복제 (Replication) 의 장점
- 복제 서버에서 읽기 요청을 처리할 수 있으므로 읽기 처리 능력을 향상 시킬 수 있다.
- 가까운 복제 서버에서 읽기 요청을 처리하면 되니까 지연 시간을 감소 시킬 수 있다.
- 마스터 서버가 죽더라도 복제 서버를 승격시켜서 처리할 수도 있으니 가용성을 향상 시킬 수 있다.
복제에서 어려운 점
데이터가 변경될 때 복제 서버에 변경된 내용을 반영하는 것. 만약 데이터가 한번 써진 후 변경되지 않는다고 하면 그냥 다 노드에 복사만 하면 되니까 문제 없다.
- 정리하자면 일관성 문제임. 복제 서버가 가진 데이터와 원본 서버가 가진 데이터가 일치하지 않는 거지.
이런 일관성 문제의 해결 방법은 복제 방법마다 다르다:
- 단일 리더 (Single Leader)
- 다중 리더 (Multi Leader)
- 리더 없음 (leaderless)
동기식 복제 vs 비동기식 복제
동기식 복제는 성능과 가용성을 희생시키고, 데이터의 내구성과 일관성을 얻을 수 있다. 비동기식 복제는 이 반대임.
반면 마이크로소프트의 체인 복제는 성능과 가용성을 지키면서도 데이터 유실이 없는 방법을 일부 성공시켰다고 한다.
Q) 마이크로소프트 체인 복제는 어떻게 이걸 가능하게 한건데?
체인 복제의 대략적인 매커니즘은 이렇다:
- 쓰기 요청: 클라이언트는 체인의 첫 번째 노드(Head)에 쓰기 요청을 보낸다.
- 데이터 전파: 첫 번째 노드는 요청을 받아 처리한 후, 변경된 데이터를 체인의 다음 노드로 전달한다. 이 과정은 체인의 마지막 노드(Tail)에 도달할 때까지 계속된다.
- 읽기 요청: 모든 쓰기 요청은 체인의 마지막 노드에서 처리가 완료된다. 클라이언트는 읽기 요청을 마지막 노드에 직접 보내어 최신의 데이터를 받을 수 있다.
일관성 보장:
- 이 방법의 일관성 보장은 마지막 노드에 써진 후에 읽기 처리가 된다는 점으로 일관성을 보장한다.
높은 성능 보장:
- 쓰기 요청은 체인의 각 노드를 순차적으로 통과하지만, 각 노드는 병렬로 다음 노드로 데이터를 전송할 수 있다. 이는 전체 체인을 통해 데이터가 효율적으로 흐를 수 있게 하여, 높은 처리량을 달성한다.
고가용성 보장:
- 체인의 각 노드가 실패할 경우를 대비하여, 복제된 데이터와 함께 자동 장애 복구 메커니즘이 구현된다. 이는 체인 내의 다른 노드가 실패한 노드의 역할을 신속하게 대체할 수 있도록 설계되어 있다고 함.
체인 복제 참고:
- https://engineering.fb.com/2022/05/04/data-infrastructure/delta/
- https://www.cs.cornell.edu/home/rvr/papers/OSDI04.pdf
Delta: A highly available, strongly consistent storage service using chain replication
Over the years, Meta has invested in a number of storage service offerings that cater to different use cases and workload characteristics. Along the way, we’ve aimed to reduce and converge th…
engineering.fb.com
복제 매커니즘: 리더와 팔로워
리더의 역할:
- 쓰기 요청은 리더에게만 전달됨.
- 쓰기 작업의 결과를 팔로워에게 전달하는 것. (이를 replication log 라고도 한다.)
팔로워의 역할:
- 리더의 쓰기 요청을 가져와서 따라 잡는 것.
- 읽기 요청을 처리하도록 만들 수 있음.
Q) 리더가 죽는 경우에는 어떻게 고가용성을 보장할 수 있는가?
리더가 죽는 경우 새로운 리더를 선출해야지 고가용성을 보장할 수 있음.
리더가 죽는 경우에는 다음과 같은 매커니즘을 통해서 고가용성을 보장할 수 있을 것:
- 리더의 죽음 감지: 일반적으로는 Heartbeat 를 기준으로 리더의 죽음을 감지한다.
- 새로운 리더 선출: 일반적으로는 최신 데이터를 가장 잘 따라간 팔로워를 새로운 리터로 선정한다.
- 새로운 리더에게 요청 라우팅
그리고 리더-팔로워 구조에서는 서로 자신이 리더라고 주장하는 문제인 Split Brain 문제도 해결해야한다.
Q) 비동기식 복제에서 리더가 죽는 경우에는 데이터 유실이 발생할 수 있는가?
- 리더에서 데이터를 쓸 때 팔로워도 복제를 했는지 확인하는 방법:
- 리더가 팔로워에게 데이터를 보낼 때 각 팔로워가 해당 데이터를 제대로 수신했는지 확인하는 과정을 추가하는 방법
- 데이터 변경은 일정 수의 쿼럼(Quorum) 의 수락이 있어야 한다는 방법:
- 리더 선출 및 데이터 변경 시 쿼럼을 요구하여 특정 수의 노드가 합의하도록 하여 데이터 유실을 방지하는 방법.
- 이중 쓰기(Dual Write) 또는 다중 리더 구조:
- 데이터를 여러 리더 또는 노드에 동시에 기록하여 리더가 죽더라도 다른 곳에서 데이터를 유지할 수 있도록 하는 방법.
- 강력한 일관성 모델 적용:
- 동기식 복제를 적용하는 방법
Replication Log 구현
구문 (statement) 기반 복제와 그 한계:
- 정의:
- 리더에서 데이터 조작을 하는 SQL 문 (= INSERT, DELETE, UPDATE 등) 을 팔로워에 그대로 가져와서 실행하는 방법을 말함.
- 한계점:
- 데이터 일관성이 안맞을 수 있다. NOW() 나 RAND(), AutoIncrement 같은 비결정적 함수가 있다면 리더의 데이터와 팔로워의 데이터가 다를 수 있음.
로그 기반의 복졔:
- 리더에서 팔로워로 WAL 로그를 전달해서 복제하는 것 방법을 말한다.
- 다만 저수준의 로그를 그대로 전달하느냐, 논리적인 정보로 변환된 로그를 전달하느냐의 방식에 따라서 다르다. 로그를 그대로 전달하면 팔로워가 해당 로그 포맷에 강하게 결합되기 때문에 리더와 팔로워의 소프트웨어 버전이 동일해야한다. 논리적인 정보로 변환해서 전달한다면 이런 결합이 줄어든다. 결합이 줄어들면 외부 데이터 저장소로도 데이터 변경 사항을 보내는 것도 쉽다. 이를 CDC (Change Data Capture) 라고도 한다.
트리거 기반의 복제:
- 리더의 데이터를 모두 복제하는게 아니라 데이터 복제에 유연함을 주고 싶을 때 사용하는 방식이다. (데이터의 일부만 저장한다던지)
- 유연함을 얻을 수 있지만, 트리거로 인해 데이터베이스 부하가 더 심할 수 있다는 점도 고려해야한다.
복제 지연으로 발생할 수 있는 문제 (데이터 일관성 문제)
비동기식 복제를 하면 리더와 팔로워의 데이터가 일시적으로 일치하지 않는 문제가 생긴다.
리더에 데이터를 쓴 이후에 팔로워에 반영되기 전에 데이터를 다시 읽을려는 요청을 클라이언트가 했다고 가정해보자. 클라이언트 입장에서는 데이터가 유실된 것 같은 착각을 줄 수 있다.
이런 일관성 문제를 처리하는 방법으로는 다음과 같은 것들이 있다:
- 리더에게 읽기 요청을 전달한다. + 모든 읽기 요청을 리더에게 전달하면 확장성에 문제가 생기므로, 읽기 요청을 팔로워에게 분산시킬 수 있는 방법을 고려해야한다.
- 일정 시간이 지났더라면 팔로워에게 전달한다던지.
- 복제 지연 로그 상태를 보고 리더에게 질의할지, 팔로워에게 질의할지 결정한다던지.
- Read Through, Write Through 전략을 사용하는 캐시를 쓰고 있다면 캐시에서 읽기 요청을 보내면 된다.
- 데이터베이스에 따라서 강한 일관성을 이용할 수도 있다.
- MongoDB 나 DynamoDB 는 Read 동기화 수준을 강하게 올리면 모든 최신 노드에게 데이터가 복제될 때까지 기다렸다가 응답할 수 있다.
사례로 보는 복제 일관성 문제 해결
단조 읽기 (monotonic read) 로 문제 해결:

- 이상 현상 사례:
- 데이터 A 가 리더에 쓰여지고 팔로워 1 과 팔로워 2 에게 복제된다. 팔로워 1 은 금방 동기화 되지만 팔로워 2 는 처리가 늦어지고 있는 상황이다. - 이 경우에 유저가 들어와서 조회 쿼리를 두 번 날리고 각각 팔로워 1 과 팔로워 2 에게 전달된다.
- 첫 쿼리는 팔로워1에게 전달되서 결과를 확인했다. 근데 두 번째 쿼리는 팔로워 2에게 전달되서 결과가 안보인다. 즉 유저 입장에서는 데이터가 있다가 사라지는 이상 현상을 보게된다. (e.g 게시판에 댓글이 생겼다가 사라지는 현상 등)
- 이 문제는 단조 읽기 (monotonic read) 로 해결할 수 있다:
- 일관된 복제 서버로부터 데이터를 읽어오는 걸 말함.
- 사용자 UserId 기반으로 해싱을 해서 복제 서버를 선택하던가. 이 방법을 선택하는 경우에는 해당 복제 서버가 장애가 나는 경우에 재라우팅 하는 기능이 필요하긴 함.
- 일관된 복제 서버로부터 데이터를 읽어오는 걸 말함.
Consistent Prefix Read 로 문제 해결:
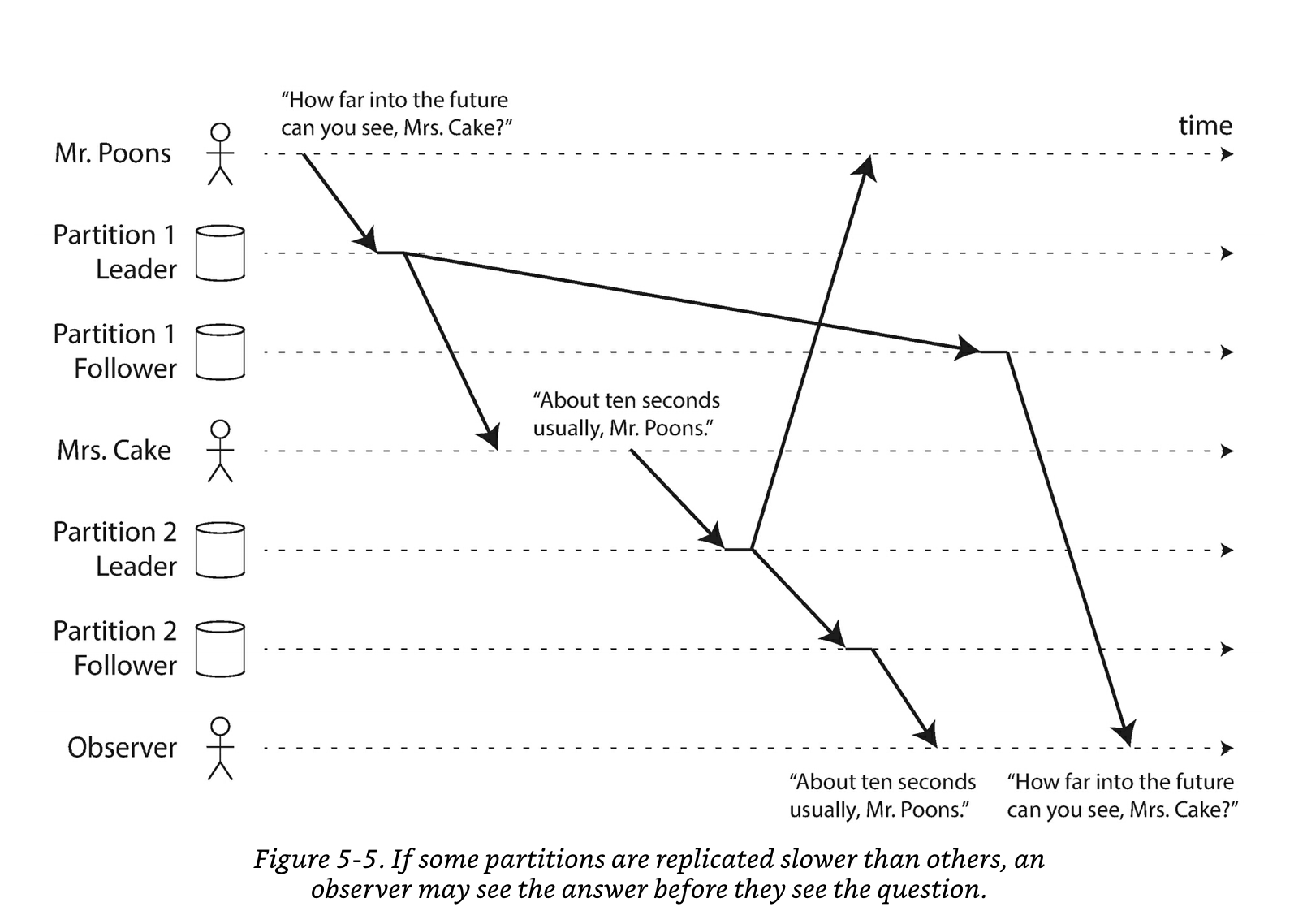
- 이상 현상 사례:
- 게시판 어플리케이션에서 샤드 1에 댓글이 먼저 달렸지만 Replica 에 지연이 생긴 상황이고, 대댓글이 샤드 2에 쓰였고 보다 빠르게 Replica 에 복제가 된 상황에서 다른 사용자가 댓글 읽기 요청을 하게되면 대댓글만 보이는 현상이 발생할 수 있다.
- 이 문제는 인과성을 줘서 읽으면 해결할 수 있다.
- 읽을 때와 쓸 때 노드의 Majority 에 복사가 되야지, 읽기와 쓰기가 성공하는 옵션을 말한다.
- 이 경우에는 대댓글이 댓글을 보고 쓸 때는 다른 사람들도 댓글을 관찰할 수 있게 된다.
다중 리더 복제
쓰기를 허용하는 리더를 더 늘리는 방식을 말한다. 결과적으로 쓰기 성능과 가용성을 얻을 수 있다.
- 다만 쓰기 충돌 문제가 발생할 수 있다.
다중 리더 복제 사례:
- 다중 데이터 센터:
- 다중 데이터 센터를 운영하는 경우에는 다중 리더를 쓰면 좋다. 하나의 데이터 센터가 무너지더라도, 다른 데이터센터에서 가용성을 보장해줄 수 있기 때문에.
- 오프라인 작업 저장소나 디바이스:
- 인터넷 연결이 끊긴 경우에도 쓰기 요청을 받을 수 있는 저장소나 휴대폰 디바이스. 인터넷 연결이 되면 이 쓰기 요청을 전송하는 식으로 사용됨.
- 협업 편집:
- 동시에 여러 사람이 편집할 수 있는 온라인 편집 어플리케이션을 만드는 경우
쓰기 충돌 문제:
- 위키 페이지 제목을 사용자 U1 과 U2 가 동시에 변경한다고 가정해보자. U1 은 A -> B 로, U2 는 A -> C 로.
- 그러면 다중 리더에서 하나의 리더의 팔로워에서는 A -> B -> C 로 변경될 것이고 다른 리더의 팔로워는 A -> C -> B 로 변경이 될 것이다.
다중 리더 복제는 무조건 비동기식 복제일 것이다:
- 다중 리더에서 쓰기 충돌을 동기식 쓰기로 변경되면 단일 리더와 차이점이 없다. 다중 리더로 하는 이유가 쓰기 성능과 가용성인데, 동기식으로 복제하면 둘 다 못얻는다.
다중 리더에서 쓰기 충돌 문제 해결 방법:
- 쓰기 충돌 회피 전략:
- 같은 키의 데이터 쓰기를 하나의 리더에게 계속 보내는 방식.
- 고려해야 하는 점으로는 내가 쓰기를 보내는 리더가 있는 데이터 센터가 고장나서 쓰기 요청이 다른 리더에게 가는 경우가 생길 수 있다는 것. 그런 경우에는 충돌이 발생할 수 있다.
- 각 리더마다 이중화를 해놓는 것도 방법일듯.
- CRDTs (Conflict-free Replicated Data Types) 를 이용해서 쓰기 충돌 데이터 병합 전략:
- CRDT는 여러 노드가 동시에 동일한 데이터에 대해 작업을 수행하더라도 자동으로 충돌 없이 일관성을 유지할 수 있음. 물론 간단한 연산이어야만 가능.
- 손실을 허용하는 경우:
- Last Wrtie Win 전략. 각 쓰기에 고유 Id (예시로는 타임스탬프) 를 부여하고 마지막 쓰기가 이기도록 하는 방법을 말함. (충돌이 발생했을 때 최신 타임스탬프가 이기는 방식으로 동작할 거다.)
- 각 복제 서버에 고유 Id 를 할당하고 높은 Id 를 가진 복제 서버가 낮은 Id 를 가진 복제 서버보다 우선적으로 적용하는 것.
다중 리더 복제 토폴로지:
- 원형 토폴로지: 노드가 원형으로 연결되어 각 노드가 다음 노드에 복제하는 방식이다. 이 토폴로지는 단순하지만, 한 노드가 고장나면 연결이 끊길 수 있어 고장에 취약약하다.
- 별 모양 토폴로지: 하나의 중심 노드(허브)가 있고 다른 모든 노드가 이 허브에 연결되는 구조이다. 중앙 노드가 고장나면 전체 시스템이 영향을 받을 수 있지만, 허브를 통해 데이터의 일관성을 유지하기 쉽다. 물론 이것 또한 허브가 단일 장애점이 될 수 있다는 문제가 있다. (허브에서만 쓰기 요청을 전달받을 수 있는 건 아님. 허브를 통해 복제가 된다라고 생각하면 된다.)
- 전체 연결 토폴로지: 모든 노드가 서로 직접 연결된 구조이다. 이 토폴로지는 가장 복잡하지만, 하나의 노드가 고장나도 다른 노드 간의 연결이 유지되기 때문에 고장에 대한 내성이 높다.
- 전체 연결 토폴로지는 "추월" 문제가 발생할 수 있다.
- 추월이란 하나의 리더에 데이터가 INSERT 된 이후 다른 리더에는 복제가 되었지만 또 다른 리더가 복제가 되지 않은 상황에서 이 데이터가 UPDATE 되면 어떤 리더에서는 INSERT -> UPDATE 순으로 적용이 되지만 다른 리더에는 UPDATE -> INSERT 되는 식으로 순서가 역전되는 현상을 말한다.
리더 없는 복제
리더가 없이 모든 복제 시스템이 쓰기 요청을 받는 식의 데이터베이스 스타일을 리더 없는 복제 또는 Dynamo 스타일의 데이터베이스라고 한다.
일부 리더가 없는 복제 스타일의 데이터베이스는 클라이언트가 모든 복제 노드에 쓰기를 직접 전송하는 대신 이 쓰기들을 여러 복제하는 방식은 코디네이터 노드 (Coordinator node) 가 수행하기도 한다. 그러니까 코디네이터에게 쓰기 요청을 보내도 되는 경우가 있고, 직접 데이터베이스 노드와 통신해서 쓰기 요청을 보내도 되는 경우가 있다.
- AWS DynamoDB 는 클라이언트는 코디네이터를 거치지 않고 직접 테이블에 쓰기 요청을 보내면 된다. 복제와 동기화는 내부적으로 처리되므로. DynamoDB는 테이블 데이터를 파티션으로 나누고, 각 파티션은 여러 복제본을 가지는 식으로 동작함.
- Apache Cassandra 는 클라이언트는 코디네이터 노드에 요청을 보내야하며, 코디네이터는 지정된 일관성 레벨에 따라 복제를 처리한다. 그러면 코디네이터는 해당 요청을 적절한 복제 노드에 전달하고 관리한다.
리더 없는 복제의 문제점: 노드가 다운되었을 때
세 개의 복제 서버가 있다고 가정해보자. 데이터 쓰기를 잘 처리하다가 그 중 하나의 노드가 다운되었다. 그리고 다운타임동안 해당 데이터는 수정되었고, 이후 다운되었던 노드가 돌아왔다.
이 상황에서 읽기 요청이 살아서 돌아온 노드에게 향하게 된다면 오래된 데이터 (outdated) 를 읽는 문제가 발생할 수 있다.
이 문제는 데이터에 Versioning 해놓고, 여러 노드에다가 한번에 질의해서 데이터를 가져오는 식으로 해결해볼 수 있다. 이를 읽기 복구 (Read Repair) 라고 함.
리더 없는 복제에서 일관성을 보장하는 방법: 정족수 (Quorum)
w (쓰기 노드 정족수) + r (읽기 노드 정족수) > n (노드의 수) 을 넘도록 만들면 강한 일관성을 보장할 수 있다:
- 세 개의 노드에서 최소 2개의 노드에 데이터가 써짐을 보장하고 읽을 때 최소 2개의 노드에서 데이터를 가져와서 읽도록 한다면 강한 일관성을 보장할 수 있지 않겠는가. 이런 방법이다.
- w + r 이 n 보다 크게 되면 항상 최신 데이터를 가지는 노드는 요청에 있을거니까 이렇게 일관성을 보장할 거라고 예상할 수 있다.
w + r > n 을 보장하더라도 강한 일관성을 보장하지 못하는 엣지 케이스가 있다:
- 위의 예시 기준으로 갑자기 2대의 노드가 죽은 후 새로운 노드가 추가되는 상황에서는 강한 일관성을 보장 못함.
- 쓰기와 읽기가 거의 동시에 발생하는 경우에도 타이밍 이슈 때문에 최신 데이터를 읽지 못할 것. (그러니까 아래의 이미지를 보면 됨.)
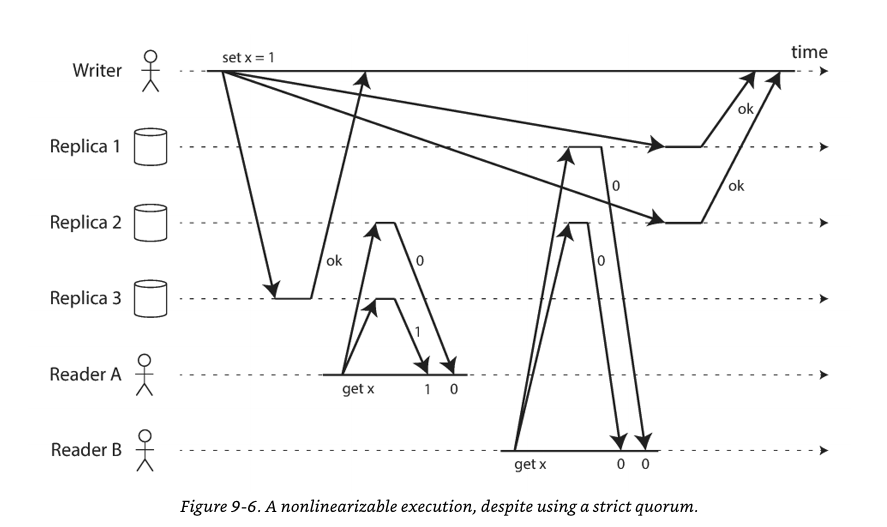
리더 없는 복제의 사용 방법: 느슨한 정족수
읽기 요청이나 쓰기 요청에서 정족수를 구성하면 생기는 단점은 가용성과 지연 시간이다.
- 정족수란 읽기 요청을 성공하기 위해서 최소 2개의 노드에서 데이터를 읽어와야한다. 뭐 이런거임.
정족수에 가용성을 부가하는 방법이 느슨한 정족수임:
- 노드의 일부가 잠시 연결이 안되거나 다운되었을 때 정족수를 구성하는 수보다 노드가 적게 살아남았다면 가용성을 잃게 된다. 이게 싫으면 살아 있는 노드 끼리라도 요청을 처리할 수 있도록 하면 됨. 이게 느슨한 정족수.
느슨한 정족수를 할 경우 생기는 문제점:
- 일관성 보장:
- W + R > N 을 보장하더라도 최신 데이터 읽기는 실패할 수 있음.
- 데이터 무결성 문제가 생김:
- 느슨한 정족수를 구성하는 동안에 쓰기 요청을 받았지만 그 노드가 죽는다면 쓰기 요청은 유실된다. 즉 데이터 쓰기는 성공했지만 유실은 발생한 무결성 문제가 발생한다.
리더 없는 복제의 쓰기 충돌 문제
다중 리더 복제와 마찬가지로 다이나모 스타일의 데이터베이스에서도 쓰기 충돌 문제가 생길 수 있다. 동일한 키에 데이터를 쓰는 것을 막지 않으므로
예시: 노드 1,2,3 이 있고 클라이언트 A 와 B 가 있다고 가정해보자.
- 클라이언트 A 가 노드 1, 2, 3 에 차례대로 데이터 X 에 대한 쓰기 요청 Y을 보낸다.
- 클라이언트 B 가 노드 1, 2, 3 에 차례대로 데이터 X 에 대한 쓰기 요청 Z 을 보낸다.
- 어떤 노드가 먼저 데이터를 처리할 지 알 수 없다. 네트워크 이슈라던지, 일시적인 장애로 인해서.
- 즉 노드 1 는 Y -> Z 처리가 될 수 있는것이고, 노드 2 는 Z -> Y 처리가 될 수 있는 것이다. (일관성 문제 발생
쓰기 충돌 해소 전략: 최종 쓰기 승리
- Last Write Win 방식을 여기서도 도입할 수 있다. Apache Cassandra 는 이 방식을 사용한다.
Last Write Win 방식의 변형: 키를 고유하게 만들어서 쓰기 충돌이 발생하지 않도록 하기
- 충돌 없이 쓰기 위해서 키를 고유한 값으로 만들고 한번만 쓰는 것이다. 즉 동시에 업데이트하는 가능성을 줄이는 것이다.
- 키를 고유하게 만들기 위해서 UUID 같은 것들을 이용한다.
- 이 방법은 이벤트 소싱과 같은 매커니즘에서 적용할 수 있음.
Apache Cassandra 에서 키를 고유하게 만들어서 이벤트 소싱을 적용하는 예시:
- Apache Cassandra 에서는 파티션 키를 각 도메인의 아이디로 설정하고, 클러스터링 키로 타임 스탬프와 UUID 값을 이용해서 설정하면 된다.
- 파티션 키:
- 파티션 키는 Cassandra에서 데이터가 저장될 노드를 결정하는 데 사용된다. 데이터는 파티션 키를 기준으로 여러 노드에 분산된다.
- 파티션 키는 동일한 값을 갖는 레코드가 동일한 파티션에 저장된다. 이로 인해 데이터 조회 시 특정 파티션에 대한 요청이 가능하며, 데이터를 빠르게 찾을 수 있다.
- 파티션 키는 단일 컬럼으로 구성되기도 하고, 여러 컬럼을 조합하여 복합 파티션 키를 구성할 수 있다.
- 클러스터링 키:
- 클러스터링 키는 파티션 내에서 데이터를 정렬하는 데 사용된다.
- 파티션 키로 특정 파티션을 결정한 후, 클러스터링 키에 따라 데이터를 순서대로 조회할 수 있다.
- 클러스터링 키를 사용하여 파티션 내에서 추가적인 정렬과 쿼리를 수행할 수 있다. 클러스터링 키를 사용하여 시간순, 알파벳순, 또는 기타 방식으로 데이터를 정렬하게 된다.
- 여러 컬럼을 사용하여 복합 클러스터링 키를 구성할 수 있다.
- 파티션 키:
- 테이블 스키마 설계: 이벤트 소싱을 위한 테이블 스키마를 설계할 때, 파티션 키와 클러스터링 키를 적절히 사용해야한다. 예를 들어, 고객의 주문 이벤트를 저장하는 경우, 파티션 키로 고객 ID를 사용하고, 클러스터링 키로 UUID 와 타임스탬프를 사용하면 된다.
- 이벤트 조회: 특정 데이터의 모든 이벤트를 조회하려면, 파티션 키를 기준으로 클러스터링 키 순서대로 정렬된 이벤트를 읽어오면 된다.
다중 리더와 리더 없는 복제 비교
다중 리더 방식 (Multi-Leader Replication):
- 가용성: 다중 리더 시스템은 여러 노드가 리더 역할을 하므로, 한 리더 노드가 고장나더라도 다른 리더가 쓰기 및 읽기 요청을 처리할 수 있다. 이는 가용성을 높인다.
- 성능: 다중 리더는 각 리더가 독립적으로 쓰기 요청을 처리할 수 있으므로, 부하가 분산되어 성능을 향상할 수 있따. 그러나 리더 간의 데이터 동기화가 필요한 경우 성능에 영향을 미칠 수 있다.
- 확장성: 다중 리더 시스템은 새로운 리더 노드를 추가하여 확장할 수 있다. 그러나 리더 간 동기화가 복잡해지면서 확장성에 영향을 줄 수 있다.
- 일관성: 다중 리더 시스템은 리더 간의 복제 및 일관성을 유지하는 데 주의가 필요하다. 리더 간 충돌이 발생할 수 있으며, 데이터 일관성을 보장하기 위해 추가적인 메커니즘이 필요하다.
리더 없는 복제 (Leaderless Replication):
- 가용성: 리더 없는 복제 방식은 노드 간에 특정 리더 역할이 없으므로, 한 노드가 고장나도 다른 노드가 쓰기 및 읽기 요청을 처리할 수 있다. 이로 인해 높은 가용성을 제공하는게 가능하다.
- 성능: 리더 없이 모든 노드가 쓰기 및 읽기를 처리할 수 있으므로, 부하가 더 잘 분산된다. 리더 간 동기화가 필요하지 않아 성능이 향상될 수 있다.
- 확장성: 리더 없는 복제 방식은 새로운 노드를 쉽게 추가할 수 있으므로 확장성이 높다. 노드 간 복제가 자동으로 이루어져 확장 시 부담이 적다.
- 일관성: 리더 없는 복제 방식은 일관성을 유지하기 위한 다양한 전략이 필요하다. 데이터 복제가 비동기적으로 이루어지므로, 일관성을 보장하려면 추가적인 메커니즘이나 일관성 레벨을 설정해야 한다.
비교:
- 가용성: 두 방식 모두 고장에 대한 내성이 높지만, 리더 없는 복제 방식이 더 높은 가용성을 제공할 수 있다.
- 성능: 다중 리더 방식은 리더 간 동기화가 필요한 반면, 리더 없는 복제 방식은 각 노드가 독립적으로 작동하므로 더 나은 성능을 제공할 수 있다.
- 확장성: 리더 없는 복제 방식은 확장에 대한 부담이 적고, 새로운 노드를 쉽게 추가할 수 있다.
- 일관성: 다중 리더 방식은 리더 간 동기화가 필요하여 일관성을 유지하기 더 쉬울 수 있지만, 리더 없는 복제 방식은 비동기적이기 때문에 일관성을 보장하려면 추가적인 전략이 필요하다.
- 물론 다중 리더 방식도 강한 일관성을 보장하기 힘들다. 가능하긴하다.
Referecnes
'Distributed System' 카테고리의 다른 글
| Batch Processing 가이드 (0) | 2024.06.24 |
|---|---|
| B-Tree 개요 (0) | 2024.04.05 |
| 데이터베이스 소개 및 개요 (0) | 2024.04.03 |
| 분산 시스템에서 워크플로우를 관리하는 방법 (0) | 2023.11.23 |
| 분산 시스템에서 데이터를 엑세스하는 방법 (0) | 2023.11.22 |