
이 글은 Advanced RAG Series: Generation and Evaluation 를 보고 정리한 글입니다.
Generation 과정:
- Generation 은 RAG Pipeline 에서 가장 마지막 단계이다.
- LLM 이 Generation 을 잘 하기 이해서는 검색된 문서를 평가해서 올바른 데이터를 사용하는게 특히 중요하다고 함. 익걸 위해서 Cognitive architectures for Language Agents(CoALA) 프레임워크를 사용하는 것은 유용할 것이라고 함.
- https://arxiv.org/pdf/2309.02427
Cognitive architectures for Language Agents(CoALA):
- Agent 설계에 도움을 주는 개념적인 프레임워크임. 크게 3가지 요소로 나눠진다:
- Information Storage (working and long-term memories):
- Working Memory: 단기적으로 정보를 저장하고 즉시 사용할 수 있게 하는 메모리임. 현재 대화의 맥락이나 중요한 임시 데이터를 저장한다.
- Long-Term Memory: 오랜 기간 동안 정보를 저장하는 메모리. 언어 규칙, 상식, 과거 대화 기록 등이 포함된다.
- Action Space (internal and extenrnal actions):
- Internal Actions: 에이전트가 내부적으로 수행하는 작업이다. 정보를 분석하거나 결정을 내리는 과정이다.
- External Actions: 에이전트가 외부 환경과 상호작용하는 작업이다. 외부 시스템과 통신하는 등의 작업을 말한다.
- decision-making procedure (which is structured as an interactive loop with planning and execution)
- Planning: 에이전트가 주어진 작업을 해결하기 위해 목표를 설정하고 이를 달성하기 위한 계획을 세우는 단계를 말한다.
- Execution: 계획을 실행하여 실제 행동으로 옮기는 단계이다. 이 과정은 상호작용적인 루프로 구성되어 있어서 실행 결과를 바탕으로 다시 계획을 세우기도 한다.
- Information Storage (working and long-term memories):
- 크게 이렇게 기억과 할 수 있는 행동 그리고 의사 결정 프로세스를 통해서 Agent 를 체계적으로 표현할 수 있다고 한다.
- https://arxiv.org/pdf/2309.02427
Corrective RAG (CRAG):
- 이전에 Retrieval 시간에도 CRAG 에 대해서 살펴보았는데 여기서는 어떻게 동작하는지 좀 더 자세하게 살펴보자.
- CRAG 는 Retrieval 한 문서를 evaluator 에 의해서 3가지 등급으로 관련 문서를 평가된다. (Correct, Ambiguous, Incorrect)
- Correct 라고 판단된 경우에는 해당 문서에서 사용자의 질문과 관련된 부분만 추출해서 Context 로 사용하게 되고, Incorerect 라고 판단된 경우라면 해당 문서는 버리고 웹 검색에서 사용해서 맥락으로 쓴다. Ambiguous 로 판단된다면 이 두 방식을 섞는 방법임.
- CRAG 는 일반적인 RAG 기법에 비해서 성능이 잘나온다고 함. 그리고 이 방법은 Evaluator 의 성능에 의존적이기 떄문에 Fine-tuning 을 해야할 가능성이 높고 문서의 퀄리티를 위해서 guardrails 를 둬야할 수도 있다고 함.
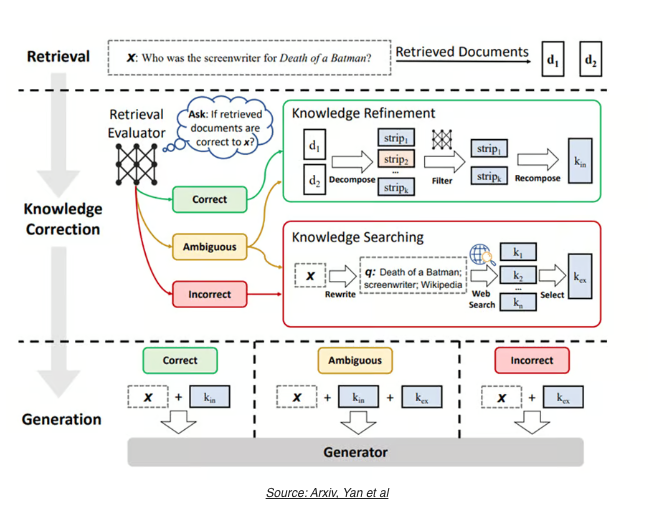

CRAG 를 LangGraph 로 구현한 코드는 다음과 같다:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# First we initialize our retriever (Functionality of the node “Retrieve”).
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=30
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
# Secondly we define the functionality for the “Grade” node. To get the grading result, we first define a Pydantic model Grader. It has one variable grade dedicated to indicating whether or not the retrieved document for the question is relevant. Using the model, we create the grading_chain that returns a Grader object.
from langchain.pydantic_v1 import BaseModel, Field
from typing import Literal
question = "What is agent memory?"
class Grader(BaseModel):
"""Returns a binary value 'yes' or 'no' based on the relevancy of the document to the question"""
grade: Literal["yes", "no"] = Field(..., description="The relevancy of the document to the question. 'yes' if relevant, 'no' if not relevant")
llm = ChatOpenAI(model='gpt-4', temperature=0)
grading_llm = llm.with_structured_output(Grader)
grading_prompt = ChatPromptTemplate.from_messages(
[
('system', """You are a grader assessing relevance of a retrieved document to a user question. \n
If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""),
('user', "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
docs = retriever.get_relevant_documents(question)
doc_txt = docs[1].page_content
grading_chain = grading_prompt | grading_llm
# Thirdly, we define the functionality of the “Generate” node.
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
prompt = hub.pull("rlm/rag-prompt")
generation_chain = prompt | llm | StrOutputParser()
# Fourthly, we define the functionality of the “Re-write query” as a chain.
system = """You a question re-writer that converts an input question to a better version that is optimized \n
for web search. Look at the input and try to reason about the underlying semantic intent / meaning."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)
re_write_chain = re_write_prompt | llm | StrOutputParser()
# Finally, we initialize the Tavily web search tool as the “Web search” node.
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)
# After defining the chains required for the functionalities of each node, we then define the GraphState to be used by LangGraph. In LangGraph, a graph is parameterized by a state object that it passes around to each node. Remember that each node then returns operations to update that state. These operations can either SET specific attributes on the state (e.g. overwrite the existing values) or ADD to the existing attribute. Whether to set or add is denoted by annotating the state object you construct the graph with. The default operation is SET, which overrides the existing values of the state.
# Here our state is a TypedDict with 4 keys indicating the question, documents retrieved for the question, whether of not search the web, and the final LLM generation.
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
search_web: whether to search the web
documents: list of documents
"""
question: str
documents: list[str]
search_web: str
generation: str
# Through each node, we update the state accordingly. We represent “nodes” in the graph as methods, that we create below. For instance, the “Retrieve” node is represented as the retrieve method, that retrieves the documents according to the graph state’s question field and updates the documents field of the state. Similarly we create a method for each node that use the defined chains to perform a specific task, update the state, and return it.
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents related to the question
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print('> 📃 Retrieving documents...')
question = state['question']
docs = retriever.get_relevant_documents(question)
state['documents'] = [doc.page_content for doc in docs]
return state
def grade(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
question = state['question']
documents = state['documents']
search_web = "yes"
print('> 🔍 Grading documents...')
filtered_docs = []
for i,doc in enumerate(documents):
grade = grading_chain.invoke({'document': doc, 'question': question})
if grade.grade == 'yes':
print(f'> 📝 \033[92mDocument {i} is relevant\033[0m')
filtered_docs.append(doc)
search_web = 'no'
else:
print(f'> 📝 \033[91mDocument {i} is irrelevant\033[0m')
state['documents'] = filtered_docs
state['search_web'] = search_web
return state
def rewrite_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print('> ✍🏻 Rewriting the question...')
question = state['question']
new_question = re_write_chain.invoke({'question': question})
state['question'] = new_question
return state
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print('> 🌎 Web searching...')
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
documents.append(web_results)
state["documents"] = documents
return state
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("> 🤖 Generating the answer...")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = generation_chain.invoke({"context": documents, "question": question})
state["generation"] = generation
return state
# We will also need to define some edges. Some of these edges may be conditional. The reason they are conditional is that the destination depends on the contents of the graph’s state. For instance, after grading the retrieved documents, our RAG pipeline should decide whether to use the retrieved documents to generate the answer or to re-write the query for a web search. It depends on the search_web property of the graph’s state which is updated within the grade node. Therefore, we define our one and only conditional edge decide_to_generate which outputs name of the next node to go based on the grading decision.
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns: Method name to execute next
"""
print("> ❓ Deciding to generate...")
search_web = state["search_web"]
if search_web == "yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print("> 💡 Decision: \033[91mAll the retrieved documents are irrelevant\033[0m")
return "rewrite_query"
else:
# We have relevant documents, so generate answer
print("> 💡 Decision: \033[92mRelevant documents found\033[0m")
return "generate"
# After defining all the nodes and edges, we finally define our graph workflow that passes the GraphState node to node via edges. We start by adding each node to the graph. Then we define the entry_point (i.e., the root node) that has only one outward edge. From the entry point we connect each node using add_edge with the source node name and target node name. In conditional edges, we use add_conditional_edges to specify the source node, the decision method, and what node to point based on the output of the decision method as a dictionary. In our case, if the decide_to_generate outputs rewrite_query, an edge will connect the grade and rewrite_query nodes. On the other hand, if the decide_to_generate outputs generate, an edge will connect the grade and generate nodes. We complete defining our graph with the generate node which does not have any outward nodes. So the last edge’s target node is a special node named, END.
# After creating the graph we compile it using the compile() method. Compiled graph will take the input and go through all the required nodes in order to reach the END. We stream the graph’s output using the stream() method so that we can print to see what is happening under the hood.
from langgraph.graph import END, StateGraph
# Provide the state graph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade", grade) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("rewrite_query", rewrite_query) # rewrite_query
workflow.add_node("web_search", web_search) # web search
# Build graph
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade")
workflow.add_conditional_edges(
"grade",
decide_to_generate,
{
"rewrite_query": "rewrite_query",
"generate": "generate",
},
)
workflow.add_edge("rewrite_query", "web_search")
workflow.add_edge("web_search", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()
def run_pipeline(question):
inputs = {"question": question}
for output in app.stream(inputs):
for key, value in output.items():
if key == 'generate':
print()
print(f'Question: {inputs["question"]}')
print(f"Answer: {value['generation']}")
run_pipeline("What is agent memory?")
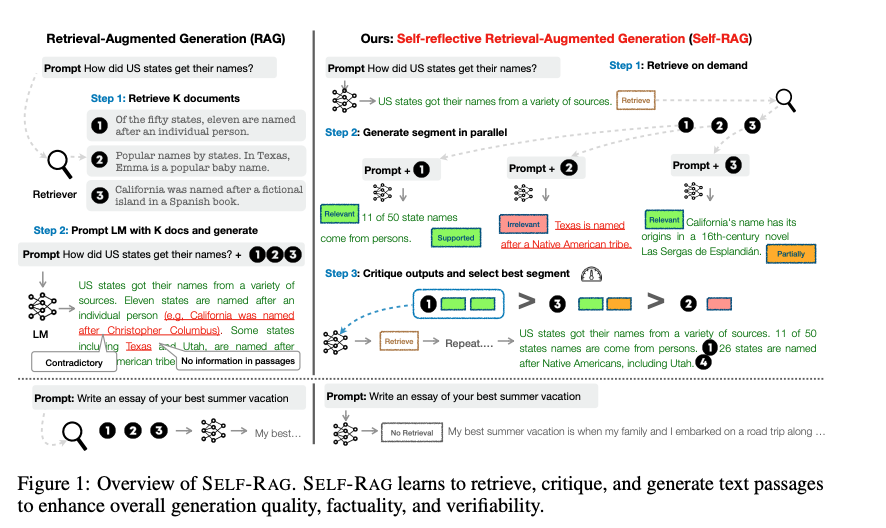
Self RAG:
- 항상 고정된 수의 문서를 검색하는 대신에 LLM 이 필요에 따라 검색하고, 스스로 성찰하는 과정을 통해 유용한 출력을 생성하는 프레임워크다.
- on-demand retrieval 와 self-reflection 이 핵심 매커니즘임.
- 항상 고정된 수의 관련 문서를 검색해서 대답하는건 그렇게 유용하지 않다고 판단함.
- Self RAG 의 동작 과정은 다음과 같다:
- 1) 검색 필요성 평가 및 검색:
- 검색 토큰 생성: 입력 프롬프트와 이전 생성 결과를 바탕으로, Self-RAG는 추가 정보가 필요할 때 검색 토큰을 생성한다.
- 검색 모델 호출: 검색 토큰이 출력되면 검색 모델을 호출하여 관련 패시지를 검색한다.
- 2) 검색된 문서 처리 및 출력 생성:
- 동시 처리: 검색된 여러 문서를 병렬로 처리하여 다양한 출력을 생성한다.
- 출력 평가: Critique Token을 사용하여 각 출력의 관련성과 사실성을 평가한다.
- 3) 최적의 출력 선택:
- 사실성과 품질: 각 출력의 사실성과 전반적인 품질을 평가하여 최적의 출력을 선택한다.
- 최종 결과 생성: 선택된 최적의 출력이 최종 결과로 사용자에게 제공된다.
- Self RAG 는 CRAG 기법과 같이 적용되었을 때 성능이 더 뛰어남.
- 1) 검색 필요성 평가 및 검색:
- https://arxiv.org/pdf/2310.11511
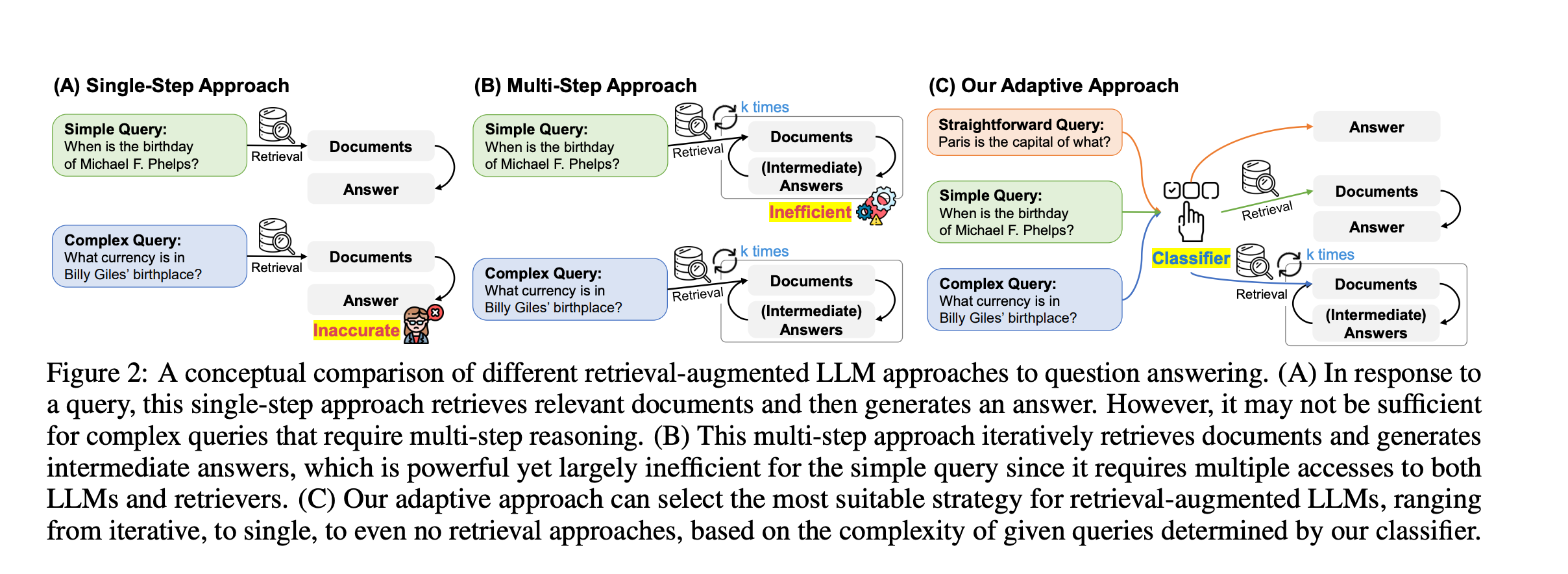
Adaptive RAG:
- 주어진 Query 를 분석해서, 간단한 쿼리라면 단일 RAG Step 을 기반으로 답변을 내리도록 하고, 복잡한 쿼리라면 여러번의 Multi Step 을 거쳐서 답변을 내리도록 하고, 쿼리가 RAG 기법이 필요 없다라고 판단하면 그 즉시 LLM 이 답변을 내리도록 하는 것.
- 질문에 따라서 효율적으로 처리하도록 하는 기법이다.
- https://arxiv.org/pdf/2403.14403
다음은 기존 CRAG 방식에다가 Self RAG + Adaptive RAG 를 합쳐서 개선한 예시임:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# We start by creating our retriever to retrieve documents (documents about agents, prompt engineering, and adverserial attacks on llms) from the vectorstore.
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=30
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
# Then we create the chain that decides whether to redirect the user question to the vectorstore, or to do a web search or to fallback when the user asks a generic question.
from langchain.pydantic_v1 import BaseModel, Field
from typing import Literal
class QueryRouter(BaseModel):
"""Routes the user query to appropriate datasources. If the query can be answered using documents about either LLM agents, prompt engineering, or adverserial attacks on LLMs, returns 'vectorstore'. Otherwise returns 'web_serach'. If the query can be answered using LLM's internal knowledge, return 'fallback'"""
datasource: Literal["vectorstore", "web_search", "fallback"] = Field(...,
description="The datasource to use for answering the query. 'vectorstore' if the query is either related to LLM agents, prompt engineering, or adverserial attacks on LLMs \
'web_search' if the query is not related to the above topics and requires web search. 'fallback' if the query can be answered using LLM's internal knowledge")
llm = ChatOpenAI(model='gpt-4', temperature=0)
query_llm = llm.with_structured_output(QueryRouter)
query_router_prompt = ChatPromptTemplate.from_template(
"""You are an expert at routing a user question to a vectorstore or web search. The vectorstore contains documents related to agents, prompt engineering, and adversarial attacks.
Use the vectorstore for questions on these topics. Otherwise, use web_search. If the question can be answered using LLM's internal knowledge, use fallback.\n\n
Question: {question}"""
)
query_routing_chain = (query_router_prompt | query_llm)
# Thirdly, we create our DocumentGrader that decides whether or not the retrieved documents are relevant to answer the question.
class DocumentGrader(BaseModel):
"""Binary score for relevance check on retrieved documents."""
grade: str = Field(...,
description="Documents are relevant to the question, 'yes' or 'no'"
)
grader_llm = llm.with_structured_output(DocumentGrader)
grading_prompt = ChatPromptTemplate.from_template(
"""
You are a grader assessing relevance of a retrieved document to a user question. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.\n\n
Retrieved document: {document}\n\nQuestion: {question}
"""
)
grading_chain = (grading_prompt | grader_llm)
# Create the chain that would answer the user question based on the provided context.
qa_prmpt = hub.pull('rlm/rag-prompt')
qa_chain = qa_prmpt | llm | StrOutputParser()
# Create the fallback chain that answers the user query using the LLM’s internal knowledge without any aditional context.
fallback_prompt = ChatPromptTemplate.from_template(
"""
You are an assistant for question-answering tasks. Answer the question based upon your knowledge. Use three sentences maximum and keep the answer concise.\n\n
Question: {question}
"""
)
fallback_chain = fallback_prompt | llm | StrOutputParser()
# Initialize the chain the detects whether or not the answer is supported by the retrieved context (i.e., no hallucinations). The HallucinationEvaluator returns ‘yes’ if there are no hallucinations, and ‘no’ otherwise.
class HallucinationEvaluator(BaseModel):
"""Binary score for hallucination present in generation answer."""
grade: str = Field(...,
description="Answer is grounded in the facts, 'yes' or 'no'"
)
hallucination_llm = llm.with_structured_output(HallucinationEvaluator)
hallucination_prompt = ChatPromptTemplate.from_template(
"""
You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts.\n\n
Set of facts: {documents} \n\n LLM generation: {generation}
"""
)
hallucination_chain = hallucination_prompt | hallucination_llm
# Define the chain that assess whether or not the answer, correctly answers the question.
class AnswerGrader(BaseModel):
"""Binary score to assess answer addresses question."""
grade: str = Field(...,
description="Answer addresses the question, 'yes' or 'no'"
)
answer_grader_llm = llm.with_structured_output(AnswerGrader)
answer_grader_prompt = ChatPromptTemplate.from_template(
"""
You are a grader assessing whether an answer addresses / resolves a question. \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question.\n\n
Question: {question} \n\n Answer: {answer}
"""
)
answer_grader_chain = answer_grader_prompt | answer_grader_llm
# Define the web search tool for sercing web.
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)
# Define the graph state that would be changed while traversing the graph.
from typing_extensions import TypedDict
from typing import List
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]
# Creating the methods for each node of the graph.
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("> 📃 Retrieving documents...")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
state["documents"] = documents
return state
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("> 🌎 Web searching...")
question = state["question"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
state["documents"] = web_results
return state
def fallback(state):
"""
Generate answer using the LLM w/o vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("> 👈 Initiating fallback...")
question = state["question"]
generation = fallback_chain.invoke({"question": question})
state["generation"] = generation
return state
def generate(state):
"""
Generate answer using the LLM w/ vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("> 🤖 Generating answer...")
question = state["question"]
documents = state["documents"]
generation = qa_chain.invoke({"question": question, "context": documents})
state["generation"] = generation
return state
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("> 🔍 Grading documents...")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for i,doc in enumerate(documents):
grade = grading_chain.invoke({'document': doc, 'question': question})
if grade.grade == 'yes':
print(f'> 📝 \033[92mDocument {i} is relevant\033[0m')
filtered_docs.append(doc)
else:
print(f'> 📝 \033[91mDocument {i} is irrelevant\033[0m')
state["documents"] = filtered_docs
return state
Creating the methods for conditional edges.
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
question = state["question"]
route = query_routing_chain.invoke({"question": question})
if route.datasource == "vectorstore":
print("> 📚 Routing to the vectorstore...")
return "retrieve"
elif route.datasource == "web_search":
print("> 🌎 Routing to web search...")
return "web_search"
else:
print("> 👈 Routing to fallback...")
return "fallback"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("> 🤔 Deciding to generate...")
filtered_documents = state["documents"]
if not filtered_documents:
print("> 💡 Decision: \033[91mAll the retrieved documents are irrelevant\033[0m")
return "web_search"
else:
# We have relevant documents, so generate answer
print("> 💡 Decision: \033[92mRelevant documents found\033[0m")
return "generate"
def evaluate_response(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
question = state["question"]
documents = state["documents"]
generation = state["generation"]
print("> 🧠 Evaluating the response for hallucinations...")
hallucination_grade = hallucination_chain.invoke({"documents": documents, "generation": generation})
if hallucination_grade.grade == "yes":
print("> ✅ \033[92mGeneration is grounded in the documents\033[0m")
print("> 🧠 Evaluating the response for answer...")
answer_grade = answer_grader_chain.invoke({"question": question, "answer": generation})
if answer_grade.grade == "yes":
print("> ✅ \033[92mAnswer addresses the question\033[0m")
return "useful"
else:
print("> ❌ \033[91mAnswer does not address the question\033[0m")
return "notuseful"
else:
print("> ❌ \033[91mGeneration is not grounded in the documents\033[0m")
return "not supported"
# Build the tree and compile it.
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
workflow.add_node("retrieve", retrieve)
workflow.add_node("web_search", web_search)
workflow.add_node("fallback", fallback)
workflow.add_node("generate", generate)
workflow.add_node("grade_documents", grade_documents)
workflow.set_conditional_entry_point(
route_question,
{
'retrieve': 'retrieve',
'web_search': 'web_search',
'fallback': 'fallback'
}
)
workflow.add_edge("retrieve", "grade_documents")
workflow.add_edge("web_search", "generate")
workflow.add_conditional_edges(
'grade_documents',
decide_to_generate,
{
'web_search': 'web_search',
'generate': 'generate'
}
)
workflow.add_conditional_edges(
'generate',
evaluate_response,
{
'useful': END,
'notuseful': 'web_search',
'not supported': 'generate'
}
)
workflow.add_edge("fallback", END)
app = workflow.compile()
def run_pipeline(question):
inputs = {"question": question}
for output in app.stream(inputs):
for key, value in output.items():
if key == 'generate' or key == 'fallback':
print()
print(f'Question: {inputs["question"]}')
print(f"Answer: {value['generation']}")
# Execute the tree.
run_pipeline("What are the types of agent memory?")
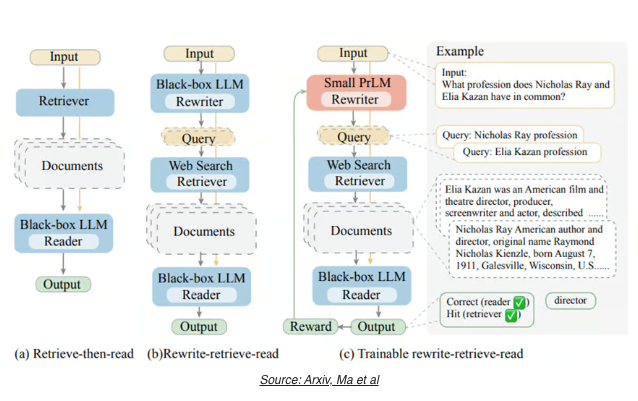
RRR (Rewrite-Retrieve-Read)
- 기존 RAG 방식은 Retrieve 한 후 문서를 Read 하는 방식이라면, RRR 은 검색 쿼리 자체를 머저 재작성(rewrite) 한 후 검색(retrieve) 하고, 읽기(read) 하는 과정임.
- 쿼리 재작성을 통해서 입력 텍스트와 필요한 지식 사이의 간격을 좁히는 것.
- https://arxiv.org/pdf/2305.14283
Evaluation:
- RAG(Retrieval-Augmented Generation) 파이프라인의 중요한 단계는 평가(Evaluation) 일 것.
- 일반적인 접근 방법은 Q&A 쌍을 테스트 데이터로 준비해두고, 모델의 출력과 실제 정답과 비교하는 것일 것. 모델의 정확성을 직접적으로 측정할 수 있긴 하나, 데이터 셋 수집에 어려움이 있고, 엣지 케이스에 대비하기는 어렵고, 특정 케이스에 최적화될 수 있을거임. 그래서 다양한 메트릭을 사용해서 평가하는게 중요하다.
RAGAs (Retrieval-Augmented Generation Assessment):
- RAG 파이프라인을 평가하기 위한 오픈 소스 프레임워크임. 이 프레임워크는 다양한 평가 지표를 제공하여 RAG 시스템의 성능을 전반적으로 평가할 수 있다.
- 평가 방법으로는 "ground truth”를 기반으로 테스트 데이터를 생성하는 방법을 제공해주고, 여러가지 메트릭을 가지고 평가를 하면 된다:
- 평가 지표(메트릭):
- Faithfulness (사실적 일관성): 생성된 응답이 사실적으로 일관되는지 평가하는 지표
- Answer Relevance (응답의 관련성): 응답이 프롬프트와 얼마나 관련 있는지 평가하는 지표
- Context Precision (문맥 정밀도): 관련 있는 정보 조각들이 높은 순위로 랭크되는지 확인하는 지표
- Aspect Critique (측면 평가): 무해성(harmlessness)과 정확성(correctness) 등의 사전 정의된 측면에 따라 평가하는 지표
- Context Recall (문맥 재현율): 실제 정답과 문맥을 비교하여 모든 관련 정보가 검색되었는지 확인하는 지표
- Context Entities Recall (문맥 엔티티 재현율): 검색된 문맥에 있는 엔티티 수를 실제 정답과 비교하여 평가하는 지표
- Context Relevancy (문맥 관련성): 검색된 문맥이 프롬프트와 얼마나 관련 있는지 평가하는 지표
- Answer Semantic Similarity (응답의 의미적 유사성): 생성된 응답이 실제 정답과 의미적으로 얼마나 유사한지 평가하는 지표
- Answer Correctness (응답의 정확성): 생성된 응답의 정확성과 실제 정답과의 일치를 평가하는 지표
LangSmith:
- LangSmith는 다양한 평가 지표를 사용하여 RAG 파이프라인의 각 단계를 분석할 수 있음.
- faithfulness(사실적 일관성), answer relevancy(응답의 관련성), context relevancy(문맥 관련성), context recall(문맥 재현율) 등 메트릭을 제공해준다.
- LangSmith는 RAGAS(다른 오픈 소스 평가 프레임워크)와의 통합할 수도 있음.
- 결과를 시각적으로 실시간으로 볼 수도 있다.
'Generative AI > RAG' 카테고리의 다른 글
| Advanced RAG series: Query Decomposition (0) | 2024.07.09 |
|---|---|
| BM42: New Baseline for Hybrid Search (0) | 2024.07.06 |
| Advanced RAG Series: Retrieval (0) | 2024.06.18 |
| Advanced RAG Series: Routing and Query Construction (0) | 2024.06.14 |
| Advanced RAG Series: Query Translation (0) | 2024.06.12 |