이 글은 Naver D2 Kafka NetworkClient Internals 글을 보고 정리하였습니다.
추가) Kafka 클라이언트 0.10.2.1 버전을 기준으로 작성되었습니다.
NetworkClient
Kafka 클라이언트인 KafkaProducer와 KafkaConsumer는 브로커 노드와 통신하기 위해 NetworkClient라는 클래스를 사용한다.
여기서는 이것의 내부 구조에 대해서 살펴보자.
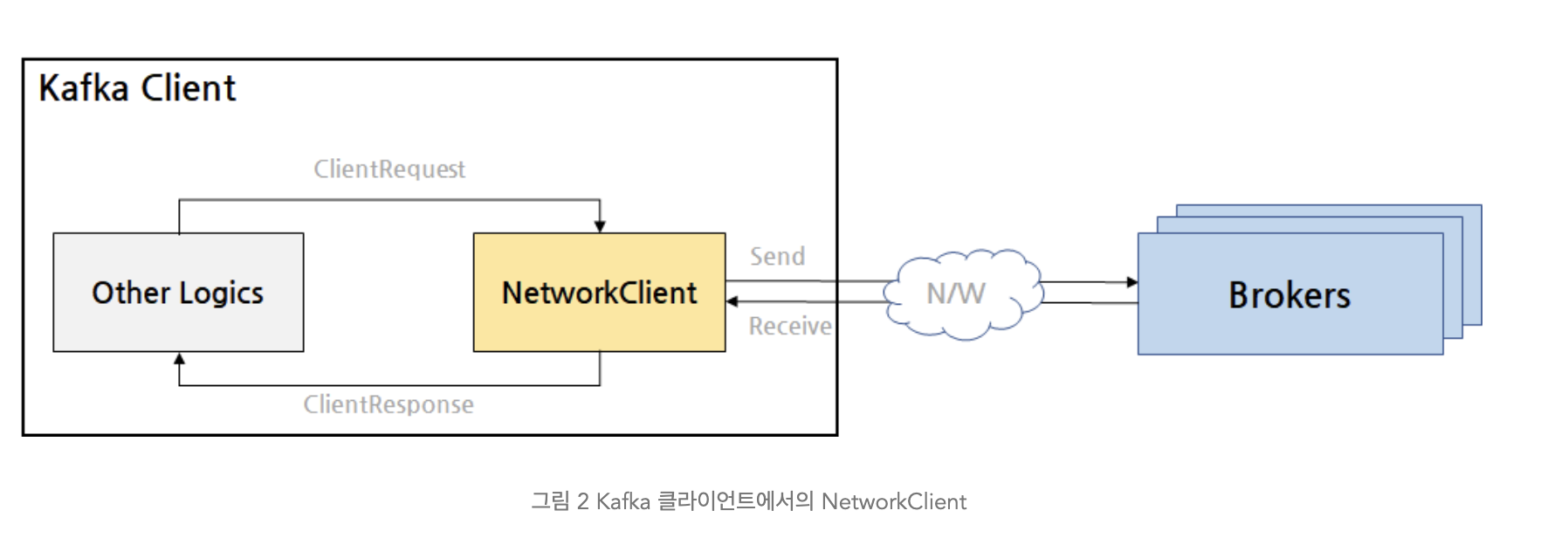
- Kafka 내부 로직은 브로커에 전달할 요청을 만들기 위해서
ClientRequest를 만든다. 이게NetworkClient가 브로커에 전달하는 식으로 사용된다. NetworkClient가 브로커와의 연결 및 요청 전송, 응답 수신을 담당한다.
NetworkClient 는 KafkaClient 인터페이스를 구현한 클래스이다. 다음은 KafakClient 인터페이스의 메소드들이다.
public interface KafkaClient extends Closeable {
// 노드에 요청을 보낼 수 있는 상태인지 확인
boolean isReady(Node node, long now);
// 노드에 요청을 보낼 수 있는 상태인지 확인하고 필요한 경우 Connection 생성
boolean ready(Node node, long now);
// 다음 연결 시도까지 얼마나 기다려야 하는지 확인
long connectionDelay(Node node, long now);
// 노드로의 연결이 끊겼는지 확인
boolean connectionFailed(Node node);
// 노드로의 연결 닫기
void close(String nodeId);
// 보내야 할 요청을 큐에 저장(나중에 준비되면 요청을 전송)
void send(ClientRequest request, long now);
// 실제 I/O 수행 및 받은 응답을 가져옴
List<ClientResponse> poll(long timeout, long now);
// 가장 요청을 적게 받은 노드를 선택
Node leastLoadedNode(long now);
// 브로커로 전송되었지만 응답을 아직 받지 못한 요청들의 총합
int inFlightRequestCount();
// 특정 브로커로 전송되었지만 응답을 아직 받지 못한 요청들의 수
int inFlightRequestCount(String nodeId);
// I/O 수행을 기다리고 있는 스레드를 깨움
void wakeup();
}
ClusterConnectionStates
ClusterConnectionStates 은 NetworkClient 내부에서 브로커와의 연결 상태를 관리하는 역할을 한다.
- 연결 상태는 NodeConnectionState 객체에 기록하며, 마지막으로 연결 시도했던 시각과 연결 상태가 기록된다.
연결 상태는 다음과 같이 전환될 수 있다:
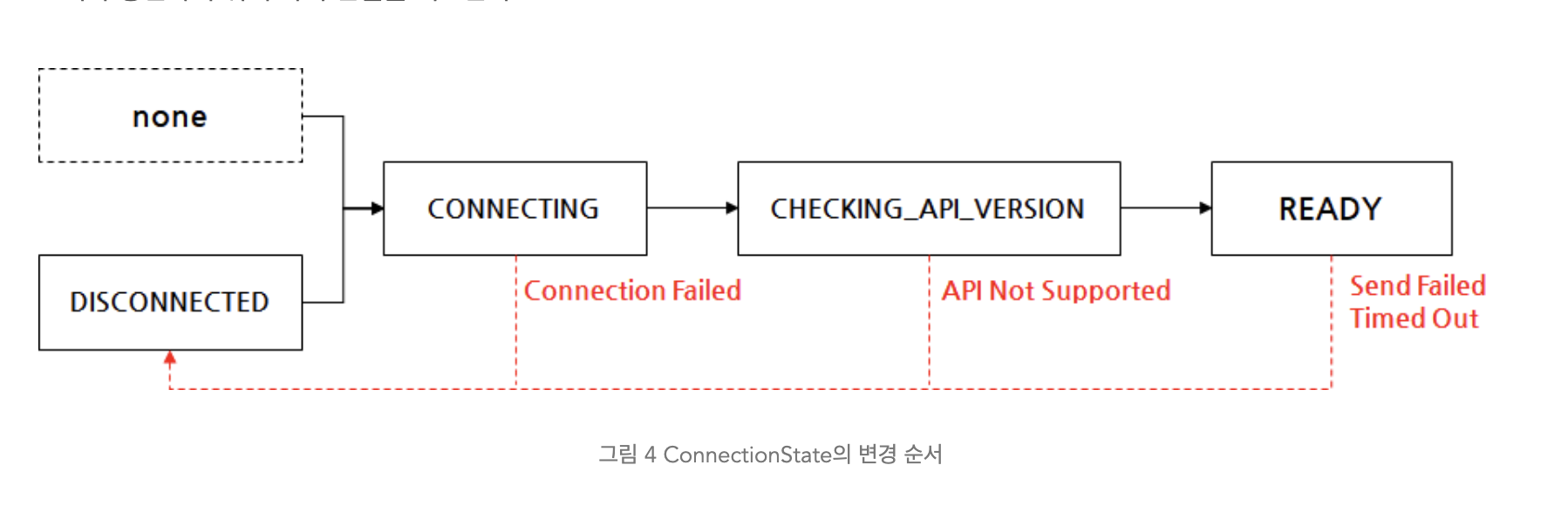
연결 상태에 대한 간략한 설명은 다음과 같다:
- DISCONNECTED: 브로커와 연결이 끊긴 상태
- CONNECTING: 소켓을 생성하고 연결을 시도 중인 상태
- CHECKING_API_VERSIONS: 연결은 되었고 브로커와 API 버전이 호환되는지 확인 중인 상태
- READY: 브로커로 요청을 전송할 수 있는 상태.
이제 각 상태에 대해 좀 더 자세히 살펴보자.
DISCONNECTED 상태
DISCONNECTED 상태는 Kafka 클라이언트와 브로커 노드의 연결이 끊긴 상태를 의미한다.
다양한 경우에 브로커 노드와 연결이 DISCONNECTED 상태로 설정될 수 있다:
- 브로커 노드로의 연결 초기화가 실패한 경우
- API 버전이 호환되지 않는 경우
- 브로커 노드로 요청 전송이 실패한 경우
- 요청이 전송되고 응답을 기다리다가 타임아웃이 발생한 경우
- 일정 시간 동안 브로커로 새로운 요청을 보내지 않은 경우
DISCONNECTED 상태라면 브로커로 요청을 보내기 위해 다시 연결을 시도한다:
- 이때 Kafka 클라이언트가 연결을 너무 빈번하게 재시도하지 않도록 최소한
reconnect.backoff.ms에 설정한 시간이 지난 이후에 재연결을 시도한다. - reconnect.backoff.ms 설정의 기본값은 '50'으로, 브로커로 연결 시도 사이에 최소 50ms의 시간차를 둔다. 이 백오프(backoff) 시간을 보장하기 위해서 NetworkClient는 브로커의 NodeConnectionState에 마지막 연결 시도 시간을 기록한다.
CONNECTING 상태
연결을 시도할 때 CONNECTING 상태가 된다.
이때 데이터를 주고 받을 수 있는 SocketChannel 을 생성한다. 생성 후 I/O Multiplexing 을 위해 Selector 객체에 SocketChannel 을 등록한다.
- Selector 에 SocketChannel 을 등록해서 Socket 으로 들어오는 다양한 이벤트들 (such as 데이터 수신, 출력) 을 수신하고 관리할 수 있다.
- Selector 는 Java NIO 에 있는 Selector 를 Kafka 에서 확장해서 구현한 객체이다.
- SocketChannel 을 만들 때 송/수신 버퍼가 만들어지며, 이 크기는
send.buffer.bytes와receive.buffer.bytes로 크기를 정할 수 있다. 각각 순서대로 송신 버퍼와 수신 버퍼이다.- 별도로 설정하지 않으면 송신 버퍼는 128KB 이고, 수신 버퍼는 64KB 이다.
- 만약 값을 '-1'로 설정하면 실행하는 운영체제의 기본값인 SO_SNDBUF와 SO_RCVBUF가 적용된다.
CHECKINGAPIVERSIONS 상태, READY 상태
CHECKINGAPIVERSIONS 상태는 카프카 브로커와 통신할 때 API 버전이 호환되는지 살펴보는 단계이다. 이게 호환되지 않는다면 정상적으로 통신할 수 없다.
카프카 클라이언트는 자신의 ApiVersion 을 브로커에게 알려주고, 브로커는 이를 받아서 호환되는지 알려준다. 정상적으로 호환되면 READY 상태로 된다.
IdleExpiryManager
Kafak 의 경우 READY 상태인 연결을 장기간 이용하지 않으면 IdleExpiryManager 에 의해서 연결이 정리된다.
IdleExpiryManager 에 의해서 연결이 정리되는 동작은 다음과 같다:
-
- NetworkClient 에서 브로커와 연결을 하기 위한 SocketChannel 은 Selector 에 등록되어있다. Selector 에서는 주기적으로 poll() 을 해서 SocketChannel 로 들어온 이벤트들을 비동기 논블로킹으로 처리된다.
- IdleExpiryManager 는 특정 이벤트들이 처리될 때마다 SocketChannel 에 어떤 이벤트들이 처리되었는지 시각을 기록해두며 이를 LRU 리스트로 관리한다. 그리고 가장 오래 쓰이지 않은 연결을 살펴보고 이게 만료 시간이 자났다면 제거한다.
- 만료 시간의 기준은
connections.max.idle.ms이며 기본값은 540000ms 이다. 즉 9분이다. 이 값을 음수로 지정하면 IdleExpiryManager 를 생성하지 않고 사용하지도 않는다.
InFlightRequests
카프카 프로듀서에서 요청을 브로커 노드별로 배치 형식으로 보낼 때 InFlightRequest 로 보냈었다. 여기서는 이에 대해 좀 더 깊게 살펴보자.
InFlightRequests 는 브로커에 요청을 보낼 때 응답을 기다리지 않고 여러개를 보낼 수 있도록 해서 성능을 높이기 위해 사용된다.

- 'in-flight'는 '운항 중의'라는 뜻의 영어 단어로 응답을 기다리지 않고 요청을 일단 보낸다 라고 해석하면 된다.
- NetworkClient 가 응답을 받지않고 브로커로 보낼 수 있는 최대 요청의 개수는
max.in.flight.requests.per.connection로 설정할 수 있다. 기본값은 5이며 이 값에 다다르게 되면 더이상의 요청은 보내지지 않게 되고 응답이 올때까지 대기한다. - InFlightRequests 는 브로커 노드 별로 구분된 Deque 에 순서대로 쌓이고 이게 하나씩 요청으로 보내진다. 브로커에서 응답이 성공적으로 오게되면 Deque 에서 관리하고 있던 요청은 이제 삭제되고 응답을 처리하게되며, 실패로 오게되면 이 실패가 재시도로 해결 가능하다고 판단한 경우에는 다시 재전송을 보낸다. 이때 Deque 의 가장 마지막에 추가 되서 요청이 보내지므로 이런 재전송 매커니즘 때문에 메시지의 순서가 뒤바뀔 수 있다.
- 이렇게 요청의 순서가 뒤바뀌는게 싫다면
enable.idempotence=true로 설정하면 된다.
- 이렇게 요청의 순서가 뒤바뀌는게 싫다면
Selector
Kafka 클러스터는 보통 수백대의 브로커 노드로 운영되는데 이런 브로커들과 연결을 효율적으로 하기 위해서는 I/O Multiplexing 과 같은 기술이 필요하다.
- Multiplexing 이라는 용어는 여러개의 입출력을 하나로 관리하는 기술이라고 알면 된다.
NetworkClient 는 Java NIO 를 이용해서 이 기술을 구현했다.
먼저 여기서는 Java NIO를 사용한 I/O 멀티플렉싱을 간단히 살펴보자.
Java NIO
기존에 네트워크 연결을 관리하던 방식은 모든 연결마다 스레드를 하나씩 둬서 관리하는 방식이다.
이런 방식은 직관적이고 쉽긴하나 카프카와 클러스터와 같은 대규모 연결을 처리하는 경우에 스레드 생성/관리 비용과 놀고 있는 스레드가 발생할 확률이 높다는 문제가 있다.
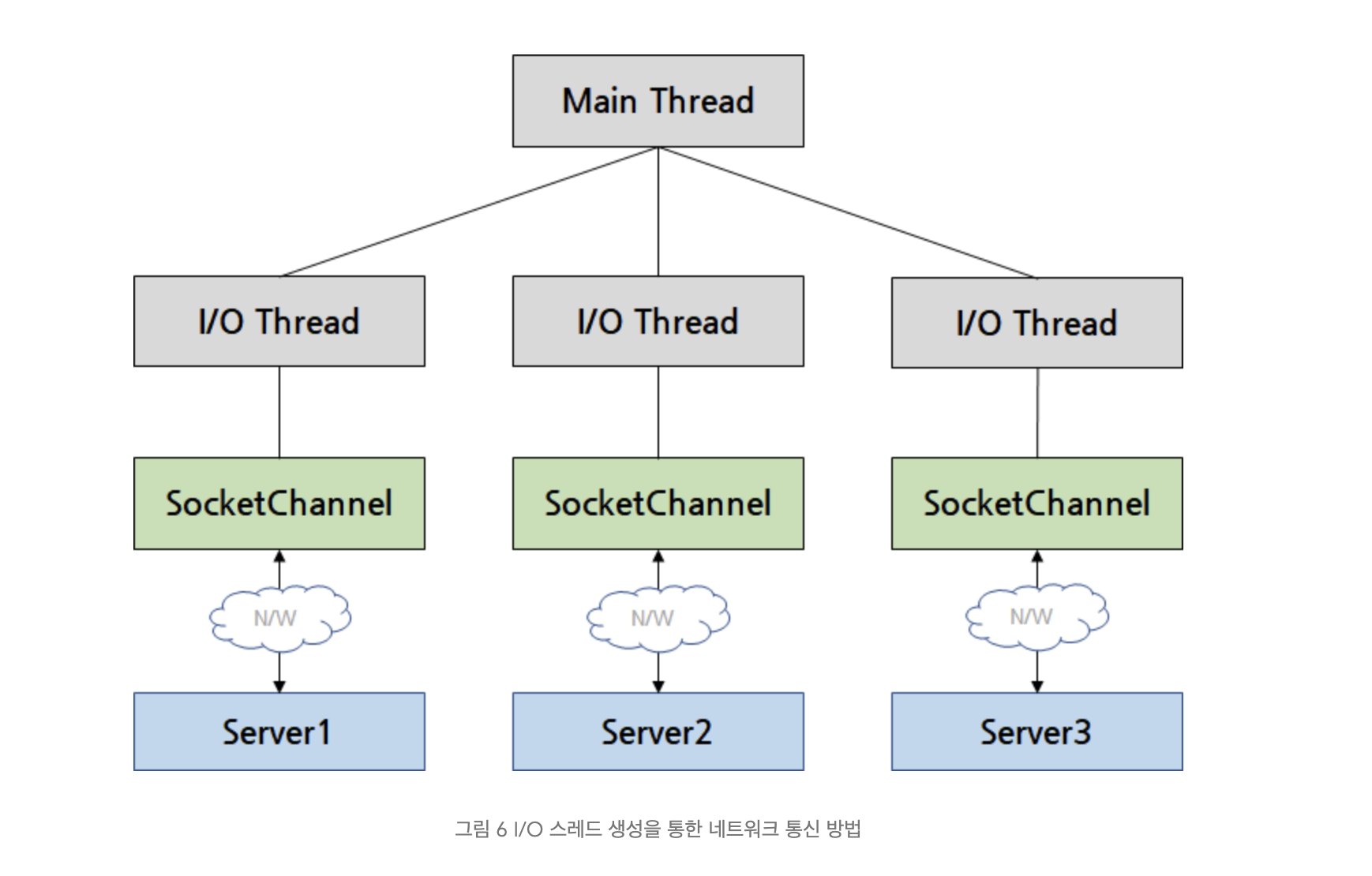
그에 비해 NIO 는 하나의 Thread 인 Selector 가 수백개의 SocketChannel 을 관리하도록 할 수 있다. 각 SocketChannel 에서 수신한 이벤트가 있다면 이를 Selector 에서 처리한다.
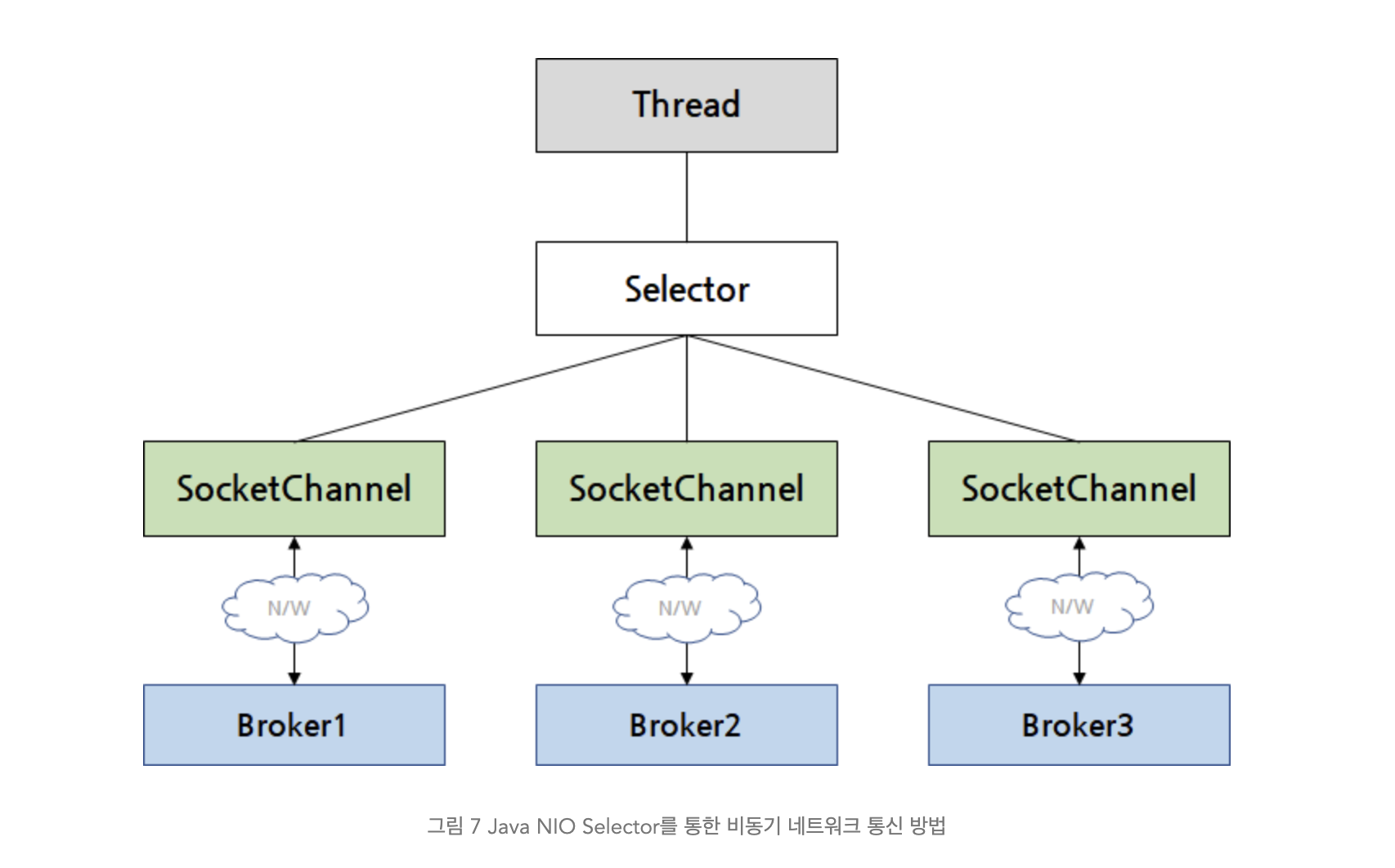
Selector 를 사용하는 법
- 먼저 Selector 를 만들어줘야한다. Selector 는 정적 메서드인 open() 메서드를 사용해서 만들 수 있다.
Selector selector = Selector.open();
- 브로커와 연결을 맺기 위해서 브로커 연결 정보를 이용해 SocketChannel 을 만들어준다.
- 주의해야 할 부분은 socketChannel.configureBlocking(false)이다. Selector를 사용한 멀티플렉싱을 위해 생성되는 SocketChannel은 반드시 논블로킹 모드로 설정해야 한다.
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false);
socketChannel.connect(new InetSocketAddress(node.host(), node.port());
- SocketChannel을 Selector에 등록한다. 다음과 같이 SocketChannel의 register() 메서드를 사용해 SocketChannel을 등록할 수 있다.
- register() 메서드의 첫 번째 파라미터는 등록할 Selector이고, 두 번째 파라미터는 interestSet 이다. interestSet 를 통해서 관심있는 이벤트들을 정의하고, 이런 이벤트들이 온다면 Selector 에서 알림을 받을 수 있다.
- Selector에 설정할 수 있는 interest operation은 다음과 같다. Bitwise OR 연산(|)으로 하나의 채널에 대해서 두 개 이상의 interest operation을 설정하는 것도 가능하다.
- OP_READ
- OP_WRITE
- OP_CONNECT
- OP_ACCEPT
SelectionKey selectionKey = channel.register(selector, SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
- SocketChannel을 Selector에 등록하면 SelectionKey 객체를 얻게 된다. SelectionKey 객체를 사용해서 Selector 객체와 SocketChannel 객체를 얻어올 수 있고, 다음 예처럼 SelectionKey 객체를 사용해 등록했던 interestSet을 바꿀 수도 있다.
selectionKey.interestOps(SelectionKey.OP_READ | SelectionKey.OP_WRITE);
- 이렇게 Selector 의 등록이 끝났다면 select() 를 통해서 이벤트를 받아올 수 있다. select() 는 타임아웃이 지나거나 이벤트가 발생한 SocketChannel 이 있다면 꺠어나게 된다.
selector.select(timeout);
- 깨어나게 되면 다음과 같이 처리해서 이벤트들을 처리할 수 있다. SelectionKey 에서 SocketChannel 을 읽어올 수 있어서 수신된 데이터를 읽을 수 있다.
// 등록한 브로커 중 필요한 연산을 할 수 있는 SocketChannel의 SelectionKey
Set<SelectionKey> selectedKeys = selector.selectedKeys();
// SelectedKeys 순회
Iterator iterator = selectedKeys.iterator();
while(iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isReadable()) {
// ... 실행 코드
}
if (key.isWritable()) {
// ... 실행 코드
}
...
}
KafkaChannel과 인증, 암호화
Kafka 는 SocketChannel 에서 인증과 암호화 기능을 추가하기 위해 KafkaChannel 이라는 것을 이용한다.
앞서 등록한 Selector 의 SocketChannel 은 확장된 기능을 제공하기 위해서 KafkaChannel 이라는 것으로 래핑된다.
public class KafkaChannel {
// 브로커 ID
private final String id;
// SocketChannel과 SelectionKey를 사용한 전송 동작
private final TransportLayer transportLayer;
// Kafka 클라이언트 인증 과정
private final Authenticator authenticator;
// 브로커에서 받은 데이터
private final int maxReceiveSize;
private NetworkReceive receive;
// 브로커로 전송할 데이터
private Send send;
...
}
KafkaChannel 의 인증 과정:
- Authenticator 가 인증과 관련된 동작을 수행하며 TransportLayer 를 이용해서 데이터를 암호화해 브로커에 전송하는 역할을 한다.
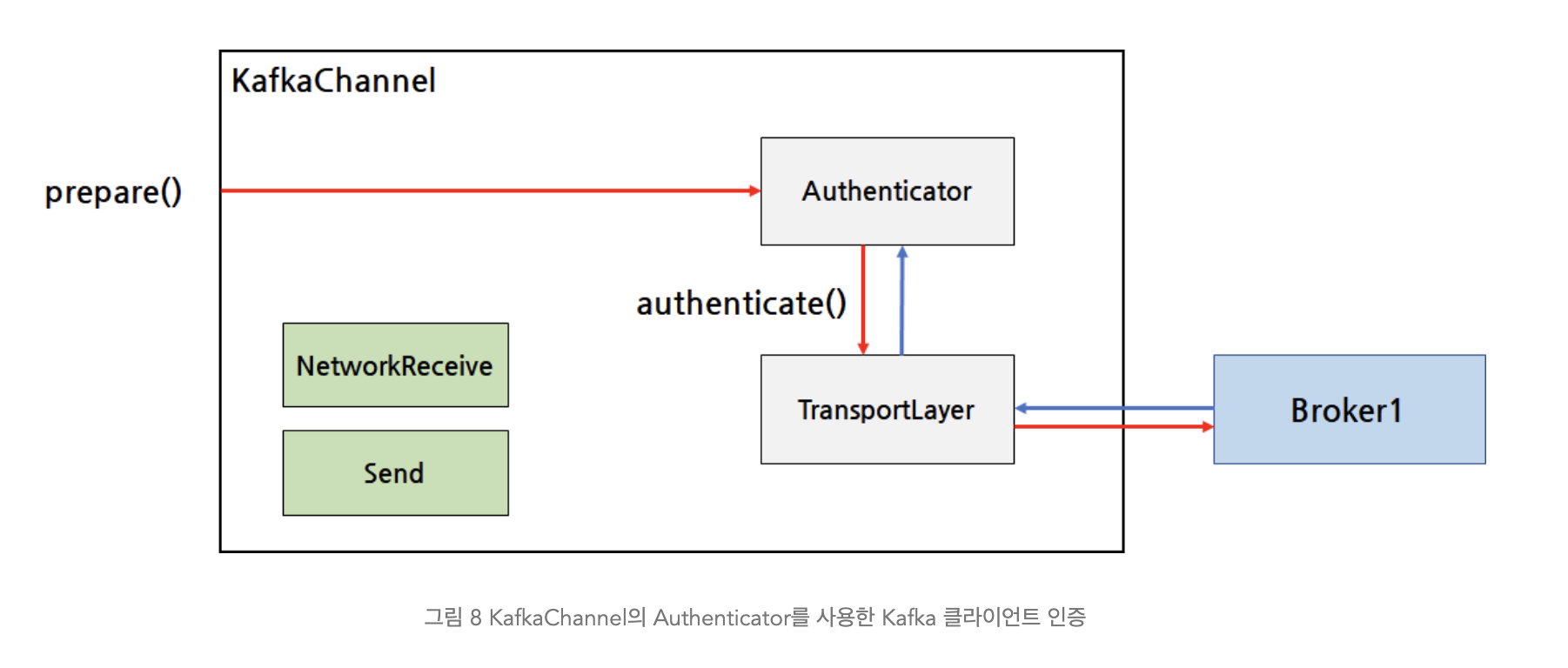
KafkaChannel 의 데이터 송/수신 과정:
- 인증 과정이 끝나면 브로커와 데이터를 본격적으로 주고 받을 수 있다.
- TransportLayer 를 통해 브로커의 데이터를 수신해서 NetworkReceive 에다가 저장하고, Send 에 있는 데이터를 브로커에 전송한다.
- Send 는 브로커에 전송하기 위해 만들었던 ClientRequest 를 바이트로 직렬화한 데이터라고 알면 된다.
- 수신한 데이터는 NetworkReceive 에 쌓이게 되고 모두 쌓이면 이를 ClientResponse 로 변환해서 반환한다.

KafkaChannel 의 생성과정:
- Selector 에 SocketChannel 이 등록될 때 KafkaChannel 도 같이 만들어진다.
- KafakChannel 은 ChannelBuilder 에 의해 만들어지며
security.protocol값에 따라서 생성이 달라진다:
- SASL_PLAINTEXT와 SASL_SSL처럼 접두어 'SASL_'로 시작하는 설정을 사용하면 Kafka 클라이언트 연결에 인증을 사용하겠다는 의미이다
Metadata
프로듀서는 저장할 토픽 파티션의 메시지는 리더 파티션에서만 쓰일 수 있으므로 리더 파티션을 가진 브로커에게 메시지를 보내야한다.
이런 브로커에 대한 정보는 Metadata 라는 녀석이 관리한다.
Metadata 는 Node 라는 객체를 통해서 브로커에 대한 정보를 저장하며, PartitionInfo 객체를 통해서 리더 파티션과 In-Sync 레플리카는 어느 브로커에서 관리하고 있는지를 저장한다.
이런 메타 정보들을 가지고 오는 건 어느 브로커에서 요청을 보내도 된다. 모든 브로커는 자신을 포함한 모든 브로커의 토픽 파티션의 관리 정보에 대해 가지고 있다.
Metadata 는 이 정보를 캐싱해두고 있고 이 정보를 주기적으로 또는 유효하지 않는 조건이라고 판단하면 갱신한다.
public class Node {
private final int id;
private final String idString;
private final String host;
private final int port;
private final String rack;
...
}public class PartitionInfo {
private final String topic;
private final int partition;
private final Node leader;
private final Node[] replicas;
private final Node[] inSyncReplicas;
...
}
MetadataUpdater
Kafka 클라이언트가 Metadata로 관리하는 메타데이터는 클러스터가 운영되는 도중에 얼마든지 바뀔 수 있다.
예를 들어 새로운 토픽이 만들어지거나 파티션 개수가 추가될 수 있다. 성능을 위해서 신규 브로커 장비가 클러스터에 추가되는 경우도 있고, 장비 장애로 클러스터에서 브로커가 제외되는 경우, 노후 장비 교체로 브로커의 장비가 교체되는 경우도 얼마든지 있을 수 있다.
일반적으로 Kafka 클라이언트는 다음의 경우에 메타데이터 갱신이 필요하다.
- 특정 브로커 노드로 연결하다가 실패한 경우
- 특정 브로커 노드에 요청을 보냈는데 타임아웃이 발생한 경우
- 새로운 토픽에 데이터를 전송하거나 새로운 토픽을 구독하는 경우
- 컨슈머 코디네이터 객체가 생성되는 경우
- Fetcher에서 데이터를 가져오려는데 Leader의 정보를 알 수 없을 경우
- 데이터 요청을 보냈는데 Unknown Partition이라는 오류가 응답으로 오거나 Leader가 아니라는 오류가 응답으로 왔을 때
- 그 밖에 메타데이터가 Stale 상태일 경우 만나게 되는 각종 Exception이 발생할 때
NetworkClient는 Metadata를 갱신하기 위해 MetadataUpdater라는 클래스를 사용한다.
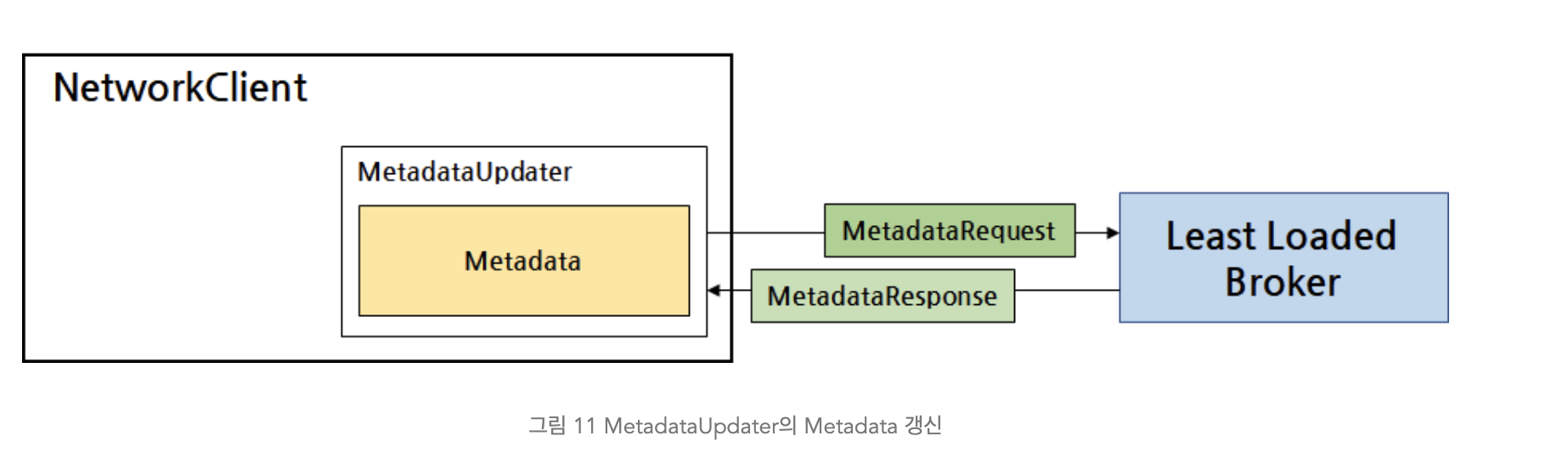
Metadata 정보를 가지고 오는 동작 방식은 다음과 같다:
- 첫 Metadata 가져오기:
- 카프카가 시작되었을 떄 Metadata 를 가지고 오기 위해 메타데이터에 대한 갱신 요청(MetadataRequest) 을 보낸다. 이를 위해 브로커 서버에 대한 정보를 알고 있어야 하므로
bootstrap.servers설정에 브로커 정보를 입력해줘야한다.
- 카프카가 시작되었을 떄 Metadata 를 가지고 오기 위해 메타데이터에 대한 갱신 요청(MetadataRequest) 을 보낸다. 이를 위해 브로커 서버에 대한 정보를 알고 있어야 하므로
- 메타데이터 갱신 요청은 백오프 시간으로 조절된다:
- 메타데이터 갱신 요청이 너무 빈번하게 브로커로 전송되지 않도록 백오프 시간을 설정할 수 있다. Metadata에는 마지막으로 정보가 갱신된 시간이 기록되어 있고, retry.backoff.ms 설정을 사용하면 마지막 갱신 시간으로부터 retry.backoff.ms 설정값만큼 시간이 지날 때까지 새로운 MetadataRequest를 전송하지 않고 기다린다. retry.backoff.ms 설정의 기본값은 '100'이다.
- 수동 갱신 이외에도 주기적인 갱신을 수행한다:
- 반대로 메타데이터에 대한 변경이 오랜 시간 동안 감지되지 않더라도 일정 시간이 지나면 갱신 요청을 브로커로 전송한다. 당장은 필요하지 않더라도 Kafka 클러스터에 추가된 브로커나 파티션에 대한 정보를 미리 알아오면 나중에 MetadataRequest를 전송하고 기다리지 않아도 되기 때문이다. MetadataUpdater는 마지막 메타데이터 갱신이 성공한 이후 metadata.max.age.ms에 설정한 시간이 지나면 다시 갱신 요청을 전송한다. metadata.max.age.ms 설정의 기본 값은 '300000'으로, 5분이다.
- 관심없는 토픽 정보는 추후에 제외되서 네트워크 전송을 효율화한다:
- MetadataUpdater가 생성하는 MetadataRequest에는 Kafka 클라이언트가 관심 있어 하는 토픽의 리스트가 담겨 있다. 다시 돌아오는 응답에는 Kafka에 있는 Kafka 클라이언트가 관심 있다고 보낸 토픽의 정보만 담겨 있다. 만약 오랜 기간 동안 사용되지 않은 토픽이 있다면 MetadataRequest에 쓸데없는 정보가 포함되어 브로커도 느려지고 주고받는 요청의 크기도 커진다. KafkaProducer는 일정 기간 동안 사용되지 않은 토픽의 정보는 메타데이터에서 제외한다. 제외된 토픽은 앞으로 전송되는 메타데이터 갱신 요청에 포함되지 않는다. 이 기간은 설정할 수 있는 값이 아니며, 5분이라는 고정값으로 설정되어 있다.
'Apache Kafka' 카테고리의 다른 글
| Kafka 에서 '정확히 한 번' 의미 (0) | 2024.01.02 |
|---|---|
| Apache Kafka Internal Mechanism (0) | 2023.12.30 |
| Kafka Consumer 주요 설정 (0) | 2023.12.29 |
| Kafka 에서 신뢰성을 주는 방법 (0) | 2023.12.28 |
| Kafka Consumer 에서 커밋을 하는 방법 (0) | 2023.12.27 |