
이 글은 Building Agentic RAG with Llamaindex 코스를 보고 정리한 글입니다.
Outline:
- 여기서는 Agentic RAG 시스템을 만들어볼거임. RAG Pipieline 의 동작을 Agent 가 하는 것을 말한다. (Routing tool use -> Retrieving -> synthesis -> Generating)
- 일반적인 RAG pipeline 위에서 Agent 를 이용하는 시스템을 말함.
- 그리고 Agent 는 작업을 단계적으로 처리해나갈텐데, 중간 단계에서 Agent 에게 Guidance 를 주는 방법에 대해서도 배워볼거임. 주니억 개발자가 올바른 행동을 하도록 만드는 것처럼.
1. Router Query Engine
QueryEngine 에 대한 정의:
- 사용자가 쿼리를 했을 때 그것과 관련된 답변을 내주도록 하는게 QueryEngine 임.
- 내부적으로 VectorStore 와 LLM 등이 합쳐져있고, RAG pipeline 의 Retrieval -> Synthesis -> Generating 과정까지 수행해주는 역할을 함.
Documents, Nodes 에 대한 정의:
- Document 는 데이터들이 있는 Container 와 같은 존재라고 알면됨. pdf 파일 같은 것.
- Nodes 는 Document 에서 쪼개진 chunk 데이터들임.
Index 에 대한 정의:
- 사용자의 쿼리와 관련해서 관련 데이터를 검색할 수 있는 자료구조임.
RouterQueryEngine 은 LLM 이 주어진 쿼리를 보고 어떤 QueryEngine 을 이용할 지 결정해주는 역할을 함.
여기서는 요약 작업에 대한 쿼리 엔진과 Q&A 작업에 대한 쿼리 엔진을 만드는데 사용자의 질문을 보고 어떤 쿼리 엔진을 사용할 지 선택해주는 역할을 한다.
실습 코드를 보자.
먼저 설정을 하는 코드임.
- nest_asyncio 는 파이썬에서 비동기 함수를 허용할 수 있도록 이벤트 루프를 사용할 수 있게 해주는거임.
- nest_asyncio.apply() 연산을 통해서 여러개의 이벤트 루프를 실행할 수 있도록 해줌. 원래 하나의 이벤트 루프만 실행이 가능하다. 이벤트 루프 하나가 여러개의 비동기 작업을 관리하는 구조임.
from helper import get_openai_api_key
OPENAI_API_KEY = get_openai_api_key()
import nest_asyncio
nest_asyncio.apply()
다음은 Document 를 Load 하는 코드를 보자.
from llama_index.core import SimpleDirectoryReader
# load documents
documents = SimpleDirectoryReader(input_files=["metagpt.pdf"]).load_data()
다음은 Document 를 Chunking 하는 코드를 보고, 임베딩 모델도 만들어보자.
from llama_index.core.node_parser import SentenceSplitter
splitter = SentenceSplitter(chunk_size=1024)
nodes = splitter.get_nodes_from_documents(documents)
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
Settings.llm = OpenAI(model="gpt-3.5-turbo")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
이제 각 작업마다 Llamaindex 에서 index 를 만들자.
from llama_index.core import SummaryIndex, VectorStoreIndex
summary_index = SummaryIndex(nodes)
vector_index = VectorStoreIndex(nodes)
index 를 이용해서 쿼리 엔진도 만들자.
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
vector_query_engine = vector_index.as_query_engine()
QueryEngine 을 이용해서 RouterQueryEngine 에서 사용할 수 있도록 tool 로 만들자.
from llama_index.core.tools import QueryEngineTool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to MetaGPT"
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from the MetaGPT paper."
),
)
Tool 로 만든 이후 RouterQueryEngine 을 만들고 사용해보자.
- selector 로 LLMSingleSelector 를 사용했는데 이건 LLM 출력을 JSON 으로 만들도록 해주는거임.
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=True
)
response = query_engine.query("What is the summary of the document?")
print(str(response))
출력 결과로는 요약 정보와 어떤 QueryEngine 이 사용했는지 볼 수 있음.
Selecting query engine 0: This choice indicates that the document is useful for summarization questions related to MetaGPT..
The document introduces MetaGPT, a meta-programming framework that enhances multi-agent collaboration based on Large Language Models (LLMs) by incorporating human-like Standardized Operating Procedures (SOPs). MetaGPT assigns specific roles to agents, streamlining workflows and improving task decomposition. By utilizing structured outputs and a communication protocol, MetaGPT ensures efficient collaboration among agents with diverse expertise. The framework also introduces an executable feedback mechanism to enhance code generation quality. Through evaluations on HumanEval and MBPP benchmarks, MetaGPT demonstrates state-of-the-art performance in code generation tasks, showcasing its robustness and efficiency in developing LLM-based multi-agent systems. Additionally, the document discusses the structured software development process in MetaGPT, emphasizing the importance of SOPs in workflow management, communication protocols, and iterative programming with executable feedback to improve code quality. Experimental results show MetaGPT outperforming previous approaches in code generation tasks, with an ablation study highlighting the effectiveness of different roles and the executable feedback mechanism. The document also outlines the development process using MetaGPT for software development, involving collaboration with a professional development team, generating a Product Requirement Document (PRD), system design, and user-friendly GUI color meter creation. Furthermore, it discusses the roles of different agents in generating requirements, designing the system, developing code, and testing the application for a "Drawing App." The document also touches on the performance evaluation of GPT models in the HumanEval benchmark, comparing GPT-4 and GPT-3.5-Turbo under different conditions, addressing limitations, ethical concerns, benefits, challenges, and how MetaGPT manages information overload.
SummaryQueryEngine 은 관련 nodes (= chunk) 를 모두 이용하는 구조라서 사용된 Nodes 수를 보면 다음과 같음.
# 34가 출력됨
print(len(response.source_nodes))
Q&A Query Engine 이 사용되는 것도 예시를 보자
response = query_engine.query(
"How do agents share information with other agents?"
)
print(str(response))
출력 결과는 다음과 같음:
Selecting query engine 1: This choice is more relevant as it focuses on retrieving specific context from the MetaGPT paper, which may provide insights on how agents share information with other agents..
Agents share information with other agents by utilizing a shared message pool where they can publish structured messages. This shared message pool allows all agents to exchange messages directly, enabling them to both publish their own messages and access messages from other agents transparently. Additionally, agents can subscribe to relevant messages based on their role profiles, allowing them to extract the information they need for their specific tasks and responsibilities.
2. Tool Caling
LLM 을 이용해서 Tool Caling 을 해볼거임. Tool caling 은 LLM 이 어떠한 도구를 선택할건지, 그리고 도구를 위해서 매개변수를 결정해주기도 할거임.
그리고 여기에다가 이전에 배운 RouterQueryEngine 개념까지 더해볼거다.
그러니까 주어진 쿼리를 보고 RouterQueryEngine 은 어떤 QueryEngine Tool 을 사용할 지 결정하고, 이 툴에 대한 매개변수까지 선택해서 결과를 가져올거임.
툴의 매개변수는 Retrieve 할 문서를 필터링 하는 조건으로 설정해볼거다.
기존 Standard RAG 는 LLM 이 VectorStore 에서 검색한 내용을 가지고 Synthesis 해서 Output 을 Generation 하는 과정만 이용했다면, Agent 시스템에서는 QueryEngine Tool 을 선택하는 것 까지 해준다.
- 주어진 질문에 대답하기 위해서는 Vector Store 선택부터, 어떻게 Chunking 되어 있는지 부터, 어떤 프롬포트를 사용할건지 등 내부적으로 다양한 요소가 있다. 이런 다양한 요소가 합쳐져서 QueryEngine 이 되는건데 이것의 결정을 LLM 이 할 수 있게됨.
LLM 의 Tool caling 을 사용하는 예시부터 보자
from helper import get_openai_api_key
OPENAI_API_KEY = get_openai_api_key()
import nest_asyncio
nest_asyncio.apply()
from llama_index.core.tools import FunctionTool
def add(x: int, y: int) -> int:
"""Adds two integers together."""
return x + y
def mystery(x: int, y: int) -> int:
"""Mystery function that operates on top of two numbers."""
return (x + y) * (x + y)
add_tool = FunctionTool.from_defaults(fn=add)
mystery_tool = FunctionTool.from_defaults(fn=mystery)
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
response = llm.predict_and_call(
[add_tool, mystery_tool],
"Tell me the output of the mystery function on 2 and 9",
verbose=True
)
print(str(response))
Tool Caling 의 출력 결과는 다음과 같다:
=== Calling Function ===
Calling function: mystery with args: {"x": 2, "y": 9}
=== Function Output ===
121
121
다음은 Document 의 메타 데이터를 보고, 이것을 통해서 필터링 검색을 수행하는 예시도 보자
from llama_index.core import SimpleDirectoryReader
# load documents
documents = SimpleDirectoryReader(input_files=["metagpt.pdf"]).load_data()
from llama_index.core.node_parser import SentenceSplitter
splitter = SentenceSplitter(chunk_size=1024)
nodes = splitter.get_nodes_from_documents(documents)
print(nodes[0].get_content(metadata_mode="all"))
메타데이터와 본문은 다음과 같다:
page_label: 1
file_name: metagpt.pdf
file_path: metagpt.pdf
file_type: application/pdf
file_size: 16911937
creation_date: 2024-06-20
last_modified_date: 2024-04-23
Preprint
METAGPT: M ETA PROGRAMMING FOR A
MULTI -AGENT COLLABORATIVE FRAMEWORK
Sirui Hong1∗, Mingchen Zhuge2∗, Jonathan Chen1, Xiawu Zheng3, Yuheng Cheng4,
Ceyao Zhang4,Jinlin Wang1,Zili Wang ,Steven Ka Shing Yau5,Zijuan Lin4,
Liyang Zhou6,Chenyu Ran1,Lingfeng Xiao1,7,Chenglin Wu1†,J¨urgen Schmidhuber2,8
1DeepWisdom,2AI Initiative, King Abdullah University of Science and Technology,
3Xiamen University,4The Chinese University of Hong Kong, Shenzhen,
5Nanjing University,6University of Pennsylvania,
7University of California, Berkeley,8The Swiss AI Lab IDSIA/USI/SUPSI
ABSTRACT
Remarkable progress has been made on automated problem solving through so-
cieties of agents based on large language models (LLMs). Existing LLM-based
multi-agent systems can already solve simple dialogue tasks. Solutions to more
complex tasks, however, are complicated through logic inconsistencies due to
cascading hallucinations caused by naively chaining LLMs. Here we introduce
MetaGPT, an innovative meta-programming framework incorporating efficient
human workflows into LLM-based multi-agent collaborations. MetaGPT en-
codes Standardized Operating Procedures (SOPs) into prompt sequences for more
streamlined workflows, thus allowing agents with human-like domain expertise
to verify intermediate results and reduce errors. MetaGPT utilizes an assembly
line paradigm to assign diverse roles to various agents, efficiently breaking down
complex tasks into subtasks involving many agents working together. On col-
laborative software engineering benchmarks, MetaGPT generates more coherent
solutions than previous chat-based multi-agent systems. Our project can be found
at https://github.com/geekan/MetaGPT.
1 I NTRODUCTION
Autonomous agents utilizing Large Language Models (LLMs) offer promising opportunities to en-
hance and replicate human workflows. In real-world applications, however, existing systems (Park
et al., 2023; Zhuge et al., 2023; Cai et al., 2023; Wang et al., 2023c; Li et al., 2023; Du et al., 2023;
Liang et al., 2023; Hao et al., 2023) tend to oversimplify the complexities. They struggle to achieve
effective, coherent, and accurate problem-solving processes, particularly when there is a need for
meaningful collaborative interaction (Chen et al., 2024; Zhang et al., 2023; Dong et al., 2023; Zhou
et al., 2023; Qian et al., 2023).
Through extensive collaborative practice, humans have developed widely accepted Standardized
Operating Procedures (SOPs) across various domains (Belbin, 2012; Manifesto, 2001; DeMarco &
Lister, 2013). These SOPs play a critical role in supporting task decomposition and effective coor-
dination. Furthermore, SOPs outline the responsibilities of each team member, while establishing
standards for intermediate outputs. Well-defined SOPs improve the consistent and accurate exe-
cution of tasks that align with defined roles and quality standards (Belbin, 2012; Manifesto, 2001;
DeMarco & Lister, 2013; Wooldridge & Jennings, 1998). For instance, in a software company,
Product Managers analyze competition and user needs to create Product Requirements Documents
(PRDs) using a standardized structure, to guide the developmental process.
Inspired by such ideas, we design a promising GPT -based Meta -Programming framework called
MetaGPT that significantly benefits from SOPs. Unlike other works (Li et al., 2023; Qian et al.,
2023), MetaGPT requires agents to generate structured outputs, such as high-quality requirements
∗These authors contributed equally to this work.
†Chenglin Wu (alexanderwu@fuzhi.ai) is the corresponding author, affiliated with DeepWisdom.
이것을 통해서 필터링 검색을 하는 방법은 다음과 같다:
from llama_index.core.vector_stores import MetadataFilters
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
[
{"key": "page_label", "value": "2"}
]
)
)
response = query_engine.query(
"What are some high-level results of MetaGPT?",
)
print(str(response))
출력 결과는 다음과 같음:
Some high-level results of MetaGPT include achieving a new state-of-the-art in code generation benchmarks with high Pass@1 scores, outperforming other popular frameworks in creating complex software projects, handling higher levels of software complexity effectively, offering extensive functionality, and demonstrating robustness and efficiency in task completion rates.
메타 데이터를 보면 다음과 같다:
for n in response.source_nodes:
print(n.metadata)
출력 결과:
{'page_label': '2', 'file_name': 'metagpt.pdf', 'file_path': 'metagpt.pdf', 'file_type': 'application/pdf', 'file_size': 16911937, 'creation_date': '2024-06-20', 'last_modified_date': '2024-04-23'}
다음은 메타 데이터를 이용한 필터링 검색을 이용해서 답변을 작성하는 걸 Tool 로 만들어서 검색하는 예시도 보자
from typing import List
from llama_index.core.vector_stores import FilterCondition
def vector_query(
query: str,
page_numbers: List[str]
) -> str:
"""Perform a vector search over an index.
query (str): the string query to be embedded.
page_numbers (List[str]): Filter by set of pages. Leave BLANK if we want to perform a vector search
over all pages. Otherwise, filter by the set of specified pages.
"""
metadata_dicts = [
{"key": "page_label", "value": p} for p in page_numbers
]
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
metadata_dicts,
condition=FilterCondition.OR
)
)
response = query_engine.query(query)
return response
vector_query_tool = FunctionTool.from_defaults(
name="vector_tool",
fn=vector_query
)
llm = OpenAI(model="gpt-3.5-turbo", temperature=0)
response = llm.predict_and_call(
[vector_query_tool],
"What are the high-level results of MetaGPT as described on page 2?",
verbose=True
)
출력 결과는 다음과 같음:
=== Calling Function ===
Calling function: vector_tool with args: {"query": "high-level results of MetaGPT", "page_numbers": ["2"]}
=== Function Output ===
MetaGPT achieves a new state-of-the-art (SoTA) in code generation benchmarks with 85.9% and 87.7% in Pass@1. It stands out in handling higher levels of software complexity and offering extensive functionality, demonstrating a 100% task completion rate in experimental evaluations.
최종적으로는 llm 에게 이런 QueryEngineTool 을 줘서 결과를 내도록 할 수 있음
from llama_index.core import SummaryIndex
from llama_index.core.tools import QueryEngineTool
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
summary_tool = QueryEngineTool.from_defaults(
name="summary_tool",
query_engine=summary_query_engine,
description=(
"Useful if you want to get a summary of MetaGPT"
),
)
response = llm.predict_and_call(
[vector_query_tool, summary_tool],
"What are the MetaGPT comparisons with ChatDev described on page 8?",
verbose=True
)
출력 결과는 다음과 같다:
=== Calling Function ===
Calling function: vector_tool with args: {"query": "MetaGPT comparisons with ChatDev", "page_numbers": ["8"]}
=== Function Output ===
MetaGPT outperforms ChatDev in various aspects such as executability, running times, token usage, code statistic, productivity, and human revision cost. It demonstrates superior performance in the SoftwareDev dataset compared to ChatDev, showcasing benefits like generating code with fewer tokens and requiring less time for execution.
3. Building an Agent Reasoning Loop
이전까지의 실습에서는 본 내용은 사용자의 질문에 적절한 도구를 LLM 이 선택하고, LLM 이 파라미터를 뽑아서 관련 문서를 검색한 후 응답을 만들어 내는 직선적으로 간단하게 처리하는 방식이었음.
Agent Reasoning Loop 를 통해서 복잡한 스텝이 필요한 질문이거나, 다소 모호한 질문에 대해서 명료화 한 후 처리하도록 만들 수 있는데 이것에 대해서 배워볼거임.
Llama Index 에서 사용할 Agent 내부 요소인 AgentWorker 와 AgentRunner 에 대해 알아보자:
- AgentWorker:
- 주어진 Task 를 실행하도록 하는 역할을 함.
- AgentRunner:
- Task 를 생성하고 AgentWorker 에 dispatch 하는 역할을 한다.
- 상태 저장도 함.
실행하는 코드 예시는 다음과 같음.
from helper import get_openai_api_key
OPENAI_API_KEY = get_openai_api_key()
import nest_asyncio
nest_asyncio.apply()
from utils import get_doc_tools
vector_tool, summary_tool = get_doc_tools("metagpt.pdf", "metagpt")
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0)
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
response = agent.query(
"Tell me about the agent roles in MetaGPT, "
"and then how they communicate with each other."
)
Full Agent Reasoning Loop:
- 현재 대화뿐만 아니라 이전의 대화 기록에 기반해 다음 행동(action)을 결정하는게 가능함.
- agent.query() 는 현재 대화만 고려하고, agent.chat() 은 이전 대화까지 고려함
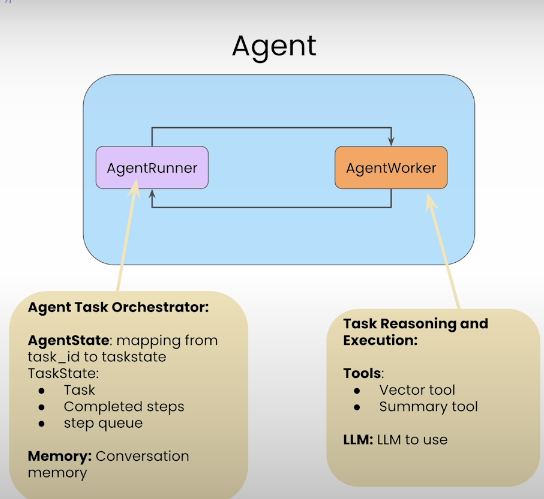
Agent Control:
- low-level API 를 이용해서 Agent 의 각 실행 단계에 대해서 볼 수 있음.
- create_task() 함수를 통해서 task 를 생성할 수 있고, run_step() 을 통해서 task 를 단계적으로 실행하는게 가능함.
- get_completed_steps() 를 통해서 스텝의 작업을 완료할 수 있음.
agent_worker = FunctionCallingAgentWorker.from_tools(
[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
task = agent.create_task(
"Tell me about the agent roles in MetaGPT, "
"and then how they communicate with each other."
)
step_output = agent.run_step(task.task_id)
completed_steps = agent.get_completed_steps(task.task_id)
print(f"Num completed for task {task.task_id}: {len(completed_steps)}")
print(completed_steps[0].output.sources[0].raw_output)
upcoming_steps = agent.get_upcoming_steps(task.task_id)
print(f"Num upcoming steps for task {task.task_id}: {len(upcoming_steps)}")
upcoming_steps[0]
step_output = agent.run_step(
task.task_id, input="What about how agents share information?"
)
4. Building a Multi-Document Agent
이전 예시에서는 Document 에 따라서 Q&A 를 위한 Vector tool 와 요약을 위한 Summary tool 을 만들었음.
여기서는 도큐먼트가 많을 때 어떻게 대응하는지 본다.
Document 의 종류에 따라서 각각의 툴을 만들 수 있음.
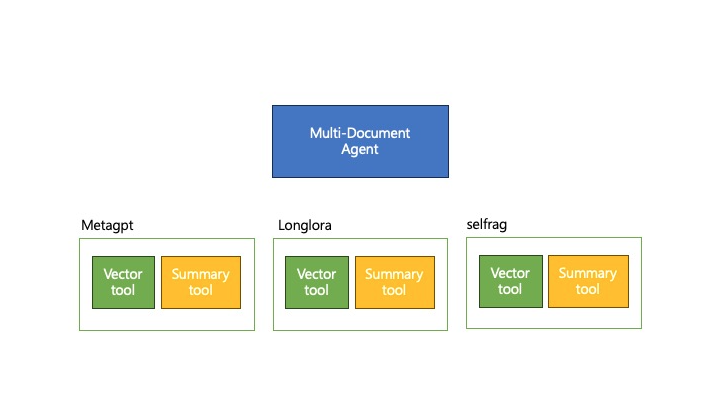
3개의 문서에 대해 각각 vector tool, summary tool 생성하는 방법임
이렇게 하면 여러개의 도구를 동시에 사용해서 사용자의 요청을 처리하는 게 가능하다.
예시 코드로는 다음과 같을 것.
from helper import get_openai_api_key
OPENAI_API_KEY = get_openai_api_key()
import nest_asyncio
nest_asyncio.apply()
urls = [
"https://openreview.net/pdf?id=VtmBAGCN7o",
"https://openreview.net/pdf?id=6PmJoRfdaK",
"https://openreview.net/pdf?id=hSyW5go0v8",
]
papers = [
"metagpt.pdf",
"longlora.pdf",
"selfrag.pdf",
]
from utils import get_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
for paper in papers:
print(f"Getting tools for paper: {paper}")
vector_tool, summary_tool = get_doc_tools(paper, Path(paper).stem)
paper_to_tools_dict[paper] = [vector_tool, summary_tool]
initial_tools = [t for paper in papers for t in paper_to_tools_dict[paper]]
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
initial_tools,
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
response = agent.query(
"Tell me about the evaluation dataset used in LongLoRA, "
"and then tell me about the evaluation results"
)
response = agent.query("Give me a summary of both Self-RAG and LongLoRA")
print(str(response))
하지만 Document 의 개수가 많으면 어떨까? 사용할 수 있는 도구가 많아지고 도구의 출력을 다 Context Window 에 담기는 어려워지고 비용도 증가하는 문제가 생긴다.
그래서 이런 경우에는 RAG 에서 사용하는 방법처럼 관련성이 있는 top-k 개의 도구를 뽑아서 사용하면 됨.
예제 코드는 다음과 같다:
urls = [
"https://openreview.net/pdf?id=VtmBAGCN7o",
"https://openreview.net/pdf?id=6PmJoRfdaK",
"https://openreview.net/pdf?id=LzPWWPAdY4",
"https://openreview.net/pdf?id=VTF8yNQM66",
"https://openreview.net/pdf?id=hSyW5go0v8",
"https://openreview.net/pdf?id=9WD9KwssyT",
"https://openreview.net/pdf?id=yV6fD7LYkF",
"https://openreview.net/pdf?id=hnrB5YHoYu",
"https://openreview.net/pdf?id=WbWtOYIzIK",
"https://openreview.net/pdf?id=c5pwL0Soay",
"https://openreview.net/pdf?id=TpD2aG1h0D"
]
papers = [
"metagpt.pdf",
"longlora.pdf",
"loftq.pdf",
"swebench.pdf",
"selfrag.pdf",
"zipformer.pdf",
"values.pdf",
"finetune_fair_diffusion.pdf",
"knowledge_card.pdf",
"metra.pdf",
"vr_mcl.pdf"
]
from utils import get_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
for paper in papers:
print(f"Getting tools for paper: {paper}")
vector_tool, summary_tool = get_doc_tools(paper, Path(paper).stem)
paper_to_tools_dict[paper] = [vector_tool, summary_tool]
all_tools = [t for paper in papers for t in paper_to_tools_dict[paper]]
# define an "object" index and retriever over these tools
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
obj_index = ObjectIndex.from_objects(
all_tools,
index_cls=VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
tools = obj_retriever.retrieve(
"Tell me about the eval dataset used in MetaGPT and SWE-Bench"
)
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tool_retriever=obj_retriever,
llm=llm,
system_prompt=""" \
You are an agent designed to answer queries over a set of given papers.
Please always use the tools provided to answer a question. Do not rely on prior knowledge.\
""",
verbose=True
)
agent = AgentRunner(agent_worker)
response = agent.query(
"Tell me about the evaluation dataset used "
"in MetaGPT and compare it against SWE-Bench"
)
print(str(response))
response = agent.query(
"Compare and contrast the LoRA papers (LongLoRA, LoftQ). "
"Analyze the approach in each paper first. "
)Conclusion
LangGraph 와 LlamIndex 의 Agent 사용 방법에 대해서 비교해봤을 때 LangGraph 가 좀 더 유연하고 응용할 여지가 많다라고 생각함.
이 코스에서 배운 건 LLM 이 여러 응용에 많이 활용되고 있다는 것을 느낌. Routing 에서만 활용되는 것 뿐 아니라, Retrieve 에서도 Evaluator 에서도 활용될 수 있을듯.
Agent 를 활용할 떄 기본적으로 중요한 요소는 Debugging, Evaluating
'Generative AI' 카테고리의 다른 글
| Domain-specific LLMs (0) | 2024.06.20 |
|---|---|
| METAGPT: META PROGRAMMING FOR AMULTI-AGENT COLLABORATIVE FRAMEWORK (0) | 2024.06.20 |
| Functions, Tools and Agents with LangChain (0) | 2024.06.12 |
| What We’ve Learned From A Year of Building with LLMs (0) | 2024.06.11 |
| Building and Evaluating Advanced RAG (0) | 2024.06.10 |