Abstract:
- 현재의 언어 에이전트(Agent) 연구가 빠른 속도로 발전했음에도 불구하고, 대규모 언어 모델(LLM)에 여러 가지 기능(예: 인터넷 검색, API 연동, 프롬프트 체이닝 등)을 ‘덧붙이는’ 식으로 이루어지다 보니 현재의 Agent 는 인간이 수행하는 것과 같은 복잡한 추론이나 행동을 보다 체계적으로 만들어낼 수 있는지에 대한 일관된 프레임워크가 부족하다는 문제가 있다고 함.
- 이를 극복하기 위해서 인지 구조(Cognitive Architecture) 개념에 따라 프레임워크를 제안하는 논문:
- 메모리(단기·장기 등) 모듈을 어떻게 구성할지:
- 모듈형 메모리(modular memory components): 여러 종류의 기억(단기 메모리, 장기 메모리 등)을 모듈별로 분리·조직화
- 행동(액션) 공간을 어떻게 정의할지:
- 구조화된 행동 공간(structured action space): 에이전트가 내부 메모리와 외부 환경을 어떤 방식으로 상호작용할지 정의하는 액션 타입(명령, API 호출 등)을 설계
- 여러 액션 중 무엇을 선택하고 어떻게 의사결정을 내리고, 어떤 걸 메모리에 저장할지:
- 일반화된 의사결정 과정(generalized decision-making process): 이러한 액션들 중 어떤 것을 선택할지, 혹은 어떤 정보를 어떤 메모리에 저장할지를 결정하는 체계적 프로세스
- 메모리(단기·장기 등) 모듈을 어떻게 구성할지:
Introduction:
- 초기에는 LLM이 직접 액션을 생성하는 단순한 방식(예: LLM이 곧바로 ‘이렇게 행동하라’고 지시)을 사용했었음.
- 이후에는 추론(Yao et al., 2022b - ReAct), 계획(Hao et al., 2023 - Reasoning with language model is planning with world model; Yao et al., 2023 - Tree of Thought), 장기 메모리 관리(Park et al., 2023 - Generative Agent 등) 등 보다 정교한 내부 프로세스를 마련해 더 나은 의사결정을 수행할 수 있게 발전함
- 문제는 이런 발전 과정에서 사용되는 용어(‘tool use’, ‘grounding’, ‘actions’ 등)가 제각각이어서, 서로 다른 연구를 비교·분석하기 어렵고 앞으로 새로운 에이전트를 만들 때 체계적인 지침이 부족하다는 점이 있음.
- 그래서 표준을 잡고 일관성을 기르는 것을 제안하고 싶은 것.
- 이를 바탕으로 저자들은 CoALA라는 개념적 프레임워크를 제시함:
- CoALA는 언어 에이전트를 세 가지 축으로 구분해 살펴본다:
- 정보 저장 구조: 작업 기억(working memory)과 장기 기억(long-term memory)을 어떻게 나누고 구성할 것인가?
- 행동 공간(action space): 내부 액션(추론, 계획 등)과 외부 액션(API 호출, 환경 조작 등)을 어떻게 정의할 것인가?
- 의사결정 절차: 계획과 실행이 상호작용하는 반복적(인터랙티브) 루프를 통해, 어떤 액션을 언제 수행할 것인가?
- CoALA는 언어 에이전트를 세 가지 축으로 구분해 살펴본다:
Background:
- Agent 시스템의 프레임워크를 제안하기 이전에 과거에 만들어진 AI 시스템에 대해서 알아보자.
- 생산 시스템(Production Systems) 과 인지 아키텍처(Cognitive Architectures) 가 어떻게 탄생했는지 보자.
- 생산 시스템이란, 일종의 “규칙 집합”으로 이루어진 형식 체계(formal system)를 말함:
- 각 규칙은 어떤 전제(precondition) 이 충족되었을 때 할 수 있는 행동(action) 으로 구성됨. 즉 전제가 만족되면 대응되는 액션(문자열 변형, 혹은 논리적 결론 도출)이 수행됨.
- 과거의 AI 시스템은 rule-based 였음.
- 예를 들면 XYZ -> XWZ 규칙은 문자열 안에서 XYZ라는 부분 패턴을 발견했을 때, 이를 XWZ로 바꾼다는 것을 의미.
- 전통적인 인지 아키텍처 Soar:
- 메모리 구조:
- 작업 기억(Working Memory):
- 에이전트가 당장 주목하고 있는 상태(state)를 저장.
- 장기 기억(Long-Term Memory):
- 절차적 기억(Procedural Memory): 에이전트가 사용할 생산 규칙(Production rules) 자체를 저장.
- 서술적 기억(Semantic Memory): 세계에 대한 사실(knowledge)을 저장.
- 에피소드 기억(Episodic Memory): 과거 행동들의 시퀀스(경험)를 저장.
- 작업 기억(Working Memory):
- 근거(grounding):
- Soar 에이전트는 로봇 센서, 시뮬레이션, 사용자 입력 등 환경으로 얻을 수 있는 정보들을 작업 기억(Working memory)에 저장함. 이런 정보는 의사결정을 할 때 도와줄거임.
- 의사결정으로부터 외부에 행동도 가능하게 됨
- 의사결정 과정(Decision Making):
- 의사 결정 루프를 가짐. 이 의사 결정 루프에서 다음 의사 결정을 할 때 생산 규칙들을 모두 비교하고 어느 규칙을 적용할 수 있는지 평가함. 그리고 이렇게 결정된 걸 행동함.
- 학습(learning):
- 새롭게 안 사실을 장기 기억에 저장함.
- 강화학습 기법을 통해, 좋은 결과를 낸 규칙은 강화하고(우선순위 상승), 좋지 않은 결과를 낸 규칙은 약화됨.
- 새로운 생산 규칙을 생성하는 것도 가능함.
- 인지 아키텍처의 한계:
- 미리 정의된 규칙을 많이 필요로 하는 약점이 있음. 근데 이런 규칙은 논리(predicate)로 표현 가능한 도메인에 국한된다고 함.
- 하지만 LLM 은 자연어 기반으로 규칙을 정의할 수 있음, 그리고 추론 능력도 가지고 있음.
- 메모리와 학습 (규칙 학습 및 자가 수정), 의사결정 루프만 LLM Agent 에게 추가하면 되지 않느냐 이런 식으로 생각하고 있음.
- 메모리 구조:
CoALA:
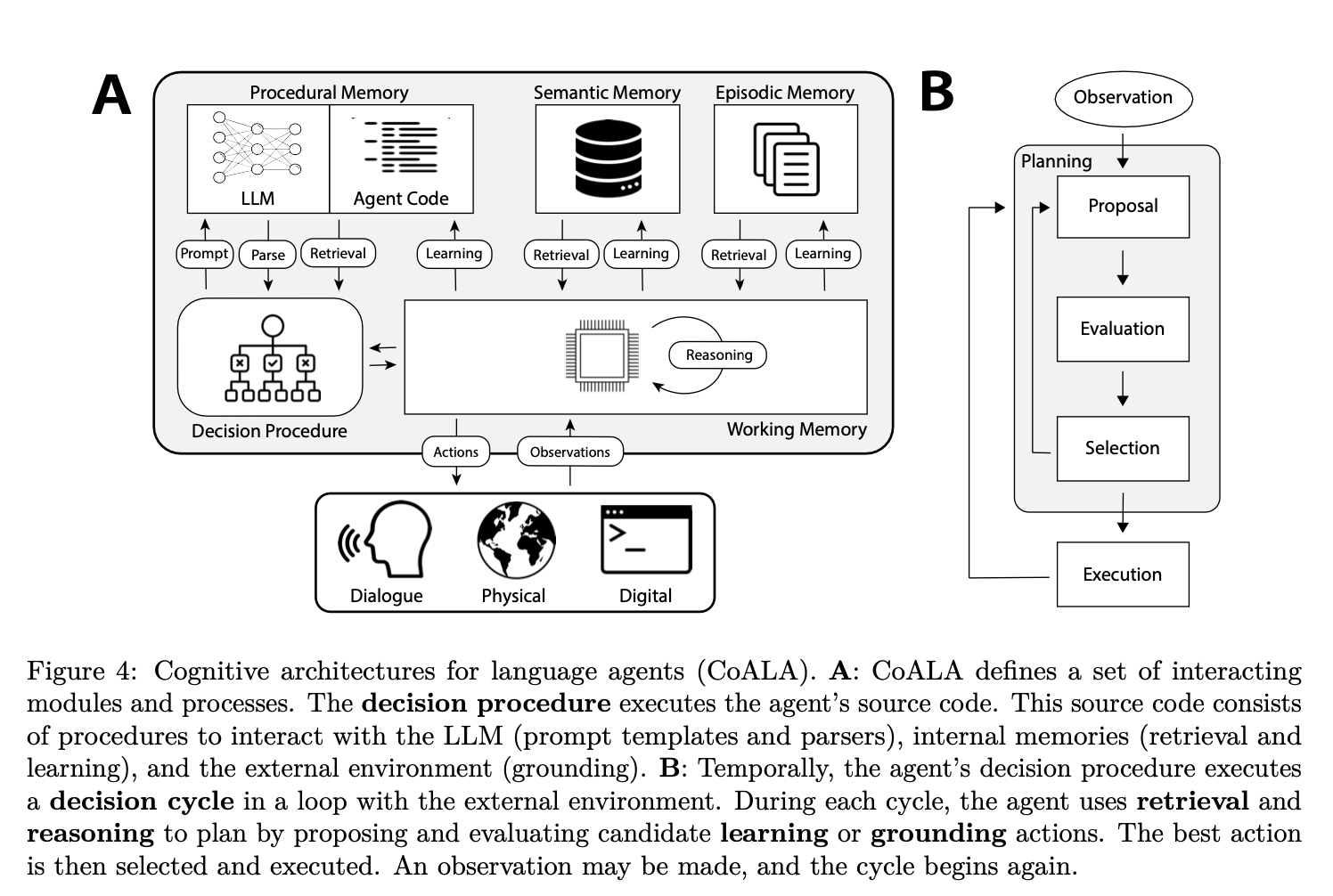
- CoALA 프레임워크를 통해서 LLM을 중심에 두고, 에이전트가 내부·외부로 어떤 식으로 작동하는지 체계적으로 구성해보자는 것.
- CoALA에서 LLM은 에이전트의 핵심 추론 엔진 역할을 담당.
- 모듈 정리:
- 메모리:
- 에이전트는 여러 종류의 메모리를 활용함.
- LLM 은 이 메모리에 있는 정보를 참조하고 갱신함으로써 맥락을 유지하고, 작업을 수행하는데 도움을 주고, 새로운 학습을 할 수 있다.
- 저장할 떄는 날 것의 그대로를 넣는 방식도 있지만, 요약하고 구조화하고, 검색을 할 수 있도록 구성할 거임.
- 단기 메모리 or Working Memory:
- 추론을 위한 정보, 의사 결정에 필요한 정보를 저장하는 곳
- Context Window 와의 차이점은 Context Window 는 LLM 입력으로 제공되는 단발성 정보라면, Working Memory 는 지속성이 있다. LLM 을 호출할 때 Agent 가 필요한 정보만 딱 가져와서 사용하면 됨. 이 과정은 Retrieval 이라기 보다는 일반적인 사용 방식을 말함. (Retrieval 은 여기서 장기 메모리에서 가져오는 연산이라는 큰 의미를 부여헀으니.)
- LLM 출력은 다시 작업 기억에 저장해 에이전트 내부 상태로 저장된다.
- 이 Working Memory 는 장기 기억과 외부 환경에 대한 정보가 모이는 중심지가 됨.
- 장기 메모리 or Long-term Memory:
- 지속적으로 유지해야 할 지식이나 과거 경험을 저장
- 여러 종류가 있음:
- Episodic Memory(에피소드 기억):
- 에이전트가 이전에 경험한 사건을 기록하는 기억
- 다음 결정을 내릴 때 과거 경험을 참고해서 내릴거임. 과거에 비슷한 상황이 있었는지 비교해보고 결정을 내릴 수도 있고, 이전에 실패한 내역을 참고해서 결정을 내릴 수도 있을 것.
- 작업 기록에서 현재 일어난 일을 기록해서 나중에 회고를 하거나, 새로운 배움(learning) 이 될 수 있도록 활용할 수 있음.
- Semantic memory(서술 기억):
- 세상에 대한 지식이나, 에이전트가 이 지식으로 만들어낸 새로운 지식도 저장될 수 있음.
- 이런 지식은 Agent 가 의사결정을 할 떄 필요하면 검색(Retrieval) 해서 정확한 답변이나 행동 방안을 마련할 수 있을거임.
- RAG 기법과 유사할 수 있다고 보고, LLM 추론 과정에서 얻어냈던 지식도 동적으로 지식 베이스에 저장하는 것도 가능.
- Procedural memory (절차 기억):
- Agent 가 할 수 있는 행동들을 정의해두는 것. 여기서 정의된 행동들만이 Agent 가 할 수 있다.
- GPT 의 Tool use 와 비슷함. 외부 행동들에 대해서 할 수 있다는 점이. 하지만 절차 기억은 여기서 다양한 도구를 더 필요로 하고, 어떤 순서로 추론을 진행하고, 언제 외부 환경과 상호작용할 수 있는지, 언제 어떻게 메모리에 저장하면 되는지 이런 정보도 넣어줘야함.
- 절차 기억은 에이전트의 “행동 방식 자체”를 바꾸는 것이므로 조심해야함.
- 크게는 할 수 있는 것으로 다음과 같음:
- Reasoning: 다음 행동을 게획하거나, 생각을 깊게 해보거나
- Retrieval: 메모리에서 읽기
- Grounding(환경과의 상호작용) 액션: 구체적으로 어떻게 외부와 상호작용할지
- Learning (장기 메모리에 쓰기)
- Episodic Memory(에피소드 기억):
- 행동(Action) 공간:
- 에이전트가 취할 수 있는 액션(행동)을 외부 액션과 내부 액션으로 구별
- 외부 액션 (grounding):
- 에이전트가 외부 환경과 상호작용하는 행동들.
- API 를 호출하거나, 웹 검색을 하거나 등
- 에이전트과 외부 환경과 연결되는 과정을 grounding(근거) 라고 부름. 그리고 이러한 행동들, 상호 작용들을 텍스트로 표현하는 작업을 말함.
- 종류로는 다음과 같음:
- Physical environments (물리 환경):
- 예시: 로봇 제어, 센서 입력(영상, 음성, 촉각 등), 물리 환경 탐색 등
- 센서로부터 들어오는 비전·오디오·촉각 데이터를 텍스트(자연어) 형태로 변환하고, 에이전트(LLM 기반)가 이 텍스트 정보를 통해 추론해서 행동 명령(“move forward 1 meter” 등)을 생성한다. 이를 로봇 플래너나 제어 모듈에 전달해 실제 물리적 행동을 수행하게 됨.
- 실제 물리적인 행동을 위한 인터페이스 구조로 Agent 가 잘 만들어주는게 중요할듯.
- Dialogue with humans or other agents (사람/에이전트 간 대화):
- 예시: 사용자와 대화형으로 상호작용, 협업(콜라보) 에이전트들끼리 대화, 감정적 지원 봇 등
- 인간(혹은 다른 에이전트)으로부터 텍스트 메시지를 입력받고, 에이전트가 내부적으로 추론을 한 후 응답(텍스트)를 생성한다. 그리고 이 텍스트는 사람이나 다른 Agent 에게 전달되고.
- 이러한 대화를 통해 작업이 더 개선될거임.
- 최근 연구에서는 여러 에이전트가 서로 대화하며 사회적 시뮬레이션(Park et al., 2023 등)을 하거나, 토론(Debate), 협동(Collaboration) 등에 활용됨.
- Digital environments (디지털 환경):
- 예시:
- 게임(텍스트 기반 게임, 3D 게임 등)에 접속해 플레이
- API 호출 (검색 엔진, 계산기, 번역기, DB 조회 등)
- 웹사이트 접속·조작 (클릭, 입력, 탐색 등)
- 코드 실행 환경 (인터프리터, REPL 등)
- Tool use (검색, 계산기, 번역 등 특정 기능) 을 API 형태로 호출하는 방식도 디지털 환경과 상호작용 하는 것으로 볼 수 있음.
- 예시:
- Physical environments (물리 환경):
- 내부 액션:
- 에이전트가 자신의 내부 메모리와 상호작용하는 과정.
- 크게 3가지로 구분:
- Retrieval (장기 메모리에서 읽기):
- 장기 메모리(semantic, episodic, procedural)에 저장된 정보를 작업 기억(working memory) 으로 가져오는 과정을 말함.
- 예: 에이전트가 과거 에피소드 기억(사용자와의 과거 대화, 게임에서의 이전 경험 등), 서술 기억(지식 베이스), 혹은 절차 기억(스킬 라이브러리)에서 필요한 정보를 검색해온 뒤, 작업 기억에 주입.
- 구현 예시:
- Voyager(Wang et al., 2023a): 마인크래프트 세계와 상호작용하기 위해, 스킬 라이브러리에서 코드 스니펫을 Dense Retrieval로 검색 → 이는 사실상 “절차 기억”에 있는 스킬을 불러오는 것과 동일.
- Generative Agents(Park et al., 2023): 에이전트가 과거 에피소드 중 “가장 관련 있는 사건(event)”을 가져오기 위해 여러 기준(최신성, 중요도, 연관도)을 활용해 에피소드 기억에서 검색.
- DocPrompting(Zhou et al., 2022a): 코드 작성 시 라이브러리 문서를 참고해서, 이는 곧 “서술 기억(knowledge)”을 조회하는 Retrieval 액션에 해당.
- Retrieval은 인간의 의사결정에도 핵심적인 역할을 함.
- 하지만 언어 에이전트 분야에서는 아직 ‘적응적이고 맥락 맞춤형’ retrieval 방법이 충분히 연구되지 않았음. 즉 매 순간의 상황(맥락) 에 맞춰 적절한 정보를 장기 메모리에서 가져오는 기술이 아직 부족하다는 것:
- “과거에 유사한 문제를 어떻게 풀었지?”라는 질문이 떠오르면, 해당 문제와 진짜 유사한 사례만을 골라서 빠르게 참조할 수 있어야 함.
- 혹은 사용자가 새로 입력한 맥락과 관련도가 높은 문서나 지식만 잘 선별해서 불러오는 등, 매번 조건(필요 정보, 최근 대화, 문제의 타입 등)에 따라 ‘딱 맞는’ retrieval이 요구됨.
- 이거에 맞는 Fine-tuning 된 모델이 필요하지 않을까? 각 상황에 맞는 검색을 만들 수 있도록 하는.
- 논문에서는 의사결정과 Retrieval을 어떻게 정교하게 통합할지가 중요한 과제라고 말함.
- Reasoning (단기 메모리에 있는 정보를 기반으로 추론을 수행한 뒤, 그 결과를 다시 단기 메모리에 반영하는 과정)
- 작업 기억 내의 정보를 바탕으로 “새로운 정보를 조합 또는 추론을 통한 생성”해내는 과정.
- Retrieval과 달리, 장기 메모리가 아니라 작업 기억만을 읽고(입력) → 그 결과를 다시 작업 기억에 쓴다는 점이 특징임.
- 주로 하는 역할:
- 최근 관찰 데이터나, 방금 Retrieval로 불러온 정보를 요약·재구성 -> 이를 통해 새로운 통찰(insight)이나 중간 계산 결과를 얻음. (새로운 통찰은 메모리에 또 저장될거임)
- Reasoning 결과가 가치 있으면, 이를 에피소드 기억이나 서술 기억 등에 기록해 놓음
- Reasoning 결과(추론된 아이디어·계획 등)는 이후 LLM 호출의 추가 맥락으로 사용되어 의사 결정에 더 나은 판단을 내리도록 도움.
- 이 작업은 CoT 프롬프트로 구성될 수 있을거임.
- 예시:
- Yao et al. (2022b - ReAct), Peng et al. (2023 -Language guided state abstractions): 최신 관찰을 요약해 다음 행동에 필요한 단서로 활용.
- Shinn et al. (2023 - Reflextion): 가장 최근까지의 행동·결과들을 분석해, 다음 결정에 도움이 되는 통찰을 뽑아냄.
- Park et al. (2023 - Generative agents): 장기 메모리에서 불러온 정보도 Reasoning으로 재해석·정리해, 이후 학습이나 의사결정에 반영.
- Learning (장기 메모리에 새로운 지식·규칙을 쓰기):
- 장기 메모리(episodic, semantic, procedural)에 새로운 정보나 지식, 규칙을 쓰는 과정을 어떻게 구현할 수 있는지에 대해 다룸
- 1) 에피소드 기억(Episodic Memory) 업데이트:
- “과거 경험”을 저장해두는 메모리에 새로운 경험(trajectory) 을 추가 기록. “비슷한 상황이었을 때 어떻게 행동했고 그 결과가 어땠는지”를 다시 살펴보기 위함임.
- 강화학습(RL)에서는 에이전트가 플레이한 에피소드(상태, 행동, 보상 등)를 저장했다가, 이후 이 데이터를 활용해 정책(policy) 업데이트.
- Generative Agents(Park et al., 2023) 등에서, 이전 대화나 행동 이력을 에피소드 기억에 넣어두고, 필요할 때 Retrieval 액션으로 꺼내서 의사결정에 활용.
- 2) 서술 기억(Semantic Memory) 업데이트:
- 세상 또는 에이전트 자신에 대한 “지식”을 담는 메모리에 새로운 지식을 추가
- Reflexion(Shinn et al., 2023): 실패 에피소드를 분석해 얻은 교훈(“부엌에는 식기세척기가 없음”)을 서술 기억에 저장 → 이후 비슷한 상황에 활용.
- 로보틱스 예시(Chen et al., 2023a): 비전-언어 모델로 환경 지도를 만들고, 이를 질의(query)에 활용
- 언어 에이전트가 경험(episodic)을 분석·추론(Reasoning)해 지식 형태로 정리, 서술 기억에 저장 → “축적된 지식”을 나중에 재사용.
- 3) LLM 파라미터(Procedural Memory) 업데이트:
- LLM 자체의 가중치(weights) 혹은 내부 모델 파라미터를 재학습(Fine-tuning)하여, 에이전트가 암묵적 추론 능력을 개선하는 방법
- XTX(Tuyls et al., 2022 - Multi-stage episodic control for strategic exploration): 에피소드 기억에 저장된 “고득점 플레이 기록”을 모아서 작은 LLM을 주기적으로 파인튜닝 → 좋은 정책을 빠르게 확보
- 하지만 비용이 크다는 특징이 있음. 그래서 학습 스케줄(“언제, 어떻게 파인튜닝할지”)을 사전에 정해두거나, 에이전트가 “필요하다고 판단할 때”만 제한적으로 수행
- 4) 에이전트 코드(Procedural Memory) 업데이트:
- LLM 가중치가 아닌, 에이전트가 사용하는 코드 자체(추론 절차, 툴 사용 방식, 학습 방식, 의사결정 로직 등)를 수정·갱신하는 방법
- 크게는 다음이 있음:
- Reasoning 업데이트:
- 프롬프트 템플릿, 추론 스크립트 등을 바꾸어 “추론 방식”을 개선
- APE(Zhou et al., 2022b - Episodic retrieval for model-based evaluation in sequential decision tasks)처럼 입력-출력 예시를 기반으로 “프롬프트 지침(prompt instruction)”을 자동 생성하여, 이 지침을 LLM 프롬프트에 첨부.
- Grounding(외부 액션) 업데이트:
- 새로운 “툴 사용 코드”나 “스킬 라이브러리”를 작성·보강해, 에이전트가 더 다양한 외부 환경을 다룰 수 있게 함.
- 예: Voyager(Wang et al., 2023a)가 마인크래프트 상호작용 스킬을 동적으로 생성·추가.
- Retrieval 업데이트:
- 현 시점에선 연구가 부족하다고 언급.
- 문서 확장, 질의 확장, dense retrieval 개선 등 기법을 통해 “어떻게 검색할지” 자체를 학습할 수도 있음.
- Learning / Decision-making 업데이트:
- 에이전트의 학습 방식(예: 어떤 방식으로 메모리에 정보를 쓰는지)이나 의사결정 로직 자체를 변경.
- 그러나 이는 기능적·안정성 측면에서 매우 위험(에이전트가 자가 수정으로 인해 의도치 않은 버그나 ‘비정렬(alignment)’ 문제를 일으킬 우려).
- 현재는 연구 사례가 거의 없으나, 장기적으로 흥미로운 방향.
- Reasoning 업데이트:
- RL 에이전트들은 주로 하나의 학습 방법(Q-learning, PPO 등)만 사용하지만, 언어 에이전트는 상황에 따라 여러 학습 절차(Episodic, Semantic 업데이트, 파라미터 파인튜닝, 코드 수정 등)를 골라서 사용할 수 있음.
- 빠르게 “지식”만 쌓고 싶다면 서술 기억에 텍스트 형태로 저장, 근본적인 추론 능력을 개선하고 싶다면 LLM 파라미터를 파인튜닝할 수 있음.
- 메모리에 추가만 하는 게 아니라, 수정·삭제(“unlearning”)도 중요. 아직 논문에서는 이 영역이 충분히 연구되지 않았다고 지적.
- 에이전트가 쌓은 기억 중 잘못된 정보나 더 이상 유효하지 않은 지식을 어떻게 제거할지도 중요한 과제.
- Retrieval (장기 메모리에서 읽기):
- 의사결정(Decision-making)
- CoALA에서 에이전트는 반복적(repeated) 의사결정 사이클을 가짐. 의사 결정은 에이전트가 할 수 있는 모든 액션(외부 액션과 내부 액션) 중에서 “어떤 액션을 언제 실행할 것인지”를 결정하는 절차가 핵심임.
- 크게 “계획(Planning) 단계”와 “실행(Execution) 단계”로 나뉘며, 이 모든 과정이 반복적 사이클(Figure 4B)로 이루어진다는 것이 주요 골자
- 각 사이클에서 Reasoning과 Retrieval 액션을 통해 Planning 을 하고 그 결과로 Grounding(외부 액션) 또는 Learning(장기 메모리에 기록) 액션을 선택하여 실행함
- Reasoning 은 Planning 에서만 활용되는게 아니라 하나의 깊은 생각을 통해 독립적인 추론을 해보는 것일 수 있을 거임. 그리고 그 결과로 단기 메모리나 장기 메모리에 쓰일 수도 있겠지.
- 에이전트가 할 수 있는 액션:
- Grounding actions (환경과 상호작용, 외부 액션)
- Learning actions (장기 메모리에 쓰기)
- Reasoning actions (작업 기억 내 추론)
- Retrieval actions (장기 메모리에서 정보 읽기)
- 실제로 한 번에 모든 액션을 다 하는 것은 아니고, 매 사이클마다 “결국 실행할 최종 액션”(외부 환경과 상호작용 혹은 내부 학습)을 선택해야 함.
- Planning Stage (계획 단계):
- 실행할 액션(특히 외부 액션 또는 학습 액션)을 “제안(Proposal) → 평가(Evaluation) → 선택(Selection)” 하는 과정.
- 보통 Reasoning과 Retrieval 액션을 사용해 후보 액션을 만들고, 각각의 가치를 평가한 뒤, 최종적으로 하나를 골라 실행할지 결정하는 식으로 동작함.
- Proposal (액션 제안):
- LLM을 통해 “가능한 액션(혹은 액션들의 시퀀스)”을 생성하거나, 혹은 도메인 지식/규칙에 의해 후보 액션 집합을 나열
- 도메인이 단순하면 모든 액션(혹은 상태에서 가능한 모든 액션)을 그냥 열거할 수도 있고, 복잡한 경우라면 LLM 추론(Reasoning)으로 가장 적절해 보이는 액션 몇 개만 뽑아볼 수 있음.
- Evaluation (액션 평가):
- 제안된 액션마다 가치(value) 를 부여해서 어떤 것이 더 괜찮은 결과를 낼 지 비교하는 것을 말함.
- 예시로 LLM의 perplexity를 활용(Ahn et al., 2022 - Do as I can, not as I say: Grounding language in robotic affordances.), 또는 내부적으로 시뮬레이션(Reasoning)해 “이 액션의 결과가 어떨지”를 추론(Yao et al., 2023 - Tree of Thought; Hao et al., 2023 - Reasoning with language model is planning with world model.).
- Selection (액션 선택):
- 평가가 끝난 액션들 중 하나를 실제로 실행하거나, 필요하면 모든 후보를 기각하고 다시 Proposal로 돌아갈 수도 있음
- 선택 과정은 보통 argmax, softmax sampling, 다수결 투표 등 다양한 방법 중 하나를 사용해 결정
- Execution Stage (실행 단계):
- 선택된 액션을 실제로 수행하는 단계.
- 예: 외부 Grounding(웹 API 호출, 로봇 제어 등) 혹은 내부 Learning(장기 메모리에 쓰기).
- 그리고 실행 결과로 외부 환경이나 내부 상태가 변화하여 새 관찰(observation)이 생기면, 이를 작업 기억에 반영한 후 다음 의사결정 사이클로 넘어가면 됨.
- 선택된 액션을 실제로 수행하는 단계.
- 이러한 액션 결정의 동향은 다음과 같음:
- 초기 언어 에이전트: LLM으로부터 곧바로 액션 하나를 샘플링해서 실행(Ahn et al., 2022; Schick et al., 2023 등). 중간 단계 추론이나 별도의 평가 없이 단순하게 동작.
- 이후에는 Reasoning 및 Retrieval 등을 활용해 상황을 분석하고, 액션 계획을 유지·수정(Xu et al., 2023b; Wang et al., 2023a; Park et al., 2023)하며, 더 복잡한 절차적 과정을 거쳐 액션을 제안·선택.
- 가장 최근에는 여러 액션 후보를 한 번에 고려해 반복적으로 제안(Proposal)과 평가(Evaluation)을 수행(Tree of Thoughts, RAP 등), 고전적인 BFS/DFS나 MCTS 같은 탐색·계획 알고리즘을 LLM으로 구현(Yao et al., 2023; Hao et al., 2023).
- 메모리:
Case Study:
- SayCan (Ahn et al., 2022):
- 도메인: 로봇(물리) 환경, 예: 부엌에서 유저가 원하는 아이템을 가져다주기
- 메모리:
- 장기 기억: LLM(절차 기억) + 학습된 value function(특정 스킬(skill)을 현재 상황에서 실행했을 때 성공할 가능성이 얼마나 높은가를 추정해주는 함수 )
- 서술 기억이나 에피소드 기억은 없음
- 액션:
- 외부 액션(grounding)만 존재: 551개 로보틱 스킬(e.g., “find the apple”, “go to the table”)
- 내부 액션(Reasoning, Retrieval, Learning)은 없음
- 의사결정:
- 각 스킬(action)을 후보로 열거하고, LLM과 value function을 함께 사용해 평가(“유용성 + 실행 가능성”).
- 최적 스킬을 1회 선택 후 바로 실행하는 단일 스텝 의사결정 구조.
- SayCan은 LLM을 “행동 후보 생성 & 가치 평가”에 활용하지만, 별도의 중간 추론(Reasoning)이나 메모리 검색(Retrieval), 학습(Learning) 액션이 없이, 그저 “단발성”으로 스킬을 선택해 실행하는 에이전트임.
- ReAct (Yao et al., 2022b):
- 도메인: 텍스트 기반 디지털 환경(예: Wikipedia API, 웹 탐색, 텍스트 게임 등)
- 메모리:
- 장기 메모리 없음. Retrieval·Learning 액션 불가능
- 액션:
- 내부 액션: Reasoning (1회)
- 외부 액션: Grounding (환경 호출)
- “Reasoning → Grounding”의 2스텝 루프로 동작.
- 의사결정:
- 각 사이클에서, LLM으로 한 번 Reasoning을 수행(“무슨 행동을 할지 생각”), 그 뒤 바로 Grounding 액션(실행).
- Action candidate를 여러 개 제안·평가하는 Evaluation/Selection 단계는 없음.
- 무조건 Reasoning 이후에 외부 액션을 해야함.
- Reasoning + Acting을 교대로 수행한다는 점이 특징이며, ReAct는 “내부추론과 외부행동을 결합해 시너지 효과를 낸” 초창기 언어 에이전트임.
- 다만 저장할 장기 메모리가 없기 때문에, 매번 새로운 사이클이 시작될 때 과거 정보를 전부 ‘프롬프트’로 실어줘야 하는 방식이다.
- Voyager (Wang et al., 2023a):
- 도메인: 마인크래프트(Minecraft) 환경
- 메모리:
- 절차 기억: 코드 형태의 “스킬 라이브러리” (e.g., “combatZombie”, “craftStoneSword”)
- 스킬이 계층적 구조를 가짐(복잡한 스킬이 더 단순한 스킬을 호출)
- 또, 새 스킬을 학습·추가하는 ‘학습(learning)’ 기능도 존재
- 액션:
- Grounding (스킬 실행, 게임 내 행동), Reasoning, Retrieval(스킬 라이브러리에서 관련 스킬 가져오기), Learning(새 스킬 추가)
- 즉, CoALA에서 제시한 4가지 액션을 모두 구현
- 의사결정:
- “현재 목표가 없으면” Reasoning으로 새 목표(Task)를 제안
- 해당 목표를 해결하기 위한 스킬(grounding 절차)을 선택해 실행
- 실행 후 결과를 보고(환경 피드백) 성공이면 Learning 액션으로 스킬 라이브러리에 영구 저장, 실패면 Reasoning을 통해 스킬을 수정
- ReAct나 AutoGPT 등 비교 대상보다 마인크래프트 환경에서 효율적으로 탐험 & 작업을 수행
- “장기 기억(스킬 라이브러리) + 학습 액션”의 중요성을 실증.
- Generative Agents (Park et al., 2023):
- 도메인: 샌드박스 게임 내 사회적 시뮬레이션, 에이전트들이 환경·서로와 상호작용
- 메모리:
- 에피소드 기억: 발생한 이벤트들을 리스트로 저장
- 서술 기억: 반복적 Reflection(회고) 과정을 통해 에피소드 기억에서 추상화된 “개인적 성향·태도·결론” 등 저장
- 액션:
- Grounding (게임 환경/다른 에이전트와 상호작용), Reasoning, Retrieval(과거 이벤트·서술 지식 참조), Learning(새로운 기억 저장)
- CoALA 액션 4종 모두 가짐
- 의사결정:
- a) Semantic memory에서 “현재 상황과 관련된 Reflection(요약·교훈)”을 Retrieval
- b) Reasoning으로 “오늘 어떤 일을 할지” 등의 고수준 계획을 세움
- c) 계획을 실행하면서, 외부 관찰(grounding observation)이 들어오면 다시 Reasoning으로 계획을 유지·수정
- d) 중간·최종 결과는 Episodic/Semantic memory에 저장(학습)
- 이 과정을 통해, 인간처럼 장기 기억을 쌓고 사회적 행동을 “이전 사건 및 성격적 성향” 기반으로 합리적으로 결정하는 에이전트를 구현함.
- Tree of Thoughts (ToT) (Yao et al., 2023):
- 도메인: 추론 문제(24게임, 퍼즐, 크리에이티브 라이팅 등)
- 메모리: 없음(장기 메모리X)
- 액션:
- 외부 액션: 최종 해답을 제출하는 것 1개만
- 내부 액션: Reasoning (체계적인 탐색·백트래킹 구현)
- 의사결정:
- “트리 탐색 알고리즘”을 LLM 기반으로 수행(BFS, DFS, MCTS 등)
- 즉 여러 단계에 걸쳐 생각을 제안 -> 평가 -> 선택하며 최적의 해답을 찾은 후 최종 한 액션을 실행.
- ToT는 내부 추론을 매우 치밀하게 계획(여러 후보 가지를 동시에 탐색)한다는 점이 특징.
- 다만 장기 메모리가 없어서, 여러 에이전트 사례 중에는 가장 미니멀하게 “Reasoning”에만 집중하는 구조.
실전적 통찰(Actionable Insights):
- LLM Agent 를 어떻게 관리할 수 있을지에 대한 내용임.
- 관점은 다음과 같이 있다:
- 모듈화된 에이전트: 단일 ‘거대 모델’이 아니라 구조화·표준화:
- 범용 소프트웨어가 표준을 제공하듯, 언어 에이전트도 CoALA 같은 개념적 프레임워크와 함께 모듈별로 제공해야하고 표준화가 되어야한다.
- 절차 기억(Procedural Memory) 에서는 어떻게 행동(Action) 을 할 지 구현을 해야함. 이 구현은 크게 LLM 이 하기에 적합한 것과, 코드(명확하고 안정적인 출력을 기대할 수 있는 것)가 할 수 있는 것으로 나눠야한다고 함.
- LLM 은 추론을 하는 부분을 말하고, 코드는 명시적인 API 호출, 알고리즘 적용, 사용자 정책 적용 등
- 에이전트 설계: 단순 Reasoning 만으로는 부족하다:
- CoALA에서는 에이전트를 다음 세 가지 요소로 필요로 하며, 현실 상황과 목적에 맞게 구체화가 잘 되야함:
- 메모리(working, episodic, semantic, procedural):
- 어떤 정보를 어디에다가 저장할 것인가? 예: 개인화된 쇼핑 도우미 에이전트
- 서술 기억: 판매 물품(카탈로그) 정보를 저장
- 에피소드 기억: 특정 고객의 구매 이력, 상호작용 이력 보관
- 절차 기억: 검색 기능을 어떻게 호출할지, 대화 스킬 등을 코드로 정의
- 그리고 이들 사이를 연결해주는 작업 기억
- 어떤 정보를 어디에다가 저장할 것인가? 예: 개인화된 쇼핑 도우미 에이전트
- 내부 액션·외부 액션(reasoning, retrieval, learning, grounding):
- 에이전트가 서술 기억, 에피소드 기억을 읽고 쓸 수 있는 권한은 어떻게?
- 의사결정(Decision-making) 절차:
- 어떤 순서로 Reasoning, Retrieval, Learning 등을 수행하며, 언제 Grounding(실제 사용자에게 검색 결과를 제시 등) 액션을 할지.
- 복잡한 문제일수록 Voyager(Wang et al., 2023a)처럼 정교한 계획을 세우는 구조를 도입할 수 있고, 단순하게 ReAct(Yao et al., 2022b) 식으로 “Reasoning 한 번 → Action 실행” 루프만 써도 되지만, 일반성이 떨어질 수 있음.
- 메모리(working, episodic, semantic, procedural):
- CoALA에서는 에이전트를 다음 세 가지 요소로 필요로 하며, 현실 상황과 목적에 맞게 구체화가 잘 되야함:
- Structured Reasoning: Prompt Engineering을 넘어서
- LLM 기반 추론을 더 구조화하고 체계적으로 관리하자는 이야기를 함.
- a) LLM 호출 간의 데이터를 명시적으로 관리하기 위해 작업 기억(working memory) 와의 상호 작용을 쉽게 할 수 있도록 LangChain 과 같은 프레임워크와 OpenAI Function calling 같은 기능을 적극적으로 이용하자.
- b) Reasoning Usecases를 통해 LLM 개선해보자. 기존 LLM은 일반 NLP 태스크(번역, 생성 등)에 맞춰 훈련되었으므로, 에이전트 환경에서 자주 사용되는 추론 형태인 자기 평가(Self-Evaluation), Reflection, Action Generation 와 같은 새로운 추론도 추가적인 훈련이 되면 더 좋다.
- Long-term Memory: Retrieval Augmentation을 넘어서:
- 기존의 Retrieval-Augmented Language Models (RAG(Guu et al., 2020) 와 같은 방식은 LLM 이 필요한 정보를 읽어서 쓰는 방식이었음. 지금은 에이전트가 스스로 생성한 콘텐츠(추론 결과, 회고, 행동 로그 등)를 장기 메모리에 쓰기까지 하고, 적절한 정보를 불러오는게 필요함. 결론적으로 에이전트는 자가학습(self-generated) 을 통한 “평생 학습(lifelong learning)” 구현이 되어야함.
- 예: 서술 기억(semantic memory)에 인간이 만든 메뉴얼/텍스트북에다가 에이전트가 직접 만든 지식을 결합해 지속적으로 확장
- 예: 에피소드 기억(episodic memory)에 과거 시도·결과를 기록해두고, Reflection 과정을 통해 새롭고 추상화된 지식(semantic)을 생성, 이후 파인튜닝까지도 고려
- 예: 절차 기억(procedural memory)에 “코드 라이브러리” 형태로 새 메서드나 스킬을 추가하며 점진적으로 능력을 확장.
- Retrieval과 Reasoning의 결합:
- 에이전트가 계획(Planning)할 때, 기억을 “단순 검색”만 하는 게 아니라 추론 과정과 번갈아가며(interleaving) 참조한다면 더 맥락적이고 정확한 의사결정을 할 수 있을 것으로 기대됨
- 여기에는 다음과 같은 것들이 있을 거임:
- 무엇을 검색해야 할지 결정하는 추론:
- 검색 전에, 현재 상황에 적합한 정보를 판단하기 위해 추론이 필요.
- 예: “현재 상황에서 어떤 과거 경험이 가장 관련이 있을까?” 또는 “이 문제를 해결하려면 어떤 유형의 지식이 필요할까?”
- 이를 통해 검색 쿼리를 생성하거나 검색 방향을 결정할 것.
- 검색된 정보를 해석·결합하는 추론:
- 검색된 결과는 보통 원시 데이터(raw data)나 단편적인 정보일 수 있음. 이를 맥락적으로 해석하고 현재 상호아에 맞게 재구성하기 위해 추가 추론이 필요할 수 있음.
- 검색 쿼리 생성 → 검색 → 검색 결과로 추론 업데이트:
- 검색된 정보를 바탕으로 추론을 보강
- 추론 결과를 바탕으로 검색 반복:
- 첫 번째 검색 결과가 부족하거나 부정확하면, 추론을 통해 새로운 검색 방향을 제안.
- 무엇을 검색해야 할지 결정하는 추론:
- 기존의 Retrieval-Augmented Language Models (RAG(Guu et al., 2020) 와 같은 방식은 LLM 이 필요한 정보를 읽어서 쓰는 방식이었음. 지금은 에이전트가 스스로 생성한 콘텐츠(추론 결과, 회고, 행동 로그 등)를 장기 메모리에 쓰기까지 하고, 적절한 정보를 불러오는게 필요함. 결론적으로 에이전트는 자가학습(self-generated) 을 통한 “평생 학습(lifelong learning)” 구현이 되어야함.
- Learning: In-Context Learning과 Fine-tuning을 넘어서
- CoALA에서 정의하는 학습(Learning)은 단순히 LLM의 In-Context Learning 과 Fine-tuning 에 국한되지 않음. 여기에는 경험과 지식을 저장하고, 에이전트의 코드(프로시저)를 직접 수정하는 것까지 포함됨.
- 여기에는 다음과 같은 것들이 있음:
- 에이전트 코드 수정(Meta-learning):
- 에이전트가 자신의 코드를 학습적으로 수정함으로써, 새로운 방식으로 메타 학습을 함.
- 예: 검색 알고리즘 개선: 더 효율적인 검색 쿼리를 생성하거나, 새로운 검색 메서드를 학습해 추가
- 예: 새 스킬 추가: 환경과의 상호작용에서 새로운 행동(grounding action)을 발견하고 이를 코드로 저장.
- Meta-learning 은 "어떻게 학습할지에 대한 학습" 으로 어떤 조건에서 특정 메모리나 절차를 사용할지에 대한 메타 데이터를 에이전트 스스로 생성하는 것.
- 에이전트 코드 수정(Meta-learning):
- Action Space: 외부 도구와 행동을 넘어서:
- 주요 논점으로는 다음과 같은 것들이 있음:
- 행동 공간 크기와 복잡성의 트레이드오프:
- 더 유능한 에이전트(예: Voyager, Generative Agents)는 더 많은 액션을 수행할 수 있지만, 행동 공간(action space)이 커질수록 의사결정(Decision-making)이 더 복잡해짐.
- 많은 액션을 고려하면 탐색·평가·선택 과정에서 리소스가 많이 소모됨.
- 특정 작업을 해결하는 데 필요한 최소한의 행동 공간만 정의해 간결한 설계를 제안함.
- 행동 공간의 안전성(Safety):
- 일부 액션은 내재적으로 위험할 수 있음.
- 내부 액션: 학습 액션(특히 절차 삭제·수정)이 잘못된 코드를 생성하면 에이전트 자체가 손상될 수 있음.
- 외부 액션: 위험한 행동(e.g., 로봇이 칼을 들거나, Bash 터미널에서 rm 명령어 실행) or 부적절한 발언 생성
- 일부 액션은 내재적으로 위험할 수 있음.
- 행동 공간 크기와 복잡성의 트레이드오프:
- 주요 논점으로는 다음과 같은 것들이 있음:
- 의사결정을 Propose-Evaluate-Select(제안-평가-선택) 구조로 바라보자:
- 기존에 대부분의 언어 에이전트는 단일 액션 생성에 중점을 뒀음. 즉, 에이전트는 LLM을 호출해 바로 하나의 액션을 생성하거나, 간단히 평가 후 실행하는 방식. CoALA는 이를 넘어서 의사결정을 더 정교하고 체계적으로 다루는 방향으로 발전시키기를 제안.
- 모듈화된 에이전트: 단일 ‘거대 모델’이 아니라 구조화·표준화:
'Generative AI > Agent' 카테고리의 다른 글
| Generative Agents: Interactive Simulacra of Human Behavior (0) | 2024.12.27 |
|---|---|
| Summary of LLM Agent Framework (0) | 2024.12.23 |
| LLM Agent Course - (2) LLM agents (0) | 2024.12.22 |
| Premise Order Matters in Reasoning with Large Language Models (0) | 2024.12.21 |
| LLM Agent Course - (1) Reasoning (0) | 2024.11.18 |