSenseQA: 상식 기반 질문에 대한 응답 능력을 평가. 상담 봇이 상식적인 응답을 제공하는 능력을 평가.
- Winogrande: 문맥 기반 추론 능력을 평가. 상담 봇이 문맥을 이해하고 적절한 응답을 제공하는 능력을 평가.
- ARC-Challenge: 과학 질문에 대한 기계 독해 능력을 평가. 논리적 추론이 필요한 질문 응답 능력을 평가.
- TriviaQA-Wiki: 위키백과 기반 퀴즈 질문 응답 능력을 평가. 지식 기반 응답의 정확성을 평가.
대화의 자연스러움 및 상호작용 품질 (Naturalness and Interaction Quality)
- Human Evaluation: 인간 평가자가 모델의 응답을 직접 평가하여 품질, 관련성, 자연스러움을 평가. 주관적 평가지만 중요한 지표.
- Coherence: 대화의 일관성을 평가. 응답이 이전 문맥과 잘 맞는지 평가.
- Engagement: 사용자가 대화에 얼마나 몰입하는지 평가. 대화의 흥미로움과 유용성을 평가.
- Satisfaction: 사용자가 대화 후 얼마나 만족하는지 평가. 사용자 설문조사를 통해 측정.
기능적 평가 (Functional Evaluation)
- Response Time: 모델이 응답을 생성하는 데 걸리는 시간. 실시간 응답의 효율성 평가.
- Handling of Edge Cases: 특이한 상황이나 예외적인 경우를 얼마나 잘 처리하는지 평가. 에러 응답 비율 측정.
- Consistency: 동일한 질문에 대해 일관된 응답을 제공하는지 평가.
Q) GLUE, SuperGlue, HELM, MMLU, BIG-bench 같은 것들은 모델의 능력을 평가할 수 있는 데이터셋 같은 것들을 제공해줘?
GLUE, SuperGLUE, HELM, MMLU, BIG-bench와 같은 데이터셋들은 자연어 처리(NLP) 모델의 성능을 평가하는 데 사용되는 데이터셋과 벤치마크를 제공해줍니다.
각 데이터셋 및 벤치마크는 다양한 측면에서 모델의 능력을 평가할 수 있도록 설계되었습니다.
GLUE (General Language Understanding Evaluation):
- 다양한 자연어 이해 과제를 포함한 벤치마크입니다.
- 문장 수집 (Sentence Coherence): Sentences Involving Compositional Knowledge (SICK) 코퍼스를 사용하여 문장의 일관성을 평가합니다.
- 문장 추론 (Sentence Inference): Recognizing Textual Entailment (RTE) 데이터셋을 사용하여 문장 간의 함의 관계를 평가합니다.
- 텍스트 유사도 (Textual Similarity): Semantic Textual Similarity (STS) 데이터셋을 사용하여 두 문장 간의 의미적 유사성을 평가합니다.
- 감정 분석 (Sentiment Analysis): Stanford Sentiment Treebank (SST-2) 데이터셋을 사용하여 문장의 감정 상태를 분류합니다.
- 문장 관련성 (Sentence Relationship): Microsoft Research Paraphrase Corpus (MRPC) 데이터셋을 사용하여 두 문장이 서로 연관되어 있는지를 평가합니다.
- 자연어 추론 (Natural Language Inference): Multi-Genre NLI (MNLI) 데이터셋을 사용하여 문장 쌍 간의 논리적 관계를 평가합니다.
- 텍스트 유사도, 텍스트 분류, 문장 관계 등을 평가합니다.
SuperGLUE:
- GLUE의 확장판으로, 보다 어려운 자연어 이해 과제를 포함합니다.
- 모델이 실제 언어 이해 능력을 갖추고 있는지를 평가하기 위한 고급 벤치마크입니다.
- WSC (Winograd Schema Challenge): 문맥상 중요한 정보를 바탕으로 대명사를 정확히 해석하는 능력을 평가합니다.
- ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset): 주어진 텍스트와 질문을 기반으로 상식적인 추론을 통해 답을 찾는 능력을 평가합니다.
- COPA (Choice of Plausible Alternatives): 주어진 상황에서 가장 그럴듯한 결과를 선택하는 능력을 평가합니다.
- MultiRC (Multi-Sentence Reading Comprehension): 여러 문장에 걸쳐 주어진 질문에 대한 답을 찾는 능력을 평가합니다.
- BoolQ (Boolean Questions): 텍스트를 읽고 질문에 대해 '예' 또는 '아니오'로 답하는 능력을 평가합니다.
HELM (Holistic Evaluation of Language Models):
- 언어 모델을 전체적으로 평가하는 벤치마크입니다.
- HELM은 단순한 정확도뿐만 아니라 공정성, 효율성, 견고성 등의 다양한 지표를 포함하여 모델의 성능을 평가합니다. 이를 통해 모델이 단순히 정답을 맞추는 능력 외에도 실제 사용 환경에서의 성능을 종합적으로 판단할 수 있습니다.
- 공정성 (Fairness):
- 모델이 특정 그룹에 대해 편향되지 않도록 공정성을 평가합니다. 이는 언어 모델이 다양한 사용자에게 공정하게 작동할 수 있는지를 확인하기 위한 중요한 지표입니다.
- Calibration (교정):
- Calibration은 모델의 예측 확률이 실제 정답과 얼마나 잘 일치하는지를 평가합니다. 모델이 자신의 예측에 대해 얼마나 확신하는지를 측정하는 것으로, 잘 교정된 모델은 높은 확신도를 가진 예측이 실제로도 높은 정확성을 가져야 합니다.
- Bias (편향)
- Bias는 모델이 특정 그룹에 대해 편향된 결과를 내는지 평가합니다. 공정성을 보장하기 위해 중요한 메트릭이며, 모델이 모든 사용자에게 공정하게 작동하는지를 확인하는 데 사용됩니다.
- Toxicity (유해성)
- Toxicity는 모델이 생성하는 텍스트가 유해하거나 공격적인 내용을 포함하는지를 평가합니다. 이는 모델이 사회적으로 수용 가능한 언어를 사용하는지를 확인하는 데 중요합니다.
- 효율성 (Efficiency):
- 모델의 자원 사용 효율성을 평가합니다. 이는 모델이 주어진 자원 내에서 얼마나 효율적으로 작동하는지를 측정하여, 실제 애플리케이션에서의 사용 가능성을 판단합니다.
- 견고성 (Robustness):
- 모델이 다양한 입력 데이터에 대해 얼마나 견고하게 작동하는지를 평가합니다. 이는 모델이 노이즈가 있는 데이터나 예상치 못한 입력에 대해 얼마나 잘 대응할 수 있는지를 측정합니다.
- 확장성 (Scalability):
- 모델이 더 큰 데이터나 더 복잡한 작업에 대해 어떻게 성능을 발휘하는지를 평가합니다. 이는 모델의 확장 가능성을 확인하는 데 중요한 지표입니다.
- 공정성 (Fairness):
- 다양한 평가 지표를 사용하여 모델의 종합적인 성능을 평가합니다.
MMLU (Massive Multitask Language Understanding):
- 다중 작업 언어 이해 평가를 위한 벤치마크입니다. 다양한 주제와 영역에서 모델의 성능을 평가합니다.
- MMLU는 57개 주제에 걸쳐 있는 질문으로 구성되어 있습니다. 이 주제들은 과학, 역사, 예술, 기술, 인문학, 의학 등 매우 광범위합니다. 각 주제는 모델이 특정 도메인 지식을 얼마나 잘 이해하고 있는지를 평가하는 데 도움이 됩니다.
- 질문들은 초등학교 수준부터 대학원 수준까지 다양한 난이도로 구성되어 있습니다. 이를 통해 모델의 기초 지식부터 고급 이해까지 종합적인 성능을 평가할 수 있습니다.
BIG-bench (Beyond the Imitation Game Benchmark):
- 언어 모델의 능력을 다양한 작업에서 평가하는 대규모 벤치마크입니다.
- BIG-bench는 204개 이상의 작업을 포함하고 있습니다. 이 작업들은 언어 모델의 다양한 능력을 평가하기 위해 고안되었으며, 크게 4가지 범주로 나눌 수 있습니다:
- 텍스트 생성 (Text Generation): 문서 생성, 대화 생성 등 언어 생성 능력을 평가합니다.
- 텍스트 이해 (Text Understanding): 독해, 텍스트 분류 등 텍스트 이해 능력을 평가합니다.
- 추론 (Reasoning): 논리적 추론, 수학적 추론 등 복잡한 추론 능력을 평가합니다.
- 지식 (Knowledge): 일반 상식, 전문 지식 등 모델이 보유한 지식을 평가합니다.
- BIG-bench는 다양한 평가 지표를 사용하여 모델의 성능을 평가합니다. 여기에는 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 스코어 등이 포함됩니다. 각 작업에 적합한 지표를 사용하여 모델의 성능을 다각도로 평가합니다.
Parameter efficient fine-tuning (PEFT)
기존 LLM 의 파라미터를 건드리지 않고, 새로운 어댑터 레이어를 추가하는 식으로 튜닝을 하는 기법임.
- 그래서 일부 파라미터만 조절됨. 전체 파라미터의 약 15~20% 만 조절된다고 함.
대표적인 PEFT 방식으로 Adapter 가 있음:
- Adapters: 모델의 특정 레이어에 작은 추가 모듈(어댑터)를 삽입하여 조정하는 방식입니다. 어댑터는 일반적으로 작은 신경망으로 구성되어 있으며, 원래 모델의 파라미터는 동결(freeze)된 상태로 두고, 어댑터의 파라미터만 학습합니다.
- 그래서 특화 작업마다 PEFT 방식으로 레이어를 만들어 두면 LLM에서 유연하게 해당 레이어를 갈아 끼울 수 있음.
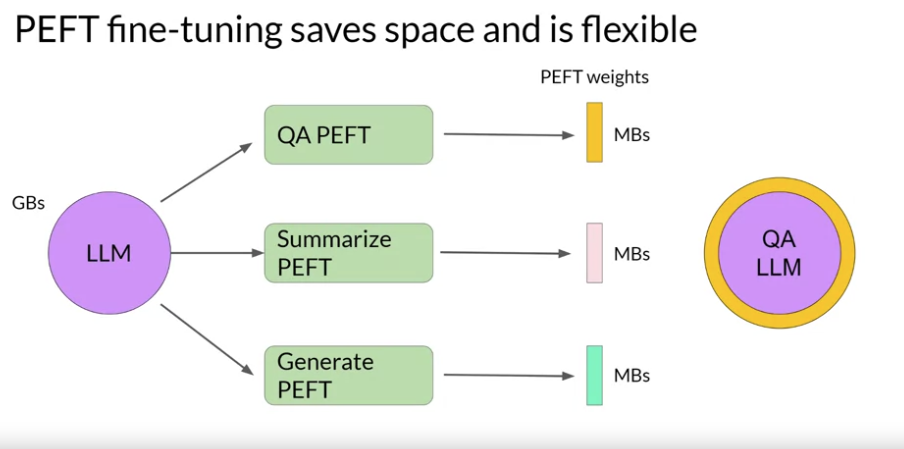
PEFT 튜닝에서는 다음과 같은 Trade-offs 를 고려해야함:
- Memory Efficiency:
- 메모리 사용량을 줄이기 위해 파라미터의 수를 줄이면, 모델의 성능이 저하될 수 있습니다
- PEFT 기법은 전체 모델 파라미터를 조정하는 대신 일부 파라미터만 학습하여 메모리 사용량을 줄입니다. 하지만 이는 파라미터 수가 적어지는 만큼 모델의 학습 능력이 제한될 수 있습니다.
- Parameter Efficiency:
- 파라미터를 효율적으로 사용하기 위해 특정 모듈(예: 어댑터)을 도입하면, 전체 모델 구조가 복잡해질 수 있습니다.
- PEFT는 파라미터의 일부만 학습하기 때문에, 동일한 성능을 내기 위해서는 보다 정교한 파라미터 조정 기법이 필요합니다. 이는 모델 구조를 복잡하게 만들 수 있습니다.
- Training Speed:
- 학습 속도를 높이기 위해 일부 파라미터만 학습하면, 전체 모델의 성능이 저하될 수 있습니다
- PEFT 기법은 적은 파라미터를 학습하기 때문에 학습 속도가 빠르지만, 모든 파라미터를 학습하는 경우보다 성능이 낮을 수 있습니다.
- Model Performance
- PEFT를 사용하여 메모리와 계산 자원을 절약하면, 최종 모델 성능이 떨어질 수 있습니다
- PEFT 기법은 파라미터 효율성과 메모리 효율성을 높이지만, 전체 파라미터를 조정하는 방법에 비해 성능이 낮을 수 있습니다. 이는 특히 복잡한 작업에서 두드러질 수 있습니다
- Inference Costs:
- 추론 비용을 줄이기 위해 일부 파라미터만 사용하면, 실시간 응답 속도나 성능이 저하될 수 있습니다.
- PEFT 기법은 모델의 파라미터 일부만 사용하기 때문에 추론 시 비용이 절감될 수 있지만, 이는 성능 저하로 이어질 수 있습니다.
PEFT 방법으로는 다음과 같다:
- Selective:
- Explanation: 전체 모델 파라미터 중에서 특정 부분만 선택적으로 튜닝하는 방법입니다. 예를 들어, 특정 레이어나 모듈만 미세 조정하고 나머지는 고정(freeze) 상태로 둡니다. 이렇게 하면 메모리와 계산 비용을 절약할 수 있습니다.
- 메모리 효율성과 학습 속도 측면에서 유리하지만, 성능 향상이 제한적일 수 있습니다.
- Reparameterization:
- Explanation: 기존 모델 파라미터를 재구성하여 더 효율적으로 학습하는 방법입니다. 일반적으로 파라미터를 저랭크 행렬로 분해하거나, 새로운 파라미터 형태로 변환하여 학습합니다.
- 파라미터 효율성을 극대화할 수 있지만, 모델 복잡도가 증가할 수 있습니다.
- Additive:
- Explanation: 모델에 새로운 모듈이나 레이어를 추가하여 특정 작업에 맞게 학습하는 방법입니다. 이는 기존 모델 파라미터는 고정하고, 추가된 모듈만 학습합니다.
- 모델 성능 향상에 효과적이지만, 추가 모듈이 들어감에 따라 추론 시 메모리 사용량이 늘어날 수 있습니다.
- 크게 Adapters 방법과 Soft Prompt 방법으로 나뉜다:
- Adapters:
- Adapter Methods는 기존 모델의 레이어 사이에 작은 모듈을 추가하여 모델을 미세 조정하는 방법입니다. 이 추가 모듈들은 원래 모델 파라미터는 그대로 두고, 추가된 모듈의 파라미터만 학습합니다.
- 장점:
- 기존 모델의 구조를 크게 변경하지 않고도 특정 작업에 맞게 모델을 조정할 수 있습니다.
- 학습할 파라미터 수가 적기 때문에 메모리 효율적이고 학습 속도가 빠릅니다.
- 다중 작업에 대해 각 작업에 맞춘 어댑터를 사용하여 쉽게 전환할 수 있습니다.
- Soft Prompt:
- 모델의 입력 프롬프트를 조정하여 모델을 미세 조정하는 방법입니다. 이 방법은 원래 모델 파라미터는 고정한 상태로, 입력 프롬프트의 일부를 학습합니다.
- 장점:
- 매우 적은 수의 파라미터만 학습하기 때문에 메모리와 계산 자원이 매우 절약됩니다.
- 학습 속도가 매우 빠르며, 다양한 작업에 대해 효율적으로 적용할 수 있습니다.
- 원래 모델의 구조를 전혀 변경하지 않으므로 매우 간단하게 적용할 수 있습니다.
- Adapter Methods는 모델 성능 향상에 매우 효과적이지만, 추가 모듈이 들어감에 따라 추론 시 메모리 사용량이 약간 늘어날 수 있습니다.
- Soft Prompt Methods는 학습 속도가 빠르고 메모리 사용량이 매우 적지만, 모델 성능 향상 효과가 제한적일 수 있습니다.
- Adapters:
PEFT techniques 1: LoRA
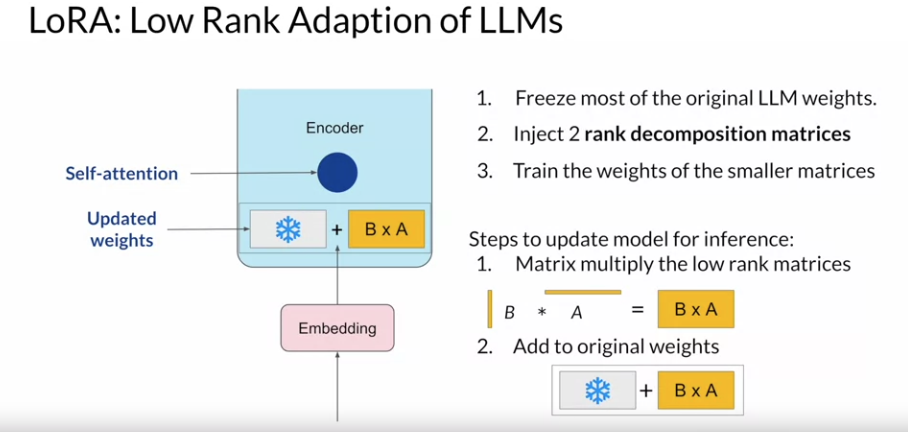
핵심 아이디어는 원래 대규모 언어 모델의 일부 가중치를 두 개의 저차원 행렬로 분해하고, 이들의 곱으로 대체하여 추론하는 것입니다.
LoRA의 작동 방식
-
- 원래 매트릭스를 저차원 행렬로 분해:
- 원래 모델의 가중치 행렬 𝑊 를 직접 학습하는 대신, 𝑊를 두 개의 저차원 행렬 𝐵 와 𝐴 로 분해합니다. 𝑊 ≈ 𝐵 × 𝐴 로 근사합니다. 여기서 𝐵 와 𝐴 는 각각 저차원 행렬로, 원래 가중치 행렬 𝑊 보다 훨씬 적은 파라미터를 가집니다.
- 학습 과정:
- 학습 과정에서는 원래 가중치 𝑊 는 동결(freeze)되고, 저차원 행렬 𝐵 와 𝐴 만 학습됩니다. 이렇게 하면 전체 모델의 파라미터 수가 크게 줄어들어, 메모리 사용량과 계산 비용이 절감됩니다.
- 추론 과정:
- 추론 시에는 저차원 행렬 𝐵 와 𝐴 의 곱 𝐵 × 𝐴 를 계산하여, 이 결과를 사용해 모델의 가중치를 업데이트합니다.
- 원래 가중치 𝑊 에 저차원 행렬의 곱 𝐵 × 𝐴 를 더하여 최종 가중치를 얻습니다. 이는 𝑊(updated) = 𝑊 + 𝐵 × 𝐴 로 표현될 수 있습니다.
- 예시를 통해 설명:
- 원래 가중치 행렬 𝑊 만약 𝑊 가 1000 × 1000 크기의 행렬이라면, 이 행렬을 직접 학습하는 것은 많은 계산 자원과 메모리를 필요로 합니다.
- 저차원 행렬 𝐵 와 𝐴 의 LoRA 기법에서는 𝑊 를 두 개의 작은 행렬 𝐵 와 𝐴 로 분해합니다. 예를 들어, 𝐵 가 1000 × 10, 1000×10 크기이고, 𝐴가 10 × 1000 크기일 수 있습니다.
- 학습: 학습 중에는 𝐵 와 𝐴 만 학습합니다. 이 작은 행렬들은 전체 모델의 파라미터 수를 크게 줄입니다.
- 추론: 추론 시에는 𝐵 × 𝐴 를 계산하여, 이 결과를 원래 가중치 𝑊 에 더합니다. 이렇게 하면 원래 모델의 성능을 유지하면서도 파라미터 효율성을 극대화할 수 있습니다.
LoRA 예시:

LoRA vs Full Fine tuning 성능 비교 (트레이드 오프를 고려헀을 때 LoRA 도 충분히 매력적이다):

LoRA 는 그리고 경량화 기법인 Quantization 과 같이 쓰기도 한다. 이걸 QLoRA 라고도 함.
Q) LoRA 기법은 Encoder 뿐 아니라 Feed forward layer 에 적용하는 방식으로도 가능해?
맞습니다.
LoRA(Low-Rank Adaptation)는 Encoder뿐만 아니라 Feed Forward Layer에도 적용할 수 있습니다. LoRA는 대규모 언어 모델의 다양한 부분에 적용할 수 있는 유연한 기법입니다.
Q) LoRA 에서 랭크 값을 정하는 방법은?
랭크는 저차원 행렬의 차원 수를 의미합니다
구체적으로, LoRA 기법에서 원래 모델의 가중치 행렬을 두 개의 저차원 행렬로 분해할 때, 이 저차원 행렬들의 차원을 "랭크(rank)"라고 합니다.
랭크는 저차원 행렬의 차원을 결정하는 중요한 하이퍼파라미터로 모델의 최종 성능에 큰 영향을 미칩니다. 랭크를 정하는 몇 가지 방법을 아래에 설명합니다
- 기본 값으로 시작: 특정 작업이나 데이터셋에 대해 기존 연구나 문헌에서 제안된 랭크 값을 기본으로 시작할 수 있습니다. 예를 들어, NLP 작업에서는 랭크 값으로 4, 8, 16 등의 작은 값을 사용할 수 있습니다.
- 점진적 증가: 기본 값에서 시작하여 점진적으로 랭크를 증가시키면서 성능을 평가합니다. 작은 값에서 시작하여 성능이 개선되는 지점을 찾습니다.
- 값을 무작정 늘린다고 성능이 더 좋아지는 건 아니라고 함. 일정한 값 이상인 경우에는 그때부터는 똑같다고도 한다.
- 일반적으로 4-32 사이가 적절하다고 함.
PEFT techniques 2: Soft prompts
Soft Prompt 방법의 개념:
- 기존의 Prompting:
- 전통적인 프롬프트 방식에서는, 모델의 입력 앞이나 뒤에 고정된 텍스트 프롬프트를 추가하여 모델이 특정 작업을 수행하도록 유도합니다.
- 예를 들어, 텍스트 생성 작업에서 "Translate the following English text to French:"와 같은 프롬프트를 추가할 수 있습니다.
- Soft Prompting:
- Soft Prompting에서는 텍스트 대신 학습 가능한 벡터(continuous embeddings)를 프롬프트로 사용합니다.
- 이 벡터는 모델 입력의 일부로 추가되며, 학습 과정에서 조정됩니다.
Soft Prompting의 작동 방식
- Embedding 추가:
- 입력 시퀀스 앞이나 중간에 학습 가능한 벡터(Soft Prompt)를 추가합니다.
- 예를 들어, 원래 입력이 𝑥 라면, Soft Prompt 𝑝 를 추가하여 [𝑝, 𝑥] 와 같은 형태로 입력을 구성합니다.
- 학습 과정:
- 모델의 원래 파라미터는 동결(freeze)된 상태로 유지하고, 추가된 Soft Prompt 벡터만 학습합니다.
- 이 벡터는 특정 작업에 맞게 학습되며, 모델이 더 나은 출력을 생성할 수 있도록 조정됩니다.
- 추론 과정:
- 학습된 Soft Prompt 벡터를 입력에 추가하여 모델에 넣습니다.
- 모델은 이 벡터와 함께 입력을 처리하여 최종 출력을 생성합니다.
Soft Prompting 예시:
- 문장 분류 작업:
- 원래 입력: "The movie was fantastic!"
- Soft Prompt: 𝑝 (학습 가능한 벡터)
- 최종 입력: [𝑝, "The movie was fantastic!"]
- 텍스트 생성 작업:
- 원래 입력: "Once upon a time,"
- Soft Prompt: 𝑝 (학습 가능한 벡터)
- 최종 입력: [𝑝, "Once upon a time,"]
장점과 단점:
- 장점:
- 효율성: 원래 모델의 파라미터를 동결하므로, 메모리 사용량과 계산 비용이 적습니다.
- 유연성: 다양한 작업에 대해 학습된 Soft Prompt를 쉽게 교체할 수 있습니다.
- 빠른 학습: 학습할 파라미터 수가 적어 학습 속도가 빠릅니다.
- 단점:
- 성능 제한: Soft Prompt 벡터의 크기와 학습 능력에 따라 모델 성능이 제한될 수 있습니다.
- 작업 특화: 각 작업에 대해 별도의 Soft Prompt를 학습해야 하므로, 일반화가 어려울 수 있습니다.
Soft Prompting 방법도 Task 별로 앞에 추가하는 토큰을 교체하는 방식으로 여러 테스크에 대응할 수 있다:

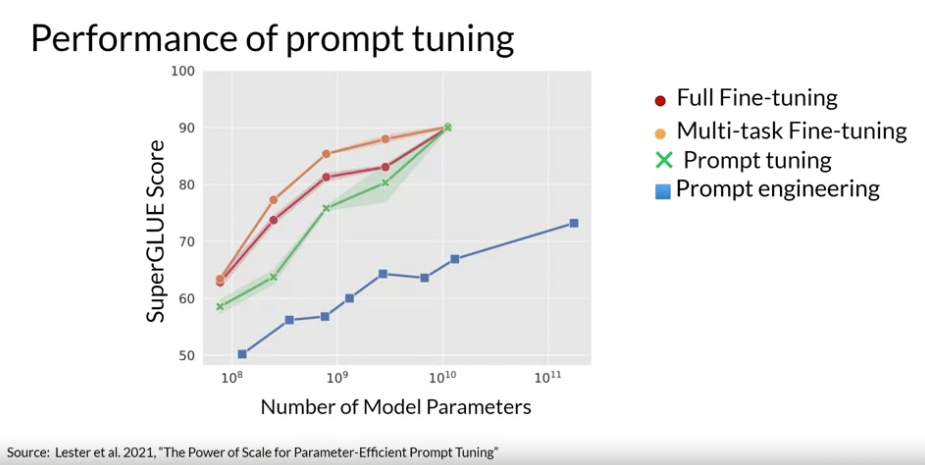
구글에서 발표한 모델 사이즈 별로 Fine-tuning 방법을 각각 적용했을 때의 성능 차이:
Q) Soft Prompting 방식의 기존 입력에 추가로 들어오는 벡터는 입력에 따라 달라지는거지?
동일한 작업이라는 학습한 벡터는 동일할 것이고, 작업이 달라진다면 다를 것이라고 한다.
즉, 특정 작업에 대해 학습된 Soft Prompt 벡터는 그 작업을 위한 고정된 임베딩(continuous embedding)으로 사용되지만, 작업이 다르면 다른 Soft Prompt 벡터를 사용할 수 있습니다.
'Generative AI' 카테고리의 다른 글
| Amazon Bedrock을 이용해 RAG, Fine tuning 없이 자동 고객 응대 서비스 구축하기 (0) | 2024.05.27 |
|---|---|
| LLM In Production (feat: Project Pluto) (0) | 2024.05.26 |
| Geneartive AI with LLMs: Week 1 (0) | 2024.05.17 |
| LLM 어플리케이션 아키텍처 (1/2) (0) | 2024.04.30 |
| LangChain Chat with Your Data (0) | 2024.04.25 |