
이진 탐색 트리
B-Tree 를 왜 사용하는지에 대해 알아보기 위해서 먼저 이진 탐색 트리부터 보자.
이진 탐색 트리의 어떤 문제점 때문에 B-Tree 를 사용하는지 파악하는 걸로.
이진 탐색 트리 문제점: 이진 탐색 트리는 트리 밸런싱이 자주 발생한다.
Q) 트리 밸런싱이 뭐고 왜 필요한데?
불균형 트리는 트리가 균등하게 자식들이 분포되지 않고 한 쪽 가지가 다른 쪽 가지보다 월등히 긴 경우를 말한다.
이런 불균형 트리는 트리 탐색 시간 복잡도가 O(N) 이 된다는 문제점이 있다.
그러므로 서로의 자식들을 거의 균등하게 맞추고 자식 서브 트리의 높이가 최대 하나만 차이 나도록 만드는 트리 밸런싱이 필요하다.
Q) 왜 이진 탐색 트리는 트리 밸런싱이 자주 발생하는데?
트리의 높이가 길고, 트리의 팬아웃 (= 하나의 노드가 가질 수 있는 자식의 수) 값이 작아서 (이진 탐색 트리의 팬아웃 값은 2이다.)
그래서 노드가 추가되고 삭제되는 일이 발생하면 금방 불균형 트리가 된다.
Q) 트리 밸런싱은 어떤 비용이 드는가?
구체적으로 트리 밸런싱의 비용을 생각해보면 노드를 재배치하고 포인터를 갱신해야하는 비용이 생긴다.
이진 탐색 트리 문제점: 디스크 기반 자료구조에 적합하지 않다.
이진 탐색 트리는 디스크 기반의 자료구조에 적합하지 않다.
이진 탐색 트리는 키 순서대로 삽입되지 않는다. 포인터로 연결되는 구조라서 인접한 범위 탐색이더라도 Random I/O 를 사용한다.
Linear I/O 를 활용할 수 없음.
Q) 디스크 기반 자료구조에 적합하려면 어떤 특징이 있어야하는데?
1) Random I/O 보다는 Linear I/O 를 쓸 수 있는 형태가 되야함. (SSD 또한 Linear I/O 가 Random I/O 보다 유리하다.)
2) 또 디스크 특성 상 하나의 작은 데이터가 필요 하더라도 블록 단위로 데이터를 가져오므로 같이 가져오는 데이터들이 유의미 해야한다.
- 그러니까 같이 가져온 데이터들이 미래에 사용할 확률이 높아야함. 정리하자면 Disk I/O 자체를 줄일 수 있는 자료구조야 함.
3) 마지막으로 포인터가 최소화될 수록 좋다.
- 이는 Linear I/O 를 사용하도록 만드는 방법과 의미가 유사한대 포인터가 많다는 건 포인터를 통해 참조한다는 뜻이니 데이터들은 인접한 곳에 있지 않게 된다.
- 그러니 연속적으로 데이터를 저장할 수 없으므로 Random I/O 를 더 쓸 것이다.
디스크 기반 자료구조
하드 디스크 드라이브 특징
- 하드 디스크에서 가장 비용이 많이 들어가는 작업은 헤드를 이동시키는 것임. 그래서 Random I/O 가 워낙 비용이 큰거다.
- 하드 디스크 드라이브에서 데이터 접근 최소 단위는 섹터다. 모든 작업은 최소 하나의 섹터를 읽거나 쓴다.
- 섹터의 크기는 512Byte ~ 4KB 사이다.
솔리드 스테이드 드라이브 특징
- SSD 는 다음과 같이 계층으로 구성된다:
- 메모리 셀이 제일 작은 단위다. 메모리 셀이 모이면 스트링이 된다.
- 하나의 셀은 보통 한 개에서 여러개의 비트를 저장한다.
- 하나의 스트링은 32-64개의 셀로 구성되어 있다.
- 스트링이 모이면 페이지를 이룬다.
- 페이지는 2~16KB 이다.
- 읽고 쓰고 하는 단위는 페이지이다.
- 페이지가 모이면 블록이 된다.
- 블록은 64~512개의 페이지로 구성된다.
- 블록 단위로 삭제가 된다.
- 페이지가 모이면 플레인이 된다.
- 플레인이 모이면 다이가 된다.
- SSD 는 하나 이상의 다이로 구성된다.
- 메모리 셀이 제일 작은 단위다. 메모리 셀이 모이면 스트링이 된다.
- SSD 에서는 플래쉬 변환 레이어 (FTL, Flast Transition Layer) 에 대해 알아야한다:
- 페이지 ID 를 실제 물리적인 주소로 매핑하는 역할을 한다.
- 가비지 컬렉션을 수행한다:
- 페이지는 블록 단위로 제거되는데, 자주 안쓰는 블록을 제거할 때 제거되는 블록에 있는 페이지는 다른 블록으로 이동된다. 이때 페이지 ID <-> 물리 주소 매핑 정보도 업데이트 됨.
- 웨어 레벨링(Wear Leveling) 작업을 수행한다:
- SSD 는 데이터를 쓸 때마다 소모된다. 웨어 레벨링을 통해서 하나의 영역만 소모되도록 만드는게 아니라 골고루 소모되도록 만들어줌.
Q) SSD 는 Linear I/O 와 Random I/O 성능은 차이 없지?
이건 반만 맞다. 단 하나의 작업만 한다면 둘의 성능은 큰 차이 없다.
그러나 SSD 의 내부적인 처리 작업 기술인 Prefetch, 연속된 페이지 읽기, 내부 병렬 처리를 생각해보면 Linear I/O 가 성능이 더 좋다.
Prefetch:
- 연속적으로 데이터를 읽을 때 앞으로 읽을 데이터를 미리 읽어서 메모리에 적재하는 기술.
- SSD 컨트롤러는 앞으로 접근할 것으로 예상되는 데이터를 미리 읽어 대기시킴으로써, 실제 요청이 발생했을 때 빠르게 데이터를 제공할 수 있다.
연속된 페이지 읽기:
- 연속된 페이지를 읽는 경우, SSD 컨트롤러는 여러 페이지의 데이터를 더 빠르게 읽어낼 수 있다.
내부 병렬 처리:
- SSD 는 내부 처리를 병렬 처리할 수 있다.
가비지 컬렉션 작업:
- 가비지 컬렉션은 유효 데이터를 보존하면서 무효 데이터를 정리하기 위해 여러 물리적 위치에서 데이터를 읽고, 정리한 후 다시 쓰는 과정을 한다.
- Linear I/O 로 데이터를 적재했다면 가비지 컬렉션을 수행할 때 무효 데이터를 정리하는 과정이 훨씬 간단해짐.
B-Tree 를 쓰는 이유는?
B-Tree 는 BST 보다 팬아웃이 많고 노드의 트리 수 또한 적다.
즉 노드에 데이터를 연속적으로 저장할 수 있으니 Random I/O 보다는 Linear I/O 를 쓰도록 만들 수 있고, 디스크에서 블록을 가져와도 이
데이터들은 연속된 데이터니까 미래에 사용될 확률도 높다. 그래서 Disk I/O 도 보다 효율적일 거임.
B-Tree 개요
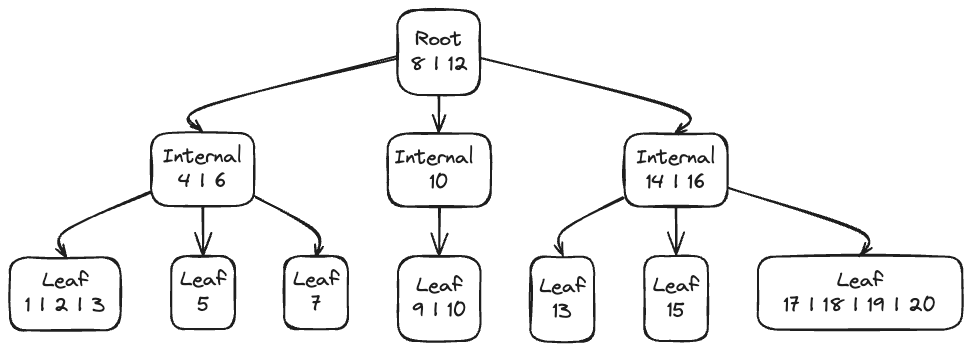
- B-Tree 는 3개의 계층으로 나뉜다.
- 루트 노드
- 내부 노드
- 리프 노드 (리프 노드에 최종 데이터가 저장되는 형태라고 알면 됨.)
- B-Tree 의 내부 노드와 루트 노드에는 키와 포인터가 저장된다:
- 키:
- 노드에는 키 값이 순서대로 정렬되어 있다. 수백개 정도의 키가 들어있음.
- 이 키와 비교함으로서 내가 원하는 리프 노드를 찾으러 가는거임.
- B-Tree 의 키 비교에는 이진 탐색이 쓰인다. 키 비교도 효율적으로 탐색함.
- 포인터:
- 자식 노드의 주소를 가리킨다.
- 각 키 옆에는 두 개의 포인터가 있다. 왼쪽의 포인터는 이 키보다 작은 값들이 담겨져있는 노드의 주소이고, 오른쪽 포인터는 해당 키보다 큰 값들이 담겨져 있는 노드의 주소이다.
- 포인터와 키는 같이 저장되는 식이다. 불필요한 디스크 탐색을 없애기 위해서.
- 키:
- BST 와 달리 팬아웃이 크다.
- 하나의 노드에 수백개의 키를 저장하기 때문에 한번의 디스크 탐색으로 많은 범위를 줄일 수 있다.
- 팬아웃의 크기와 트리 밸런싱과는 연관이 있다. 팬아웃이 클수록 트리 밸런싱이 적게 일어난다. 트리의 높이 차이를 기준으로 밸런싱이 필요함을 인지하니까.
- B-Tree 는 범위 쿼리에 효과적이다:
- 리프 노드에 연속된 값들이 저장되어 있으니까.
- 변형된 B-Tree 의 경우에는 리프 노드끼리 이중 연결 리스트로 연결되어 있기도 하다. 이 경우에는 인접한 리프 노드로 쉽게 탐색할 수 있기 때문에 훨씬 범위 쿼리에 효과적임.
- B-Tree 의 시간 복잡도:
- 시간 복잡도는 노드에서 높이 탐색이 몇 번 일어났는지, 그리고 하나의 노드에서 적합한 키를 찾기 위한 비교는 몇 번 일어나는지 파악하면 된다.
B-Tree 노드 분할 과정
Q) 언제 분할 하는데?
리프 노드가 가득 찬 상황에서 노드를 하나 더 추가할 때.
Q) 어떻게 분할하는데?
대략적인 과정은 다음과 같다.
- 1) 새로운 노드를 만듬
- 2) 가득 찬 노드의 절반 데이터를 새로운 노드로 옮김.
- 3) 새로운 키를 알맞은 노드에 삽입
- 4) 부모 노드에서 새로운 노드 포인터 추가해줌 + 기존 노드 포인터도 수정
Q) 부모 노드에도 포인터가 추가되네? 그럼 부모 노드도 이때 가득차면 어떻게 됨?
부모 노드도 분할된다. 루트 노드까지 재귀적으로 분할 될 수 있음.
B-Tree 노드 병합 과정
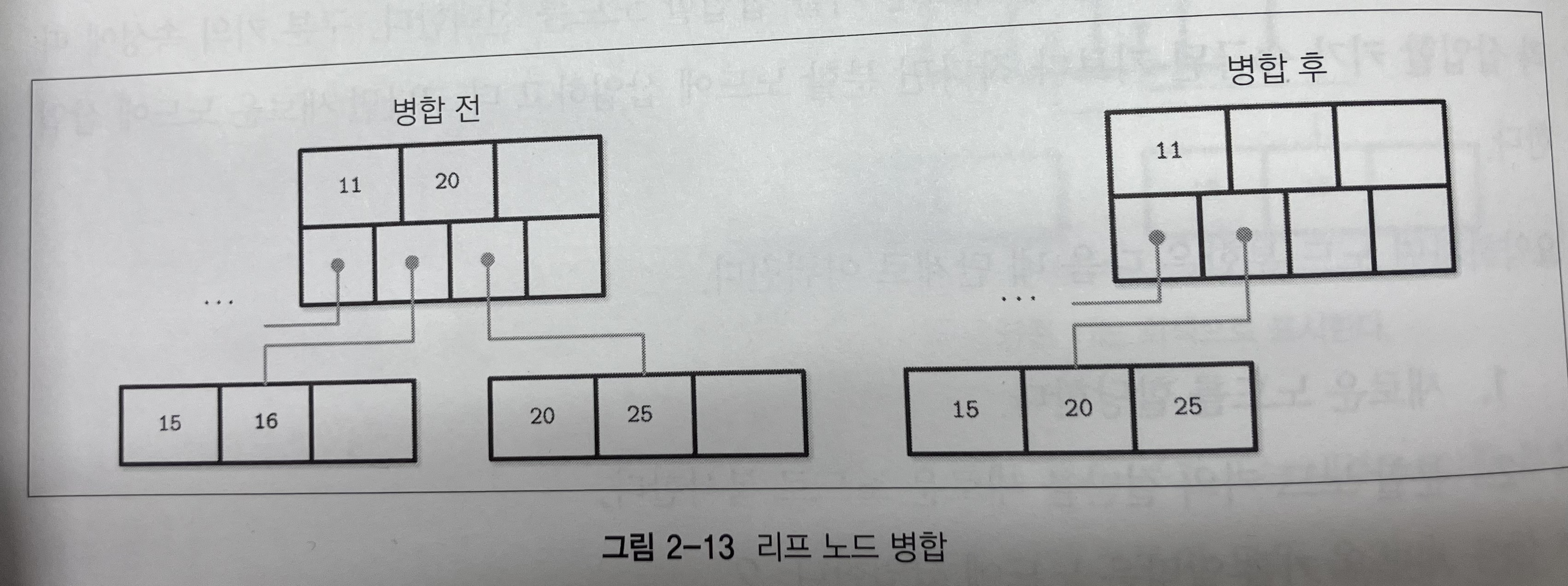
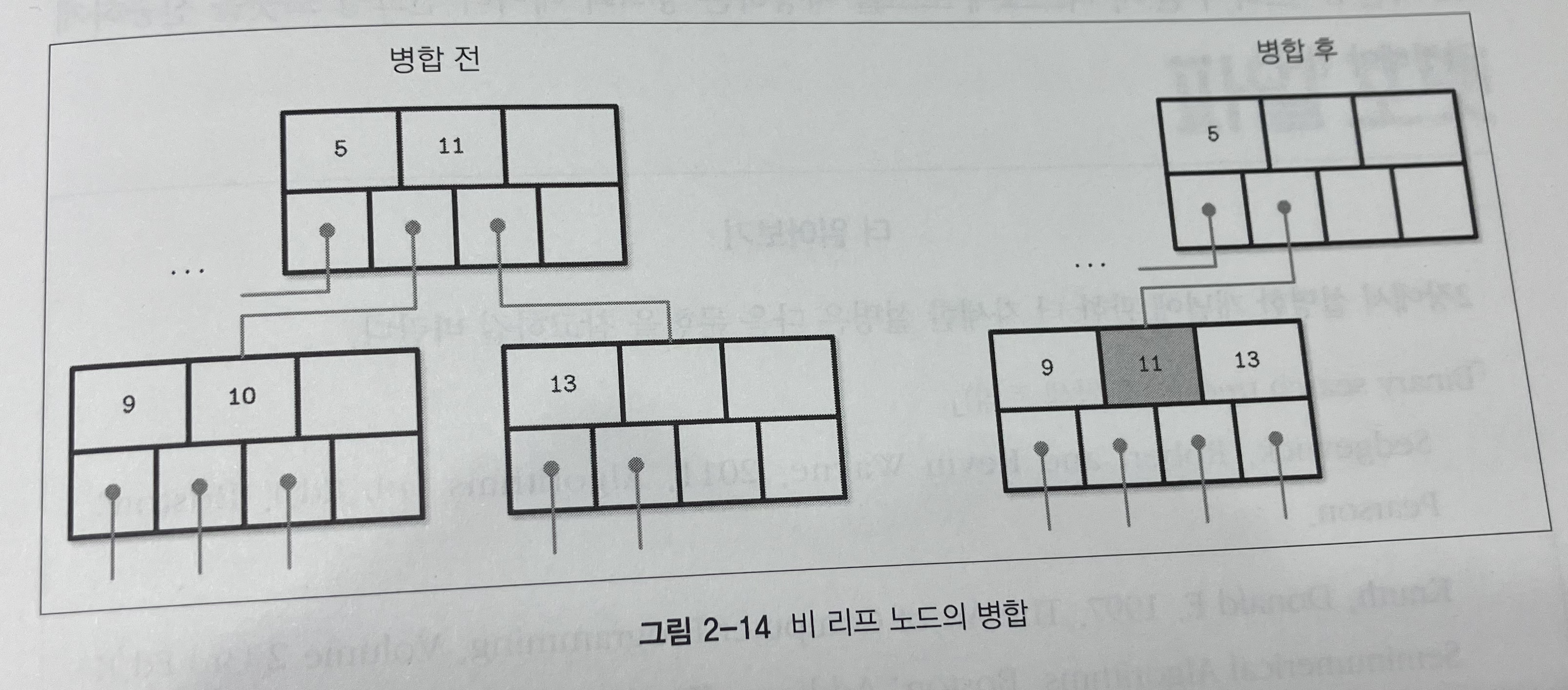
Q) 노드 병합은 언제 일어나는데?
노드를 삭제하는데 노드가 너무 공간이 많이 남을 때
두 개의 시나리오가 있음:
- 하나의 노드로 모두 합치기 가능할 때
- 하나의 노드로 모두 합치는게 가능하지는 않다면 키를 골고루 나눠가짐.
Q) 어떻게 병합하는데?
대략적인 과정은 다음과 같다:
- 모든 키를 오른쪽 노드에서 왼쪽 노드로 옮긴다.
- 부모 노드에서 오른쪽 노드를 가리키는 포인터를 제거한다. 이 과정에서 부모 노드의 포인터도 업데이트 될 수 있음.
- 오른쪽 노드는 삭제한다.
'Distributed System' 카테고리의 다른 글
| Batch Processing 가이드 (0) | 2024.06.24 |
|---|---|
| 복제 (Replication) 정리 (0) | 2024.04.24 |
| 데이터베이스 소개 및 개요 (0) | 2024.04.03 |
| 분산 시스템에서 워크플로우를 관리하는 방법 (0) | 2023.11.23 |
| 분산 시스템에서 데이터를 엑세스하는 방법 (0) | 2023.11.22 |