Abstract:
- 이 글은 유추적 추론(Analogical Reasoning) 방법을 사용한 새로운 프롬프트 방식을 제안하는 논문임.
- CoT 를 사용할 떄 단계별 추론을 할 수 있도록 레이블이 붙은 예시를 제공해줘야함. 이를 준비하는 건 시간이 많이 걸리고 새로운 문제에 대한 적응력이 떨어질 수 있음.
- 유추적 프롬프트(Analogical Prompting) 는 이러한 문제를 해결하는 것으로 주어진 문제를 해결하기 전에 모델이 스스로 관련 예시나 지식을 생성하도록 유도하는 방법임.
- 모델이 각 문제에 맞게 생성한 예시나 지식을 맞춤형으로 제공하는 것. 아무래도 Few-shot CoT 방법이 성능이 잘 나오니까 이를 위한 방법이다.
- 이 방법은 Zero-shot CoT 방법과 수동으로 준비한 Few-shot CoT 방법보다 성능이 잘 나온다고 함.
Introduction:
- 관련 예시를 자동으로 생성하여 LLM의 추론 과정을 안내하는 방법임:
- 0-shot CoT는 간단하고 광범위하지만 원하는 성능을 기대해보기 어려울 수 있음.
- Few-shot CoT는 자세한 지침을 제공하지만, 각 작업마다 추론 과정이 레이블된 예시가 필요하여 비용이 많이듬.
- 이 프롬프트 기법은 유추적 추론(Analogical Reasoning)에서 영감을 받음:
- 인간은 새로운 문제를 해결할 때 과거의 관련 경험을 떠올려 해결한다. (Vosniadou & Ortony, 1989).
- 예를 들어, 새로운 수학 문제를 마주하면 "비슷한 문제를 알고 있나?" 를 생각하고, 이전에 해결한 방법을 떠올려 새로운 문제에 적용함. (Polya, 2004).
- 또한, 사각형의 넓이를 구하기 위해 변의 길이를 알아야 한다는 고수준의 지식도 활용한다. 이는 문제를 풀기 위해서 사전 지식을 이용하거나, 해당 문제와 관련된 기본적인 개념이나 공식을 떠올려서 이를 적용하는 것을 말함.
- 이 프롬프트의 방법론은 다음과 같다:
- 1) 주어진 문제에 대해, LLM이 스스로 관련된 예시와 솔루션을 생성하도록 프롬프트한다.
- 예시 지침: "# 관련된 문제와 해법을 회상하세요:..."
- 2) 그런 다음, 원래 문제를 해결한다.
- 동시에, 특정 예시를 보완하는 고수준의 지식을 생성하도록 유도할 수 있음. 이는 해당 문제를 해결하는 데 필요한 더 깊은 이론적 배경이나 원리까지 스스로 생성해내는 걸 말함.
- 이 모든 과정을 단일 프롬프트로 수행하여 지식, 예시, 문제 해결을 한 번에 진행할 수 있다고도 함. 이건 사용자는 모델에게 특정 문제에 대해 관련된 예시를 떠올리도록 지시하고, 필요한 고수준 지식을 생성한 뒤, 최종적으로 문제를 해결하도록 요청하는 프롬프트를 말함.
- 여러번의 멀티 턴을 통해서도 이 기법을 사용할 수 있을듯.
- 1) 주어진 문제에 대해, LLM이 스스로 관련된 예시와 솔루션을 생성하도록 프롬프트한다.
Analogical Prompting:

유추적 프롬프트(Analogical Prompting) 자세하게:
- 해결해야 할 대상 문제 x가 주어지면, 다음과 같은 지시문을 프롬프트에 추가함.
# 문제: [x]
# 관련된 문제들: 세 가지 관련 있고 서로 다른 문제를 회상하세요. 각 문제에 대해 설명하고 해결책을 제시하세요.
# 초기 문제 해결:- LLM 은 먼저, 질문-추론-답변 형태의 여러 개의 관련 예시(K개) 를 생성할 것. 그런 다음, 초기 문제를 해결한다. (프롬프트의 "# 초기 문제 해결:" 부분).
- 모든 지시문은 단일 프롬프트 내에 제공되며, 이를 통해 LLM은 연속적인 과정으로 예시 생성과 문제 해결을 수행한다.
- 프롬프트에서 '#' 기호를 사용하면 LLM이 응답을 더 구조적으로 구성하는 데 도움이 된다고 함.
- 기술적 고려사항:
- 관련 있고 다양한 예시 생성의 중요성:
- LLM이 동일한 문제를 반복 생성하는 경향이 있으므로, 프롬프트에 서로 다른 문제를 생성하세요 와 같은 지시문을 포함해야함.
- 단일 패스(single-pass) vs. 독립적인 예시 생성:
- 대안으로 예시를 별도로 생성하고 이를 다시 LLM에 입력할 수 있지만, 단일 프롬프트 방식이 성능 면에서 유사하고 구현이 더 간편하다고 함.
- (예시를 생성할 때 temperature 를 높게 주는 방법을 쓰면 되니까 멀티 턴이 좀 더 효과적이지 않을까 생각도 듬)
- 생성할 예시의 수(K):
- 실험을 통해 K=3~5개의 예시를 생성하는 것이 가장 효과적임을 발견하였다고 함(자세한 내용은 §6.5 참조).
- 관련 있고 다양한 예시 생성의 중요성:
- 예시 생성은 유용하지만, 코드 생성과 같은 복잡한 작업에서는 LLM이 저수준의 예시에 지나치게 의존해서 일반화에 실패할 수 있다고 함.
- 이러한 한계를 극복하기 위해, 예시를 보완하는 고수준의 통찰이나 지식("knowledge") 을 LLM이 스스로 생성하도록 유도하는 방법을 제안.
- 구체적으로 프롬프트에 추가 지시문을 포함하여 LLM이 문제의 핵심 개념을 파악하고 이를 설명하도록한다.
# 튜토리얼: 문제의 핵심 개념을 파악하고 튜토리얼을 제공하세요.- LLM 은 먼저 고수준의 지식을 생성하여 문제의 핵심 개념을 식별하고 이 지식을 바탕으로 관련된 예시를 생성하고, 최종적으로 초기 문제를 해결할 것.
- 주의: 지식을 예시보다 먼저 생성하는 것이 더 나은 결과를 보여줬다고 함.
- 이렇게하면 LLM이 더 깊은 이해를 바탕으로 문제를 해결하게 되어, 복잡한 작업에서도 일반화 능력이 향상된다고 함.
지식과 예시 생성:
- 지식과 예시를 함께 생성하는 것은 코드 생성과 같은 복잡한 작업에서 특히 유용하다고 함.
- 지식은 LLM이 특정 예시에 지나치게 의존하는 것을 방지하고, 새로운 문제에 대한 일반화 능력을 준다고 한다.
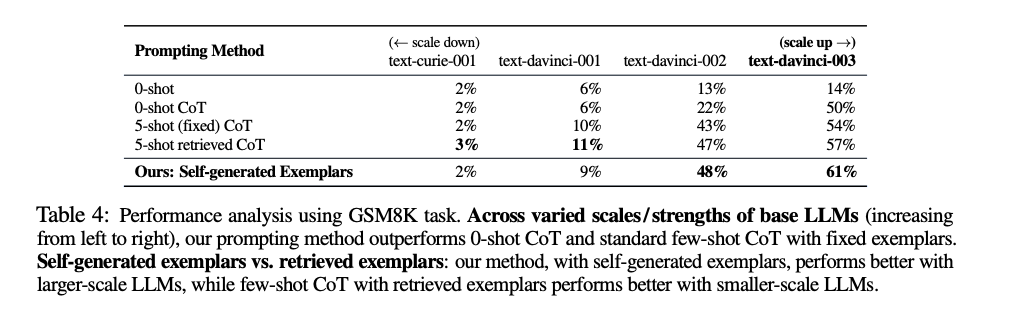
예시 생성 대 검색:
- 자체 예시 생성은 문제 해결에 관련성 높은 예시를 제공할 수 있다는 장점이 있음.
- 반면 대안으로, 외부 데이터에서 관련 예시를 검색하는 방법이 있다. 이 경우, 레이블된 예시 데이터셋이 필요하지만 레이블된 데이터셋에서 검색된 예시는 본질적으로 유효하고 정확하다는 장점이 있음.
- 충분히 비교해볼만한 방법이기도 하고, 더 나은 결과를 내기도 한다고 함.
- 대규모 LLM에서는 자체 예시 생성이 더 효과적일 수 있다고도 함.
- 반면 소규모 LLM에서는 검색 기반 접근법이 더 적합할 수 있다고도 한다. (모델의 능력이 제한적이므로)
생성할 예시의 수:
- 생성한 예시의 수인 K=1일 때, LLM의 성능이 저하되었다고 함.
- K≥3일 때, LLM은 일관된 성능을 보였으며, K=3 또는 5에서 가장 좋은 결과를 나타냈다고 한다.
정성적 분석:
- GSM8K와 MATH 데이터셋에서 정답을 맞춘 50개와 틀린 50개의 문제를 대상으로 분석:
- 정답을 맞춘 50개 문제:
- (6/50) 생성된 예시가 관련성이 없었습니다.
- (9/50) 생성된 예시가 관련성은 있지만 해결책이 잘못되었습니다.
- (35/50) 생성된 예시가 관련성이 있고 정확했습니다.
- 틀린 50개 문제:
- (10/50) 생성된 예시가 관련성이 없었습니다.
- (12/50) 생성된 예시가 관련성은 있지만 해결책이 잘못되었습니다.
- (28/50) 생성된 예시가 관련성이 있고 정확했지만, LLM이 새로운 문제를 해결하지 못했습니다:
- (12/50) 예시와 새로운 문제 사이의 일반화 격차로 인해 실패했습니다 (예: 새로운 문제가 예시보다 더 어려움).
- (8/50) 특정 예시에 지나치게 의존하여 잘못된 방향으로 이끌렸습니다.
- (8/50) 계산 실수 등 기타 문제가 있었습니다.
- 정답을 맞춘 50개 문제:
- 생성된 예시들은 대체로 관련성이 있고 정확했지만 관련성을 높이고, 해결책을 높이는게 정답을 맞추는데 도움이 될거임.
- 그리고 생성된 예시가 새로운 문제보다 간단해서 일반화에 도움이 안되는 문제를 해결하는 건 미래 연구에서 해결해야할듯
CONCLUSION and LIMITATIONS:
- 유추적 프롬프트는 문제 해결을 위해 관련된 추론 예시를 스스로 생성하는 새로운 언어 모델 프롬프트 방법임.
- 유추적 프롬프트는 기본적인 0-shot 및 0-shot CoT 프롬프트보다 더 많은 토큰을 생성하므로 , 추론 시 계산량이 증가함.
- LLM이 충분한 능력을 갖추지 못했거나, 새로운 문제를 해결하는 데 필요한 관련 지식을 학습하지 못한 경우, 자체 생성이 실패할 수도 있음.
- 반대로, 더 강력한 LLM은 관련된 사전 지식을 활용하여 더 복잡한 문제를 해결할 수 있다.