모든 기술이 그렇듯이 내부 구조를 알아두면 트러블슈팅과 디버깅에 도움이 된다.
여기서는 카프카를 이용하는 개발자가 알아둘만한 내부 매커니즘에 대해서 다룬다.
1. 클러스터 멤버쉽
브로커 멤버 관리를 위한 주키퍼 사용:
- 카프카는 현재 클러스터 브로커 멤버 관리를 위해 아파치 주키퍼를 사용한다.
- 브로커 식별자는 주키퍼에 등록한다:
- 각 브로커는 고유 식별자를 가진다:
- 자신의 설정 파일에 고유 식별자를 등록하거나 자동으로 생성된 고유 식별자를 통해서
- 브로커는 식별자를 프로세스가 시작할 때 주키퍼에 Ephemeral 노드 형태로 등록한다.
- Ephemeral 노드는 ZooKeeper 가 클라이언트 세션을 관리하는 방법이다.
- Ephemeral 노드를 통해 Kafka 클러스터는 실시간으로 브로커의 상태를 모니터링할 수 있다.
- 각 브로커는 고유 식별자를 가진다:
- 브로커 탈퇴/추가에 대한 알림을 받음:
- 브로커들은 주키퍼의 /brokers/ids 경로를 구독 (Watch) 해서 브로커가 추가되거나 제거될 때 알림을 받을 수 있다.
브로커 식별자를 바탕으로 담당하는 토픽 파티션을 식별한다:
- 브로커 식별자를 바탕으로 어떤 토픽 파티션을 브로커에서 관리하는지 나타내기 때문에 브로커가 죽고나서 새로운 브로커가 같은 Id 를 가지고 들어오게 되면 작업을 이어받아서 처리할 수 있다.
2. 컨트롤러
컨트롤러의 역할:
- 카프카 브로커의 컨트롤러는 일반적인 브로커 기능인 토픽 파티션 메시지를 저장하는 기능 이외에 파티션 리더 선출, 브로커 탈퇴/가입 담당 기능까지 한다.
컨트롤러 선출:
- 컨트롤러가 되는 브로커는 주키퍼에 가장 먼저 등록한 브로커이다:
- 클러스터에서 가장 먼저 시작한 브로커는 주키퍼에 /controller 라는 고정적인 위치에 Ephemeral 노드를 생성함으로써 컨트롤러가 된다. 뒤늦게 시작하는 브로커들도 여기에 Ephemeral 노드를 생성하려고 시도하지만 이미 생성된 노드가 있다는 예외를 받게 되고 컨트롤러가 존재함을 알게된다.
- /controller 에 생성한 Ephemeral 노드가 곧 컨트롤러임을 약속한 것이다.
다음은 컨트롤러가 응답이 없거나 크래시가 나서 새로운 컨트롤러가 선출되는 과정이다:
- 죽은 컨트롤러 판별:
- 컨트롤러 브로커가 주키퍼에
zookeeper.session.timeout.ms동안 하트비트를 보내지 않는다면 연결이 끊어진 것으로 판단해서 새로운 컨트롤러를 선출한다.
- 컨트롤러 브로커가 주키퍼에
- 새로운 컨트롤러 선출 과정:
-
- 주키퍼는 연결이 끊어진 컨트롤러 노드에 대한 정보를 삭제한다. 즉 /controller 경로에 생성된 Ephemeral 노드를 삭제시킨다.
- 컨트롤러가 아닌 브로커들은 /controller 경로에 와치를 설정해서 이런 삭제에 대한 알람을 받을 수 있게 된다.
- 알람을 받은 후 브로커들은 /controller 에 새로운 Ephemeral 노드를 생성하려고 시도한다. 가장 먼저 성공한 브로커가 컨트롤러가 되며, 뒤늦게 시도한 브로커는 이미 생성된 컨트롤러가 있으므로 실패한다.
- 새롭게 컨트롤러가 된 브로커는 증가한 Epoch 넘버를 부여받는다. 이를 통해서 기존에 죽은 줄 알았던 이전 컨트롤러의 활동을 막는다. 즉 Epoch 넘버를 통해 좀비 어플리케이션 문제인 Split Brain 문제를 예방할 수 있다. 컨트롤러가 던지는 모든 메시지는 Epoch 넘버가 부여되는데 이전 Epoch 넘버의 명령은 무시하면 되니까.
-
브로커가 클러스터를 나갔을 때, 컨트롤러에 의해 새로운 토픽 파티션 리더가 선출되는 과정:
- 컨트롤러는 브로커가 탈퇴했다는 정보를 듣는다:
- 브로커는 주키퍼에 자신을 등록시키는데 다른 브로커들은 여기에 Watch 를 설정해둬서 탈퇴에 대한 알림을 받을 수 있다.
- 나가는 브로커로부터 직접적으로 CotnrolledShutdownRequest 요청을 받아서 탈퇴헀음을 알 수 있다.
- 나간 브로커가 담당하고 있던 리더 토픽 파티션들을 다른 브로커가 관리하도록 만들기 위해서 In-Sync 파티션들을 순회하면서 리더 파티션들을 선정한다.
- 컨트롤러는 나간 브로커가 담당하고 있던 토픽 파티션 정보와 남아있는 브로커가 관리하고 있는 토픽 파티션에 대한 정보를 모두 알고있다. 컨트롤러로 선정되었을 때 이 정보를 주키퍼로부터 가지고 오기 떄문에 안다.
- 컨트롤러는 토픽 파티션의 리더가 될 브로커 정보를 새롭게 갱신해서 주키퍼에 쓴 이후, 갱신된 파티션의 리더와 팔로워 정보를 포함한 요청을 모든 브로커에게 보낸다. 이 요청은 LeaderAndISR (Leader and In-Sync Replicas) 이라고 하며, 배치 형태로 하나의 요청에 브로커가 관리해야 할 여러 토픽 파티션에 대한 정보가 모두 들어있다.
- In-Sync Replica 는 리더가 될 수 있는 후보군의 팔로워 파티션을 말한다. 최근까지 리더의 메시지를 복제한 녀석들만 In-Sync Replica 이고, 리더 파티션과 연결이 끊겨서 메시지가 뒤쳐져 있는 녀석들은 Out-Sync Replica 이다.
- 컨트롤러는 모든 브로커가 가지고 있는 브로커들의 정보와 레플리카 맵에 대한 정보를 새롭게 갱신하도록 UpdateMetadata 요청을 보낸다.
- 레플리카 맵은 토픽 파티션의 팔로워/리더 정보가 어느 브로커에 있는지를 나타내는 정보다.
- 이렇게 새롭게 토픽 파티션의 리더를 가지게 된 브로커들은 이제 다시 프로듀서와 컨슈머로부터 읽기/쓰기 요청을 처리할 수 있게 된다. 그리고 팔로워 파티션들은 새 리더로부터 메시지를 복제하게 된다.
3. KRaft: 주키퍼 없는 새로운 Raft 기반의 컨트롤러
Kafka 3.3 버전부터는 이제 주키퍼 없이 컨트롤러를 구성할 수 있게 된다.
Kafka 가 Zookeeper 를 없앤 이유:
- 컨트롤러가 주키퍼에 쓰는 요청은 동기식이나, 컨트롤러가 브로커에 쓰는 요청은 비동기식이다. 그리고 주키퍼에게 업데이트를 받는 것 역시 비동기식이다. 이렇기 때문에 요청의 처리 순서가 꼬여서 메타 데이터가 일치하지 않는 문제가 발생할 수 있다.
- 컨트롤러가 새로 선출될 때 주키퍼로부터 모든 브로커와 파티션 담당에 대한 정보를 받아오고 이를 갱신하는 정보를 모든 브로커에게 보내야하는데 이 지점이 병목이다. 이걸 개선하려는 목적도 있음.
- 주키퍼라는 새로운 분산 시스템을 알아야하는 것도 문제라고 판단함.
기존에 주키퍼가 하고 있던 역할:
- 클러스터 메타데이터 관리 (= 브로커 멤버 관리, 토픽 파티션 정보 관리, 토픽 파티션 레플리카 관리)
- 컨트롤러 선출
Raft 기반의 변경된 방식:
- 모든 메타데이터 변경 내역들은 컨트롤러에서도 가지고 있지만 다른 브로커들도 이를 가지고 있다. 주기적으로 변경 내역을 컨틀롤러에서 가지고 오는 방식이다. 만약 이걸 가지고 오지 않는다면 Fenced State 가 되서 클라이언트의 쓰기 요청을 수행할 수 없게 된다.
- 이렇게 모든 브로커가 메타 데이터 변경 내역을 가지고 있기 때문에 컨트롤러가 죽어도 새로운 컨트롤러가 선출되고 복구되는 과정이 굉장히 빨라진다.
- 브로커가 컨트롤러의 정보를 가지고 오는 API 를 MetadataFetch API 라고 하며 가지고 오는 방식은 Pull 방식이다.
- 주키퍼를 사용했던 때에는 주키퍼에 자신 브로커에 대한 정보를 등록했다면 Raft 기반에서는 컨트롤러 쿼럼에 등록한다. 브로커가 종료되도 삭제되진 않고 offline 상태로 돌아갈 뿐이다. 메타 데이터에 대한 최신 정보를 가지게 된다면 online 상태로 돌아가게 된다.
4. 복제
카프카는 복제를 통해서 데이터의 신뢰성과 지속성을 보장할 수 있다. 하나의 리더 파티션에 저장된 데이터는 여러 팔로워 파티션에 복사되는 식으로 말이다.
리더 파티션의 역할:
- 프로듀서가 보낸 메시지를 파티션에 저장하고, 컨슈머의 읽기 요청에 메시지를 전달해준다.
- 프로듀서가 보낸 메시지는
min.insync.replica설정 값만큼 최신 상태가 복제가 되어야지 컨슈머에서 읽어갈 수 있다.
- 프로듀서가 보낸 메시지는
- 팔로워 파티션이 최신 상태까지 복제했는지를 파악한다.
- 팔로워 파티션은 컨슈머처럼 주기적으로 리더 파티션으로부터 메시지를 읽어가서 동기화를 한다. 이렇게 읽어가는 요청을 바탕으로 리더 파티션은 팔로워 파티션이 어디까지 동기화 했는지를 파악한다.
- 만약 일정시간동안 (=
replica.lag.time.max.ms) 데이터를 가지고 가지 않는다면 팔로워 파티션을 Out-Sync 파티션으로 판단해서 리더가 될 수 없도록 한다.
선호 리더의 중요성:
- 여러 In-Sync 팔로워 파티션들 중에서 리더가 될 유력한 후보인 선호 리더라는 것이 있다. 이는 브로커가 첫 토픽 파티션을 만들 때 결정한 리더 파티션을 말한다. 첫 리더 파티션도 브로커의 장애로 리더가 변경되었을 수 있는데 언제든지 다시 리더로 돌아갈 수 있도록 선호 리더로 정해둔다.
- 이런 선호 리더가 있는 이유는 파티션들을 첫 설계할 때 브로커의 부하를 균등하게 제공하려고 리더 파티션을 정했을 것이기 때문이다. 리더가 변경된 상태라면 부하의 균형이 균등하지 않을 것이라서 이를 다시 균등하게 만들기 위해 선호 리더가 있는 것임.
- 카프카에서는
auto.leader.rebalance.enable=true설정으로 선호 리더를 가지는 설정을 활성화한다. - 선호 리더를 찾는 방법은
kafak-topic.sh의 출력되는 파티션 레플리카 정보를 보면 된다. 목록에 표시된 첫 레플리카가 선호 리더다.
5. 요청 처리
카프카 클라이언트들은 브로커와 통신할 때 자체적으로 구현한 TCP 레벨의 이진 프토토콜을 사용한다.
- 프로토콜에 대한 상세한 내용은 이 링크를 참고하자.
카프카 브로커로의 모든 요청은 공통된 표준 헤더를 가진다:
- 요청 유형: 어떤 유형의 요청인지 판단하기 위해서 사용된다.:
- Produce Request: 클라이언트가 브로커에게 데이터를 쓰기 위해 보내는 요청.
- Fetch Request: 클라이언트가 브로커로부터 데이터를 읽기 위해 보내는 요청.
- OffsetCommit Request: 컨슈머가 특정 토픽의 오프셋을 커밋하기 위해 보내는 요청.
- Metadata Request: 클라이언트가 클러스터의 메타데이터(예: 토픽의 리더 정보, 브로커 목록 등
- 요청 버전: 클라이언트의 버전 별로 호환성있게 리턴하기 위해서 필요하다.
- Correlation ID: 요청의 고유성을 식별하기 위해서 사용된다.
- 클라이언트 ID: 요청을 보낸 어플리케이션을 식별하기 위해서 사용된다.
브로커의 요청 처리 개요:
-
- 연결 요청이 오면 이를 Acceptor Thread 가 수신하고 이를 Processor Thread 에게 넘긴다. Acceptor Thread 는 연결만 수신하고 응답은 Processor Thread 가 전달하는 구조임.
- Processor Thread 는 요청을 요청 큐에다가 넣는다. 그러면 I/O 스레드에서 이를 꺼내서 처리할 것이다.
- Processor Thread 는 응답 큐에서 응답을 꺼내서 클라이언트에게 반환한다. (기본적으로 비동기 처리임)
- 때로는 응답을 보낼 때 지연을 시켜야하는 경우가 있다. (컨슈머의 경우 최소 바이트만큼은 모여야 데이터를 줄 수 있으니까.) 이 경우에는 Purgatory 에 저장해놓고 조건이 만족되면 응답한다.
요청은 크게 3가지 종류로 분류할 수 있다:
- 쓰기 요청: 프로듀서가 보낸 것
- 읽기 요청: 컨슈머가 보낸 것
- 어드민 요청: Admin Client 가 메타데이터 작업을 위해 보낸 것.
카프카 클라이언트는 어떻게 리더 파티션을 가진 브로커를 알고 보내는 것인가?
- 카프카 클라이언트가 리더 파티션을 가지고 있지 않은 브로커에게 메시지를 보낸다면 'Not a Leader for Partition' 이라는 에러를 받는다. 즉 올바른 브로커에게 보낼 책임은 카프카 클라이언트에게 있는 셈이다.
- 카프카 클라이언트는 브로커들이 어떤 리더 토픽 파티션을 가지고 있는지에 대한 메타정보를 요청해서 얻고 이를 바탕으로 올바른 브로커에게 요청을 전달한다.
- 이 정보를 얻기 위해서 어떤 브로커에게 요청해도 괜찮다. 모든 브로커가 이 메타 정보를 가지고 있으니
- 이 정보를 카프카 클라이언트는 캐싱해서 가지고 있는데 시간이 지나고 상황이 바뀌면 유효하지 않은 데이터가 될 것이므로 주기적으로 갱신을 한다. 이 주기는
metadata.max.age.ms이다. 그리고 'Not a Leader for Partition' 와 같은 예외를 받아도 수동으로 갱신을 한다.
5.1 프로듀서의 쓰기 요청은 어떻게 처리되는가?
브로커의 쓰기 요청 처리 과정은 다음과 같다:
-
- 유효성 검사를 한다:
- 사용자가 토픽 쓰기에 올바른 권한을 가지고 있는가?
- acks 설정 값이 올바른가? (0, 1, all 만 올 수 있음)
- 만약 acks 설정이 all 이면 In-Sync 레플리카의 수는 현재 최소 개수를 만족하는가?
- acks 설정에 따라 처리가 약간씩 달라진다:
- acks 설정은 다음과 같다:
acks=0: 프로듀서는 메시지를 보내고 브로커의 응답을 기다리지 않음.acks=1: 리더 파티션에서만 써지고 응답을 받음acks=all: 리더 파티션 뿐 아니라 모든 In-Sync 레플리카에서도 써지고 응답을 받음.
- acks 가 0과 1이라면 자신만 준비되면 바로 응답을 내보낼 수 있지만, all 이라면 다른 레플리카에 써져야 하므로 Purgatory 에 쓴 후 응답을 내보낼 조건이 되면 그제서야 보낸다.
5.2 컨슈머의 읽기 요청은 어떻게 처리되는가?
읽기 요청시 컨슈머가 브로커에 보내는 정보들:
- 읽어야 하는 파티션 목록
- 오프셋
- 메타데이터:
- 가지고 올 수 있는 최소 데이터 양
- 가지고 올 수 있는 최대 데이터 양
- 데이터를 가지고 오는 주기. (최소 데이터 양이 충족되지 않았더라도, 이 주기가 돌아오면 데이터를 가지고 옴)
브로커의 읽기 요청 처리 과정은 다음과 같다:
-
- 요청이 유효한지 판단한다:
- 지정된 오프셋이 유효한지 판단한다. 만약 오프셋이 삭제되었거나 유효하지 않은 오프셋을 전달했다면 에러를 던진다.
- 오프셋이 유효하다면 지정된 오프셋만큼의 데이터를 보낸다. 이때 Zero Copy 가 사용된다:
- Zero Copy 는 리눅스 시스템 콜이며, Page Cache 에 있는 데이터를 Network Buffer 로 한번에 데이터를 복사하기 위해서 사용되는 방식이다. 이 방식을 사용하지 않으면 여러번의 Byte Copy 가 발생한다.
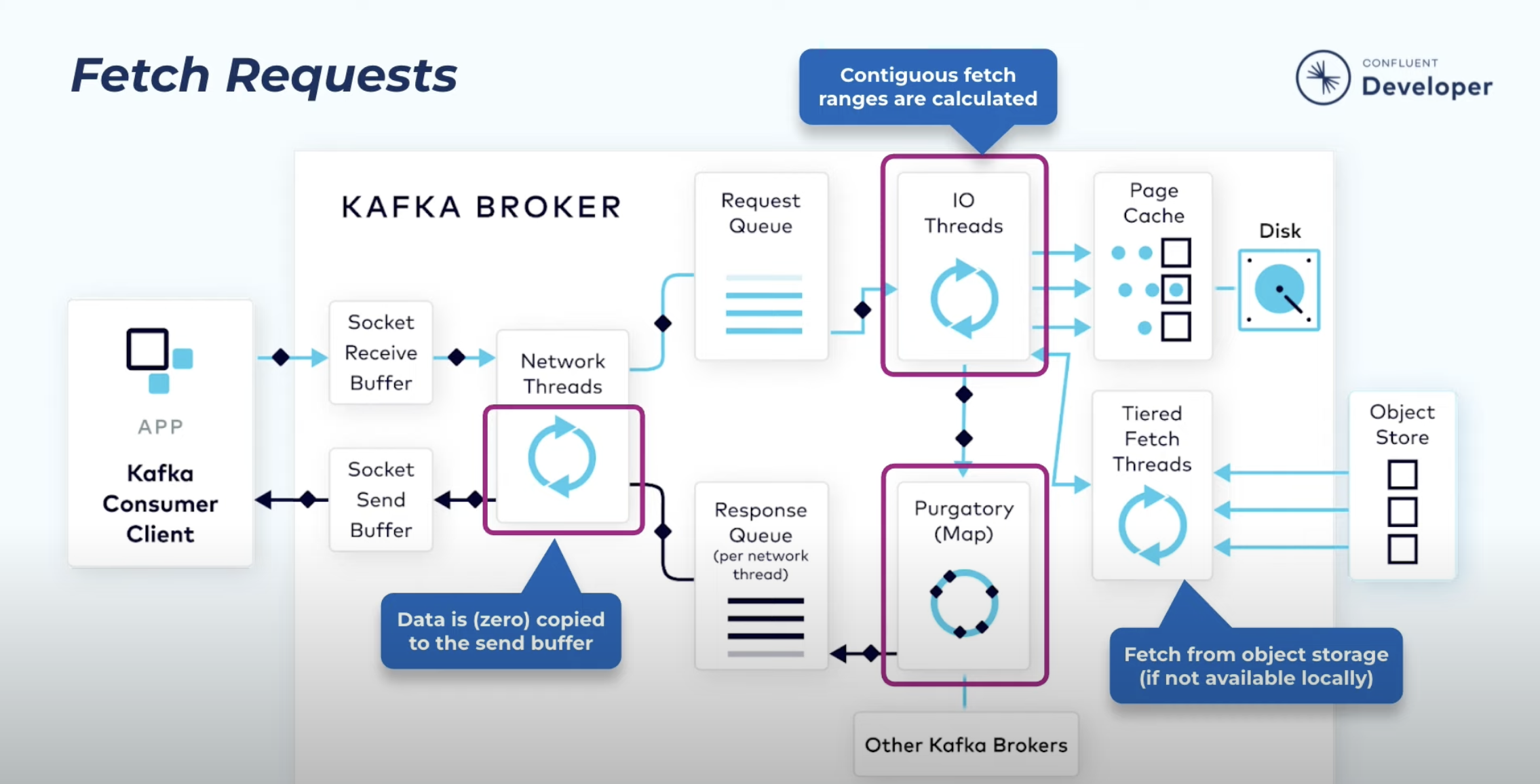
컨슈머가 읽어오는 요청은 In-Sync 레플리카까지 모두 복제된 데이터라는 걸 알아야한다:
- 리더 파티션에서만 쓰인 데이터는 읽어오지 않는다. 이는 유실될 확률이 있는 것이므로.
- 만약 리더 파티션에서 In-Sync 레플리카로의 복제가 지연된다면 이로 인해서 컨슈머도 읽어오는 주기가 길어질 수 있다. 이 주기는
replica.lag.time.max.ms값에 비례할 것이다.replica.lag.time.max.ms값동안 In-Sync 레플리카가 복제를 하지 않는다면 Out-Sync 레플리카가 되고 새로운 In-Sync 레플리카가 복제를 수행할 것.
Fetch Session 을 통한 읽기 요청의 중복 메타 데이터 전송을 최소화:
- 카프카 컨슈머에서 매번 읽기 요청할 때마다 읽어야하는 파티션 목록과 오프셋과 같은 메타데이터 정보를 보내는 건 오버헤드가 있으니 이를 세션을 유지함으로써 중복 데이터 전달을 최소화 한다. 변경 사항이 있는 경우에만 메타 데이터를 추가해서 보내면 된다.
- 브로커에선 상황에 따라 이런 세션을 강제로 종료할 수 있는데, 이 경우에는 Kafka Consumer Client 가 내부적으로 알아서 그때는 필요한 메타데이터 정보를 보내니 걱정하지 않아도 된다.
6. 저장소
6.1 계층화된 저장소
카프카 3.0 부터는 계층화된 저장소 (Tiered Storage) 기능이 탑재될 예정이다.
계층화된 저장소가 나온 이유는 다음과 같다:
- 모든 데이터를 로컬에 저장하는 것은 한계가 있으며, 데이터는 각자의 특성이 있다. 처리량과 지연시간이 중요하거나, 보존 기간이 중요하거나.
- 계층화된 저장소는 HDFS 나 S3 와 같은 원격 저장소에 저장되서 영구적으로 보관할 수 있다. 이렇게 하면 브로커가 관리하는 데이터의 수가 줄어서 클러스터 확장/축소가 더 쉽다.
계층화된 저장소의 등장으로 인한 성능 변화:
- 외부 저장소로 로그 세그먼트를 보내게 되면서 부하가 심한 상황에서는 성능이 감소됨:
- p99 값이 (AS-iS) 21밀리초에서 (TO-BE) 25밀리초로 성능 감소
- 컨슈머에서 오래된 데이터를 읽는 경우에는 성능이 향상됨:
- p99 값이 (AS-IS) 60밀리초에서 (TO-BE) 42밀리초로 향상
- 외부 저장소에서 읽는 데이터니 페이지 캐시 경합이 없어서.
6.2 파티션 할당 과정
토픽을 만들게 되면 카프카는 다음 기준에 따라서 파티션을 브로커에 할당한다:
- 리더 파티션과 팔로워 파티션을 각 브로커에 균등하게 배분한다:
- 배분은 기본적으로 라운드 로빈을 사용한다. 리더 파티션 1,2,3 이 있고 브로커가 1,2,3 이 있다면 각각 할당하게 된다.
- 리더 파티션을 할당한 이후 팔로워 파티션을 할당하는데 팔로워 파티션의 시작 지점은 리더 파티션이 할당된 브로커 다음 번호부터 할당한다고 알면 된다.
- 팔로워 파티션은 리더 파티션과는 서로 다른 브로커에 배분하려고 한다.
- 브로커에 렉 정보가 있다면 이에 기반해서 파티션을 균등하게 배분하려고 한다:
- 렉은 가용 영역이라고 보면 되는데 서로 같은 렉에 파티션이 있다면 하나의 렉만 크래쉬가 나더라도 장애의 영향이 더 크니까 가용성을 위해 렉에 파티션을 분산시는 것이 좋다.
- 예시로 렉 A 에 브로커 0과 1이 있고, 렉 B 에 브로커 2와 3이 있다면 브로커 0, 2, 1, 3 순으로 파티션이 할당될 것이다.
파티션이 할당된 후 이제 파티션이 저장될 디렉토리를 결정해야하는데 이는 가장 적은 파티션을 소유한 디렉토리를 선택한다.
6.3 파일 관리
카프카의 데이터 파일은 하나의 거대한 로그 파일 대신에 로그 세그먼트 단위로 관리된다:
- 로그 세그먼트의 크기는
log.segment.bytes에 의해서 결정된다. 기본값은 1GB 이다.
카프카의 데이터 파일 삭제 정책은 로그 세그먼트가 닫힌 후에 로그 파일 크기로 하느냐, 시간으로 하느냐로 설정할 수 있다:
- 크기로 설정할 경우
log.retention.bytes로 정할 수 있다. 이 설정은 파티션 단위로 설정되며, 로그 파일이 이 크기에 도달하면 삭제된다. 기본적으로는 비활성화 되어있다. - 시간 단위로 설정할 경우
log.retention.ms로 설정할 수 있다. 기본값은 ms 단위가 아니라 hour 을 이용하며,log.retention.hours값으로 설정되어 있고 일주일이다.
6.4 파일 형식
카프카 프로듀서가 보낸 레코드의 메시지 형식과 컨슈머가 컨슘하는 메시지의 형식은 동일하다:
- 이를 통해 Zero Copy 를 최적화 할 수 있으며 프로듀서가 보낸 메시지를 압축 해제하고 다른 형식으로 저장하는 오버헤드가 없게 되서 성능을 높일 수 있다.
카프카의 메시지는 사용자가 보낸 본문인 Payload 와 메타데이터를 포함하고 있는 시스템 헤더 이렇게 두 부분으로 나뉜다:
- Payload:
- 사용자가 보내고 싶은 데이터를 말한다. (such as: key, value, 사용자 정의 헤더)
- 이 부분은 사용자에 의해 압축될 수 있으며 가능한 압축하는 것이 좋다. 압축하는 것이 네트워크 전송할 때 유리하므로.
- 시스템 헤더:
- 바이트 단위로 표시된 레코드의 크기
- 배치 내에 있는 메시지가 시작되는 오프셋과 현재 메시지의 오프셋 차이. 즉 상대적인 오프셋 차이를 말하며 이 둘을 조합하면 오프셋이 결정된다.
- 현재 레코드의 타임스탬프와 배치 내 첫번째 레코드의 타임스탬프 차이.
카프카 프로듀서는 메시지를 배치 형식으로 전송한다:
- 배치는 파티션 별로 묶이며, 프로듀서가 브로커로 보내는 요청 단위는 여러 배치가 섞여있을 수 있다.
- 배치 단위로 전송하는 이유는 네트워크 전송에 효율적이기 떄문임.
- 이렇게 배치 단위로 보내기 때문에 배치 전송에 약간의 딜레이를 주는
linger.ms=10설정을 잡아두면 성능에 도움이 된다.linger.ms는 기본적으로 셋팅되어 있지 않아서 즉시 데이터를 보내게 된다.linger.ms를 설정해도 프로듀서가 브로커로 보내는 단위인 배치가 가득차면 딜레이없이 보내게 된다.
파티션 단위의 메시지 배치 헤더에는 다음과 같은 정보가 포함되어있다:
- 메시지 형식의 버전을 가리키는 매직 넘버
- 배치에 포함된 첫 번째 메시지의 오프셋과 마지막 오프셋 차이,
- 프로듀서가 보내는 배치를 생성해서 보내는 시점에서는 오프셋은 0으로 되며, 브로커가 저장할 떄 실제 오프셋으로 변환된다고 함.
- 메시지의 타임스탬프
- 배치의 크기
- 해당 배치를 받은 리더의 에포크 값.
- 배치 메시지가 오염되지 않았다는 뜻을 나타내는 체크섬
- 서로 다른 속성을 표현하기 위한 16비트:
- 압축 유형, 타임스탬프 유형, 배차가 트랜잭션의 일부 혹은 컨트롤 배치의 여부 등을 포함함
- 프로듀서 ID, 프로듀서 에포크, 배치의 첫 번째 Sequence Number 등 (= 메시지 전달을 정확히 한 번 보장하기 위해서 사용)
보내는 쪽과 소비하는 쪽의 메시지 형식 버전이 다른 경우에는 변환 과정이 일어날 수 있으므로 변환 과정을 없애도록 클라이언트의 버전을 올려야한다:
- 예시) Prdocuer 와 Broker 는 V2 버전의 메시지 형식을 이용하는데 Consumer 는 V1 버전의 메시지만 읽는 경우에는 메시지를 읽을 떄 V2 에서 V1 으로 변환한다.
- FetchMessageConversionPerSec 나 MessageConversionsTimeMs 지표를 보면 이런 변환 과정이 발생하는지 알 수 있다.
6.5 인덱스
카프카에서는 컨슈머의 특정 오프셋부터의 읽기 요청을 빠르게 하기 위해서 인덱스 파일을 가지고 있다:
- 카프카의 컨슈머는 메시지를 읽기 위한 요청을 보낼 때 읽기 시작을 하고 싶은 오프셋 번호와 한번에 읽을 수 있는 최대 데이터양을 보낸다. 브로커는 이 데이터 양에 맞추서 메시지를 보낼 것이다. 아니면 컨슈머 설정인 max.poll.records 설정 값만큼 보내거나.
- 이 인덱스 파일은 오프셋 번호와 실제 데이터의 파일 내 위치가 매핑되어있다. 이런 인덱스 파일이 없다면 로그 세그먼트 파일을 하나씩 모두 뒤지면서 찾아야할 것이다.
- 이런 인덱스 파일은 로그 세그먼트당 하나씩 유지되어 있을 것이다. 그러므로 오프셋 번호를 받을 경우 어느 인덱스 파일을 열어야 하는지 알아야하며, 이 인덱스 파일에서 오프셋 번호로 어디서부터 파일을 읽으면 되는지에 대한 정보가 들어있을 것이다.
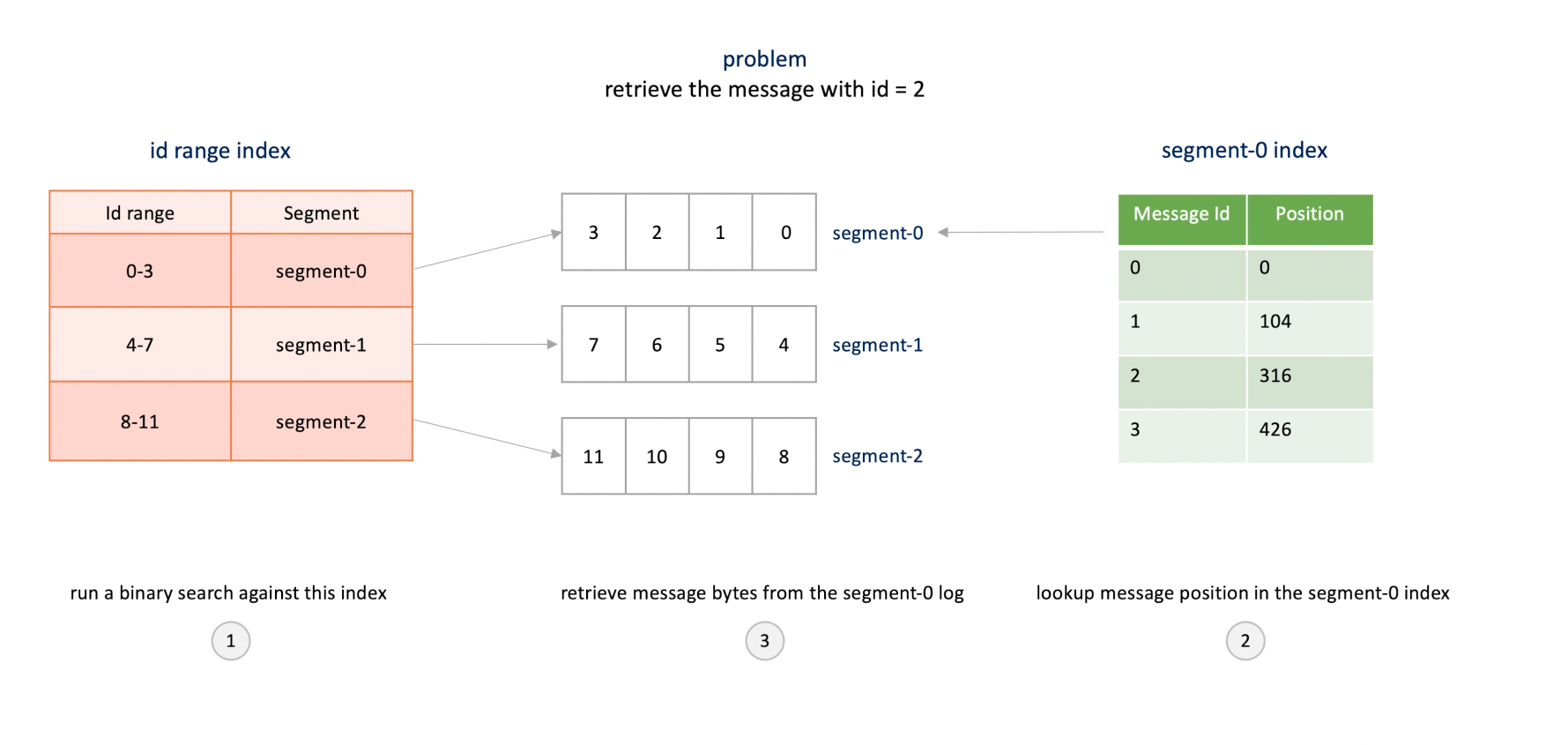
오프셋 번호로 데이터를 빠르게 읽을 수 있을 뿐 아니라 타임스탬프를 기준으로도 데이터를 빠르게 읽을 수도 있다.
- 이는 카프카 스트림즈에서 주로 사용하는 방식이며, 데이터 복구에도 주로 사용한다.
6.6 압착 (Compaction)
토픽 파티션에 쓰여진 메시지를 오랫동안 보관할 필요가 없는 경우나, 마지막 메시지만 보관하면 되는 경우에는 Compaction 기능을 이용해서 파티션의 마지막 데이터만 유지하도록 할 수 있다:
- 이는 카프카를 통해서 어플리케이션의 상태를 만드는 경우에 활용할 수 있다.
- 이런 압착 기능은 토픽 단위로 지정할 수 있으며
cleanup.policy=compact로 지정하면 된다. 기본값은delete이며 이는 일정 시간이 지나거나 로그 파일이 커지면 삭제된다. - 삭제와 압착 둘 다를 쓸 수 있으며 이 경우에는
cleanup.policy=delete,compact이렇게 설정하면 된다. - 파티션에 쓰여진 메시지에서 key 별로 구별되서 압착이 된다. 그러므로 key 는 Null 값을 주지 말자.
압착의 작동원리는 다음과 같다:
- 파티션의 메시지들은 기존 압착이 된 영역인 clean 영역과 새롭게 들어온 데이터 영역인 dirty 영역으로 나눠져있다. clean 과 dirty 영역을 합쳐서 압착을 하는 것이다.
- 카프카의 압착 기능 동작은 먼저 Dirty 영역을 읽어서 인메모리 맵을 만든다. 그리고 가장 오래된 클린 영역의 데이터를 읽으면서 새로운 상태의 압착 상태를 만든다.
- 오래된 데이터를 읽을 떄 인메모리 맵에 없는 데이터는 곧 최신 상태를 나타내므로 새로운 로그 세그먼트에 기록을 하고, 인메모리 맵에 있는 데이터는 인메모리 맵에 있는 데이터가 최신 상태가 될 것이므로 이 데이터는 스킵된다.
- 만약 dirty 영역의 데이터가 많아서 인메모리 맵의 메모리 사이즈를 초과한다면 dirty 영역을 쪼개고 여러 phase 를 나눠서 압착을 한다.
- 카프카의 압착 기능 활성화는
log.cleaner.enabled설정이 활성화 되어 있어야한다. - 압착으로 사용되는 메모리는
log.cleaner.dedupe.buffer.size로 설정할 수 있으며 이 메모리는log.cleaner.threads가 나눠서 사용한다. 그러므로 메모리가 부족하다면 스레드의 수를 줄이거나 메모리를 더 많이 할당해줘야한다.
압착에서 데이터를 삭제하고 싶다면 해당 키 값에 value 로 null 값을 넘겨주면 된다. 컨슈머 쪽에서는 이 데이터를 읽을 때 삭제되었음을 알고 이에 맞게 처리하면 된다.
- 이와 다르게 카프카 Admin Client 에서 사용하는 deleteRecords 메소드는 이것과 동작 방식이 다르다. 이 메소드는 읽을 수 있는 메시지의 오프셋 범위를 옮겨서 해당 메시지를 읽을 수 없도록 하는 방식이다.
토픽의 압착은 언제 되는가?
- 일단 현재 로그 세그먼트 파일이 닫혀야한다. 액티브 로그 세그먼트 파일인 경우에는 압착이 되지 않는다.
- 액티브 로그 세그먼트가 아니라면 이제 로그 세그먼트의 더티 부분이 50% 이상인 경우에 압착 조건이 충족된다.
- 압착의 시점을 결정하는 두 가지 변수가 있다:
min.compaction.lag.ms: 압착을 하기 전 지나야 하는 최소 시간을 말한다.max.compaction.lag.ms: 이 시간 안에는 압착이 반드시 되어야 하는 시간을 지정할 때 사용한다.
'Apache Kafka' 카테고리의 다른 글
| Kafka 에서 '정확히 한 번' 의미 (0) | 2024.01.02 |
|---|---|
| Kafka Network Client Internals (0) | 2023.12.31 |
| Kafka Consumer 주요 설정 (0) | 2023.12.29 |
| Kafka 에서 신뢰성을 주는 방법 (0) | 2023.12.28 |
| Kafka Consumer 에서 커밋을 하는 방법 (0) | 2023.12.27 |