Abstract:
- 언어 모델의 추론 능력을 향상시키는 데 성공적인 것으로 알려진 “체인 오브 쏘트(Chain of Thought, CoT)” 기법에 대해 다른 관점에서 다룸.
- 아직 CoT의 근본적인 작동 방식은 완전히 이해되지 않았음. 일반적으로는 논리적으로 타당한 추론이 중요할 것으로 예상되지만, 이 연구에서는 놀랍게도 잘못된(유효하지 않은) 데모를 사용해도 성능에 큰 영향이 없다는 결과가 나왔음.
- 또 기존의 CoT는 언어 모델에게 어떤 실수를 피해야 하는지 명시적으로 알려주지 않기 때문에, 오히려 더 많은 오류를 유발할 수 있을거임.
- 이에 착안하여, 인간이 긍정적인 예시뿐만 아니라 부정적인 예시로부터도 학습하는 방식에 영감을 받아, 저자들은 언어 모델의 추론 능력을 향상시키기 위한 “대조적 체인 오브 쏘트(Contrastive Chain of Thought)“를 제안한다.
- 새로운 접근법은 기존의 CoT와 달리, 올바른 추론과 잘못된 추론의 데모를 모두 제공하는 방법임. 이를 통해 모델이 단계별로 추론하는 동시에, 어떤 실수를 피해야 하는지 학습하도록 도움.
- 일반화 능력을 높이기 위해, 저자들은 대조적인 데모를 자동으로 생성하는 방법도 도입함.
Introduction:
- 이전 연구들의 배경:
- 모델의 규모를 크게 확장하면 일반화 능력과 새로운 작업 수행 능력이 향상된다는 걸 발견함. (Brown et al., 2020; Wei et al., 2022a).
- 그러나 모델 크기만 늘리는 것으로는 복잡한 추론 작업을 해결할 수 없다는 것도 발견함. (Rae et al., 2022).
- 이러한 한계를 극복하기 위해 중간 추론 단계를 생성하여 모델의 추론 능력을 향상시키는 CoT 프롬프트가 제안됨. (Wei et al., 2022b).
- CoT 에 대한 이해가 부족:
- CoT의 성공에도 불구하고 그 작동 방식에 대한 완전한 이해는 부족함. (Cooper et al., 2021)
- 심지어 잘못된 추론을 포함한 데모도 올바른 데모와 비슷한 성능을 보인다는 연구가 있음. (Wang et al., 2023).
- 중간 단계에서의 실수는 전체 추론 과정을 탈선시킬 수 있으며, 이는 결과의 정확도와 모델의 신뢰성을 떨어뜨린다는 연구도 있다. (Ling et al., 2023; Turpin et al., 2023).
- 대조적 체인 오브 쏘트 (CCoT):
- 인간은 긍정적 예시뿐만 아니라 부정적 예시로부터도 학습한다는 점에서 영감을 받음.
- 모델에게 올바른(긍정적) 추론과 잘못된(부정적) 추론의 데모를 모두 제공하여 추론 능력을 향상시키는 방법을 제안함.
- 이 논문의 핵심 과제는 효과적인 부정적 데모를 어떻게 만들고 이를 다양한 작업에 일반화할 수 있는지가 핵심임.
- 여러 유형의 잘못된 추론을 분석하여 기존의 올바른 추론 체인에서 자동으로 대조적 데모를 생성하는 간단하고 효과적인 방법을 개발했음.
- 대조적 CoT는 작업에 종속적이지 않으며, 자기-일관성(self-consistency) 등의 다른 방법과도 호환될 수 있다고도 함.
- 실험 및 결과:
- GPT-3.5-Turbo 모델을 사용했을 때, 기존 CoT에 비해 GSM-8K 데이터셋에서 9.8점, Bamboogle 데이터셋에서 16.0점의 성능 향상을 보였다고 함.
- 그리고 제안된 방법으로 생성된 추론 체인은 오류가 크게 감소하였다고도 한다.
잘못된 CoT 추론 예시:

- Invalid Reasoning (잘못된 논리):
- 정의: 계산이 맞더라도 논리적인 오류가 포함된 경우.
- 문제: Leah가 32개의 초콜릿을 가지고 있고, 여동생이 42개의 초콜릿을 가지고 있습니다. 두 사람이 35개의 초콜릿을 먹었다면, 남은 초콜릿은 몇 개인가요?
- 올바른 CoT: Leah와 여동생이 각각 32개와 42개의 초콜릿을 가지고 있으므로, 총 74개의 초콜릿이 있습니다. 35개를 먹으면 74 - 35 = 39개의 초콜릿이 남습니다. 정답은 39입니다.
- 잘못된 CoT: Leah의 여동생이 Leah보다 10개의 초콜릿을 더 많이 가지고 있으므로, 42 - 32 = 10입니다. 이후 잘못된 계산을 통해 초콜릿이 39개가 남는다고 하여 정답은 맞추지만, 논리적인 단계가 틀렸습니다.
- 비교: 올바른 조건에서는 전체 초콜릿 수를 더하고 35를 빼는 과정을 거칩니다. 그러나 잘못된 논리에서는 여동생의 초콜릿 수에서 Leah의 초콜릿 수를 빼서 불필요한 계산을 하였고, 이 과정이 문제 해결에 불필요한 논리적 단계를 추가한 것입니다.
- Incoherent Objects (비일관적인 오브젝트):
- 정의: 문제와 맞지 않는 숫자나 대상을 사용한 경우.
- 잘못된 CoT: Leah와 여동생이 각각 32개와 42개의 초콜릿을 가지고 있다고 하면서, 이들을 합친 74 대신에 잘못된 값을 도입합니다. 그 결과 남은 초콜릿 수가 42라고 합니다.
- 비교: 올바른 CoT에서는 문제에서 주어진 숫자 그대로를 사용해 계산을 진행합니다. 하지만 비일관적인 오브젝트에서는 잘못된 숫자나 오브젝트(예: Leah의 초콜릿 수를 잘못 합산하거나 전혀 다른 값을 사용)를 사용하여 계산이 틀리게 진행됩니다.
- Incoherent Language (비일관적인 언어):
- 정의: 논리적으로는 맞을 수 있으나, 서술이 일관되지 않은 경우.
- 잘못된 CoT: Leah가 32개의 초콜릿을 가지고 있었는데, 그 다음 문장에서 Leah가 갑자기 42개의 초콜릿을 가지고 있다고 설명합니다. 결국 계산은 맞지만, 서술이 혼란스럽고 일관성이 없습니다.
- 비교: 올바른 CoT에서는 동일한 Leah의 초콜릿 수(32)를 일관되게 유지하지만, 비일관적인 언어에서는 갑작스럽게 Leah의 초콜릿 수가 바뀌어 혼란을 초래합니다. 논리적으로는 맞을 수 있으나, 언어적 일관성이 없는 상태입니다.
- Irrelevant Objects (관련 없는 오브젝트):
- 정의: 문제와 관련 없는 숫자나 대상이 도입된 경우
- 잘못된 CoT: Leah와 여동생이 각각 19개와 31개의 초콜릿을 가지고 있다고 가정하며, 전혀 다른 숫자를 도입하여 계산합니다. 계산 과정에서 초콜릿 수가 달라져 정답도 틀리게 나옵니다.
- 비교: 올바른 CoT에서는 문제에서 주어진 숫자를 그대로 사용하여 계산하지만, 관련 없는 오브젝트에서는 문제와 무관한 잘못된 숫자(19와 31)를 사용하여 계산합니다. 이로 인해 답이 틀리게 도출됩니다.
- Irrelevant Language (관련 없는 언어):
- 정의: 문제와 무관한 설명이나 정보가 추가된 경우.
- 잘못된 CoT: Leah와 여동생의 초콜릿 수를 설명하는 대신, Patricia라는 이름이 등장하고 그녀가 자선 단체에 머리카락을 기부하려 한다는 정보가 포함됩니다. 계산 과정은 맞지만 전혀 관계없는 언어적 설명이 추가됩니다.
- 비교: 올바른 CoT에서는 문제와 관련된 정보만을 사용하지만, 관련 없는 언어에서는 문제와 무관한 정보(Patricia와 머리카락 기부)가 포함되어 문제 해결에 혼란을 줍니다.
잘못된 CoT 추론과 기존의 CoT 와의 성능을 비교:
- 기존의 CoT와 비교하여, 모든 올바른 추론과 잘못된 추론을 모두 제공한 경우에 성능이 크게 향상되었다고 함.
- 이는 모델이 올바른 추론과 잘못된 추론을 모두 제공받을 때, 단계별 추론을 더 잘 학습할 수 있음을 시사한다.
- 잘못된 추론 유형 중에서도 비일관적인 오브젝트를 포함한 데모가 가장 큰 성능 향상을 가져왔다고 함.
Contrastive Chain of Thought 구체적인 방법:
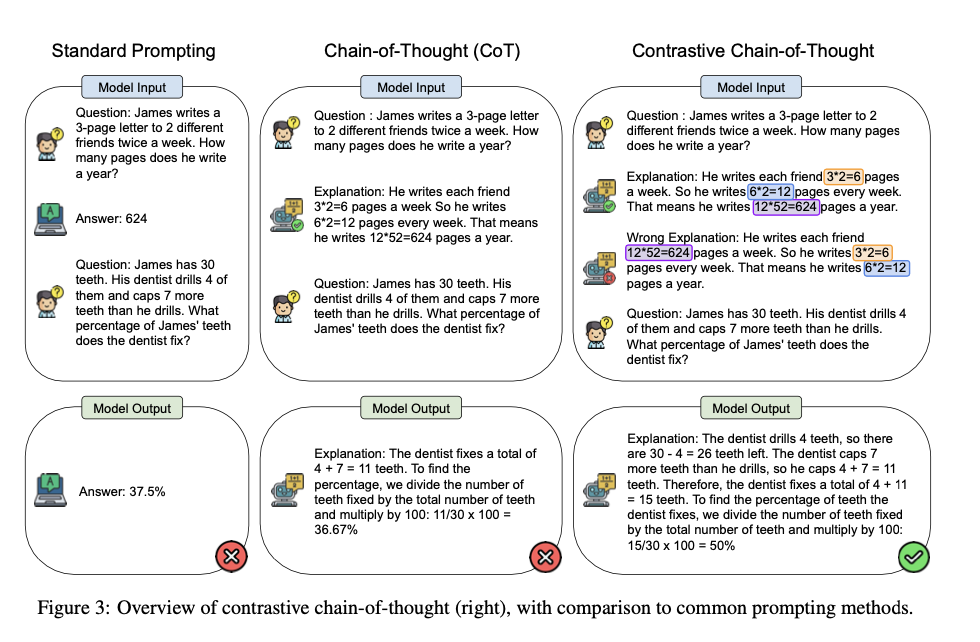
- 표준 프롬프트가 질문과 정답만 제공하는 E_j = (Q_j, A_j) 구조이고, CoT 가 질문, 중간 추론 단계, 최종 정답을 제공하는 E_j = (Q_j, T_j, A_j) 구조라면 CCoT 는 올바른 중간 추론 단계와 최종 정답 T_j^+, A_j^+, 그리고 잘못된 중간 추론 단계와 최종 오답 T_j^-, A_j^-를 함께 제공한다.
- 그리고 잘못된 추론 단계(T-)는 자동으로 생성됨:
- 비일관적인 오브젝트(incoherent objects) 추론 예시가 가장 성능 향상에 기여를 많이 했으니 이를 자동으로 만든다.
- 올바른 추론 단계(T+) 에서 객체(entity) 의 위치를 임의로 변경하는 것.
- 즉 숫자, 방정식, 인물 등과 같은 객체를 추출한 뒤, 이를 임의로 섞어서 비일관적인 추론 과정을 만듬.
CCoT 실험과 결과:
- 추론 작업의 종류: 실험은 두 가지 주요 추론 작업에 초점을 맞춤
- 산술 추론(Arithmetic Reasoning): GSM8K, AQuA, GSM-Hard, SVAMP, ASDIV와 같은 데이터셋을 사용
- 사실 기반 질문 답변(Factual QA): Bamboogle과 StrategyQA 데이터셋을 사용
- 결과:
- 대조적 CoT는 기존의 CoT에 비해 일관된 성능 향상을 보여주었음.
- 자기 일관성(Self-consistency)의 효과:
- Self-consistency 는 CoT 프롬프팅의 성능을 향상시키는 인기 있는 디코딩 전략임
- 이 실험에서는 대조적 CoT가 자기 일관성과 함께 사용될 때 성능이 더욱 향상된다는 것을 발견했음.
- AQuA 데이터셋에서는 대조적 CoT만으로는 성능이 4.0% 향상된 반면, 자기 일관성을 적용했을 때는 14.2%의 추가 성능 향상을 기록
'Generative AI > Prompt Engineering' 카테고리의 다른 글
| Complexity-Based Prompting for Multi-step Reasoning (0) | 2024.10.19 |
|---|---|
| Uncertainty-Routed CoT Prompting (0) | 2024.10.18 |
| True Detective: A Deep Abductive Reasoning BenchmarkUndoable for GPT-3 and Challenging for GPT-4 (0) | 2024.10.18 |
| Large Language Models as Analogical Reasoners (0) | 2024.10.18 |
| Take a Step back: Evoking Reasoning via Abstraction in Large Language Models (0) | 2024.10.17 |