요청이 실패했을 때 취할 수 있는 전략은 많다. (e.g Fallback, Failover, Cancel 등)
여기서는 그 중 하나인 Retry 를 소개하고 이를 잘 사용하는 방법에 대해서 알아보자.
When to retry
Retry 를 할 수 없는 상황도 많다.
예시를 들면 Retry 를 통해서 요청이 여러개가 서버에 들어가게 되서 '중복 처리' 와 같은 사이드 이펙트가 발생하는 경우.
즉 API 를 제공하는 서비스가 Idemopotent Operation 을 지원하지 않는다면 Retry 를 신중하게 해야한다.
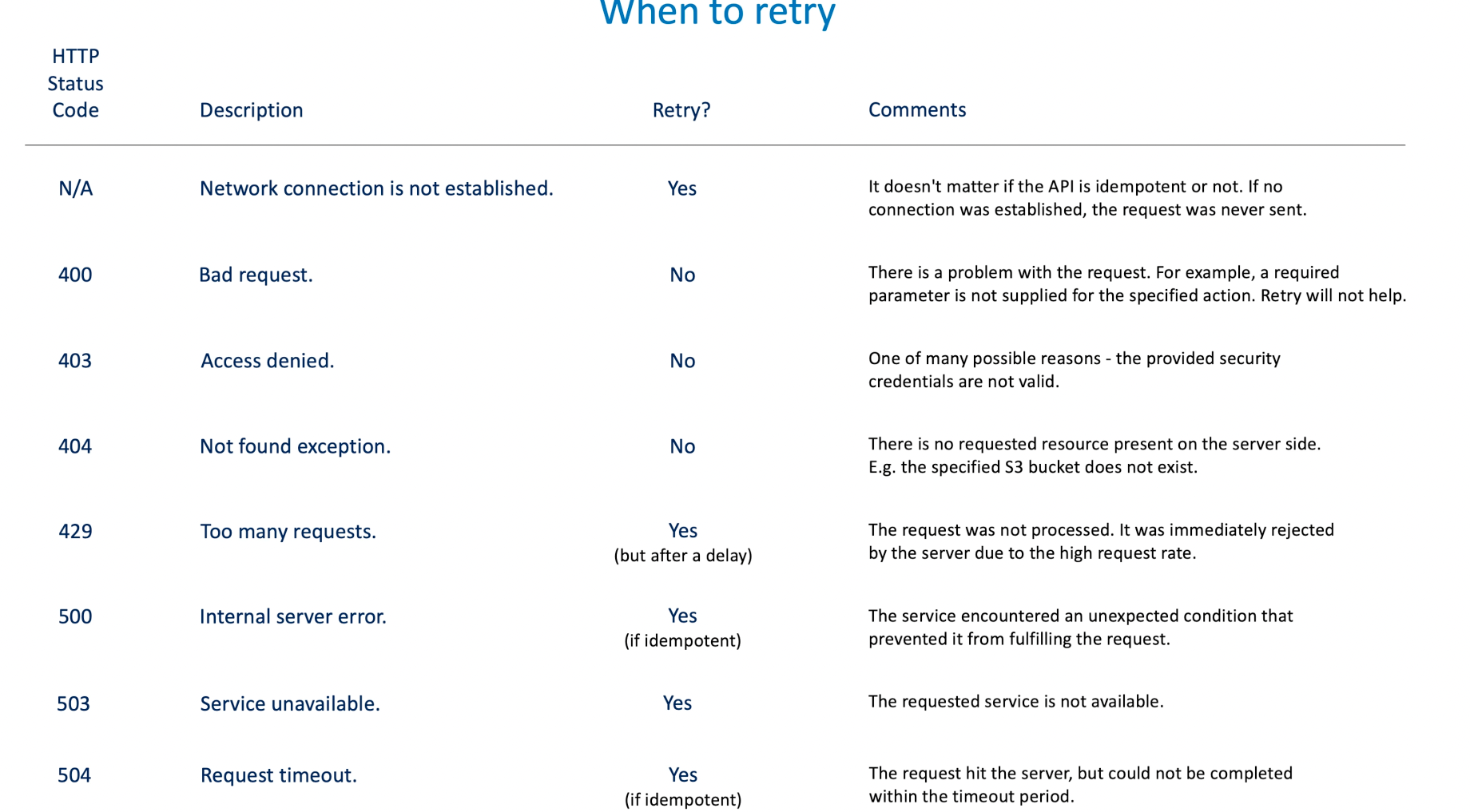
Idemopotent Operation 을 지원하지 않는 서비스의 경우 Retry 를 해도 되는지 판단하기 위한 정보로는 Status Code 가 있다:
Status Code값이 일반적인 4XX 라면 재시도를 해도 똑같이 실패할 것이기 때문에 재시도는 의미없다. 그러나 429 에러는 서버의 부하가 많은 상황이기 때문에 일정 시간 이후에 재시도를 하면 된다.- 500 에러는 처리하다가 죽었을 수 있기 때문에 멱등성 연산을 지원한다면 Retry 를 할 수 있다.
- 504 에러는 요청이 들어갔을 수 있기 때문에 멱등성 연산을 지원한다면 Retry 를 할 수 있다.
- 503 에러는 요청 자체를 받지 못한 것이기 때문에 그냥 Retry 를 해도 된다.
번외로 Idemopotent Operation 을 가진 API 를 만들기 위한 방법으로는 요청을 보내는 사람은 Unique Request Id 를 담아서 보내고, 요청을 처리하는 서버는 이를 Cache 로 가지고 있는 것이다. AWS API 의 경우에는 이를 10-15 분 정도 유지하고 있다고 한다.
How to Retry
Retry 를 해도 괜찮은 상황이라고 판단했으면 이제 Retry 를 잘해야한다.
Retry 를 할 때 고려해야 할 사항은 다음과 같다:
- Expotional backoff
- Retry Limited Count
- jitter
Expotional backoff:
- Retry 에 일정시간 딜레이를 주는 것을 말한다. 서버가 많은 부하 때문에 요청을 처리하지 못하는 경우가 많기 때문에 일정시간 지연을 주는 것이다.
- 지연은 Retry 마다 지수적으로 증가한다. 즉 처음에는 1초동안 기다려보고, 두 번째 Retry 에는 2초, 세 번째 Retry 는 4초, 네 번째 Retry 는 8초 이렇게 기다리는 것이다. (이렇게 증가시키는 이유는 추측인데 상황이 아직 좋아지지 않았으니가 Retry 를 하는 것일테니 좀 더 기다려보자는 취지에서 하는 것 아닐까?)
jitter:
- 모든 요청들이 동시적으로 Retry 를 하지 않도록
Expotional backoff외에 random delay 를 추가적으로 주는 것이다. - jitter 이 없다면 요청들이 동시적으로 Retry 되면서 특정 시간의 주기에만 트래픽이 급증할 것이다. (트래픽이 급증하면 또 요청을 처리 못할 수 있으니)
Retry Limited Count:
- Retry 를 하는 횟수를 말한다. 이게 없으면 무한적으로 Retry 를 하면서 자원을 점유할 것이다.
'System Design > General' 카테고리의 다른 글
| (1) Apache Flink 논문 리뷰 - 컴퓨터 세계를 완전히 변화시킨 25개의 논문 (0) | 2024.05.20 |
|---|---|
| Data Store Internals (0) | 2024.04.05 |
| 기본적인 시스템 규모 확장을 위해 사용하는 기법 (0) | 2024.04.01 |
| 파티셔닝: 대규모 시스템의 핵심 전략 (0) | 2023.12.23 |
| Transactional Outbox Pattern (0) | 2023.12.20 |