이 글은 Advanced RAG Series: Retrieval 포스팅을 보고 정리한 글입니다.
Retrieval 과정에서는 Retrieval 한 이후 Post Processing 이 중요하다:
- 사용자의 쿼리와 관련있는 Top K 개의 Chunk 를 뽑아오더라도, 이게 Context Window 공간과는 아직 안맞을 수 있으므로 좀 더 후처리가 필요하다고 함.
계속해서 누누히 말하지만 LLM 영역에서 확실하게 올바른 방법은 아직까지는 없음. UseCase 나 Document 데이터에 따라서 더 나은 방법이 다를거임.
Reranking 방법:
- Retrieval 한 데이터에서 다시 ranking 을 매기는 reranking 방법은 효율적일 수 있다고 함.
- raranking 하는 방법도 여러가지가 있음. 하나씩 살펴보자.
Reranking 1) Increasing Diversity:
- Increasing Diversity:
- Maximum Marginal Relevance (MMR) 공식을 이용해서 Retrieval 한 데이터를 최대한 관련성이 높고, 다양성 또한 높은 문서를 고르도록 하는 방법임.
- 중복되는 문서를 제거하기 위한 방법.
- 주로 두 가지 변수에 의해서 제어된다. a) 쿼리와의 문서와의 유사성이 높은 문서, b) 이미 선택된 문서와 연관이 적은 문서
- Haystack 에서 제공해주는 DiversityRanker 를 이용해서 이를 구현할 수 있다고 함.
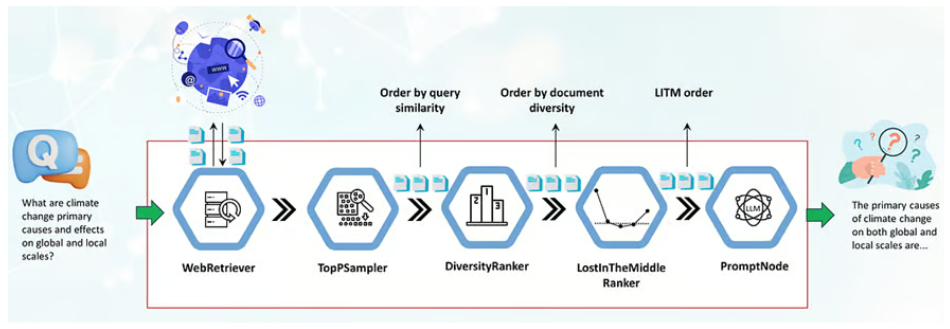
Reranking 2)LostInTheMiddleReranker:
- LLM 은 Retrieval 한 문서에서 처음과 끝이 아닌 중간에 있는 문서의 경우에는 잘 활용하지 못한다는 특징을 사용하는 기법임. 가져온 문서에서도 다시 재랭킹을 해서 문서의 처음과 끝에 중요한 문서를 배치하도록 하는 기법.
- 앞의 기법인 Increasing Diversity 와 같이 사용하는 걸 추천한다고 한다.
Reranking 3)Cohere Rerank:
- RAG 에서 Vector Database 에서 검색한 문서에 대해 재랭킹을 적용하는 기법임. 재랭킹을 할 때 초기 사용자 쿼리와 문서를 다시 관련성을 비교해서 재랭킹하는 것.
- 벡터 간 검색을 한 이후에 Cohere Rarank 라는 기법을 한번 더 적용시키는 거임.
- 벡터 간 검색도 유사도를 판단하지만, 단어의 빈도나 위치에 의존해서 의미적인 맥락을 충분히 반영하지 못할 수 있음. 그래서 Cohere Rerank 를 적용해서 의미적인 비교까지 하는거임.
LangChain 에서 Cohere Rerank 를 사용하는 예시는 다음과 같음. 여기에서는 Compression 매커니즘도 적용됨.
from langchain_community.llms import Cohere
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
compressor = CohereRerank(model="rerank-english-v2.0", top_n=3)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(question)
prompt = ChatPromptTemplate.from_template(
"""
Asnwer the given question using the provided context.\n\nContext: {context}\n\nQuestion: {question}
"""
)
cohere_with_rag_chain = (
{'context': compression_retriever, 'question': RunnablePassthrough()}
| prompt
| ChatOpenAI(model='gpt-4', temperature=0)
| StrOutputParser()
)
cohere_with_rag_chain.invoke(question)
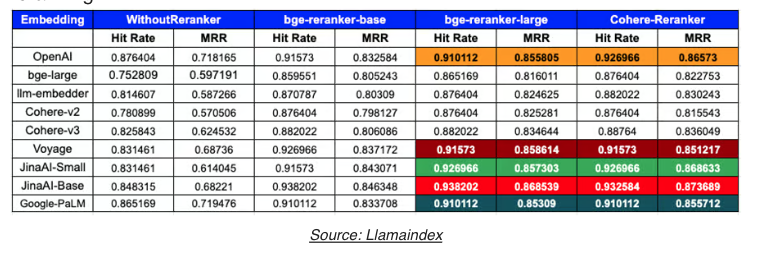
Reranking 4) bge-rerank:
- 여러가지 Rerank 매커니즘을 사용하는 것과 rerank 알고리즘과 시너지를 내는 임베딩 모델을 같이 사용하는 것도 중요하다.
- 다음과 같이 여러 알고리즘과 embedding 모델을 이용해서 평가해보고 우리의 데이터에 가장 잘 맞는 알고리즘과 임베딩 모델을 선택하자.
- 평가에 사용할 수 있는 기준은 Hit Rate 와 MRR (Mean Reciprocal Rank) 가 있다. Hit rate 는 top k 문서 안에 포함되느냐 를 평가한 지표이고, MRR 은 관련된 문서의 랭킹을 이용한 점수이다.
Reranking 5) mxbai-rerank-v1:
- 현재 가장 성능이 좋다고 알려진 rerank 알고리즘임.
Reranking 6) RankGPT (GPT 3.5):
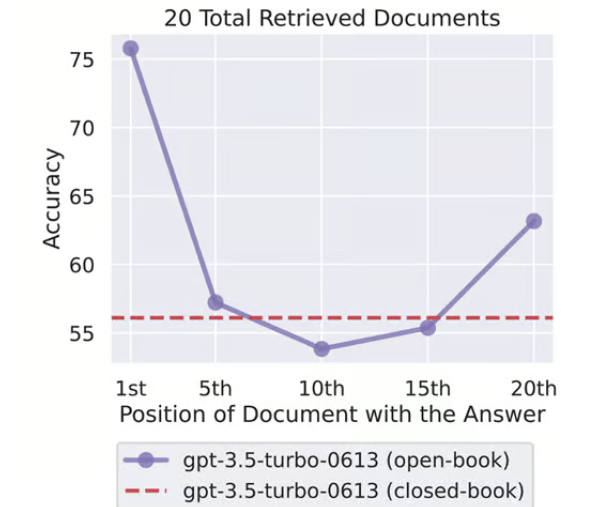
- GPT 3.5 를 ranking 에 rerank 에 사용할 경우 Cohere rerank 보다 훨씬 더 랭킹을 잘 매긴다고 함.
- GPT 3.5 의 context window 를 극복하기 위한 방법으로는 sliding window 기법이 있음. 아래 이미지와 같이 나오는거지만 누적식으로 랭킹을 매겨서 랭킹 범위를 벗어나는 문서는 제외하는 기법임.
- 이런 기법을 사용할 경우 훨씬 더 간단하지만 비용적인 측면이나 latency 측면이 더 많이 나온다는 문제점도 있다.
- https://arxiv.org/abs/2304.09542?utm_source=div.beehiiv.com&utm_medium=referral&utm_campaign=advanced-rag-series-retrieval

Prompt Compression:
- 관련된 Doucument 를 조회한 이후 쿼리와 연관이 없다고 생각하는 부분은 compression 하는 방법이다.
- 이를 위한 여러가지 기법들이 있음.
Prompt Compression 1) LongLLMLingua:
- 문서를 처음에는 크게 압축하면서 직접적으로 관련이 없는 정보를 대량으로 제거한다. 그 다음 두 번째에는 남은 정보를 세밀하게 분석해서 주요 정보는 유지하면서도 세밀하게 압축을 한번 더 한다.
- 압축을 수행할 때는 사용자의 질문과의 관련성을 고려해서 압축한다. 질문과 관련이 있는 부분은 압축이 되지 않고, 질문과 관련이 없는 부분은 더 압축됨.
- 문서의 각 부분이 가진 중요도에 따라서 압축 비율은 다르게 적용됨. 중요한 부분은 덜 압축되고, 중요하지 않은 부분은 더 압축된다.
- 압축 후에는 평가를 거쳐서 중요한 정보가 손실되었는지 확인하고 복구 매커니즘을 해서 중요한 정보가 사라지지 않도록 만든다.
- 압축되고 난 이후 문서를 재정렬(reranking) 을 해서 더 중요한 문서가 더 앞단에 오게 만든다.
- 특히 긴 문서에서 효과적이라고 함.
- https://arxiv.org/abs/2310.06201?utm_source=div.beehiiv.com&utm_medium=referral&utm_campaign=advanced-rag-series-retrieval
Prompt Compression 2) RECOMP
- compressors 를 사용해서 문서에서 핵심 문장을 추출하거나, 여러 문서를 종합해서 재구성해서 요약본을 만드는 두 가지 방법을 지원함.
- RECOMP 는 두 가지 압축 방법 중 하나를 적용하면 됨.
- Extractive Compressor:
- 문서에서 사용자의 쿼리와 관련 있는 문장을 선택해서 요약을 만듬.
- Abstractive Compressor:
- 여러 문서를 종합해서 새로은 요약을 만들어낸다. 단순히 종합해서 새로운 요약을 만들어내는게 아니라 이해하고 이를 재구성한다.
- Extractive Compressor:
- https://arxiv.org/abs/2310.04408?utm_source=div.beehiiv.com&utm_medium=referral&utm_campaign=advanced-rag-series-retrieval

Prompt Compression 3) Walking Down the Memory Maze
- 이 방식은 일단 Indexing 단계에서 Chunking 을 요약-트리 구조로 저장해둬야 함.
- 그러니까 문서가 일정한 크기의 Chunk 로 쪼개지면, Chunk 를 합친 상태로 요약한 부모 Chunk 로 이뤄지는 식으로 문서를 저장해둠.
- 이렇게 저장해둔 상태에서 이제 사용자가 검색을 하면 최상단의 요약된 Chunk 부터 순회하면서 질문과 연관성이 있는 CHunk 를 찾아 나서는거임.
- 특히 이 방법은 긴 문서에서 효과적이라고 함.
RAG-fusion 기법:
- 사용자의 질문을 다양한 관점에서 여러개의 쿼리로 생성한 이후, 각각의 쿼리를 Vector Store 에 검색하고, RRF 에 따라 문서의 랭킹을 매겨서 문서를 사용하는 기법임.
- https://towardsdatascience.com/forget-rag-the-future-is-rag-fusion-1147298d8ad1
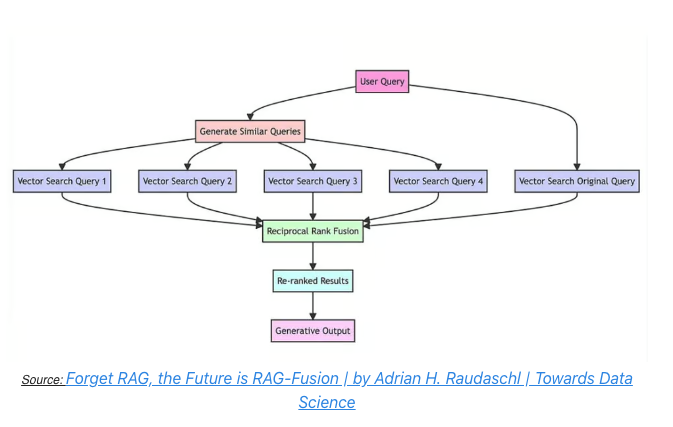
RAG Fusion 의 Reciprocal Rank Fusion 정렬 알고리즘을 사용하는 예제는 다음과 같음:
def rrf(results: List[List], k=60):
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_results
from langchain.prompts import ChatPromptTemplate
question = "What is QLoRA?"
prompt = ChatPromptTemplate.from_template(
"""
You are an intelligent assistant. Your task is to generate 4 questions based on the provided question in different wording and different perspectives to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}
"""
)
generate_queries = (
{"question": RunnablePassthrough()}
| prompt
| ChatOpenAI(model='gpt-4', temperature=0.7)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
fusion_retrieval_chain = (
{'question': RunnablePassthrough()}
| generate_queries
| retriever.map()
| rrf
)
fusion_retrieval_chain.invoke(question)
def format_context(documents: List):
return "\n\n".join([doc[0].page_content for doc in documents])
prompt = ChatPromptTemplate.from_template(
"""
Asnwer the given question using the provided context.\n\nContext: {context}\n\nQuestion: {question}
"""
)
rag_with_rrf_chain = (
{'context': fusion_retrieval_chain | format_context, 'question': RunnablePassthrough()}
| prompt
| ChatOpenAI(model='gpt-4', temperature=0)
| StrOutputParser()
)
rag_with_rrf_chain.invoke(question)
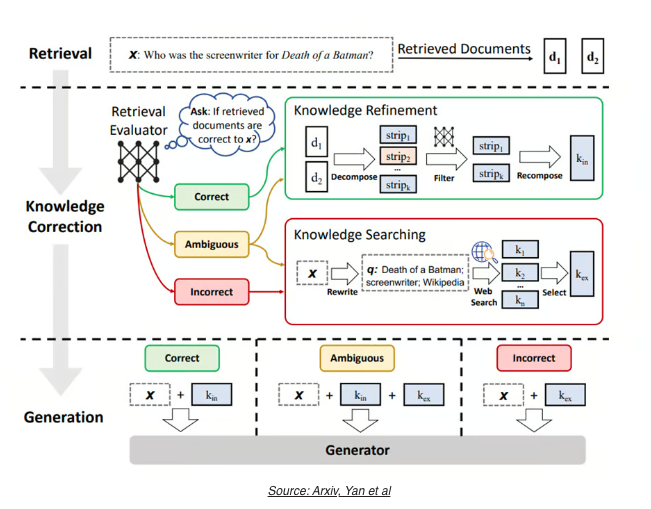
Refinement 1) CRAG (Corrective Retrieval Augmented Generation):
- 일반적인 RAG 기법에서 조회한 문서의 관련성을 평가할 수 있는 경량화 된 Evaluator 를 활용하는 기법임.
- RAG Evaluator 는 조회된 문서를 평가해서 Correct, Ambiguous, Incorrect 로 평가함. Correct 인 경우에는 해당 문서를 활용하고, Ambiguous 는 웹 검색을 추가로 활용해서 문서의 데이터를 보완하고, Incorrect 는 조회된 문서를 폐기하고 웹 검색 결과를 적극적으로 이용하는 기법임.
- 웬만한 RAG 보다는 성능이 좋다고 함.
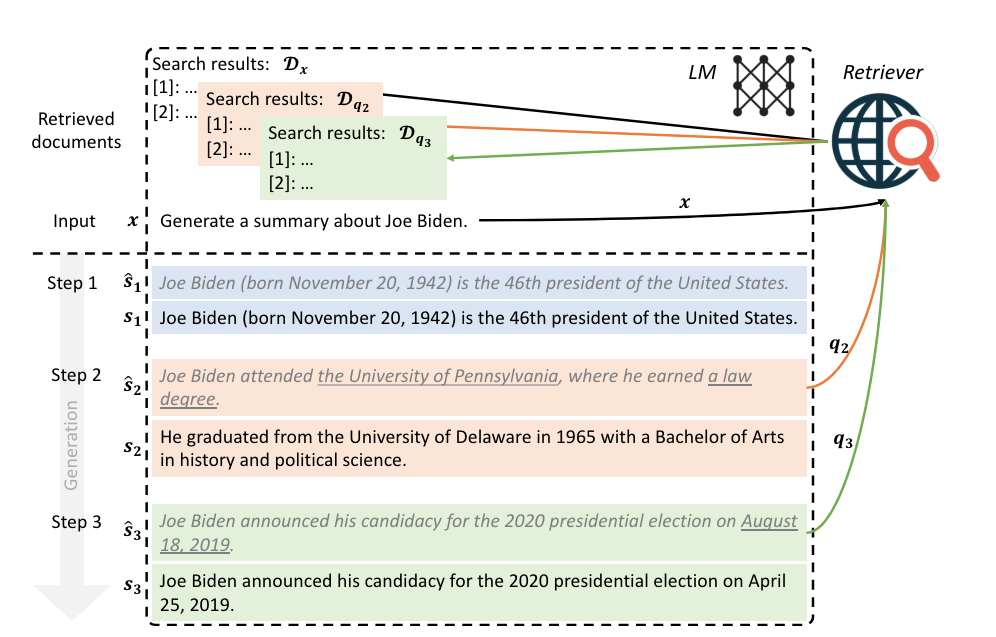
Refinement 2) FLARE (Forward Looking Active Retrieval):
- 이 기법은 긴 문장을 생성할 때 할루시네이션이 더 발생하도록 하는데 유용한 기법임.
- 작동 원리는 다음과 같다:
- 1) 사용자 질문에서 관련된 문서를 뽑아오고, 이를 바탕으로 임시 텍스트를 생성한다.
- 2) 생성한 임시 텍스트를 평가하고 low-probability tokens 를 포함하는지 평가한다. (low-probability tokens 는 문맥과 관련되지 않은 어색한 토큰을 말함)
- 3) 이 토큰이 발견된다면 관련된 문서를 더 검색한 후 다시 문장을 생성하도록 한다.
'Generative AI > RAG' 카테고리의 다른 글
| BM42: New Baseline for Hybrid Search (0) | 2024.07.06 |
|---|---|
| Advanced RAG Series: Generation and Evaluation (0) | 2024.06.19 |
| Advanced RAG Series: Routing and Query Construction (0) | 2024.06.14 |
| Advanced RAG Series: Query Translation (0) | 2024.06.12 |
| Advanced RAG series: Indexing (0) | 2024.06.05 |