
Log
카프카에서는 데이터를 저장하기 위해 내부적으로 Log 파일을 사용한다.
모든 데이터를 메모리에만 저장했을 떄의 문제점은?
- 메모리 공간만큼만 데이터를 저장할 수 있다. 이것보다 더 빠르게/빈번하게/크게 요청이 온다면 데이터를 저장할 수 없다. 그래서 디스크도 같이 사용해야함.
- 데이터를 저장하고 있는 Broker 가 Crash 난다면 해당 데이터는 잃어버릴 수 있음 (Durability 문제)
Log 는 그래서 어떤 자료구조인데?
- 메모리에서 Array 형식으로 저장하는 Queue 를 이용하는 것과 유사하게, 로그는 File 의 끝에 데이터를 추가하는 식으로 순서대로 적재한다.
- 저장된 데이터는 유일하게 식별되기 위해서 단조적으로 증가하는 Unique 한 identifier 를 사용한다.
- WAL (Write-Ahead Log), Journal 로그라고도 불린다.
Log 는 하나의 거대한 파일을 말하는건가?
아니다. Log 파일은 Segment 로 분리해서 가지고 있다.
이유는 다음과 같다:
- 하나의 거대한 파일이라면 메모리에 올려놓기가 부담스러움.
- 필요없는 데이터들은 지워줘야하늗네, 하나의 파일만 쓴다면 동시성 문제가 발생함. (이 작업을 Compaction 작업이라고도 한다.)
Log 파일에서는 어떻게 데이터를 읽는데? 파일의 모든 내용을 읽어서 원하는 데이터를 찾는가?
이런 방식으로 읽으면 성능이 나오지 않는다.
그래서 Log 파일 같은 경우는 데이터가 파일 내의 “어느 위치에 있는지” 알려주는 인덱스를 사용한다.
이 인덱스에는 해당 데이터가 어떤 파일에 있는지, 파일 내에 위치는 어딘지 (= 파일 오프셋을 말함) 정보가 들어가있다.
Log 인덱스 파일은 어떻게 구조화되어 있는데?
인덱스 파일을 만드는 방법은 여러가지가 있다:
- Sparse Index 를 사용하는 방법:
- 데이터는 단조적으로 증가하는 Unique Identifier 로 구별되니까, 모든 데이터를 인덱스로 만드는 게 아닌 일부 데이터만을 인덱스로 만드는 방법이다.
- 이 방법은 모든 데이터를 인덱스에 저장하진 않는다. 그러므로 검색 속도는 약간 희생되지만 보다 저장 공간을 효율적으로 관리하는 방법이다.
- 일부 데이터만을 인덱스로 만들기만 해도 어디부터 읽으면 되는지 알 수 있으니까 기존 검색 방법보다 훨씬 빠르다.
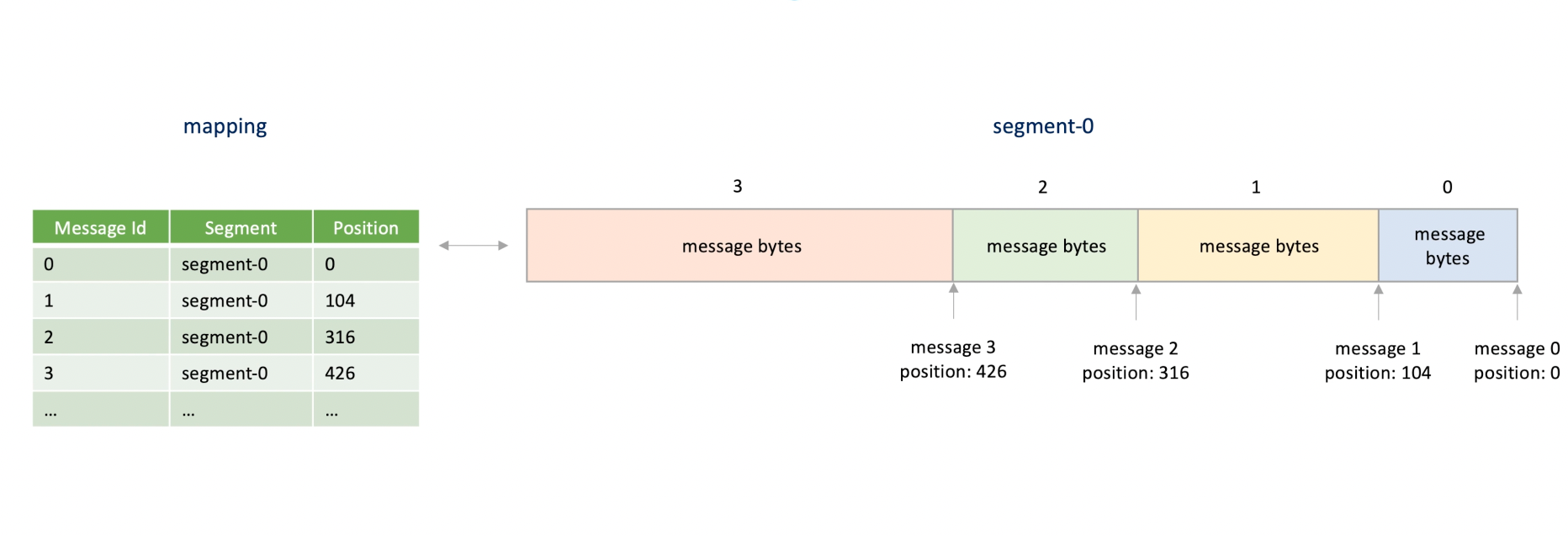
- Hash Table 을 사용하는 방법:
- 이것도 두 종류로 나뉜다:
- 1) 하나의 인덱스 파일에 모든 Segment 파일 데이터를 인덱스로 만드는 방법
- 2) Segment 파일마다 인덱스 파일을 만드든 방법.
- 물론 우리는 하나의 파일에 모든 데이터를 다 넣으면 동시성 문제와 메모리 사이즈 문제를 일으킨다는 걸 안다. 그래서 Segment 마다 인덱스 파일을 만드는 게 낫다.
- 데이터의 Unique Identifier Id 를 Key 로 쓰고, 파일 오프셋 데이터를 value 로 해시 테이블에 저장하는 방법이다.
- 이것도 두 종류로 나뉜다:
Hash Table 주의점: Hash Table 은 메모리 사이즈를 초과할 경우에 굉장히 느려진다.
디스크 저장공간까지 사용해서 해시 테이블을 사용하는 경우에는 디스크 탐색을 Random I/O 를 사용하기 때문임.
디스크 검색에 나름 최적화 된 자료구조인 B-Tree 나 LSM-Tree 는 Linear I/O 를 사용하는 방식이기 때문에 Hash Table 보다 훨씬 낫다.
Hash Table 을 이용해서 Segment 마다 인덱스를 만든다면, 해당 데이터가 어떤 Segment 파일에 있는지는 어떻게 아는데?
가장 최근 인덱스 파일부터 열어보면서 이 데이터 Id 에 대한 파일 오프셋 값을 가지고 있는가? 이렇게 검색하는 방법이 있다. 근데 이 방법은 느림.
그래서 데이터 id 값이 어느 인덱스 파일에 들어있는지 확인하도록 만드는 하나의 매핑 인덱스를 더 만드는 방법이 있음.
매핑 인덱스를 만들 떈 모든 데이터 id 값마다 어떤 인덱스 파일에 들어있는지 기록하는 건 불필요함.
데이터 id 는 단조적으로 증가하는 형태이니까 데이터 id 값의 범위마다 인덱스 파일과 매핑하도록 만들면 훨씬 효율적임.
이 파일에 검색할 때는 Binary Search 를 이용하면 되고.

Time Series Data
Time interval (hours, minutes, seconds 등) 동안에 수집한 데이터들을 말한다. 이런 데이터들은 주로 데이터 분석등에서 사용됨.
예시: 주식의 일주일간의 시간별 time series 데이터
날짜 시간 개장 가격 최고 가격 최저 가격 종가 거래량
2023-04-01 09:00 100 105 99 102 500
2023-04-01 10:00 102 106 101 104 300
2023-04-01 11:00 104 108 103 107 400
2023-04-02 09:00 107 109 106 108 600
2023-04-02 10:00 108 110 107 109 350
2023-04-02 11:00 109 113 108 112 450
...Time Series data 는 크게 두 종류가 있다:
- 정규 시계열 데이터(Regular Time Series)
- 예: 매일 아침 9시의 온도, 매월 첫 번째 날의 주식 종가, 매년 GDP 등)
- 예측 분석, 시계열 모델링, 추세 분석 등에 사용된다.
- 비정규 시계열 데이터(Irregular Time Series)
- 예: 불규칙한 시간에 기록된 거래 데이터, 사건이 발생할 때마다 기록되는 센서 데이터 등
- 특정 사건이나 활동에 대한 반응을 분석할 때 유용
비정규 시계열 데이터는 어떻게 수집하는데?
특정한 이벤트가 발생했을 때 실행되도록 만들어져 있음.
Time Series Data 는 그래서 어떤 식으로 사용되는데?
예시: Youtube 조회수 데이터 수집 및 조회
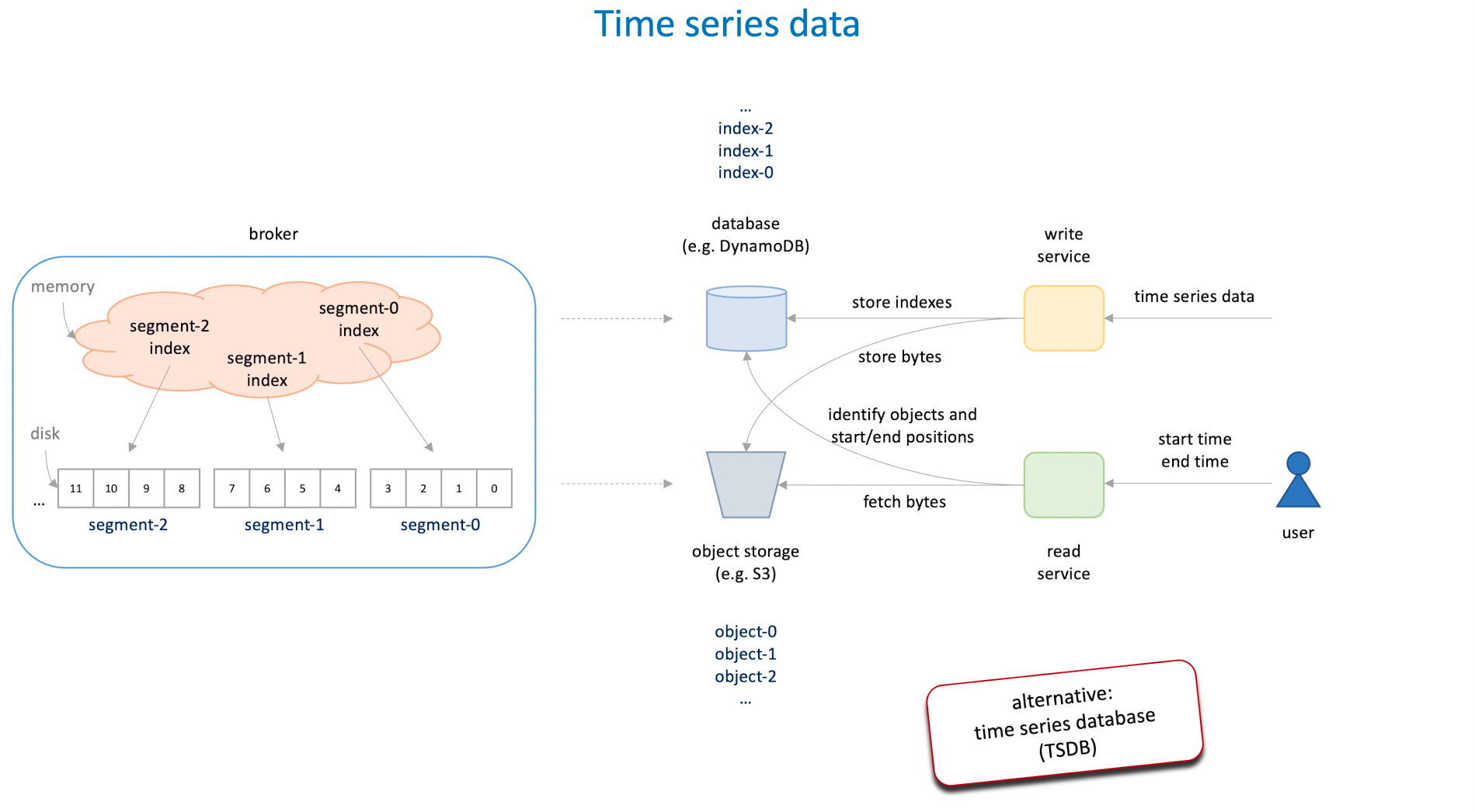
- Write Service:
- 유튜브 조회수 Time series data 를 수집해서 Object Stroage 인 S3 에 저장한다. 그 다음 해당 Object Storage 를 빠르게 조회하기 위해서 대표적인 Low Latency 데이터베이스인 DynamoDB 에 인덱스 값을 업데이트한다.
- 인덱스 데이터는 아래와 같이 저장될 것임. DynamoDB 에서는 파티션 키와 정렬 키를 이용해서 고유하게 식별함.
- Object Storage 는 일정 크기에 도달할 때까지 유튜브 조회수 데이터가 계속 누적되면서 들어갈 거고, DynamoDB 의 인덱스는 시계열 데이터를 수집할 때마다 EndTime 값이 업데이트 될 거임.
{
"VideoID": "VIDEO123", // 파티션 키
"StartTime": 1651363200, // 정렬 키 - 세그먼트 시작 시간의 UNIX 타임스탬프
"EndTime": 1651449599, // 세그먼트 끝 시간의 UNIX 타임스탬프
"ObjectKey": "segment1_2024-04-01", // Object Storage에서 데이터를 찾을 수 있는 키
"Size": 1024, // 세그먼트 데이터의 크기 (예: 바이트)
"Checksum": "abc123", // 데이터 무결성 확인을 위한 체크섬
// 기타 필요한 메타데이터 필드
}- Read Service:
- 사용자가 특정 유튜브 비디오의 조회수를 요청한다면 DynamoDB 에서 Index 를 조회한 후 해당 Object Key 를 가지고 S3 에서 가지고 올 거임.
- 사용자의 요청에는 다음 정보들이 있을거임. (VideoId, Starttime, EndTime) 이 정보를 바탕으로 DynamoDB 에 검색해서 어떤 Object 파일들을 가지고 오면 될 지 파악할거임. (DynamoDB 는 범위 검색이 된다)
- 중요한 점:
- 시계열 데이터는 대량의 데이터가 생성되며 대부분의 과거 데이터는 접근을 하지 않기 때문에 Object Storage 같은 저렴한 저장소를 주로 이용한다.
- 그러나 Low Latency 를 위해서 Index 검색/갱신은 빠르게 하기 위해 DynamoDB 를 쓴다.
Simple Key-Value Database
Log File + Log Compaction 을 이용해서 간단한 CRUD 연산을 하는 Key-Value Datastore 를 만들 수 있다.
이 방식은 Riak 의 기본 스토로지 엔진인 Bitcask 에서 사용되는 방식임.
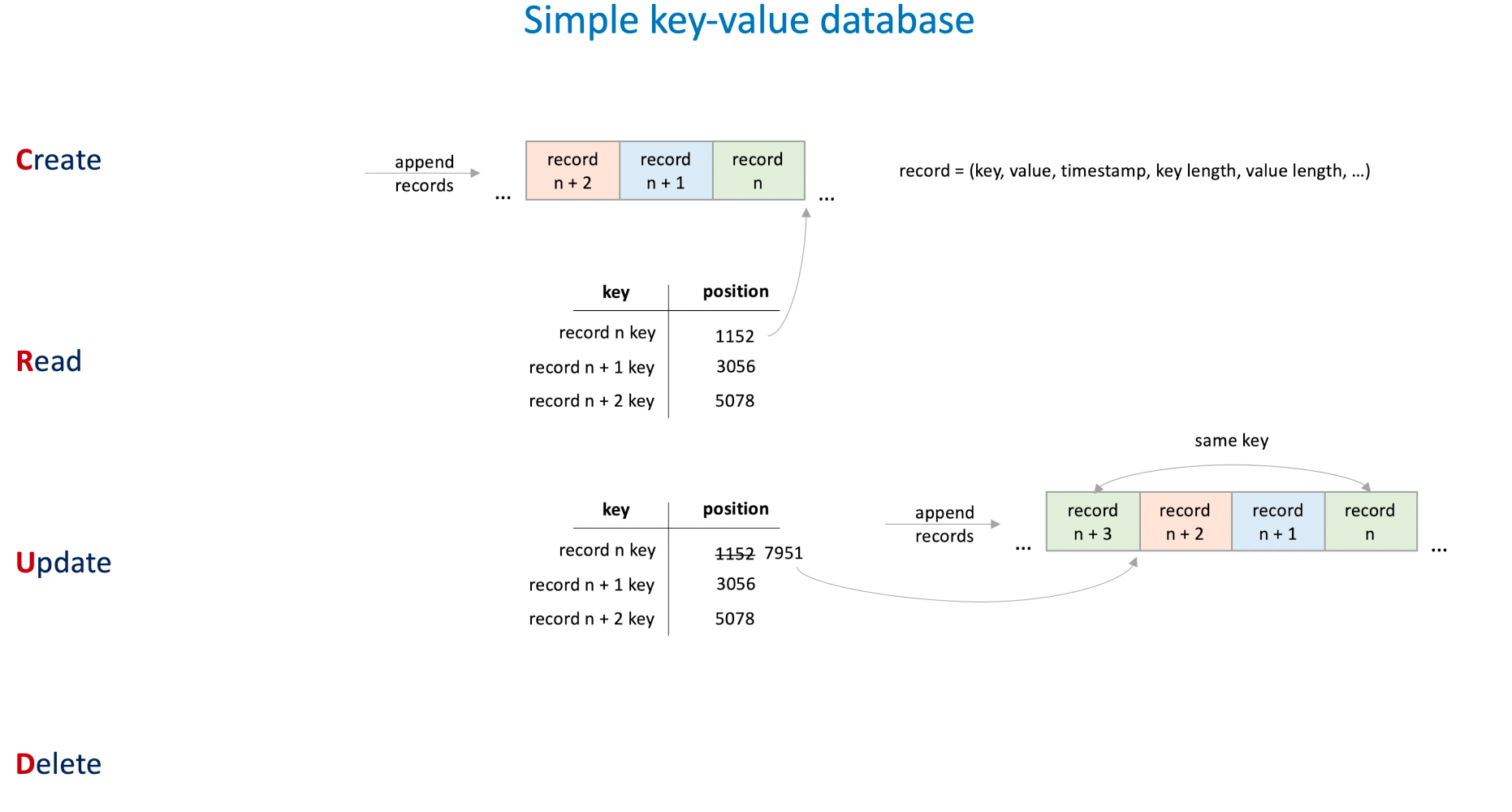
어떻게 만드는데?
CREATE:
- 단순히 Log File 의 끝에다가 쓰면 된다.
READ:
- Hash Table 기반의 Log 인덱스 파일을 만들어서 이를 통해 읽으면 됨.
UPDATE:
- CREATE 처럼 적용하면 된다. 기존에 있던 데이터를 찾는게 아니라 새로운 데이터를 Log File 에 기록하는 것.
- 그리고 인덱슴나 업데이트 해주면 됨.
DELETE:
- Tomestone (묘지) 데이터를 넣는 것. 그래서 누군가 이 데이터에 접근하게 되면 조회될 떄 이거 삭제된거라고 판단하면 됨.
- 이런 식으로 일단 임시적으로 데이터가 지워졌다고 marking 하고 주기적으로 Log File 을 병합하면서 데이터를 지워주면 됨.
Q) 로그 파일의 끝에다가 추가하기만 하면 디스크가 가득차는 문제가 생길 거 같은데?
맞다. 그래서 Log Compaction 작업을 통해서 주기적으로 중복 데이터는 합쳐줘야함.
Log Compaction 은 중복 데이터 중에서 최신 데이터만 남기고 오래된 데이터는 삭제됨. 그리고 tomestone 으로 마킹된 데이터 또한 삭제됨.
Q) Log Compaction 작업은 어떻게 동작하는데?
이 작업을 하는 전용 스레드가 있겠지, 이 스레드가 주기적으로 백그라운드에서 돌면서 새로운 로그 세그먼트 파일을 만들고 오래된 로그 세그먼트 파일부터 최신 로그 세그먼트 파일까지 읽으면서 병합할거임.
Q) 계속 데이터가 추가되면 Index 도 메모리 사이즈를 넘겠네? 그러면 디스크를 쓰게 될거고 성능도 급격히 떨어지는 거 아님?
맞다.
Q) Hash Table 기반의 인덱스라면 단 건 조회는 잘하겠지만, 범위 쿼리는 잘 못하겠네?
맞다.
이 데이터베이스의 특징은 뭔데?
Read 와 Wrtie 가 강하다. 둘 다 시간 복잡도가 O(1) 이니까.
대신에 Read 는 Disk 영역을 안쓴다는 가정하에. (Bitcask 는 이걸 가정함.)
Embedded database
RabbitMQ 와 같은 메시지 브로커는 내부적으로 Embedded database 를 사용한다.
Embedded database 를 사용하는 이유: (vs Remote Database)
- Latency, Throughput:
- 원격 호출을 하지 않는 Embedded database 가 더 성능이 좋음.
- Failure Mode:
- Remote Database 와 Newtork Partition 이 발생하는 문제, 성능 저하가 생기는 문제에 대응해야함.
- Cost:
- 데이터베이스를 확장해서 쓰는 비용이 더 비쌈.
Q) Embedded database 말고 Cache 를 써도 되지 않을까?
Cache 는 자주 접근하는 데이터를 저장해서 부하를 분산하는 목적인데 메시지 브로커는 사용된 메시지는 폐기 시키니까 용도에 맞지는 않은듯?
RocksDB
3가지 구성요소로 이뤄짐:
- Memtable:
- In-memory buffer 로 쓰기 요청을 메모리상에서 유지시킴
- SkipList 나 Self-balancing binary search tree (e.g Red-Black Tree) 로 구성된다.
- Memtable 이 일정 크기를 넘으면 disk 로 flush 되는데 이때 SSTable 형식으로 저장된다:
- Binary Search Tree 는 inorder traversal 하면 정렬된 순서대로 읽을 수 있으니까 SSTable 을 쉽게 만들 수 있음.
- log:
- Write-Ahead Log 로 사용. (쓰기 요청의 durability 를 위해서)
- Memtable 을 복구하는 용도로도 사용한다.
- Memtable 마다 WAL 을 하나씩 가진다고 알면 됨.
- SSTable (Sorted String Table):
- Disk 에 저장되는 구조
- Key-value pair 로 저장되며 key 값으로 정렬되어 저장된다.
Q) RocksDB 는 언제 사용하는데?
고성능의 로컬 스토리지가 필요한 어플리케이션에서 사용됨.
Q) SkipList 와 Self-balancing Binary Search Tree 의 차이점은 뭔데?
둘 다 삽입, 삭제, 검색 연산에 대해 O(logN) 을 보장한다.
그리고 둘 다 SSTable 에 저장될 때도 효율적이다.
- Red-Black Tree 는 inorder 로 순회해서 읽으면 됨
- SkipList 도 가장 낮은 레벨부터 정렬되어 있어서 읽으면 됨
하지만 동시성 제어에서는 SkipList 가 더 뛰어나다.
- SkipList는 기본적으로 여러 레벨의 연결 리스트로 구성되어 있으며, 각 노드는 다음 노드를 가리키는 포인터를 가지고 있다. 이 구조는 동시에 여러 위치에서 삽입이나 삭제 같은 수정 작업이 발생해도, 특정 부분의 리스트만을 잠금(lock)함으로써 동시성 제어를 할 수 있음.
- SkipList는 잠금 세분화를 통해 더 높은 동시성을 지원함. 수정 작업 시, 전체 구조를 잠그는 대신 필요한 노드나 리스트 부분에 대해서만 잠금을 적용할 수 있음.
- Red Black Tree 의 경우에도 노드 단위로 잠그긴 하지만 SkipList 가 더 뛰어남.
그리고 둘 다 Optimistic Locking 을 적용할 수 있다.
Q) 왜 굳이 SSTable 형식으로 저장하는데?
SSTable 이 장점이 많음:
- Compaction 작업이 쉽다. 이미 정렬되어 있으니까 합치는 것도 쉬움. Merge Sort 를 생각해보면 됨.
- 인덱스도 Compact 하다. 모든 데이터를 인덱스에 올려놓을 필요가 없음. Sparse Index 로 구성하는게 가능하다. 여기서 Binary Search 로 검색할거임. 검색 성능도 괜찮음.
Q) 인덱스는 언제 만들어지는데?
인덱스는 SSTable 내에 있음.
인덱스는 각 데이터 블록의 시작 키를 포함하고 있으며, 이를 통해 주어진 키를 포함하는 데이터 블록을 빠르게 찾을 수 있음.
Q) Memtable 이 가득차서 Disk 에 기록될 때 그럼 새로운 쓰기 요청은 어떻게 되는데?
새로운 Memtable 이 만들어져있을 거고 거기에서 쓰기 요청을 받을거임.
Q) Read 요청은 어떻게 처리하는데?
Memtable 에서 먼저 검색한다. 없으면 디스크에서 SSTable 을 순차적으로 읽어온다
Q) 그러면 Read 요청이 엄청 느려질 수도 있겠네?
맞다. 그래서 추가적으로 BloomFilter 를 쓴다. 이를 통해서 RocksDB 에 없는 데이터는 금방 파악할 수 있음.
Page Cache
비효율적인 디스크 접근 방식:
- Too Many Small I/O:
- 작은 데이터를 빈번하게 디스크에 접근해서 가지고 올 경우에 처리량이 안나올거임.
- 이 문제를 해결하는 건 Batch. 즉 디스크의 데이터를 저장할 때나 읽어올 때 Batch 로 한번에 읽어오는 것.
- Excessive byte copying:
- 네트워크를 통해 데이터를 보낼 때 주로 발생한다. 디스크 데이터가 네트워크 인터페이스 카드로 복사될 때 Byte Copy 가 많이 일어나기 때문에.
- 이 문제를 해결하는 건 Zero Copy 임. 복사 없이 내보낼 수 있도록 하는 것.
Page Cache 를 이용해서 Disk 에 적재할 때 장점:
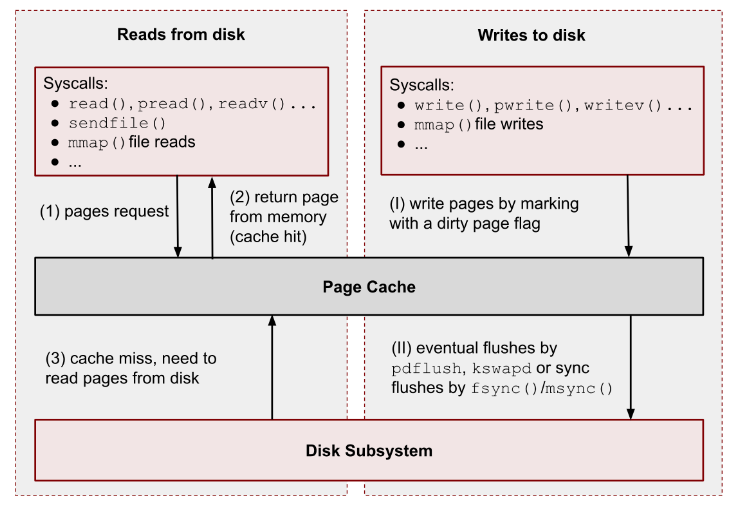
- OS 는 Page Cache 를 디스크에 저장할 떄 write 의 과정을 최적화 (= 정렬) 해서 시도하는 것.
디스크에서 데이터를 읽어서 네트워크로 전송하는 과정에서는 4번의 바이트 카피가 일어난다:
- Zero Copy 는 이런 불필요한 바이트 카피를 줄여준다. 대신에 조건이 있긴 함. 데이터를 변경하거나 조작하지 않을 때 즉 필터링하거나 데이터를 transform 하지 않을 때.
Page Cache 를 이용할 떄 아직 디스크에 반영되지 않았더라면 데이터 손실은 발생할 수 있다. 이 경우에 어떻게 해결하는가?
- MongoDB 는 Log File (= Journal) 에 기록하는 것을 기다리는 것으로 해결할 수 있음.
- Apache Kafka 는 Data Replication 을 통해서 보장할 수 있다. (동시에 죽지 않는다는 가정하에)
'System Design > General' 카테고리의 다른 글
| 7 Must-know Strategies to Scale Your Database (0) | 2024.06.16 |
|---|---|
| (1) Apache Flink 논문 리뷰 - 컴퓨터 세계를 완전히 변화시킨 25개의 논문 (0) | 2024.05.20 |
| 기본적인 시스템 규모 확장을 위해 사용하는 기법 (0) | 2024.04.01 |
| 파티셔닝: 대규모 시스템의 핵심 전략 (0) | 2023.12.23 |
| Transactional Outbox Pattern (0) | 2023.12.20 |