최근 '우아한 테크 세미나: 대규모 트랜잭션을 처리하는 배민 주문시스템의 진화'를 보았는데요,
주문 시스템의 성능 향상을 위해 어플리케이션 레벨에서 파티셔닝(Partitioning) 을 도입 했더라고요.
세미나를 보고나서 데이터베이스 레벨에서 지원하는 파티셔닝과 다르게 어플리케이션에서 직접 파티셔닝을 이용하려면 어떠한 것들에 대해 고려해야하는지 정리해보고 싶다는 생각이 들어서 글을 작성해보았습니다.
우아한 테크 세미나도 유용한 내용이 많던데 궁금하시면 원문을 봐보시는 걸 추천드립니다. 링크는 아래에 적어둘게요.
1. 파티셔닝의 목적:
파티셔닝은 시스템에 확장성 (Scalability) 를 제공하기 위해서 사용됩니다.
시스템의 사용자 수가 증가하거나, 트래픽이 증가함에 따라서 시스템이 이에 맞게 처리량도 같이 증가할 수 있는 능력을 가지기 위해서 필요한거죠.
배달의민족 주문 시스템도 이용하는 고객이 많아지니까 주문 쓰기 트래픽이 증가함에 따라서 이를 처리하기 위해 파티셔닝을 도입했다고 합니다.
2. 파티셔닝의 종류: 수평 파티셔닝(Horizontal Partitioning)
본 글에서 집중하는 파티셔닝 방식은 수평 파티셔닝입니다.
이 방식은 테이블의 데이터 행(Row)들을 여러 부분으로 나누는 것으로, 관계형 데이터베이스에서의 확장성 문제를 해결하는 데 주로 사용됩니다.
이것 외에도 테이블 자체를 분리하는 Vertical Partitioning 이라는 것도 있습니다.
3. 파티셔닝 적용 시 고려해야 할 요소들
제가 생각할 때 파티셔닝을 적용할 때 고려해야하는 사항은 다음과 같습니다.
3.1 파티셔닝 전략(Partitioning Strategies)
데이터를 어떤 기준으로 분산시킬지 결정하는 것입니다.
균등하지 않은 데이터 분배는 한 노드에 과부하를 초래할 수 있기 때문에 목적에 맞는 전략을 이용하는 것이 중요합니다.
3.2 핫 스팟(Hot Spot)
모든 데이터가 균등하게 분산되었다 하더라도, 특정 데이터에 대한 접근이 압도적으로 높다면 파티셔닝의 효과를 제대로 누리지 못합니다.
그러므로 이에 대한 고려가 생길 수 있습니다.
3.3 리밸런싱(Rebalancing)
노드를 추가 함에 따라 기존 노드에 있던 데이터들을 새로운 노드로 옮기는 리밸런싱 과정은 발생할 수 밖에 없습니다.
리밸런싱이 일어나는 동안에는 많은 양의 데이터가 이동함에 따라 부하가 평소보다 심할 것이기 때문에 취약할 수 있기 때문에 이에 대해 알고 있는 것이 중요합니다.
3.4 Scatter/Gather 모델
파티션 키 없이 수행되는 쿼리는 모든 샤드에서 검색 후 결과를 집계하는 Scatter/Gather 모델을 사용해야 합니다.
이는 트래픽을 분산시키는 파티셔닝의 목적을 제공할 수 없으므로 확장성 측면에서 좋지 않을 수 있습니다.
어플리케이션의 대부분의 쿼리가 Scatter/Gather 모델이라면 이에 대한 고려가 필요할 수 있습니다.
3.5 요청 라우팅(Request Routing)
쿼리를 처리하기 위해 적절한 샤드에게 요청을 전달하는 것이 필요합니다.
단순히 클라이언트 측에서 모든 샤드에 대한 연결 정보를 관리하는 것은 복잡성을 유발하기 때문에 라우팅 전략을 세우는 것이 필요할 수 있습니다.
4. 파티셔닝 전략 상세 분석
4.1 Hash 기반 파티셔닝
이 전략은 데이터를 해시 함수를 통해 샤드에 분배합니다.
데이터 분산에 효과적이지만, 범위 쿼리 처리와 해시 함수의 오버헤드에 취약합니다.
이를 극복하기 위해 샤드 내에 세컨더리 인덱스의 활용이나 리소스를 적게 사용하는 효율적인 해시 함수의 선택이 중요합니다.
4.2 Range 기반 파티셔닝
데이터를 키의 범위에 따라 분배하는 전략으로, 범위 쿼리에 강점을 가집니다.
그러나 불균등한 데이터 분배 문제를 초래할 수 있으므로, 적절한 범위 설정과 분배 전략이 필요합니다.
예시로 Auto Increment 칼럼을 가지고 Range 파티셔닝을 하게되면 마지막 파티션만 비정상적으로 커질 수 있습니다.
4.3 Look up 기반 파티셔닝
Mapping Table 을 사용하여 데이터가 어떤 샤드로 가야 할지 결정합니다. 유연성이 높지만, Mapping Table 이 단일 실패 지점이 될 수 있으므로, 고가용성과 성능 최적화를 고려한 설계가 중요합니다.
5. 핫 스팟(Hot Spot)
균등하게 데이터를 분배했더라도, 특정 데이터에 대한 접근이 비정상적으로 많은 경우는 존재할 수 있습니다.
Hot Spot 에 대한 해결법은 요청이 읽기냐 쓰기냐에 따라 다릅니다.
읽기 작업의 경우에는 Replication 을 늘려서 분산 시키는 것이고, 쓰기 작업의 경우엔 파티션 키에 랜덤 숫자인 Salted Key 를 붙혀서 여러 파티션으로 분산 시키는 방법이 있습니다.
Salted Key 의 경우에는 나중에 읽을 때가 문제이므로 이에 대한 메타 정보 관리 비용이 증가할 수 있습니다.
6. 리밸런싱 전략
리밸런싱은 시스템의 데이터의 양이 늘어나거나 노드 구조에 변화가 있을 때 데이터를 새롭게 재배치하는 것을 의미합니다.
리밸런싱 전략을 잘 선정하고 실행하는 것은 시스템 성능에 큰 영향을 미칩니다.
잘못된 예시로 단순히 mod % N (노드의 수) 으로 데이터를 분배한다면 노드 수가 변경됨에 따라 모든 데이터가 리밸런싱 되는 과정이 발생할 것입니다.
그러면 리밸런싱 중에는 막대한 양의 데이터 이동으로 인해 읽기/쓰기 요청을 처리하기 힘들어질 수 있으므로 이런 방식은 사용하지 않는 것이 좋습니다.
리밸런싱을 하는 전략은 다음과 같이 크게 세 가지가 있습니다.
6.1 정적 파티셔닝 (Fixed Number of Partitioning)
이 전략은 미리 정해진 최대 파티션 수를 유지하는 방식입니다.
새로운 노드가 추가되면 기존 노드의 파티션 일부를 이동시키는 식으로 운영합니다.
운영적으로 간단하지만, 최대 파티션의 수를 정하는 문제와 일부 파티션이 과도하게 커지는 문제가 발생할 수 있습니다.
6.2 동적 파티셔닝 (Dynamic Partitioning)
이 방식은 데이터의 양에 따라 파티션이 자동으로 분할되는 방식입니다.
데이터가 증가하면 파티션은 쪼개지고 새롭게 만들어진 파티션은 적절한 노드에 분배하여 시스템이 균등하게 트래픽을 받을 수 있도록 유지할 수 있습니다.
MongoDB와 HBase가 이 방식을 사용합니다.
6.3 노드 비례 파티셔닝 (Partitioning Proportionally to Nodes)
노드당 고정된 수의 파티션을 유지하며, 노드 추가 시 기존 노드의 파티션 일부를 새 노드로 이동시킵니다.
이 방식은 균형 잡힌 데이터 분포를 유지하는 데 유리하지만, 노드 추가 시 데이터 분배의 불균형을 초래할 수 있습니다.
그러나 일반적으로 노드 당 파티션의 수가 많은 편이라서 (Cassandra 의 경우에는 노드 당 256 개의 파티션을 가집니다.) 괜찮은 편입니다.
7. Scatter/Gather 모델의 효율적 관리
하나의 쿼리를 처리하기 위해서 모든 파티션에서 검색이 된 후 결과를 집계해서 반환하는 처리 모델을 Scatter/Gather 모델이라고 합니다.
이런 모델은 쿼리에 파티션 키가 없기 때문에 모든 파티션들을 조회해야합니다.
여러 파티션들에서 병렬로 조회하고 집계되기 때문에 크게 문제는 없어보이지만 좋은 처리 모델은 아닙니다.
결국 트래픽을 분산시키기 위해서 파티셔닝을 사용하는데 모든 파티션에서 이를 처리하는 것은 확장성 있는 방식은 아니기 때문입니다.
Scatter/Gather 모델을 해결하는 방법으로는 AWS DynamoDB 가 이용하는 Global Index 를 사용하는 방법이 있습니다.
Global Index 는 모든 파티션들에 있는 데이터에 대해 색인을 생성하는 것을 말합니다. 하나의 노드에서 모든 색인 정보를 가지고 있는 건 무리니 각 노드마다 색인의 범위를 나눠서 관리합니다.
예시로 자동차의 색상을 기준으로 글로벌 인덱스를 생성한다면 A 노드에서는 자동차의 색상 중 Red 에 대한 정보만을 유지할 것이고, B 노드에서는 색상 중 Yellow 에 대해서만 유지하는 식으로 관리합니다. (이 예시를 기준으로는 파티션 키는 자동차 id 일 것입니다.)
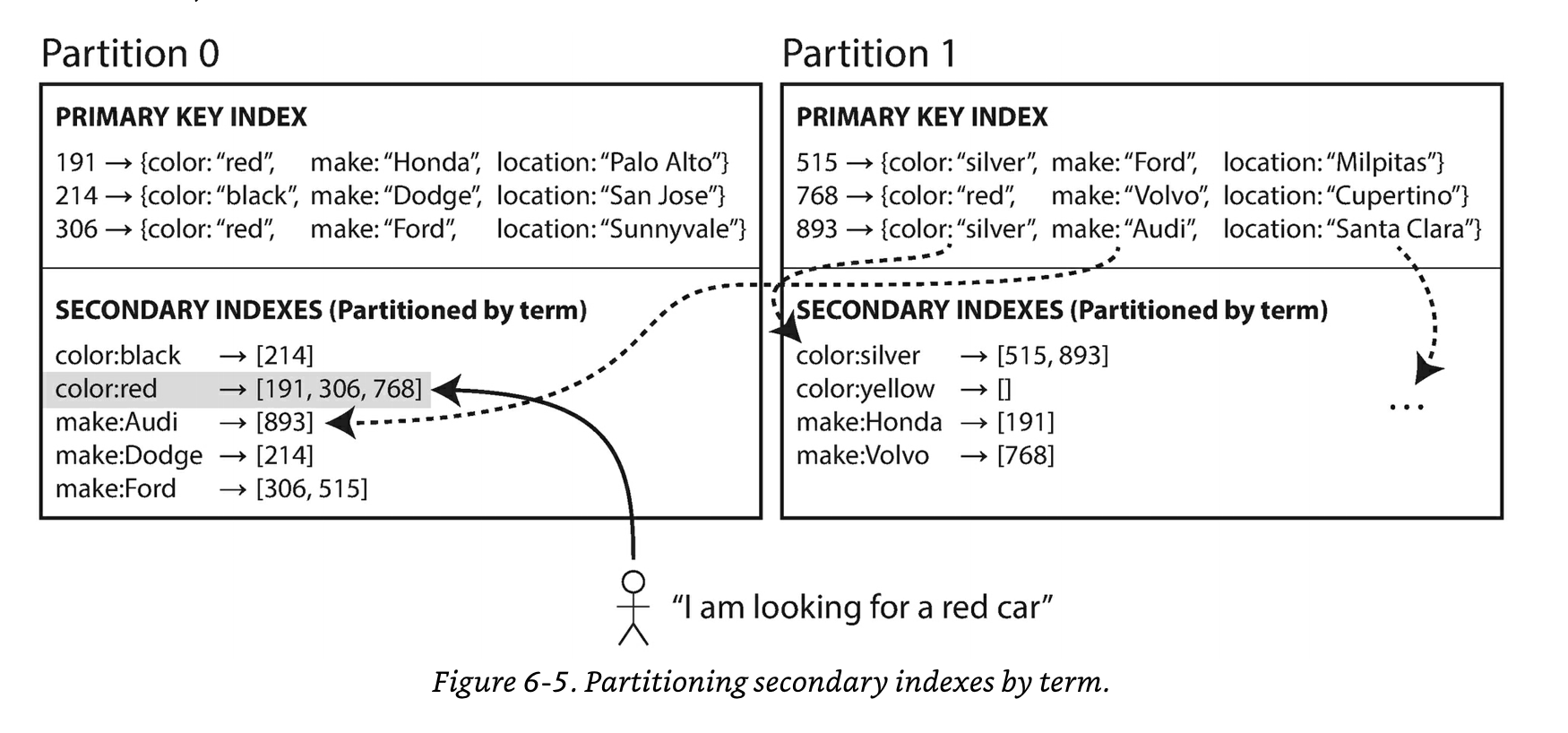
이 방식 말고도 CQRS (Command and Query Separation) 패턴을 이용해서 별도의 조회 모델을 만드는 것도 방법일 수 있습니다.
8. 요청 라우팅(Request Routing)의 중요성
요청 라우팅이란 데이터베이스 시스템에서 쿼리가 적절한 샤드로 정확하게 전달되도록 하는 과정입니다.
파티셔닝 전략에 따라서 데이터를 어떤 샤드에 보내야할 지 결정했다 하더라도 실제 샤드가 어느 노드에 있는지에 대한 연결 정보를 알아야 데이터를 보낼 수 있습니다.
이런 연결 정보를 아는 방법으로는 가장 간단하게는 클라이언트에서 연결 정보를 가지고 있는 것인데, 리밸런싱으로 인해 샤드의 위치가 달라질 수 있기 때문에 연결 정보를 동적으로 갱신할 수 있도록 하는 것이 필요합니다.
그러나 이렇게 기능을 넣다보면 샤드와 연결하기 위한 클라이언트가 복잡해지는 문제가 생깁니다.
이런 클라이언트의 복잡성을 줄이기 위해서 연결 라우팅을 담당하는 Reverse Proxy 를 쓰거나 아니면 Cassandra 나 Redis Cluster 에서 지원하는 Gossip Protocol 을 사용하는 방법이 있습니다.
이렇게하면 클라이언트는 어떠한 노드와 연결해도 상관이 없습니다.
내부 노드들끼리 연결 정보를 공유하고 있어서 자신이 처리하지 못하는 데이터라면 다른 노드들에게 요청을 새로 전달하도록 만들어서 이를 처리하도록 할 것입니다.
https://www.youtube.com/watch?v=WCwPSVu8mH8&list=LL&index=2&t=421s
'System Design > General' 카테고리의 다른 글
| (1) Apache Flink 논문 리뷰 - 컴퓨터 세계를 완전히 변화시킨 25개의 논문 (0) | 2024.05.20 |
|---|---|
| Data Store Internals (0) | 2024.04.05 |
| 기본적인 시스템 규모 확장을 위해 사용하는 기법 (0) | 2024.04.01 |
| Transactional Outbox Pattern (0) | 2023.12.20 |
| Retry 를 잘하는 방법 (0) | 2023.11.20 |