이 글은 Apache Flink™: Stream and Batch Processing in a Single Engine 을 참고해서 작성한 글입니다.
Apache Flink는 스트리밍 데이터와 배치 데이터를 처리하기 위한 오픈 소스 시스템입니다.
Flink는 다양한 데이터 처리 응용 프로그램(e.g 실시간 분석, 연속 데이터 파이프라인, 배치 처리, 반복 알고리즘(머신러닝, 그래프 분석))이 모두 파이프라인 방식의 내결함성 데이터플로우로 표현되고 실행될 수 있다는 철학을 바탕으로 구축되었습니다.
이 논문에서는 Flink의 아키텍처를 소개하고, 다양한 사용 사례를 단일 실행 모델 하에서 어떻게 통합할 수 있는지 설명합니다.
1. Introduciton
데이터 처리 방식은 크게 두 가지 방식이 있습니다:
- 1. 데이터 스트림 처리(Data-stream processing): 이는 복잡한 이벤트 처리 시스템(complex event processing systems)을 예로 들 수 있습니다. 데이터 스트림 처리는 실시간으로 데이터를 처리하는 방식으로, 데이터가 생성되는 즉시 분석하고 대응합니다. 예를 들어, 실시간 트래픽 모니터링이나 금융 거래 처리 같은 분야에서 활용됩니다.
- 2. 정적(배치) 데이터 처리(Static (batch) data processing): 배치 데이터 처리는 데이터를 미리 저장해 두고, 이를 일괄적으로 처리하는 방식입니다. 대량의 데이터를 분석할 때 주로 사용되며, 분석 결과가 실시간으로 필요하지 않은 경우에 적합합니다. Hadoop을 비롯해 Apache Spark와 Apache Drill과 같은 실행 엔진이 사용됩니다.
현재 많은 데이터 처리 시스템이 데이터의 연속적이고 시간에 민감한 특성을 무시하고, 데이터를 정적인 배치로 처리하는 방식으로 처리하고 있습니다:
- 스트림을 스트림으로 처리하지 않음: 데이터 스트림은 연속적으로 생성되고, 이론적으로는 끊임없이 흐르는 데이터의 연속체입니다. 예를 들어, 소셜 미디어 플랫폼에서의 사용자 활동, 온라인 거래, 센서 데이터 등이 이에 해당합니다. 이 데이터는 생성되는 즉시 실시간으로 분석하고 대응하는 것이 이상적입니다. 하지만 많은 시스템들이 이러한 연속성을 고려하지 않고 데이터를 다룹니다.
- 데이터 레코드의 인위적 배치: 실시간 데이터를 실제로는 '인위적으로' 구분된 배치로 나눕니다. 예를 들어, 한 시간, 하루 또는 한 달 단위로 데이터를 나누어 처리할 수 있습니다. 이렇게 하면 각 배치는 독립적인 정적 데이터 세트로 간주되며, 시간의 흐름을 고려하지 않고 처리됩니다. 즉, 데이터가 생성된 시점이나 순서가 처리 과정에서 중요한 요소로 고려되지 않습니다. 이는 처리 과정을 단순화할 수 있지만, 실시간으로 발생하는 현상이나 이벤트에 신속하게 대응하는 데는 한계가 있습니다.
기존의 데이터 처리 아키텍처인 Lambda Architecture 의 문제점:
- 배치 프로세스로 인한 높은 지연시간
- 정확하지 않은 스트림 처리
- 시스템의 높은 복잡도를 유발할 수 있음. 그 중에 하나가 비즈니스 로직이 스트림과 배치 두 곳에 있는 것.
- Time dimension 에 대해 고려되지 않음.
Lambda Architecture 의 문제점을 해결한 Kappa 아키텍처 소개:
- Kappa 아키텍처는 Lambda 아키텍처의 복잡성과 데이터 일관성 문제를 해결하기 위해 제안된 데이터 처리 아키텍처입니다.
- Lambda 아키텍처에서 발생하는 주요 문제 중 하나는 두 가지 별도의 데이터 처리 경로(배치 레이어와 스피드 레이어)를 유지해야 한다는 것인데 이는 중복된 로직과 데이터 관리의 복잡성을 초래하며, 결과적으로 데이터 일관성 문제를 야기할 수 있습니다.
- 단일 처리 레이어: Kappa 아키텍처는 모든 데이터 처리를 하나의 스트림 처리 시스템을 통해 처리하는 방식을 채택합니다. 이는 실시간 데이터 스트림과 대규모 데이터 세트를 동일한 로직으로 처리할 수 있게 함으로써, 아키텍처를 단순화하고 개발 및 유지 보수의 효율성을 높입니다.
- 시간 차원의 통합 관리: 스트림 처리 엔진을 사용함으로써, Kappa 아키텍처는 데이터의 시간 차원을 효과적으로 관리할 수 있습니다. 이는 실시간 데이터 분석뿐만 아니라, 과거 데이터 재처리(reprocessing)에도 동일한 로직을 적용할 수 있게 합니다.
- 확장성과 유연성: 스트림 처리 엔진의 활용은 높은 처리량과 낮은 지연 시간을 요구하는 대규모 시스템에서 확장성과 유연성을 제공합니다. 데이터가 변경되거나 업데이트가 필요한 경우, 전체 시스템을 중단하지 않고도 로직을 쉽게 수정하고 재배포할 수 있습니다.
Kappa 아키텍처의 구현 기술로 Apache Flink 소개:
- Flink는 데이터 스트림 처리를 실시간 분석, 연속적인 스트림, 그리고 배치 처리를 아우르는 통일된 모델로 채택하고 있습니다.
- 이는 프로그래밍 모델과 실행 엔진 모두에 적용됩니다. 그리고 Flink는 Apache Kafka나 Amazon Kinesis와 같은 내구성 있는 메시지 큐와 함께 사용되어 데이터 스트림의 사실상 임의적인 재생을 가능하게 합니다.
- 주요 특징은 다음과 같습니다:
- 통일된 데이터 스트림 처리 모델: Flink는 실시간 이벤트 처리, 주기적인 대규모 데이터 집계, 역사적 데이터의 처리를 구분하지 않고 통합적으로 접근합니다. 이는 모든 데이터 처리를 연속적인 스트림으로 간주하며, 다양한 유형의 계산이 단순히 내구성 있는 스트림의 다른 지점에서 처리를 시작한다는 개념입니다.
- 상태 관리: 각기 다른 종류의 계산은 계산 도중 다른 형태의 상태를 유지합니다. 이는 Flink가 스트림을 처리하면서 필요한 데이터를 저장하고 관리할 수 있다는 것을 의미합니다. 상태 관리는 Flink의 처리 과정에서 중요한 역할을 합니다.
- 윈도잉 메커니즘: Flink는 매우 유연한 윈도잉(데이터를 일정 시간 혹은 조건에 따라 구분하는 기능) 메커니즘을 제공합니다. 이를 통해 초기에 근사치 결과를 계산하거나, 지연되어 정확한 결과를 도출하는 등 다양한 시나리오에서 결과를 산출할 수 있습니다. 이는 배치 처리 시스템과 실시간 처리 시스템을 따로 운영할 필요가 없다는 것을 의미합니다.
- 시간 개념의 지원: Flink는 이벤트 시간(event-time), 수집 시간(ingestion-time), 처리 시간(processing-time) 등 다양한 시간 개념을 지원합니다. 이는 프로그래머가 이벤트 간의 상관 관계를 정의할 때 높은 유연성을 가질 수 있도록 해줍니다. 각각의 시간 개념은 데이터가 발생하고 처리되는 시점을 다르게 해석하여, 보다 정확하고 유용한 데이터 처리를 가능하게 합니다.
1. Q & A
Q) Time Dimension 이 무엇인가?
데이터가 생성, 수정, 접근되는 시점과 관련된 정보를 의미합니다.
시간 차원을 충분히 고려한 시스템은 데이터가 발생한 시간 (event time) 이나, 데이터가 처리되는 시간 (processing time) 이나, 데이터가 소비된 시간 (ingestion time) 을 기반으로 잘 처리할 수 있습니다.
Q) 람다 아키텍처에서 배치 레이어를 준 이유는 스트림 처리가 실패했을 경우를 대비하기 위해서 였는가?
스트림 처리의 실패를 대비하기 위한 것도 있지만, 주된 목적은 더 큰 범위에서 데이터 처리를 보완하고, 정확성을 확보하기 위한 것입니다.
이 레이어는 실시간으로 데이터를 처리하여 빠른 피드백과 결과를 제공하는 것을 목표로 합니다.
데이터 스트림이 들어오는 대로 빠르게 처리하며, 주로 시간에 민감한 애플리케이션에 사용됩니다.
이 레이어의 처리 결과는 완전하지 않을 수 있으며, 일시적인 오류 또는 근사치를 포함할 수 있습니다.
Q) 람다 아키텍처에서 스트림 처리는 데이터의 정확한 처리를 제공하지 못할 수 있다고도 했는데 이 이유는 람다 아키텍처에서 사용하는 스트림 서비스는 Apache Flink 처럼 상태 정보나 체크포인트 같은 정보를 저장하지 못하기 때문이야?
맞습니다.
Q) 실무에서는 Kappa 아키텍처로 어떻게 사용해?
Apache Kafka + Apache Flink 조합으로 이용합니다.
Kafka에서 스트림 데이터를 관리하고, Flink에서 실시간으로 데이터를 처리하면서 실패한 작업에 대한 재처리를 지원합니다.
즉 Kafka는 데이터의 내구성을 보장하며, Flink는 처리 로직과 상태 관리를 통해 필요 시 재처리를 수행할 수 있습니다
Q) 왜 Kafka 와 Flink 를 함께 사용하는가?
- 데이터 버퍼링과 저장: Kafka는 높은 처리량을 지원하는 분산 메시징 시스템으로, 대량의 데이터를 신뢰성 있게 저장하고, 여러 소비자에게 데이터를 전달할 수 있습니다. Kafka는 데이터를 불변의 로그 형태로 저장하여 여러 스트림 처리 시스템이 데이터를 동시에 읽을 수 있게 해주며, 재처리가 필요할 때 원본 데이터에 다시 액세스할 수 있는 기능을 제공합니다.
- 실시간 스트림 처리: Flink는 이벤트 기반의 스트림 처리에 특화된 프레임워크로, 복잡한 이벤트 처리, 실시간 분석, 그리고 지속적인 데이터 처리와 같은 기능을 제공합니다. Flink는 Kafka로부터 데이터를 읽어 실시간으로 처리하고, 처리 결과를 다시 Kafka로 보낼 수 있습니다.
- 유연성과 확장성: Kafka와 Flink의 조합은 높은 확장성과 유연성을 제공합니다. Kafka는 데이터를 관리하고, Flink는 복잡한 처리 로직을 수행하는데, 이 두 시스템 모두 클러스터 환경에서 쉽게 확장할 수 있어 대규모 데이터 처리 요구사항을 충족시킬 수 있습니다.
- 내결함성과 데이터 일관성: Flink는 상태 관리 및 체크포인트를 통한 내결함성 기능을 제공합니다. 데이터 처리 중 문제가 발생하더라도 마지막 체크포인트에서부터 재시작할 수 있으며, Kafka의 데이터 로그는 이러한 복구를 지원하는 데 핵심적인 역할을 합니다.
Q) Kafka + Flink 조합에서 Kafka 의 데이터들은 일시적으로만 저장이 가능하니까 필요하면 영속성 스토로지도 사용하겠네?
맞습니다.
Flink 와 Kafka 외에도 데이터 웨어하우스, 빅데이터 스토리지 시스템(예: HDFS, Amazon S3 등)을 포함하는 복합 데이터 처리 아키텍처를 구성할 수 있습니다.
Q) Apache Flink 의 데이터 스트림의 임의적인 재생은 뭐지? 원한다면 특정 데이터부터 다시 재생을 해서 스트림 처리를 할 수 있다는건가?
맞습니다.
Q) Apache Flink 의 윈도우 매커니즘으로 필요하다면 하루동안의 데이터들을 모아서 처리하는 것도 가능하다는거임?
맞습니다.
Apache Flink의 윈도우 매커니즘은 유연해서 다양한 크기와 길이의 데이터를 모아 처리할 수 있습니다. 하루 동안의 데이터를 모아서 처리하는 것도 가능하며, 이를 통해 일별 요약, 통계, 분석 등을 수행할 수 있습니다
Flink에서 윈도우를 설정하는 방법은 다음과 같습니다:
- 시간 기반 윈도우 (Time Windows): 특정 시간 동안 수집된 데이터를 기반으로 윈도우를 설정합니다. 예를 들어, Tumbling Window는 지정된 시간 동안 데이터를 모으고, 그 시간이 지나면 윈도우를 닫고 결과를 출력합니다. 하루 동안의 데이터를 처리하려면 24시간 길이의 Tumbling Window를 설정할 수 있습니다.
- 카운트 기반 윈도우 (Count Windows): 특정 수의 데이터 이벤트를 기반으로 윈도우를 설정합니다. 이 방법은 시간보다는 이벤트의 수가 중요할 때 사용됩니다.
- 세션 기반 윈도우 (Session Windows): 활동 사이에 일정 시간 간격이 없을 때 데이터를 하나의 세션으로 그룹화합니다. 이는 사용자 세션 분석 등에 유용할 수 있습니다.
- 슬라이딩 윈도우 (Sliding Windows): Tumbling Window와 비슷하지만, 윈도우가 중첩되어 슬라이드합니다. 예를 들어, 24시간 윈도우를 1시간마다 슬라이드시키면 매시간마다 지난 24시간 동안의 데이터를 분석할 수 있습니다.
Flink의 윈도우 매커니즘은 또한 다양한 시간 개념을 지원합니다:
- 이벤트 시간 (Event Time): 데이터에 포함된 타임스탬프를 기준으로 윈도우를 처리합니다.
- 수집 시간 (Ingestion Time): 데이터가 Flink로 입력되는 시간을 기준으로 윈도우를 처리합니다.
- 처리 시간 (Processing Time): 윈도우 연산이 실행되는 시간을 기준으로 처리합니다.
2. System Architecture
Apache Flink의 시스템 아키텍처에 대해 설명합니다.
Flink의 아키텍처는 소프트웨어 스택과 분산 시스템으로 구성되며, 다양한 배포 옵션과 핵심 구성 요소들을 포함합니다.
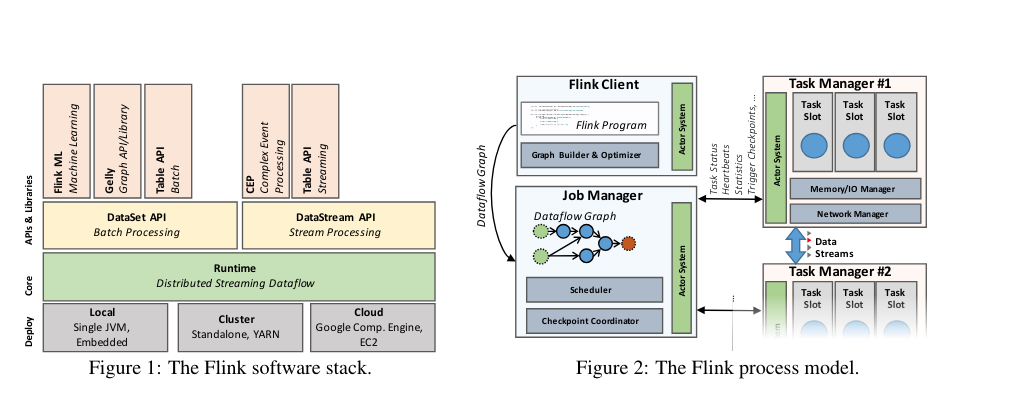
배포, 핵심, API, 라이브러리 (Deployment, Core, APIs, Libraries):
- Flink의 소프트웨어 스택은 배포, 핵심, API, 라이브러리의 네 가지 주요 레이어로 구성됩니다.
Flink의 런타임과 API (Flink's Runtime and APIs):
- Flink의 핵심은 분산 데이터플로우 엔진으로, 데이터플로우 프로그램을 실행합니다.
- Flink 에서는 두 가지 주요 API가 있습니다:
- DataSet API: 유한한 데이터 집합을 처리하는 데 사용되며, 주로 배치 처리에 사용됩니다.
- DataStream API: 무한할 수 있는 데이터 스트림을 처리하는 데 사용되며, 주로 스트림 처리에 사용됩니다.
- Flink의 런타임 엔진은 스트리밍 데이터플로우 엔진으로 볼 수 있으며, DataSet과 DataStream API는 모두 이 엔진을 실행합니다.
Flink 소프트웨어 스택 (Flink Software Stack):
- DataSet API: 배치 처리용 API로, 유한한 데이터 세트를 처리합니다.
- DataStream API: 스트림 처리용 API로, 잠재적으로 무한한 데이터 스트림을 처리합니다.
- Runtime: 분산 스트리밍 데이터플로우 엔진으로, 데이터플로우 프로그램을 실행합니다.
- Deployment Options:
- 로컬 (Local): 단일 JVM에서 실행.
- 클러스터 (Cluster): 독립형 또는 YARN에서 실행.
- 클라우드 (Cloud): Google Compute Engine, Amazon EC2 등에서 실행.
- Libraries:
- FlinkML: 머신 러닝 라이브러리.
- Gelly: 그래프 처리 라이브러리.
- Table API: SQL과 유사한 연산을 지원하는 API.
- CEP: 복잡 이벤트 처리 라이브러리.
- Deployment Options:
Flink 클러스터의 구성 (Flink Cluster Components):
- Flink 클러스터는 클라이언트, 잡 매니저, 태스크 매니저의 세 가지 프로세스로 구성됩니다:
- 클라이언트 (Client): 프로그램 코드를 가져와 데이터플로우 그래프로 변환하고 잡 매니저에 제출합니다.
- 잡 매니저 (Job Manager): 데이터플로우의 분산 실행을 조정합니다. 연산자와 스트림의 상태 및 진행 상황을 추적하고 새로운 연산자를 스케줄링하며 체크포인트와 복구를 조정합니다.
- 태스크 매니저 (Task Manager): 실제 데이터 처리가 이루어지는 곳으로, 연산자를 실행하고 스트림을 생성합니다. 태스크 매니저는 잡 매니저에게 상태를 보고하며, 버퍼 풀을 유지하고 네트워크 연결을 관리합니다.
데이터플로우 그래프 (Dataflow Graph):
- 모든 Flink 프로그램은 최종적으로 데이터플로우 그래프로 컴파일됩니다. 데이터플로우 그래프는 연산자와 데이터 스트림으로 구성된 방향성 비순환 그래프(DAG)입니다.
Flink의 유연성 (Flink’s Flexibility):
- Flink는 스트리밍과 배치 처리 모두를 지원하는 유연한 플랫폼입니다.
- 스트리밍 데이터플로우 엔진은 스트리밍, 배치, 반복 및 대화형 분석을 단일 실행 모델로 통합합니다.
2. Q & A
Q) Flink 프로그램이 실제 코드부터 실행까지의 과정은?
Step 1: Writing the Code:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> dataStream = env.socketTextStream("localhost", 9092);
DataStream<String> processedStream = dataStream
.flatMap((String value, Collector<String> out) -> {
for(String word : value.split(" ")) {
out.collect(word);
}
})
.returns(Types.STRING)
.map(String::toUpperCase)
.returns(Types.STRING);
processedStream.print();
Step 2: Creating the Dataflow Graph
- Flink 프로그램을 실행시킬 때 High-level 의 코드들은 자동적으로 번역되서 Dataflow Graph 로 표현됩니다.
Step 3: Submitting the Job
- Client 는 Dataflow 로 구성된 Graph 를 Job Manager 에게 제출하면 됩니다.
- 그러면 Job Manager 는 이들을 실행해줍니다.
Step 4: Job Distribution and Execution
- Job Manager Functions:
- Scheduling: JobManager 는 TaskManager 에게 잡얼 분배할 스케줄을 계획합니다.
- Fault Tolerance: 실행 중에 실패가 발생하더라도 복구할 수 있도록 Checkpoint 메커니즘을 주기적으로 실행합니다.
- Coordination: 작업 사이의 현재 처리 과정을 추적할 수 있도록 합니다.
- Task Managers:
- Execution: 각각의 테스크 매너지는 자신이 받은 테스크들을 처리합니다. 테스크들은 이전에 작성한 프로그램의 map, filter, flatmap 과 같은 연산들입니다.
- Resource Management: 테스크 매니저는 다른 Task Manager 로 데이터를 exhange 할 수 있도록 버퍼를 관리하는 역할도 합니다.
Step 5: Monitoring and Management
- Monitoring: 실행 중에 Flink 대시보드를 사용하여 작업 진행 상황을 모니터링하고, 작동 중인 데이터 흐름 그래프를 시각화하고, 처리량 및 대기 시간과 같은 지표들을 확인할 수 있습니다.
- Management: 실패와 같은 문제가 있는 경우 작업 관리자는 마지막으로 성공한 체크포인트부터 작업을 다시 시작할 수 있습니다.
Q) Flink 에서 생성된 그래프는 어떻게 표현디지? 파일 형식으로 구성되어 있는건가?
아니다.
Flink 프로그램을 작성하고 실행하면 Flink의 클라이언트 구성 요소가 상위 수준 코드를 구문 분석하고 자동으로 데이터 흐름 그래프를 구성하는데 이 그래프는 Flink 런타임 환경 내에서 프로그래밍 방식으로 구축됩니다.
그래프 자체는 파일이 아니지만 Flink는 작업을 실행하면 Dataflow 그래프를 웹 UI 내에서 이 그래프를 시각해서 볼 수 있다.
Q) TaskManager의 버퍼 풀은 스트림 작업 중 상태를 저장하기 위한 메모리로 사용되는건가?
TaskManager의 버퍼 풀은 주로 네트워크 버퍼를 관리하는 데 사용됩니다.
이는 클러스터 내에서 다른 작업자나 태스크 간에 데이터 스트림을 주고받을 때 나가는 데이터와 들어오는 데이터를 버퍼링하기 위해 할당된 메모리 세그먼트입니다.
데이터플로우가 실행되는 동안, 데이터는 다른 TaskManager에서 실행 중인 다양한 태스크 간에 전송되어야 합니다. 버퍼 풀은 데이터가
네트워크를 통해 다른 태스크로 전송되기 전이나 다른 태스크로부터 수신되기 전에 데이터를 임시로 저장합니다.
또 다른 기능으로 버퍼 풀은 백프레셔 관리에서도 중요한 역할을 합니다. 다운스트림 태스크가 데이터를 처리하는 속도가 느리면 버퍼가 차기 시작하며, 이는 업스트림 태스크에게 데이터를 천천히 전송하도록 신호를 보내 시스템 과부하를 방지합니다.
Q) Flink 에서 상태는 처음에는 메모리에 저장되고 주기적으로 내결함성 시스템으로 저장되는 건가?
맞습니다.
그리고 Flink는 상태를 저장할 수 있는 다양한 상태 백엔드 옵션을 제공합니다:
- 메모리 상태 백엔드(On-Heap): 이 백엔드는 JVM 힙 메모리 내에 상태를 저장합니다. 가볍고 매우 빠르지만, 사용 가능한 메모리의 양에 의해 제한되며, 큰 상태 크기에는 적합하지 않습니다. JVM 가비지 컬렉터 성능 문제를 초래할 수 있기 때문입니다.
- FsStateBackend(Off-Heap): 이 백엔드는 상태를 JVM 힙의 객체로 저장하지만 체크포인트를 파일 시스템(로컬 또는 분산)에 씁니다. 실제 상태 크기는 사용 가능한 디스크 공간에 의해서만 제한됩니다.
- RocksDBStateBackend: 이 오프 힙 상태 백엔드는 상태를 C++로 작성된 임베디드 키-값 저장 엔진인 RocksDB에 저장합니다. 이 백엔드는 매우 큰 상태에 적합하며, 증분 체크포인트를 지원합니다.
Q) Task Manager는 여러 Task Manager와 상호작용하면서 실행되는건가? 아니면 하나의 Task Manager가 모든 태스크를 실행하는건가?
여러 Task Manager 와 협력하면서 실행됩니다.
즉 Task Manager는 대규모 데이터 처리 작업을 효율적으로 처리하기 위해 분산 환경에서 협력하도록 설계되었습니다.
Flink 클러스터의 각 Task Manager는 작업의 일부 태스크를 실행하는 역할을 합니다. Flink에서 태스크는 보통 데이터플로우 그래프의 하나의 연산(예: map, reduce, filter 연산)에 해당합니다.
그리고 Flink 는 병렬성을 가지고 있는데 병렬성은 태스크의 병렬 인스턴스가 몇 개 실행되는지를 정의합니다. 이는 작업별로 또는 Flink 클러스터 전체에 대해 설정할 수 있습니다. 작업의 병렬성이 1보다 높게 설정되면, Flink는 이러한 태스크를 여러 Task Manager에 분배합니다.
Q) Task Manager를 EC2와 같은 것으로 간주하면 되는건가? 그리고 Task Manager는 Job A의 태스크 하나와 Job B의 태스크 하나를 동시에 처리할 수 있는건가?
맞습니다.
Apache Flink의 Task Manager를 Amazon Web Services (AWS)의 EC2 인스턴스와 역할 면에서 비교할 수 있습니다 둘 다 워크로드를 실행하는 서버로서 기능합니다.
3. The Common Fabric: Streaming Dataflows
3.1 Dataflow Graphs Overview:
여기서는 Apache Flink의 데이터플로우 그래프에 대해 설명합니다.
데이터플로우 그래프:
- 데이터플로우 그래프는 Flink 프로그램이 실행되는 기본 구조로, 여러 연산자와 데이터 스트림으로 구성됩니다.
- 데이터플로우 그래프는 방향성 비순환 그래프(DAG)입니다.
- 이 그래프는 두 가지 주요 구성 요소로 이루어져 있습니다:
- 상태를 가지는 연산자 (Stateful Operators): 데이터 처리 논리를 구현하는 노드들입니다. 예를 들어, 필터, 해시 조인, 스트림 윈도우 함수 등을 포함합니다. 특별한 경우로, 상태를 가지지 않는 연산자도 있을 수 있습니다.
- 이 그래프는 두 가지 주요 구성 요소로 이루어져 있습니다:
- 데이터 병렬 처리:
- 데이터플로우 그래프는 데이터 병렬 방식으로 실행됩니다.
- 연산자는 여러 병렬 인스턴스, 즉 서브태스크(subtasks)로 나뉩니다.
- 데이터 스트림은 여러 스트림 파티션으로 분할되며, 각 파티션은 하나의 서브태스크에서 생성된 데이터를 나타냅니다.
- 데이터 스트림 (Data Streams): 연산자가 생성한 데이터를 다른 연산자가 소비할 수 있도록 연결하는 간선들입니다.
- 연산자의 역할:
- 연산자들은 상태를 가질 수 있습니다. 상태는 데이터 스트림의 중간 결과를 저장하고, 이전 데이터와의 관계를 유지하는 데 필요합니다.예를 들어, 윈도우 연산, 집계 연산, 키 그룹화된 연산 등은 상태를 유지해야 합니다.
- 일부 연산은 상태를 유지할 필요가 없습니다. 이러한 연산은 입력 데이터를 처리하고, 결과를 즉시 내보냅니다. 예를 들어, 단순한 필터링, 맵핑, 변환 연산 등은 상태를 필요로 하지 않습니다.
- 데이터 분배 패턴:
- 데이터 스트림은 다양한 패턴으로 데이터를 분배합니다:
- 포인트 투 포인트 (Point-to-Point): 한 연산자에서 다른 연산자로 직접 데이터를 전달합니다.
- 브로드캐스트 (Broadcast): 한 연산자에서 여러 연산자로 데이터를 보냅니다.
- 재분할 (Re-partition): 데이터를 재분배하여 여러 연산자로 분배합니다.
- 팬아웃 (Fan-out): 한 연산자가 데이터를 여러 연산자에게 보냅니다.
- 병합 (Merge): 여러 연산자로부터 데이터를 결합하여 하나의 스트림으로 만듭니다.
- 데이터 스트림은 다양한 패턴으로 데이터를 분배합니다:
3.2 Data Exchange through Intermediate Data Streams
Apache Flink가 연산자 간에 데이터를 교환하는 방법에 대해 설명합니다.
중간 데이터 스트림 (Intermediate Data Streams):
- 중간 데이터 스트림은 한 연산자가 생성한 데이터를 다른 연산자가 소비할 수 있도록 하는 것입니다.
- 이 스트림은 데이터가 디스크에 저장될지 아니면 메모리에 유지될지에 따라 물리적으로 존재할 수도 있고 그렇지 않을 수도 있습니다.
파이프라인 방식과 블로킹 방식의 데이터 교환:
- 파이프라인 방식 (Pipelined Data Exchange):
- 실시간 스트리밍 프로그램과 배치 데이터플로우의 일부에서 사용됩니다.
- 데이터가 생성되는 즉시 소비자에게 전달되며, 이는 생산자와 소비자가 동시에 실행될 수 있도록 합니다.
- 소비자의 상태에 따라 생산자가 데이터를 보내는 속도를 조절하는 백프레셔(back pressure) 메커니즘을 지원합니다.
- 블로킹 방식 (Blocking Data Exchange):
- 유한한 데이터 스트림(배치 작업)에 사용됩니다.
- 생산자가 모든 데이터를 버퍼링한 후 소비자에게 전달하므로, 생산자와 소비자가 다른 실행 단계로 나뉘게 됩니다.
- 메모리를 더 많이 사용하고 종종 보조 저장소에 데이터를 저장하지만, 복잡한 연산(예: 정렬-병합 조인)에서 연산자 간의 상호작용을 분리하여 분산 교착 상태를 방지합니다.
- 정리하자면 파이프라인 방식은 바로바로 전달하는 방식이고, 블로킹 방식은 모아서 전달하는 방식입니다.
지연 시간과 처리량의 균형:
- Flink의 데이터 교환 메커니즘은 버퍼 교환을 중심으로 구현됩니다.
- 데이터 레코드가 준비되면 버퍼에 직렬화되어 소비자에게 전달됩니다.
- 버퍼는 가득 차거나 타임아웃이 발생할 때 소비자에게 전송됩니다.
- 이 접근 방식은 버퍼 크기와 타임아웃 설정에 따라 높은 처리량과 낮은 지연 시간을 균형 있게 유지할 수 있습니다.
- 예를 들어, 작은 버퍼 타임아웃은 낮은 지연 시간을 제공하지만 처리량이 줄어들 수 있고, 큰 타임아웃은 처리량을 증가시키지만 지연 시간이 길어질 수 있습니다.
제어 이벤트 (Control Events):
- 데이터 외에도 스트림은 연산자가 주입하는 제어 이벤트를 전달할 수 있습니다.
- 이러한 이벤트는 스트림 파티션 내의 다른 데이터 레코드와 함께 순서대로 전달되며, 수신 연산자는 이 이벤트를 받아 특정 작업을 수행합니다.
- 제어 이벤트의 예로는 다음이 있습니다:
- 체크포인트 배리어 (Checkpoint Barriers): 스트림을 체크포인트 이전과 이후로 나누어 체크포인트를 조정합니다. 체크포인트는 복구해서 처리할 . 때 사용합니다.
- 워터마크 (Watermarks): 스트림 파티션 내에서 해당 시간까지의 이벤트 메시지는 모두 왔음을 전달합니다. 해당 이벤트로 윈도우 연산을 트리거하는데 사용합니다.
- 반복 배리어 (Iteration Barriers): 반복 알고리즘에서 슈퍼스텝이 끝났음을 나타냅니다. 이는 뒤에서 자세하게 설명합니다.
순서 보장 및 연산자의 책임:
- Flink의 단일 입력 스트림을 소비하는 단항 연산자는 FIFO(선입선출) 순서를 보장합니다.
- 여러 입력 스트림을 받는 연산자는 스트림의 도착 순서에 따라 병합하여 효율성을 유지하고 백프레셔를 방지합니다.
- Flink 는 데이터 분배 방식인 재분할이나 브로드캐스트 후에는 순서를 보장하지 않으며, 순서가 필요한 연산자는 이를 명시적으로 처리해야 합니다.
3.2 Q & A
Q) 블로킹 방식으로의 데이터 교환은 여러 프로듀서의 데이터를 모아서 정렬해서 병합하는 것 같은건가? 처리 자체가 병목이 될 수 있는거겠네?
맞습니다.
블로킹 방식으로의 데이터 교환은 여러 프로듀서(생산자)의 데이터를 모아서 정렬하거나 병합하는 과정에서 발생합니다. 이 방식은 데이터를 한꺼번에 모아서 처리하기 때문에 다음과 같은 특징과 단점이 있습니다:
- 특징:
- 데이터 버퍼링:
- 블로킹 방식에서는 프로듀서가 생성한 모든 데이터를 버퍼에 저장합니다.
- 버퍼가 가득 차면 데이터를 소비자(컨슈머)에게 전달합니다.
- 단계적 실행:
- 프로듀서와 컨슈머가 동시에 실행되지 않습니다.
- 프로듀서가 모든 데이터를 생성하고 버퍼링을 완료한 후에야 컨슈머가 데이터를 처리할 수 있습니다.
- 메모리 사용량 증가:
- 모든 데이터를 한꺼번에 버퍼링하기 때문에 메모리 사용량이 증가합니다.
- 데이터가 많아지면 보조 저장소(디스크)에 데이터를 저장해야 할 수도 있습니다.
- 순서 보장:
- 데이터를 정렬하거나 병합하는 작업에서는 데이터의 순서가 보장됩니다.
- 이는 데이터의 순서가 중요한 작업(예: 정렬-병합 조인)에서 유리합니다.
- 데이터 버퍼링:
- 단점:
- 높은 지연 시간:
- 모든 데이터를 버퍼링하고 나서야 처리하기 때문에 지연 시간이 증가합니다.
- 실시간 처리가 필요한 경우에는 부적합합니다.
- 병목 현상:
- 버퍼링 과정에서 데이터가 한 곳에 모이기 때문에 처리 과정에서 병목 현상이 발생할 수 있습니다.
- 특히 대량의 데이터를 처리할 때 이러한 병목이 더욱 두드러질 수 있습니다.
- 복잡성 증가:
- 데이터를 한꺼번에 모아서 처리해야 하므로 시스템의 복잡성이 증가합니다.
- 메모리 관리, 데이터 저장 및 로드, 버퍼링 등의 추가 작업이 필요합니다.
- 높은 지연 시간:
Q) 체크포인트 베리어(Checkpoint Barriers) 에 대해 알려줘.
체크포인트 베리어는 장애가 나더라도 정확히 한 번(Exactly-Once) 처리 보장을 위해 사용됩니다.
체크포인트 베리어는 체크포인트를 생성하는데 사용되는 이벤트입니다. 체크포인트는 Flink의 상태를 저장하여 장애 발생 시 복구할 수 있도록 하는 메커니즘입니다
체크포인트 베리어는 스트림에 주입되어 모든 연산자가 해당 베리어를 수신할 때까지 스트림을 구분합니다. 이 과정은 다음과 같이 진행됩니다:
-
- 베리어 주입: 체크포인트 베리어가 스트림 소스에서 주입됩니다.
-
- 베리어 전파: 베리어는 각 연산자 사이를 이동하면서 스트림을 논리적으로 체크포인트 전후로 나눕니다.
-
- 상태 저장: 모든 연산자가 베리어를 수신하면, 현재 상태를 내구성 있는 저장소에 기록합니다.
- 베리어 통과: 베리어는 모든 연산자에 의해 처리되고 나면 스트림을 계속 흐르게 합니다.
Q) 워터마크(Watermarks) 에 대해 알려줘.
워터마크는 스트림 데이터에서 이벤트 시간이 어떻게 진행되고 있는지를 나타내는 특별한 이벤트입니다. 워터마크는 다음과 같은 역할을 합니다:
- 이벤트 시간 추적: 워터마크는 특정 시점까지의 모든 이벤트가 처리되었음을 나타냅니다.
- 윈도우 연산 트리거: 워터마크는 이벤트 기반 윈도우 연산을 트리거하여, 특정 시간 구간의 데이터를 처리하도록 합니다.
- 지연 처리 허용: 워터마크는 일정 시간 지연된 데이터를 처리할 수 있도록 도와줍니다.
- 예를 들어, 워터마크가 "2024-01-01T12:00:00"을 나타낸다면, 이 시간 이전의 모든 이벤트가 이미 도착했음을 의미합니다. 이를 통해 연산자는 이벤트 시간이 지난 윈도우를 닫고 결과를 출력할 수 있습니다.
Q) 반복 배리어(Iteration Barriers) 에 대해 알려줘
반복 배리어는 반복 알고리즘에서 슈퍼스텝(superstep)의 끝을 나타내는 이벤트입니다.
반복 알고리즘이라는 것이 있습니다. 이건 같은 데이터를 여러 번의 반복을 통해 점진적으로 결과를 개선하는 방식입니다.
주로 머신러닝의 Gradient Descent 와 같은 작업을 생각해보면 됩니다.
슈퍼 스텝은 이러한 반복의 한 단계를 의미합니다.
반복 배리어는 다음 순서로 처리됩니다.
-
- 반복 시작: 반복 배리어는 반복 알고리즘의 각 슈퍼스텝이 끝났음을 나타냅니다.
-
- 상태 동기화: 슈퍼스텝이 끝나면, 모든 연산자의 상태가 동기화되고 다음 단계로 넘어갑니다.
-
- 피드백 채널: 반복 배리어는 피드백 채널을 통해 데이터를 다시 입력으로 전달하여 다음 슈퍼스텝을 시작합니다.
슈퍼스텝(Superstep)은 Bulk Synchronous Parallel (BSP) 모델에서 유래된 개념으로, 각 반복 단계는 다음과 같은 단계를 거칩니다:
- 연산 수행: 각 노드는 주어진 데이터를 처리합니다.
- 통신: 노드 간의 데이터를 교환하여 다음 단계의 입력으로 사용합니다.
- 동기화: 모든 노드는 동기화 지점을 기다려, 모든 노드가 현재 단계의 작업을 완료했음을 보장합니다.
3.3 Fault Tolerance
Apache Flink의 장애 허용 메커니즘에 대해 설명합니다.
Flink는 신뢰할 수 있는 실행으로 엄격한 정확히 한 번(Exactly-Once) 처리 보장을 제공하며 체크포인팅과 부분 재실행을 통해 장애를 처리합니다.
먼저 기본 가정 (General Assumptions):
- Flink는 데이터 소스가 내구성이 있고 재생 가능하다는 가정을 합니다. 예를 들어, 파일이나 내구성 있는 메시지 큐(Apache Kafka 등)가 있습니다.
- 그러니까 데이터가 삭제되지 않음을 가정하고 시작합니다.
체크포인팅 메커니즘 (Checkpointing Mechanism):
- Flink의 체크포인팅 메커니즘은 분산된 일관된 스냅샷 개념을 기반으로 하여 정확히 한 번(Exactly-Once) 처리 보장을 달성합니다.
- 데이터 스트림의 무한한 특성으로 인해 장애 발생 시 재계산이 현실적이지 않기 때문에, Flink는 일정 간격으로 연산자의 상태를 스냅샷하여 복구 시간을 제한합니다.
비동기 베리어 스냅샷팅 (Asynchronous Barrier Snapshotting, ABS):
- Flink는 비동기 베리어 스냅샷팅(ABS) 메커니즘을 사용합니다. 베리어는 스트림에 주입되는 제어 레코드로, 논리적 시간에 해당하며 스트림을 체크포인트 전후로 나눕니다.
- 연산자는 상위 스트림으로부터 베리어를 수신하고, 먼저 정렬 단계를 수행하여 모든 입력으로부터 베리어를 받았는지 확인합니다.
- 연산자는 자신의 상태를 내구성 있는 저장소(예: HDFS)에 기록합니다.
- 상태가 백업되면, 연산자는 베리어를 하위 스트림으로 전달합니다.
- 결국, 모든 연산자가 자신의 상태 스냅샷을 등록하고 전역 스냅샷이 완료됩니다.
- ABS는 비동기 분산 스냅샷을 위한 Chandy-Lamport 알고리즘과 유사하지만, Flink 프로그램의 DAG 구조로 인해 전달 중인 레코드를 체크포인트할 필요가 없습니다. 대신, 정렬 단계만으로도 연산자 상태에 모든 영향을 적용할 수 있습니다.
ABS 에 대해 좀 더 간략하게 설명하면 다음과 같습니다:
-
- 체크포인트 베리어 (Checkpoint Barriers):
- 체크포인트 베리어는 데이터 스트림에 삽입되는 특별한 이벤트입니다.
- 각 체크포인트 베리어는 특정 체크포인트를 나타내며, 데이터 스트림을 논리적으로 체크포인트 전후로 나눕니다.
- 체크포인트 베리어 (Checkpoint Barriers):
-
- 정렬 단계 (Alignment Phase):
- 정렬 단계는 각 연산자가 모든 입력 스트림에서 체크포인트 베리어를 수신할 때까지 기다리는 과정입니다.
- 예를 들어, 연산자가 세 개의 입력 스트림을 가지고 있다면, 모든 스트림에서 체크포인트 베리어가 도착할 때까지 데이터를 계속 처리하지만, 베리어가 도착한 스트림의 경우 체크포인트를 완료할 때까지 데이터를 임시로 버퍼링합니다.
- 정렬 단계 (Alignment Phase):
-
- 상태 저장 (State Snapshot):
- 모든 입력 스트림에서 체크포인트 베리어를 수신하면, 연산자는 자신의 현재 상태를 내구성 있는 저장소(예: HDFS)에 저장합니다.
- 상태가 저장되면, 연산자는 체크포인트 베리어를 하위 스트림으로 전달합니다.
- 상태 저장 (State Snapshot):
-
- 베리어 전달 (Barrier Propagation):
- 체크포인트 베리어가 상위 스트림(데이터 소스 또는 이전 연산자)에서 생성되어 하위 스트림(다음 연산자)으로 전달됩니다.
- 이 과정에서 모든 연산자는 자신의 상태를 저장하고 베리어를 전달하여 전체 데이터플로우 그래프가 일관된 체크포인트를 가질 수 있도록 합니다.
- 베리어 전달 (Barrier Propagation):
ABS 예시를 통한 설명:
- 체크포인트 베리어 주입:
- 데이터 소스에서 체크포인트 베리어가 스트림에 삽입됩니다. 예를 들어, 체크포인트 베리어가 "체크포인트 1"을 나타낸다고 가정합니다.
- 베리어 전파 및 정렬:
- 체크포인트 베리어는 스트림을 따라 이동하며 각 연산자에 도달합니다.
- 연산자 A는 세 개의 입력 스트림을 가지고 있습니다. 첫 번째 스트림에서 체크포인트 베리어를 수신하면, 해당 스트림에서 더 이상의 데이터를 처리하지 않고 버퍼링합니다. 두 번째와 세 번째 스트림에서도 베리어를 수신할 때까지 계속 데이터를 처리합니다.
- 모든 입력 스트림에서 체크포인트 베리어를 수신하면 정렬 단계가 완료됩니다.
- 상태 저장:
- 연산자 A는 자신의 현재 상태를 저장소에 저장합니다.
- 상태 저장이 완료되면, 연산자 A는 체크포인트 베리어를 다음 연산자(연산자 B)로 전달합니다.
- 반복 과정:
- 연산자 B는 연산자 A에서 전달된 체크포인트 베리어를 수신합니다. 연산자 B도 동일한 과정을 거쳐 자신의 상태를 저장하고 체크포인트 베리어를 하위 스트림으로 전달합니다.
- 이 과정이 모든 연산자에 대해 반복됩니다.
- 전체 스냅샷 완료:
- 모든 연산자가 체크포인트 베리어를 수신하고 상태를 저장하면, 전체 데이터플로우 그래프에 대한 일관된 체크포인트가 완료됩니다.
장애로부터의 복구 (Recovery from Failures):
- 장애가 발생하면, 모든 연산자의 상태는 마지막 성공한 스냅샷으로 되돌아갑니다.
- 입력 스트림은 해당 스냅샷 지점부터 다시 시작됩니다.
- 최대 재계산 필요량은 두 연속 베리어 간의 입력 레코드 양으로 제한됩니다.
- 부분적인 서브태스크 복구도 가능합니다. 이 경우, 즉시 상위 서브태스크에서 버퍼된 처리되지 않은 레코드를 재생합니다.
3.3 Q & A
Q) 연산자와 스트림의 관계는 어떻게 되는거지? 하나의 연산자를 실행하기 위해 여러개의 스트림이 있는건가? 병렬로 실행하기 위해서
연산자와 스트림의 관계
- 연산자 (Operator):
- 연산자는 데이터 처리 로직을 실행하는 단위입니다. 예를 들어, 필터링, 매핑, 조인 등의 작업을 수행합니다.
- 각 연산자는 여러 개의 병렬 인스턴스, 즉 서브태스크(Subtasks)로 분할되어 병렬 처리가 가능합니다.
- 스트림 (Stream):
- 스트림은 연산자 간에 데이터를 전달하는 통로입니다. 연산자가 생성한 데이터는 스트림을 통해 다음 연산자로 전달됩니다.
- 스트림은 여러 개의 스트림 파티션(Stream Partitions)으로 나뉘어 각 파티션이 하나의 서브태스크와 연결됩니다.
그러니까 하나의 연산자를 실행하더라도 병렬 처리를 위해 서브 테스크로 분할되서 처리가 되고, 서브 테스크로 분할되서 처리하기 위해 데이터를 전송하는 통로인 스트림은 파티션으로 나뉜다는 것을 말합니다.
Q) Flink 의 Fault Tolerance 매커니즘인 ABS 는 정확히 한 번 처리되는게 맞아? At Least Once 수준으로 보장되는 것 아닌가? 정렬 단계에서 하나의 체크 포인트 베리어가 스트림에 도달하지 않는다면 같은 레벨에 있는 스트림은 계속해서 데이터를 처리하고 있으니까 여러번 처리될 수 있는거 아니야?
정확히 한 번 처리되는게 맞습니다.
체크포인트 이후의 중복 데이터를 처리하는 동안, 상태 스냅샷을 통해 이미 처리된 데이터는 무시되거나 재처리되지 않도록 보장됩니다.
이는 상태 기반 연산자에서 특히 중요한데, 예를 들어 윈도우 연산자는 체크포인트 시점 이후의 데이터를 다시 처리할 때 상태를 확인하여 중복을 방지합니다.
3.4 Iterative Dataflows
Apache Flink의 반복 데이터플로우 메커니즘은 반복적인 데이터 처리 작업을 효율적으로 지원하기 위해 설계되었습니다.
반복적 데이터 처리 작업:
- 이러한 작업들은 데이터를 여러 번 반복해서 처리하며, 각 반복(iteration)마다 결과를 점진적으로 개선합니다.
- 반복적 데이터 처리는 그래프 처리, 기계 학습 모델 구축, 최적화 알고리즘 등 여러 응용 분야에서 중요한 역할을 합니다.
반복 데이터플로우의 구성:
- Flink에서 반복 데이터플로우는 특별한 연산자인 반복 스텝(Iteration Steps)으로 구현된다.
- 반복 스텝은 자체적으로 실행 그래프를 포함할 수 있으며, 반복의 시작(헤드)과 끝(테일)을 나타내는 태스크들로 구성됩니다.
- 반복 스텝은 플로우 그래프의 피드백 채널을 통해 데이터를 다시 입력으로 전달하여 반복을 계속합니다
Flink의 반복 데이터플로우 구현:
- Iteration Steps:
- Flink의 반복 스텝은 반복 작업의 각 단계를 나타내며, 연산자가 데이터 플로우 내에서 반복적으로 실행될 수 있도록 합니다.
- 반복 스텝은 명시적인 피드백 루프를 사용하여 데이터가 반복적으로 처리되도록 합니다.
- 반복 헤드와 테일 (Iteration Head and Tail):
- 반복 헤드는 반복의 시작점을 나타내며, 반복 데이터를 초기화합니다.
- 반복 테일은 반복의 끝점을 나타내며, 반복된 데이터가 다시 반복 헤드로 전달됩니다.
Bulk Synchronous Parallel (BSP) 모델:
- Flink는 BSP 모델을 사용하여 반복 작업을 동기화합니다.
- BSP 모델에서는 각 반복 단계를 슈퍼스텝(Superstep)이라고 하며, 각 슈퍼스텝은 세 단계로 구성됩니다:
- 계산 (Compute): 각 노드는 주어진 데이터를 처리합니다.
- 통신 (Communicate): 노드 간에 데이터를 교환하여 다음 단계의 입력으로 사용합니다.
- 동기화 (Synchronize): 모든 노드는 동기화 지점을 기다려, 모든 노드가 현재 단계의 작업을 완료했음을 보장합니다.
피드백 채널 (Feedback Channels):
- 피드백 채널은 데이터를 반복 헤드로 다시 전달하여 반복 작업을 계속할 수 있게 합니다.
- 이 채널은 데이터 플로우 내에서 반복 루프를 형성하며, 반복이 종료될 때까지 계속해서 데이터를 전달합니다.
상태 관리 및 체크포인팅:
- 반복 데이터플로우에서 상태 관리는 중요한 역할을 합니다.
- Flink는 반복 작업 중에도 일관된 상태를 유지하며, 체크포인팅 메커니즘을 통해 반복 과정에서의 장애 복구를 지원합니다.
4. Stream Analytics on Top of Dataflows
Flink의 DataStream API를 사용하여 스트림 분석을 수행하는 방법을 설명합니다.
Flink Runtime 은 스트림 분석 프레임워크로서의 역할을 하며, 시간 관리, 상태 관리, 윈도우 연산 등을 지원하는데 이들에 대해서 하나씩 살펴보겠습니다.
4.1 The Notion of Time
Flink에서 시간의 개념을 다루며, 이벤트 시간을 기반으로 스트림 데이터를 처리하는 방법을 설명합니다.
시간의 종류:
- 이벤트 시간 (Event Time):
- 이벤트가 생성된 시점을 나타내는 시간입니다. 예를 들어, 센서에서 발생한 데이터의 타임스탬프입니다.
- 처리 시간 (Processing Time):
- 데이터를 처리하는 시스템의 벽 시계 시간입니다. 즉, 연산이 실행되는 시점의 실제 시간입니다.
- 인제션 시간 (Ingestion Time):
- 이벤트가 Flink에 들어오는 시점을 기준으로 한 시간입니다.
시간의 왜곡 (Time Skew):
- 분산 시스템에서 이벤트 시간과 처리 시간 사이에는 왜곡이 발생할 수 있습니다. 예를 들어, 네트워크 지연으로 인해 이벤트가 생성된 시간과 처리되는 시간 사이에 차이가 발생할 수 있습니다.
워터마크 (Watermarks):
- 워터마크는 이벤트 시간의 진행을 나타내는 특별한 이벤트입니다.
- 워터마크는 스트림 소스에서 생성되며, 이벤트의 타임스탬프를 기반으로 설정됩니다.
- 워터마크는 데이터 스트림을 통해 전파되며, 각 연산자는 워터마크를 수신하여 이벤트 시간 기반 연산을 수행할 수 있습니다.
- 워터마크는 특정 시점까지의 모든 이벤트가 도착했음을 나타냅니다. 예를 들어, 워터마크가 "2024-01-01T12:00:00"이면, 이 시간 이전의 모든 이벤트가 이미 도착했음을 의미합니다.
워터마크와 윈도우 연산:
- 워터마크는 윈도우 연산을 트리거하는 데 사용됩니다.
- 윈도우 연산은 일정 시간 동안의 데이터를 그룹화하여 집계 작업을 수행합니다. 예를 들어, 1분 동안의 데이터를 집계하여 평균값을 계산할 수 있습니다.
- 워터마크를 사용하면, 이벤트 시간 기반으로 윈도우를 정의하고, 데이터가 지연되어 도착하더라도 정확한 집계를 수행할 수 있습니다.
이벤트 시간 기반의 정확한 처리:
- Flink는 이벤트 시간 기반의 처리 방식을 통해 정확한 결과를 제공합니다.
- 이벤트 시간 기반 처리는 데이터가 지연되어 도착하더라도 올바른 순서로 처리되도록 합니다.
- 이를 통해 실시간 스트림 데이터 분석에서 발생할 수 있는 시간 왜곡 문제를 해결합니다.
결국 워터마크를 통해서 이벤트 생성된 시각으로 데이터를 모아서 윈도우 연산을 지원할 수 있게 됩니다. 이 개념이 없다면 처리 시간을 기준으로 윈도우 연산을 하게 될 것입니다.
4.1 Q & A
Q) 워터마크를 통해 특정 시점까지의 모든 이벤트 도착을 나타낸다고 했는데 이건 확률적인거야? 아니면 엄격하게 모든 이벤트 도착을 보장할 수 있는 개념이 있는거야?
워터마크는 특정 시점까지의 모든 이벤트가 도착했음을 나타내지만, 이것은 확률적인 개념입니다.
이는 엄격한 보장이 아니라, 스트림 소스가 워터마크를 생성할 때 설정된 기준에 따른 추정입니다.
스트림 소스에서 워터마크는 주기적으로 또는 특정 이벤트의 도착에 따라 생성되는데 소스는 이벤트의 타임스탬프를 분석하여 워터마크를 설정합니다.
예를 들어, 최근에 도착한 이벤트의 타임스탬프를 기준으로 몇 초 뒤의 시간을 워터마크로 설정할 수 있습니다.
4.2 Stateful Stream Processing
Apache Flink의 DataStream API는 상태를 관리하는 효율적인 방법을 제공하여 복잡한 스트림 처리를 가능하게 합니다.
이 절에서는 상태 저장 연산자와 상태 관리 메커니즘에 대해 설명합니다.
상태 저장 연산자 (Stateful Operators):
- 대부분의 Flink 연산자는 상태를 저장할 수 있습니다. 이는 연산자가 이전에 처리한 데이터에 대한 정보를 유지할 수 있게 합니다.
- 상태는 단순한 카운터나 합계에서부터 복잡한 데이터 구조(예: 분류 트리, 희소 행렬)까지 다양합니다.
상태의 중요성:
- 상태는 다양한 응용 프로그램에서 중요한 역할을 합니다. 예를 들어, 사용자 세션 관리, 윈도우 집계, 머신 러닝 모델 업데이트 등이 있습니다.
- 스트림 윈도우는 상태 저장 연산자의 대표적인 예입니다. 윈도우는 메모리 내에서 지속적으로 업데이트되는 버킷으로, 데이터 레코드를 할당받아 집계 작업을 수행합니다.
상태의 명시적 관리:
- Flink에서는 상태를 명시적으로 관리할 수 있습니다. 이는 연산자의 로컬 변수로 상태를 등록하거나, 연산자 상태 추상화를 사용하여 파티션된 키-값 상태를 선언할 수 있습니다.
- 상태는 내구성 있는 저장소에 저장되고 체크포인팅 메커니즘을 통해 내구성을 보장합니다.
상태백엔드 (State Backend):
- 상태백엔드는 상태가 어떻게 저장되고 관리되는지를 결정합니다. Flink는 다양한 상태백엔드를 지원하여 상태 저장 및 체크포인팅을 위한 유연한 구성을 제공합니다.
- 예를 들어, RocksDB와 같은 내구성 있는 상태백엔드나, 메모리 내 상태백엔드를 사용할 수 있습니다.
상태의 체크포인팅과 복구:
- Flink의 체크포인팅 메커니즘은 정확히 한 번 처리(Exactly-Once) 보장을 제공합니다.
- 체크포인트는 주기적으로 연산자의 상태를 내구성 있는 저장소에 스냅샷으로 저장합니다.
- 장애가 발생하면, Flink는 마지막 성공한 체크포인트로 상태를 복구하여 연산을 계속할 수 있습니다.
상태 저장 연산자 예시: 카운터 상태
// 상태 저장 연산자 예시: 카운터 상태
public class StatefulMap extends RichMapFunction<String, Tuple2<String, Integer>> {
// 카운터 상태를 위한 값 스테이트(ValueState)
private transient ValueState<Integer> counterState;
@Override
public void open(Configuration config) {
ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<>(
"counter", // 상태 이름
Types.INT); // 상태 타입
counterState = getRuntimeContext().getState(descriptor);
}
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
Integer currentCounter = counterState.value();
if (currentCounter == null) {
currentCounter = 0;
}
currentCounter += 1;
counterState.update(currentCounter);
return new Tuple2<>(value, currentCounter);
}
}
// 상태백엔드 설정 예시: RocksDB
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:40010/flink/checkpoints"));
// 체크포인팅 설정 예시
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(10000); // 10초마다 체크포인팅 수행
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);4.2 Q & A
Q) RocsDB 같은 경우는 Flink 의 임베디드 DB 인거야?
RocksDB는 Apache Flink의 임베디드 데이터베이스로 사용될 수 있지만, Flink에 내장되어 있는 것은 아닙니다.
RocksDB는 Facebook에서 개발한 고성능 키-값 저장소로, Flink의 상태 백엔드(State Backend) 중 하나로 사용됩니다.
상태 백엔드는 Flink의 상태를 관리하고 저장하는 메커니즘을 제공하며, RocksDB는 이러한 상태 백엔드로 유용합니다.
4.3 Stream Windows
Apache Flink의 스트림 윈도우 개념을 다룹니다.
스트림 윈도우는 연속적으로 도착하는 데이터 스트림을 일정한 논리적 단위로 그룹화하여 집계 작업을 수행하는 중요한 개념입니다. 이를 통해 실시간 스트림 데이터에서 의미 있는 통계를 계산할 수 있습니다.
윈도우의 필요성:
- 스트림 데이터는 끝이 없기 때문에, 데이터를 집계하거나 분석하기 위해서는 일정한 구간으로 나누어 처리해야 합니다.
- 윈도우는 이러한 구간을 정의하고, 데이터를 그룹화하여 연산을 수행할 수 있게 합니다.
윈도우 할당자 (Window Assigners):
- 윈도우 할당자는 데이터 레코드를 논리적 윈도우에 할당하는 역할을 합니다.
- 할당자는 타임스탬프나 레코드 수 등을 기준으로 윈도우를 정의합니다.
트리거 (Triggers):
- 트리거는 윈도우의 연산을 실행하는 조건을 정의합니다.
- 기본적으로 타임스탬프나 레코드 수를 기준으로 트리거를 설정할 수 있으며, 사용자 정의 트리거도 가능합니다.
이빅터 (Evictors):
- 이빅터는 윈도우에서 레코드를 제거하는 역할을 합니다.
- 윈도우의 크기를 관리하거나 특정 조건에 따라 레코드를 제거할 수 있습니다.
윈도우의 유형:
- Flink는 다양한 윈도우 유형을 지원하여 유연한 스트림 처리를 가능하게 합니다.
- 타임 윈도우 (Time Windows): 일정 시간 간격으로 데이터를 그룹화합니다. 예: 슬라이딩 타임 윈도우, 텀블링 타임 윈도우.
- 카운트 윈도우 (Count Windows): 일정 수의 레코드 단위로 데이터를 그룹화합니다. 예: 슬라이딩 카운트 윈도우, 텀블링 카운트 윈도우.
- 세션 윈도우 (Session Windows): 데이터의 불규칙한 간격을 기준으로 세션을 정의합니다. 세션은 활동 간격이 없으면 종료됩니다.
- 글로벌 윈도우 (Global Windows): 모든 데이터가 하나의 윈도우에 할당됩니다. 트리거를 사용하여 연산을 실행합니다.
- 유연한 윈도우 정의:
- Flink는 사용자가 윈도우 할당자, 트리거, 이빅터를 조합하여 다양한 윈도우 연산을 정의할 수 있도록 유연성을 제공합니다.
- 예를 들어, 슬라이딩 타임 윈도우를 정의하여 5초 간격으로 1분 동안의 데이터를 집계할 수 있습니다.
예시: 원도우 작성
// 슬라이딩 타임 윈도우 설정: 1분 동안의 데이터를 5초 간격으로 집계
DataStream<Tuple2<String, Integer>> stream = ...;
DataStream<Tuple2<String, Integer>> windowedStream = stream
.keyBy(0)
.timeWindow(Time.minutes(1), Time.seconds(5))
.sum(1);
// 세션 윈도우 설정: 10초 동안 활동이 없으면 세션 종료
DataStream<Tuple2<String, Integer>> stream = ...;
DataStream<Tuple2<String, Integer>> sessionWindowedStream = stream
.keyBy(0)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.sum(1);
// 사용자 정의 트리거: 특정 조건에 따라 윈도우 연산을 트리거
public class CustomTrigger extends Trigger<Object, TimeWindow> {
// 이 메서드는 새로운 요소가 윈도우에 추가될 때마다 호출됩니다.
@Override
public TriggerResult onElement(Object element, long timestamp, TimeWindow window, TriggerContext ctx) {
// 사용자 정의 로직
return TriggerResult.CONTINUE;
}
// 이 메서드는 프로세싱 타임(Processing Time) 타이머가 만료될 때 호출됩니다.
// 특정 시간에 트리거를 발동하거나 상태를 정리하는 데 사용할 수 있습니다.
@Override
public TriggerResult onProcessingTime(long time, TimeWindow window, TriggerContext ctx) {
// 사용자 정의 로직
return TriggerResult.FIRE;
}
@Override
public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) {
// 사용자 정의 로직
return TriggerResult.CONTINUE;
}
// 이 메서드는 이벤트 타임(Event Time) 타이머가 만료될 때 호출됩니다.
// 특정 이벤트 시간이 도달했을 때 트리거를 발동하거나 상태를 정리하는 데 사용할 수 있습니다.
@Override
public void clear(TimeWindow window, TriggerContext ctx) {
// 클리어 로직
}
}
DataStream<Tuple2<String, Integer>> stream = ...;
DataStream<Tuple2<String, Integer>> customTriggeredStream = stream
.keyBy(0)
.timeWindow(Time.minutes(1))
.trigger(new CustomTrigger())
.sum(1);
4.4 Asynchronous Stream Iterations
Apache Flink에서 비동기 스트림 반복을 지원하는 방법에 대해 설명합니다.
비동기 반복은 스트림 처리에서 중요한 역할을 하며, 특히 머신러닝 모델 구축, 그래프 처리, 강화 학습 등의 분야에서 많이 사용됩니다.
비동기 반복의 필요성:
- 스트림 데이터 처리에서는 데이터를 여러 번 반복해서 처리해야 하는 경우가 많습니다.
- 예를 들어, 머신러닝 모델을 점진적으로 업데이트하거나 그래프 알고리즘을 반복적으로 실행할 때 비동기 반복이 필요합니다.
비동기 반복의 구현:
- Flink는 비동기 반복을 지원하여 반복적인 데이터 처리 작업을 효율적으로 수행할 수 있습니다.
- 비동기 반복은 데이터가 피드백 루프를 통해 연산자로 다시 입력되어 여러 번 처리되도록 합니다.
반복 데이터플로우 모델:
- Flink의 반복 데이터플로우 모델은 반복의 시작(헤드)과 끝(테일)을 나타내는 연산자로 구성됩니다.
- 피드백 채널을 통해 데이터가 반복적으로 연산자로 전달됩니다.
반복 제어 이벤트 (Iteration Control Events):
- Flink는 반복의 시작과 끝을 제어하기 위해 반복 제어 이벤트를 사용합니다.
- 반복 제어 이벤트는 슈퍼스텝(superstep) 모델을 기반으로 하며, 각 슈퍼스텝은 반복의 한 단계를 나타냅니다.
- 슈퍼스텝은 계산(Compute), 통신(Communicate), 동기화(Synchronize)의 세 단계로 구성됩니다.
상태 관리와 체크포인팅:
- 비동기 반복에서도 상태 관리와 체크포인팅이 중요한 역할을 합니다.
- Flink는 반복 작업 중에도 일관된 상태를 유지하며, 체크포인팅 메커니즘을 통해 장애 복구를 지원합니다.
비동기 스트림 반복 예시:
// 비동기 반복 예시
// Flink 실행 환경 설정
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 반복 데이터 스트림 생성
DataStream<Tuple2<Long, Double>> input = ...;
// 반복 데이터플로우 설정
IterativeStream<Tuple2<Long, Double>> iteration = input.iterate();
// 반복 내부 연산 정의
DataStream<Tuple2<Long, Double>> iterationBody = iteration.map(new MyIterationMapper());
// 반복 종료 조건 정의
// 피드백 스트림의 filter
// 피드백 스트림의 filter는 반복을 계속할지 여부를 결정합니다.
// 특정 조건을 만족하는 데이터만 다시 반복의 시작점으로 보내집니다.
// 조건을 만족하지 않는 데이터는 반복에서 제외됩니다.
DataStream<Tuple2<Long, Double>> feedback = iterationBody.filter(new FilterFunction<Tuple2<Long, Double>>() {
@Override
public boolean filter(Tuple2<Long, Double> value) {
return value.f1 > 0.01; // 특정 조건을 만족하면 반복 계속
}
});
// 반복 결과 정의
iteration.closeWith(feedback);
// 반복 종료 후의 결과 스트림
// 결과 스트림의 filter
// 결과 스트림의 filter는 반복이 종료된 데이터를 최종 결과로 분리합니다./
// 특정 조건을 만족하는 데이터를 결과 스트림으로 보내고, 반복에서 제외합니다.
DataStream<Tuple2<Long, Double>> result = iterationBody.filter(new FilterFunction<Tuple2<Long, Double>>() {
@Override
public boolean filter(Tuple2<Long, Double> value) {
return value.f1 <= 0.01; // 특정 조건을 만족하면 반복 종료
}
});
env.execute("Asynchronous Iteration Example");4.4 Q & A
Q) Flink 의 비동기 스트림 반복을 통해서 큰 머신러닝 모델의 분산 학습을 시킬 수 있는건가?
맞습니다.
다음 예시처럼 학습할 수 있습니다.
// 1. 환경 설정 및 데이터 스트림 생성
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<Long, Vector>> input = ...; // 입력 데이터 스트림
// 2. 반복 데이터플로우 설정
IterativeStream<Tuple2<Long, Vector>> iteration = input.iterate();
// 3. 반복 연산 정의
DataStream<Tuple2<Long, Vector>> iterationBody = iteration.map(new GradientDescentMapper());
// 4. 반복 종료 조건 정의
DataStream<Tuple2<Long, Vector>> feedback = iterationBody.filter(new FilterFunction<Tuple2<Long, Vector>>() {
@Override
public boolean filter(Tuple2<Long, Vector> value) {
return value.f1.norm() > 0.001; // 특정 조건을 만족하면 반복 계속
}
});
// 5. 반복 종료 후의 결과 스트림
DataStream<Tuple2<Long, Vector>> result = iterationBody.filter(new FilterFunction<Tuple2<Long, Vector>>() {
@Override
public boolean filter(Tuple2<Long, Vector> value) {
return value.f1.norm() <= 0.001; // 특정 조건을 만족하면 반복 종료
}
});
// 6. 반복 종료 정의
iteration.closeWith(feedback);
// 7. 사용자 정의 연산자 (GradientDescentMapper)
public static class GradientDescentMapper implements MapFunction<Tuple2<Long, Vector>, Tuple2<Long, Vector>> {
private transient ValueState<Vector> modelState;
@Override
public void open(Configuration config) {
ValueStateDescriptor<Vector> descriptor = new ValueStateDescriptor<>(
"modelState", // 상태 이름
Types.GENERIC(Vector.class)); // 상태 타입
modelState = getRuntimeContext().getState(descriptor);
}
@Override
public Tuple2<Long, Vector> map(Tuple2<Long, Vector> value) throws Exception {
Vector currentModel = modelState.value();
if (currentModel == null) {
currentModel = new DenseVector(value.f1.size());
}
// Gradient Descent 업데이트 로직
Vector gradient = computeGradient(value.f1, currentModel);
Vector newModel = currentModel.subtract(gradient.scale(0.01)); // 학습률 0.01
modelState.update(newModel);
return new Tuple2<>(value.f0, newModel);
}
private Vector computeGradient(Vector data, Vector model) {
// 사용자 정의 기울기 계산 로직
return data.subtract(model); // 예시: 간단한 차이 계산
}
}
5. Batch Analytics on Top of Dataflows
Flink는 배치 처리를 스트리밍 데이터플로우의 특별한 경우로 간주합니다.
즉, 모든 입력 데이터를 하나의 윈도우에 삽입하여 스트리밍 프로그램을 배치 프로그램으로 변환할 수 있습니다.
이를 통해 Flink는 스트리밍 및 배치 작업 모두를 단일 실행 모델로 통합합니다. 하지만 배치 데이터를 처리할 때는 몇 가지 최적화가 필요하다고 합니다.
배치 처리를 위한 접근 방식
- 동일한 런타임 사용:
- 배치 연산도 스트리밍 연산과 동일한 런타임에서 실행됩니다.
- 큰 연산을 분리된 단계로 나누어 순차적으로 스케줄링합니다.
- 주기적 스냅샷 비활성화:
- 주기적 스냅샷의 오버헤드가 큰 경우, 이를 비활성화하고 최근에 저장된 중간 스트림에서 데이터 파티션을 재생함으로써 장애 복구를 수행합니다.
- 블로킹 연산자:
- 블로킹 연산자를 이용해야하는 이유는 모든 데이터를 한번에 처리하기 위해서 입니다.
- 정렬 등의 블로킹 연산자는 전체 입력을 소비할 때까지 차단됩니다.
- Flink는 관리 메모리를 사용하여 메모리 경계를 초과할 경우 데이터를 디스크로 스필합니다.
- 전용 DataSet API:
- DataSet API는 배치 연산을 위한 익숙한 추상화를 제공합니다. 예를 들어, DataSet 데이터 구조와 DataSet 변환(조인, 집계, 반복 등)을 포함합니다.
- 쿼리 최적화 계층을 통해 DataSet 프로그램을 효율적인 실행 가능한 코드로 변환합니다.
- 주기적 스냅샷 비활성화, 블로킹 연산자, 전용 DataSet API 등을 통해 배치 작업의 효율성을 극대화할 수 있습니다. 이러한 접근 방식을 통해 Flink는 고성능의 일관된 데이터 처리 환경을 제공합니다.
5.1 Query Optimization
Apache Flink의 쿼리 최적화에 대해 다룹니다. Flink의 쿼리 최적화는 병렬 데이터베이스 시스템의 기술을 기반으로 하며, 쿼리 성능을 최적화하기 위해 다양한 전략을 사용합니다.
최적화 기술:
- Flink의 최적화는 병렬 데이터베이스 시스템에서 사용되는 여러 기술을 기반으로 합니다.
- Plan Equivalence, Cost Modeling, Interesting-Property Propagation 등이 포함됩니다.
- Plan Equivalence 은 동일한 논리적 쿼리를 다양한 물리적 실행 계획으로 표현할 수 있는 능력을 의미합니다. 이는 여러 실행 계획을 생성하고, 그 중에서 가장 효율적인 계획을 선택하기 위해 필요합니다.
- Cost Modeling 은 각 실행 계획의 예상 비용을 추정하여, 가장 효율적인 계획을 선택하는 과정입니다. 비용 모델은 다양한 자원 사용량을 평가하여 최적의 실행 계획을 결정합니다. 네트워크 I/O 와, Disk I/O 그리고 CPU 비용등을 고려해서 비용을 계산한다.
- Interesting-Property Propagation 는 쿼리 최적화 과정에서 특정 속성이 중요한 영향을 미치는 경우, 이를 전파하여 최적화하는 방법입니다. 특정 속성(예: 데이터의 정렬 상태, 파티션 구조 등)이 실행 계획의 효율성에 미칠 수 있을 것이다.
- Interesting-Property Propagation:
- Flink의 최적화는 이 개념을 사용하여 다양한 물리적 실행 계획을 나열하고, 비용 기반 접근 방식을 통해 최적의 계획을 선택합니다.
- 비용 모델은 네트워크 및 디스크 I/O, CPU 비용 등을 포함합니다.
- 카디널리티 및 비용 추정:
- UDF(사용자 정의 함수)가 포함된 경우 카디널리티와 비용을 추정하는 것이 어렵습니다.
- Flink는 이러한 문제를 극복하기 위해 프로그래머가 제공하는 힌트를 사용합니다.
- 실행 전략:
- Flink는 다양한 실행 전략을 지원합니다. 예를 들어, 재파티션(Repartition)과 브로드캐스트 데이터 전송(Broadcast Data Transfer), 정렬 기반 그룹화(Sort-Based Grouping) 및 정렬-해시 기반 조인(Sort- and Hash-Based Join) 구현 등을 포함합니다.
- 최적화 프로그램은 다양한 물리적 플랜을 나열하고, 비용 기반 접근 방식을 사용하여 최적의 플랜을 선택합니다.
- 최적화 과정:
- Flink의 최적화 과정은 쿼리의 논리적 표현을 물리적 실행 계획으로 변환하는 과정입니다.
- 이 과정에서 쿼리의 비용을 최소화하기 위해 다양한 최적화 기술을 사용합니다.
- Flink는 물리적 계획을 나열하고, 비용을 추정하여 최적의 계획을 선택합니다.
5.2 Memory Management
Apache Flink의 메모리 관리(Memory Management) 시스템은 효율적인 데이터 처리를 위해 중요합니다.
5.2절에서는 Flink가 어떻게 메모리를 관리하고, 데이터 처리 성능을 최적화하는지 설명합니다.
메모리 세그먼트 (Memory Segments):
- Flink는 데이터 레코드를 메모리 세그먼트에 직렬화하여 저장합니다.
- 이러한 방식은 JVM 힙(heap) 내에서 객체를 할당하지 않고, 메모리 세그먼트를 통해 데이터를 관리함으로써 효율성을 높입니다.
- 이는 가비지 컬렉션(garbage collection) 오버헤드를 줄이고, 메모리 사용을 최적화합니다.
직렬화 및 역직렬화 (Serialization and Deserialization):
- Flink는 데이터 레코드를 직렬화된 형태로 저장하고, 필요한 경우 역직렬화하여 처리합니다.
- 직렬화된 데이터를 메모리 세그먼트에 저장함으로써, 불필요한 객체 생성과 메모리 할당을 최소화합니다.
- 이를 통해 데이터 처리 성능을 향상시킵니다.
버퍼 관리 (Buffer Management):
- Flink는 데이터 처리를 위해 버퍼를 사용합니다. 버퍼는 데이터 레코드를 저장하는 메모리 블록입니다.
- 버퍼는 채워지면 소비자에게 전송되며, 필요 시 디스크로 스필(spill)할 수 있습니다.
- 이는 대규모 데이터셋을 처리할 때 메모리 한계를 극복하고, 안정적인 성능을 유지하는 데 도움이 됩니다.
메모리 외부 저장 (Off-Heap Storage):
- Flink는 메모리 외부 저장(off-heap storage)을 사용하여 JVM 힙 외부에서 데이터를 저장할 수 있습니다.
- 이는 가비지 컬렉션 오버헤드를 줄이고, 메모리 관리의 효율성을 높입니다.
- 오프 힙 저장을 통해 대규모 데이터셋을 효과적으로 처리할 수 있습니다.
정렬 및 조인 작업 (Sorting and Joining):
- Flink의 정렬 및 조인 연산은 가능한 한 직렬화된 데이터 형태로 작업을 수행합니다.
- 데이터가 메모리 세그먼트에 저장되므로, 정렬 및 조인 연산 시 불필요한 역직렬화 과정을 피할 수 있습니다.
- 필요 시 데이터를 디스크로 스필하여 메모리 사용을 최적화합니다.
5.2 Q & A
Q) Flink 는 데이터 레코드를 JVM 힙 외부에 저장하고, 이때 메모리 세그먼트 형태로 관리하는거지? 메모리 세그먼트 형태로 관리하면 직렬화 형태로 데이터를 저장할 수 있어서 네트워크를 통한 데이터 전송도 빨라지게 되고, 정렬이나 조인 등의 작업에서도 역직렬화의 작업이 필요없는거지?
맞습니다.
메모리 세그먼트는 Flink가 데이터를 저장하는 기본 단위입니다. 이는 JVM 힙 외부에 위치하며, 데이터를 직렬화된 형태로 저장할 수 있습니다.
직렬화된 데이터는 네트워크 전송 시 효율적입니다. 데이터가 이미 직렬화되어 있으므로 추가적인 직렬화 작업이 필요 없습니다.
직렬화된 데이터는 데이터 전송 크기를 줄이고, 전송 속도를 향상시킵니다.
메모리 세그먼트에 직렬화된 데이터는 정렬 및 조인 작업 시 역직렬화가 필요 없습니다.
5.3 Batch Iterations
5.3절에서는 Apache Flink에서 배치 반복(Batch Iterations)을 처리하는 방법에 대해 설명합니다.
반복(iteration)은 그래프 분석, 병렬 기울기 하강법(parallel gradient descent), 최적화 기법과 같은 많은 데이터 처리 작업에서 중요한 역할을 합니다.
Flink는 다양한 반복 모델을 지원하여 효율적인 반복 처리를 가능하게 합니다.
반복의 필요성:
- 반복적인 데이터 처리는 많은 알고리즘에서 필수적입니다. 예를 들어, 머신러닝에서 모델을 점진적으로 개선하거나 그래프 알고리즘에서 여러 번의 반복을 통해 최종 결과를 얻는 경우가 있습니다.
- Flink는 이러한 반복 작업을 효율적으로 처리하기 위해 다양한 반복 모델을 제공합니다.
반복 모델:
- Flink는 Bulk Synchronous Parallel(BSP) 모델과 Stale Synchronous Parallel(SSP) 모델을 포함한 여러 반복 모델을 지원합니다.
- BSP 모델: 각 반복(iteration)은 슈퍼스텝(superstep)으로 나뉘며, 모든 노드가 현재 슈퍼스텝을 완료할 때까지 기다렸다가 동기화 되는 방식입니다. 이후 다음 슈퍼스텝이 시작됩니다.
- SSP 모델: 노드 간의 동기화가 느슨하며, 일부 노드가 느려도 전체 반복 과정이 계속 진행됩니다.
델타 반복(Delta Iterations):
- Flink는 델타 반복(delta iterations)이라는 새로운 최적화 기법을 도입했습니다.
- 델타 반복은 매 반복마다 전체 데이터를 처리하는 대신, 변경된 데이터만 처리하여 효율성을 극대화합니다.
- 이는 희소한 계산적 종속성(sparse computational dependencies)을 활용하여 처리 속도를 향상시킵니다.
Gelly와의 통합:
- Gelly는 Flink의 그래프 API로, 반복적인 그래프 알고리즘을 효율적으로 실행할 수 있도록 설계되었습니다.
- Gelly는 델타 반복을 활용하여 그래프 알고리즘의 성능을 최적화합니다.
5.3 Q & A
Q) SSP 는 느린 노드의 처리를 기다리지 않는 방식인거지? 대신에 충돌이 생겨서 오차가 좀 생길 수 있는건가?
맞습니다.
느린 노드의 처리를 기다리지 않고 진행하는 방식입니다. 이는 Bulk Synchronous Parallel (BSP) 모델의 동기화 오버헤드를 줄이기 위한 접근 방식입니다. 대신, 이로 인해 충돌이 생기거나 데이터의 일관성 문제가 발생할 수 있으며, 결과에 약간의 오차가 생길 수 있습니다
Q) 델타 반복이 뭐지? 그래프 처리에서 사용하는 기법인가?
델타 반복(Delta Iterations)은 Apache Flink에서 제공하는 반복 처리 최적화 기법으로, 주로 그래프 처리와 같은 반복적인 데이터 처리 작업에서 사용됩니다.
델타 반복의 핵심 아이디어는 매 반복(iteration)마다 전체 데이터셋을 처리하는 대신, 변경된 데이터(델타)만 처리함으로써 연산의 효율성을 높이는 것입니다.
그렇지만 머신러닝 Gradient Descent 에서도 사용이 가능합니다.
- 델타 기울기(Delta Gradient):
- 각 반복에서 모델 파라미터가 업데이트되면, 변경된 파라미터에 의해 영향을 받는 데이터 포인트만 다시 계산합니다.
- 전체 데이터셋이 아닌, 변경된 데이터 포인트만 선택적으로 처리하여 연산 비용을 줄일 수 있습니다.
6. Related Work
6장에서는 Apache Flink와 유사한 기능을 제공하는 기존의 시스템 및 연구에 대해 논의합니다.
이 장에서는 배치 처리와 스트림 처리 시스템을 주로 다루며, Flink가 이들과 어떻게 다른지, 어떤 점에서 개선되었는지를 설명합니다.
대표적인 배치 처리 시스템:
- Apache Hadoop: 가장 널리 알려진 대규모 데이터 분석 시스템으로, MapReduce 패러다임을 기반으로 합니다.
- Dryad: 일반적인 DAG(Directed Acyclic Graph) 기반의 데이터플로우를 제공하는 시스템입니다.
- Apache Tez: Dryad의 아이디어를 구현한 오픈 소스 시스템입니다.
- MPP 데이터베이스: 대규모 병렬 데이터베이스 시스템으로, SQL 쿼리를 병렬로 처리합니다. 예로는 Apache Drill과 Impala가 있습니다.
- Apache Spark: DAG 기반의 실행 엔진을 제공하는 데이터 처리 프레임워크로, 반복적인 데이터 처리와 배치 처리를 모두 지원합니다.
Flink의 차별점:
- 파이프라인 스트리밍 실행: Flink는 스트림과 배치 작업을 모두 파이프라인 스트리밍 실행 방식으로 처리합니다.
- 정확히 한 번 상태 일관성: Flink는 가벼운 체크포인팅을 통해 정확히 한 번의 상태 업데이트를 보장합니다.
- 네이티브 반복 처리: Flink는 네이티브 반복 처리를 지원합니다.
- 고급 윈도우 기능: Flink는 이벤트 시간 기반의 복잡한 윈도우 기능을 지원하며, 정렬되지 않은 데이터도 처리할 수 있습니다.
대표적인 스트림 처리 시스템:
- SEEP, Naiad: 스트림 처리 시스템으로, 동기화와 반복 처리를 지원합니다.
- Microsoft StreamInsight, IBM Streams: 상업용 스트림 처리 시스템입니다.
- Apache Storm: 수평 확장 가능한 스트림 처리 시스템으로, 최소한 한 번(at-least-once) 처리를 보장합니다.
- Apache Samza: 스트림 처리 시스템으로, at-least-once 처리를 지원합니다.
- Google MillWheel: 내부적으로 Google에서 사용하는 스트림 처리 시스템으로, 정확히 한 번 처리와 낮은 지연 시간을 목표로 합니다.
- Apache Beam/Google Dataflow: MillWheel의 아이디어를 바탕으로 한 스트림 처리 시스템입니다.
Flink의 차별점:
- 이벤트 시간과 무질서 이벤트 처리: Flink는 이벤트 시간과 무질서 이벤트 처리를 완벽하게 지원합니다.
- 상태 관리와 일관성 보장: Flink는 정확히 한 번의 상태 일관성을 보장합니다.
- 높은 처리량과 낮은 지연 시간: Flink는 높은 처리량과 낮은 지연 시간을 동시에 달성할 수 있습니다.
- 배치와 스트림 작업 통합: Flink는 배치와 스트림 작업을 동일한 엔진에서 통합하여 처리할 수 있습니다.
6. Q & A
Q) Flink 의 무질서 이벤트 처리는 뭐야?
Apache Flink의 무질서 이벤트 처리(Out-of-Order Event Processing)는 이벤트 스트림에서 이벤트가 발생한 순서와 도착한 순서가 다른 경우에도 올바르게 처리할 수 있도록 설계된 기능입니다.
- 네트워크 지연으로 인해 이벤트가 발생한 순서대로 도착하지 않을 수 있습니다.
Flink의 무질서 이벤트 처리 메커니즘
- 워터마크 생성:
- 소스에서 이벤트를 읽을 때 워터마크를 생성합니다. 워터마크는 이벤트 스트림에 주기적으로 삽입되며, 특정 시간까지의 모든 이벤트가 도착했음을 나타냅니다.
- 이벤트 시간 기반 윈도우:
- Flink는 이벤트 시간 기반으로 윈도우를 정의하고, 워터마크를 사용하여 윈도우를 트리거합니다.
- 예를 들어, 5분 간격의 슬라이딩 윈도우를 정의할 때, 워터마크가 윈도우의 끝에 도달하면 해당 윈도우가 완료되고 결과가 계산됩니다.
- 정렬되지 않은 이벤트 처리:
- Flink는 정렬되지 않은 이벤트를 처리하기 위해 일정 기간 동안 데이터를 버퍼에 저장하고, 워터마크를 기반으로 버퍼에서 데이터를 정렬하여 처리합니다.
7. Acknowledgements
논문의 7장은 Flink 프로젝트의 개발과 발전에 기여한 사람들과 커뮤니티에 대한 감사의 글을 포함하고 있습니다.
그러므로 Pass
8. Conclusion
Apache Flink 논문의 8장은 Flink의 주요 기여와 장점을 요약하며, 향후 연구 및 개발 방향에 대한 논의를 포함합니다.
Flink의 주요 기여:
- Flink는 스트리밍 및 배치 데이터 처리를 위한 통합 데이터플로우 엔진을 구현한 플랫폼입니다.
- 다양한 데이터 처리 작업을 하나의 실행 모델로 통합하여, 실시간 분석, 연속 데이터 파이프라인, 이력 데이터 처리(배치), 반복 알고리즘(머신러닝, 그래프 분석) 등을 지원합니다.
- Flink는 파이프라인 방식의 고가용성 데이터플로우를 제공하며, 효율적이고 신뢰성 있는 데이터 처리를 보장합니다.
스트리밍 및 배치 처리의 통합:
- Flink는 스트리밍과 배치 작업을 동일한 실행 엔진에서 처리할 수 있도록 설계되었습니다.
- 배치 작업은 스트리밍 작업의 특수한 경우로 취급되어, 동일한 API와 실행 모델을 통해 처리됩니다.
- 이를 통해 Flink는 스트리밍과 배치 작업 간의 경계를 허물고, 데이터 처리의 유연성을 극대화합니다.
상태와 윈도우 기반의 스트림 처리:
- Flink는 스트림 처리에서 상태(state)를 일급 객체로 취급하며, 윈도우(window)를 사용한 데이터 처리 기능을 제공합니다.
- 이벤트 시간(event-time), 인제스천 시간(ingestion-time), 처리 시간(processing-time) 등 다양한 시간 개념을 지원하여, 사용자가 원하는 방식으로 데이터 이벤트를 처리할 수 있습니다.
- Flink의 윈도우 기능은 다양한 윈도우 종류와 트리거, 이빅터를 통해 유연한 스트림 처리를 가능하게 합니다.
효율적인 반복 처리:
- Flink는 반복적인 데이터 처리 작업을 네이티브로 지원합니다.
- 델타 반복(delta iterations)과 같은 최적화 기법을 통해 반복 처리의 효율성을 극대화합니다.
- 이는 그래프 분석, 머신러닝 등 반복적인 데이터 처리 작업에 유용합니다.
고가용성과 내결함성:
- Flink는 정확히 한 번 처리되는 상태 일관성을 보장하며, 가벼운 체크포인팅을 통해 높은 내결함성을 제공합니다.
- 장애 발생 시 빠르게 복구할 수 있는 메커니즘을 갖추고 있어, 실시간 데이터 처리의 신뢰성을 높입니다.
미래 연구 방향:
- Flink의 성능과 기능을 지속적으로 개선하기 위한 연구가 계속될 것이라고 합니다.
- 더 많은 데이터 소스와 싱크(sink)를 지원하고, 새로운 데이터 처리 요구사항을 충족시키기 위해 API와 런타임을 확장할 예정이라고 합니다.
- 머신러닝, 그래프 처리, 복잡한 이벤트 처리(CEP) 등 다양한 도메인에 특화된 기능을 추가할 계획이라고 합니다.
'System Design > General' 카테고리의 다른 글
| Cache 잘 쓰는 방법 정리 (0) | 2024.06.16 |
|---|---|
| 7 Must-know Strategies to Scale Your Database (0) | 2024.06.16 |
| Data Store Internals (0) | 2024.04.05 |
| 기본적인 시스템 규모 확장을 위해 사용하는 기법 (0) | 2024.04.01 |
| 파티셔닝: 대규모 시스템의 핵심 전략 (0) | 2023.12.23 |