What is the agent?
- An intelligent system taht interacts with some environemnt
- Physical Environmnet: robot, autonomous car
- Digital Environments: Alphago, Siri
- What is "intelligent"?
- 시대에 따라서 변하고 있긴 함.
- 3가지의 카테고리로 나뉘고 있다고 함:
- Level 1: Text Agent
- Uses text action and observation
- Examples: ELIZA, LSTM-DQN (초기 텍스트 대화형 Agent 임)
- Rulbe-based Agent 라는게 특징이었음. 대화를 하기 위해서 여러가지 룰을 설정해놔야함. 질문을 계속해줘야한다, 상대방의 응답을 반복해야한다 등.
- 즉 Manual design 을 해야한다는게 특징이었다.
- Level 2: LLM Agents
- Use LLM to act
- Examples: Langugae Planner, SayCan
- Level 3: Reasoning Agent
- Use LLM to reason to act
- Examples ReAct, AutoGPT
- 이것에 대해서 오늘 이야기 해볼거임.
- Level 1: Text Agent
LLM Agent 의 역사:
- LLM 에서 Reasoning 을 늘리려는 연구, Acting 을 해보려는 연구들이 합쳐서 ReAct 기반의 기법이 등장해서 Agent 가 되었고, 여기에서 새로운 종류의 어플리케이션과 Agent 를 이용하는 새로운 방법들이 등장

What is this paradigm of reasoning agent (ReAct?):
- QA 시스템을 기준으로 생각해보자:
- 일반적인 질문이라면 LLM 이 답할 수 있음.
- 하지만 어렵고 복잡한 문제를 묻는다면 Reasoning 이 필요할 수 있고 (Chain-of-Thought), 최근 사실을 묻는다면 훈련 데이터 이외에 새로운 지식을 얻을 수 있는 방법이 필요하고 (RAG), 어려운 계산 능력을 요구한다면 그것에 맞는 도구가 필요할 수 있음 (Code augumentation)
- RAG 기법같은 경우는 지식을 해결해줄 수 있지만 실시간으로 변경하는 지식까지는 알기 어렵다. (날씨를 묻는다거나, 현재 시간을 묻는다거나) 그래서 Tool use (Search engine, Calculator, APIs) 가 나옴.
- 그리고 이러한 도구를 사용하기 위해서는 LLM 이 특수한 구조의 토큰을 뱉어야하기 때문에 파인튜닝을 해야했음.
- 간단하고 Unifiying Solution 은 없을까? 라는 의문으로 ReAct Agent 가 등장:
- QA 시스템만 하더라도 여러 종류의 질문이 들어올 수 있기 때문에 준비를 해야한다.
- 각 질문에 맞는 기법을 우리는 다 연구하긴 했음. 근데 이거를 각각 상황에 맞게 잘 써주도록 조율해주는 존재가 필요하다고 생각함. 그래서 Reasoning 과 Acting 을 사용한 LLM Reasoning Agent 의 등장
- "Acting support Reasoning, Reasoning guides Acting"
ReAct Agent 의 동작 과정:
- 여기서 말하는 one-shot, few-shot prompting 은 ReAct Agent 의 Thought -> Action -> Observation 하는 과정을 이끌어내기 위해 프롬프팅으로 예시를 몇개 추가할거냐 이런 방법임. 이것 말고도 ReAct Agent 로 잘 동자하게끔 fine-tuning 하는 것도 있다.
- "Let's consider one task for now. (생각, 행동, 관찰을 한번에 하나씩)"
- Thinking 은 현재 진행 상황을 보고 계획을 하거나 어떠한 문제가 생겼을 때 어떻게 우회해서 해결할 지 이러한 것도 가능

ReAct Agnet 의 Zero-shot Prompt:

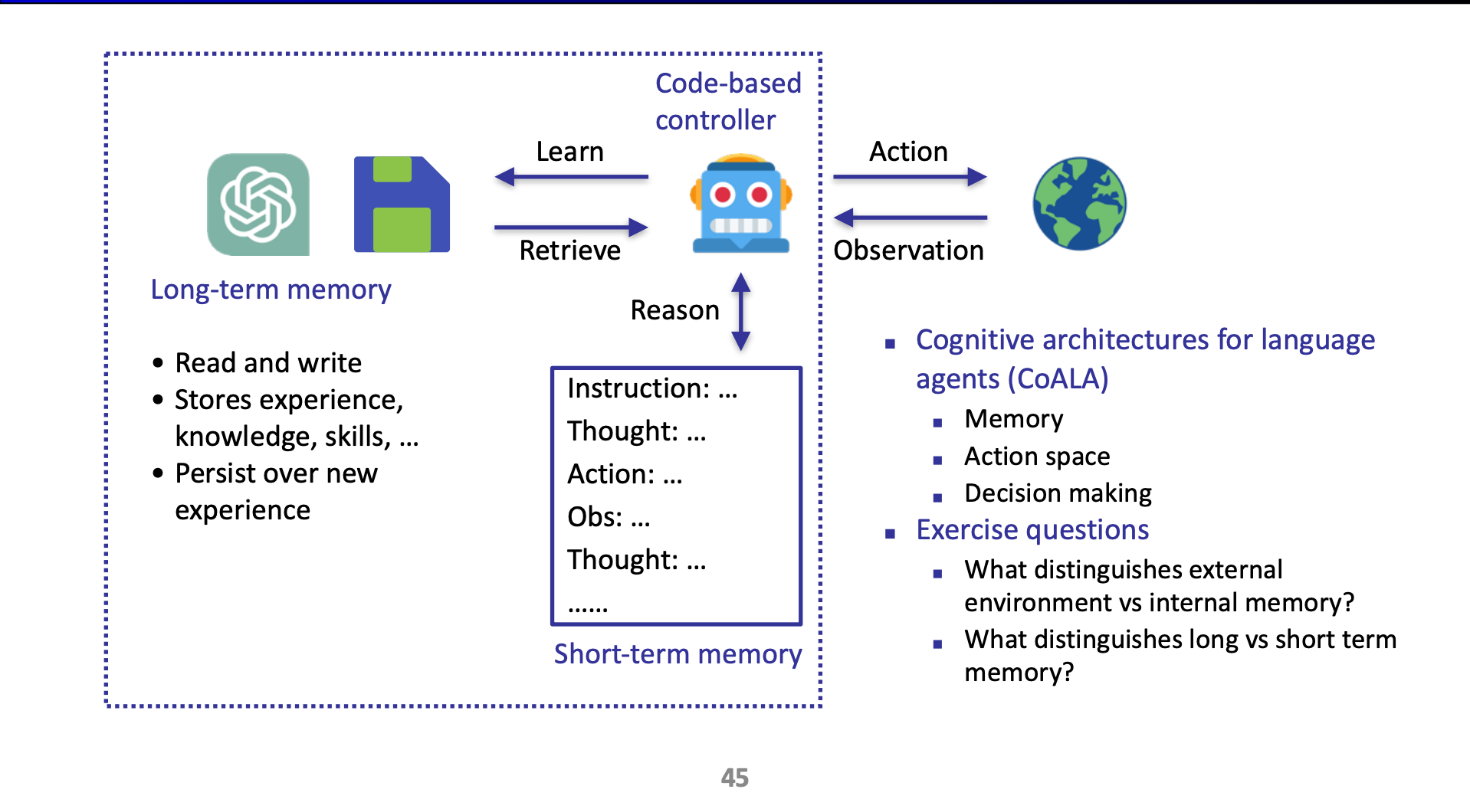
ReAct Agent 를 다루는 새로운 방법들이 등장하고 있음: 여기서는 가장 대표적으로 Long-term Memory 를 소개:
- 아무래도 ReAct Agent 가 작업의 내역들, 상태들을 기록하는 공간이 Prompt 다 보니까, 긴 문맥에서의 상태 유지가 힘들거임. 그리고 무조건 Append-only 로 프롬프트 내의 공간에 기록을 하기도 하고. 이런 컨택스트 윈도우 공간은 short-term memory 와 같은 것.
- Long term 메모리에서는 잊혀지면 안되는 지식들을 보관할거임.
대표적인 Long-term Memory 를 다루는 Agent 가 Reflextion:
- ReAct + Long-term Memory.
- 여기서 장기 메모리는 자신의 한 행동에 대한 피드백을 넣어두고, 다음에 행동할 때 이를 활용함.
- 이런 기법을 썼을 때 성능이 괜찮았다고 함.
- 이런 Reflextion 의 방법은 Tranditional RL (Reward 를 바탕으로 backpropagtaion 을 하는) 과는 다르게 언어적인 피드백을 할 수 있다고 New verbal RL 이라고도 불림
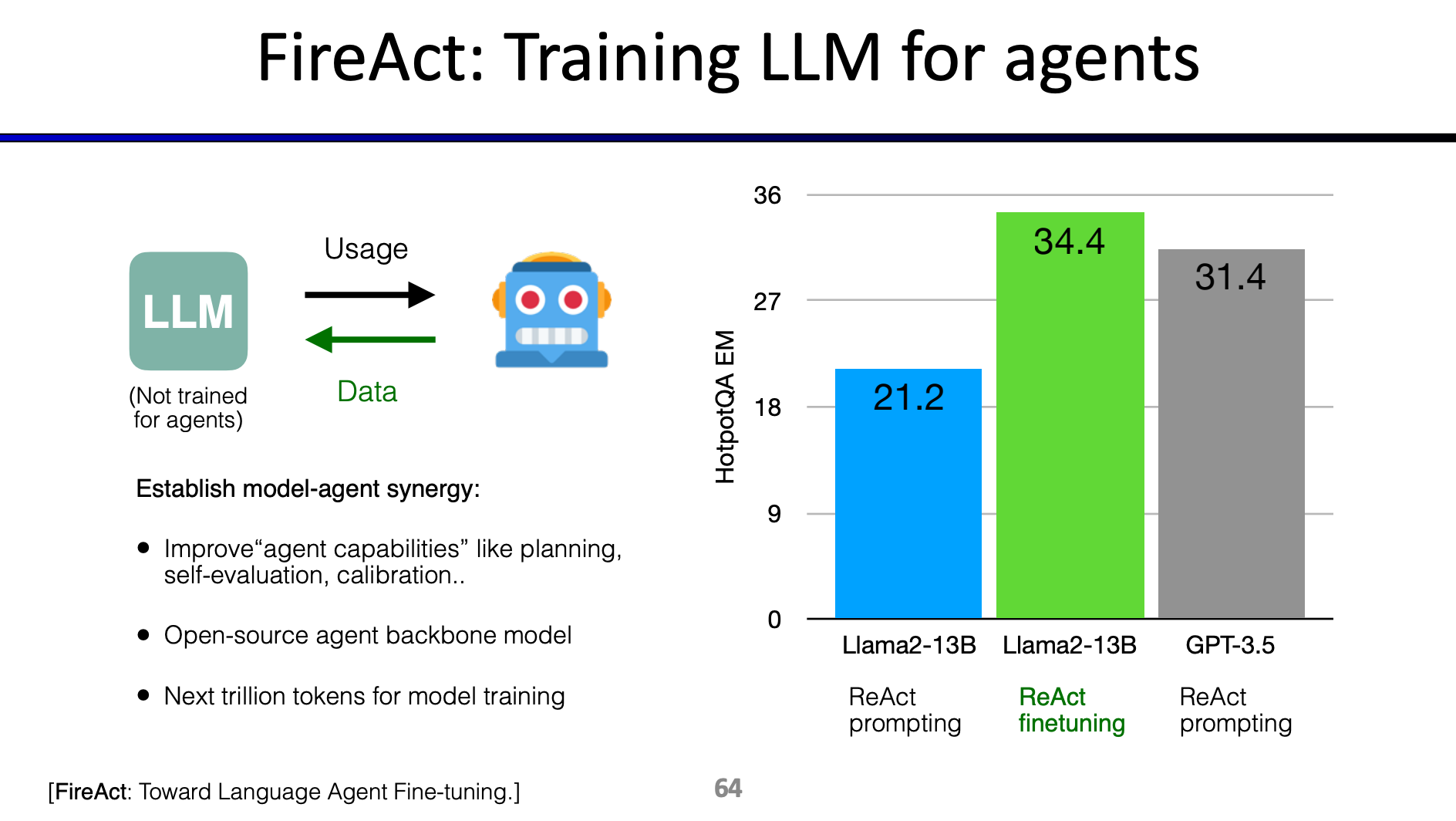
ReAct Agent 가 해당 작업을 잘 수행하도록 Fine-tuning 하는 건 도움이 됨:
- 아무래도 이런건 학습이 안되어 있을거니까. 예로 새로운 화확 물질을 발견하도록 Agent 가 작업을 수행하는 건 훈련되어있지 않을거임.
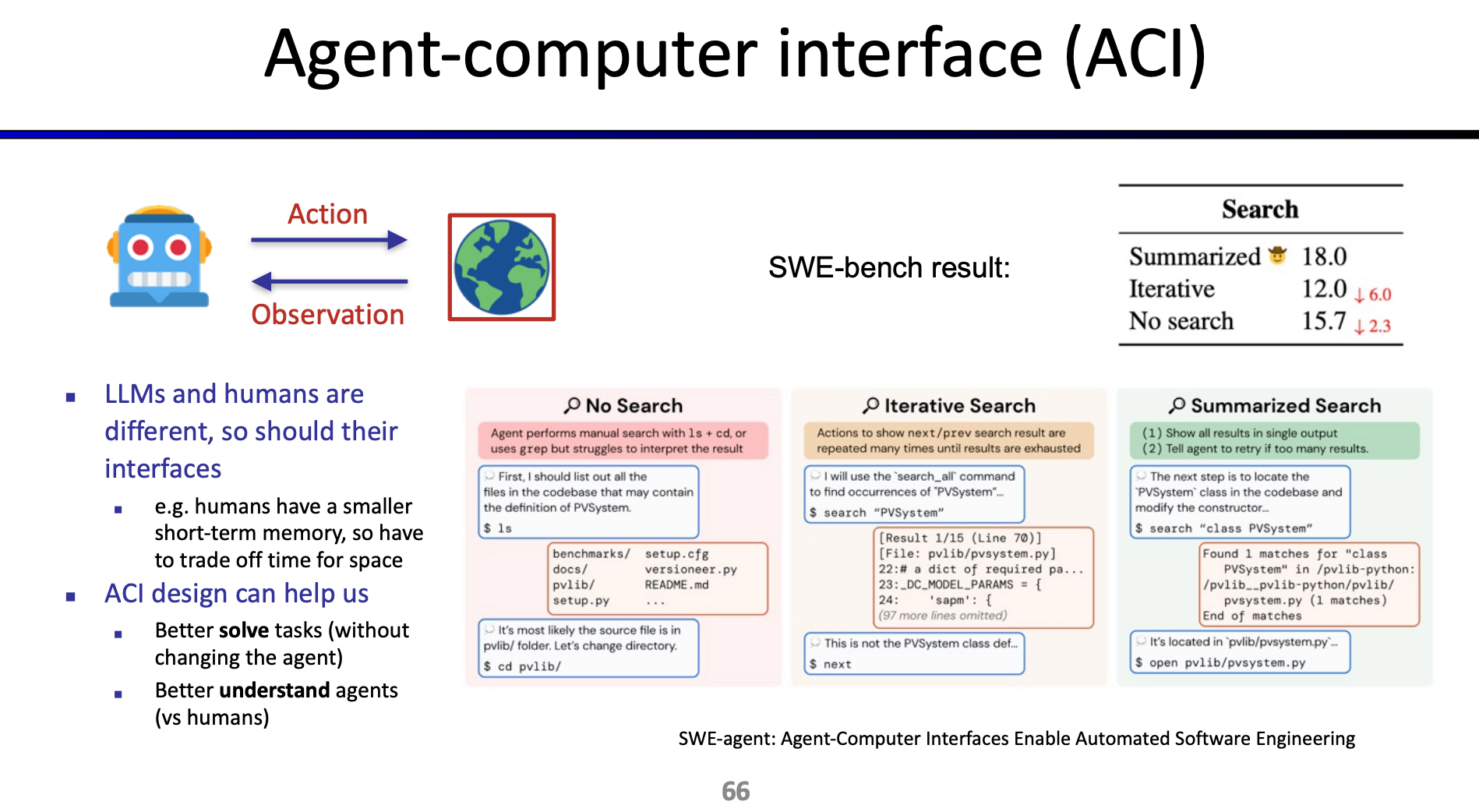
ReAct Agent 가 해당 작업을 잘 수행하도록 작업에 대한 결과 Output 은 요약해서 하나의 잘 정돈된 결과를 보여주는게 나음:
'Generative AI > Agent' 카테고리의 다른 글
| Summary of LLM Agent Framework (0) | 2024.12.23 |
|---|---|
| Cognitive Architectures for Language Agents (0) | 2024.12.23 |
| Premise Order Matters in Reasoning with Large Language Models (0) | 2024.12.21 |
| LLM Agent Course - (1) Reasoning (0) | 2024.11.18 |
| Multi AI Agent Systems with crewAI (0) | 2024.06.25 |