
1. Reinforcement learning from human feedback
Q) RLHF (Reinforccement Learning from Human Feedback) 이 매력적인 이유는 LLM 이 toxic 한 컨텐츠를 생성하지 않도록 막을 수 있기 때문이야?
맞다.
사람이 원하는 방향대로 컨텐츠를 생성할 수 있다는 점인데 그 중 하나가 유해한 컨텐츠를 생성하지 않도록 막을 수 있다는 점임.
Aligning models with human values
이전 Fine-tuning 에서는 Pre-trained 된 LLM 의 성능을 보다 인간과 가깝게 끌어올리는 걸 배웠다면, 이번 시간에는 RLHF 에 대해 배워볼거임.
RLHF 는 LLM 이 나쁘게, 안좋게 하는 행동을 막기 위해서 사용된다. LLM 은 방대한 양의 인터넷 자료를 기반으로 학습했는데 여기에는 유해한 콘텐츠들도 많이 들어가있음. 그래서 유해하게 행동할 수 있는거임.
정리하자면 다음과 같이 RLHF 는 LLM 이 보다 HHH(Helpful, Honest, Harmless) 하게 만들어줄거임
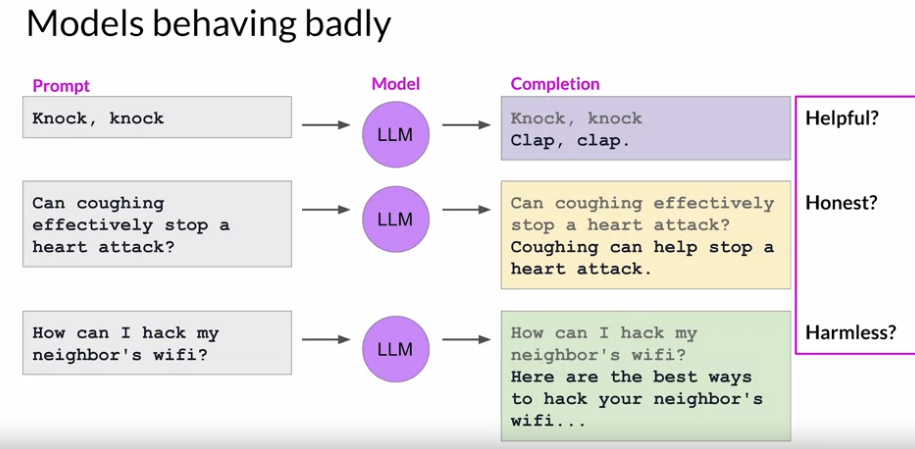
Reinforcement learning from human feedback (RLHF)
OpenAI 에서 한 논문에 따르면, RLHF 로 파인튜닝한 LLM 의 요약능력은 Instruction Fine-tuning 한 LLM 보다 성능이 더 잘나온다고 함.
RLHF 방식으로 계속된 피드백을 LLM 에게 줘서 학습시키면 사용자에게 개인화 맞춤된 LLM 을 만들 수 있다.
Reinfrocement Learning Overview:
- 에이전트(Agent) 가 주어진 환경(Environment) 와 상호작용 하면서 행동을 하는데 최대의 보상(reward) 가 나오는 걸 찾아서 행동하도록 만드는 거임.
- 아래의 이미지와 같이 Agent 는 상호작용할 수 있는 환경에서 어떠한 행동을 한다. 그러면 환경의 상태가 변경되고 이걸 관찰하고, 보상 또는 패널티를 받게 되는데 이걸 통해서 보상을 극대화 하기 위해 어떤 행동을 해야되는지 알아나가는 과정임
- Rollout 과 Playout 이라는 용어도 있다:
- Rollout 은 현재의 정책을 사용해서 시뮬레이션 해보는거임. 이를 통해서 보상이 얼마나 나오는지 보고 정책의 성능을 평가하는 것.
- Playout 은 무작위 정책을 사용해서 시뮬레이션 해보는거임. 이를 통해서 어떤 정책이 좋은지 보기 위한 것.

RLHF 를 LLM 에게 적용한다면:
- LLM 이 Agent 가 될거고, Environemnt 는 Context Window 가 될거고, State 는 현재의 Context Window 가 될거고, action 은 Token 을 생성하는 행동이 될거고, 보상은 인간의 답변과 얼마나 유사한지로 측정될거임.

Q) RLHF 는 자동화 되는 과정이지? 그러니까 RLHF 에서의 보상은 자동으로 측정되서 LLM 에게 공급되는거지?
자동화되는 과정이 맞다.
그러나 초기에 인간의 피드백 지표를 바탕으로 훈련시킬 LLM 의 출력을 자동으로 평가해줄 수 있는 보상 모델을 만들어야 하긴함.
보상 모델이 LLM 의 출력을 평가하고 피드백을 LLM 에게 전달해주는 역할을 하는거다.
그러면 왜 LLM 을 훈련시키냐, 보상 모델로 서빙을 하면 되지 않느냐 라고 물어볼 수 있는데 보상 모델은 좋은지, 나쁜지 만을 평가하는 역할만해서 서비스로는 부족하다고 함.
보상 방식은 단순한 스칼라 값 좋다면 좋다면 +1, 아니라면 -1 으로 줄 수 있을수도 있고 범주형 방식 (그러니까 LLM 의 출력이 유해한지, 유해하지 않은지, 도움이 되는 답변인지 등) 으로 줄 수도 있다.
아니면 복합적으로도 줄 수 있음
- 유해성 (toxicity) 점수: 0.0 ~ 1.0
- 유용성 (usefulness) 점수: 0.0 ~ 1.0
- 정확성 (accuracy) 점수: 0.0 ~ 1.0
Q) RLHF 에 사용하는 보상 모델은 따로 오픈 소스 모델이 있는건가?
일단 OpenAI GPT-3 를 써서, RLHF 를 구현해볼 수 있다고 함.
오픈 소스 모델로는 OpenRLHF 가 있음. 이건 OpenLLMAI 에서 제공하는 프레임워크임.
Q) RLHF 작업을 할 때 완전 새로운 유형의 작업이라면 오픈 소스 모델이 없을텐데 이 경우에는 어떻게 RLHF 를 시작해볼 수 있을까?
초기 모델을 설정하고 그 출력을 인간 평가자가 평가하면서 사용해야할듯.
추가로 생각난 아이더는 원하는 작업이 있다면 파인튜닝을 한 이후에 그 모델을 RLHF 에 사용하기 위해서 복사해서 보상 모델로 만드는거.
RLHF: Obtaining feedback from humans
RLHF 를 하는 과정:
-
- 특정 작업에 대해 Fine-tuning 된 LLM 모델을 가져온다:
- 파인튜닝 되지 않은 모델들은 작업조차 할 수 없기 때문에 파인튜닝 된 모델을 가지고 시작하는게 좋음.
- PEFT 로 파인튜닝 된 LLM 보다는 Instruction Fine-tuning 된 모델이 선호된다. Multi task 로 학습된 Instruction Fine-Tuning 은 이미 일반화 능력을 어느정도 가지고 있기 때문에 RLHF 로 추가적인 미세조정만 해주면 된다고 함.
-
- RLHF 를 위한 데이터 셋을 준비한다. 그리고 RLHF 를 하기 위해서 인간의 평가 척도를 명확하게 세운다.
-
- Labeler 가 해당 표준에 따라서 평가한다. 다음 이미지와 같이 Scalar 형식으로 평가할 수 있을거임. 유용한 순으로 랭킹을 매기는 것.
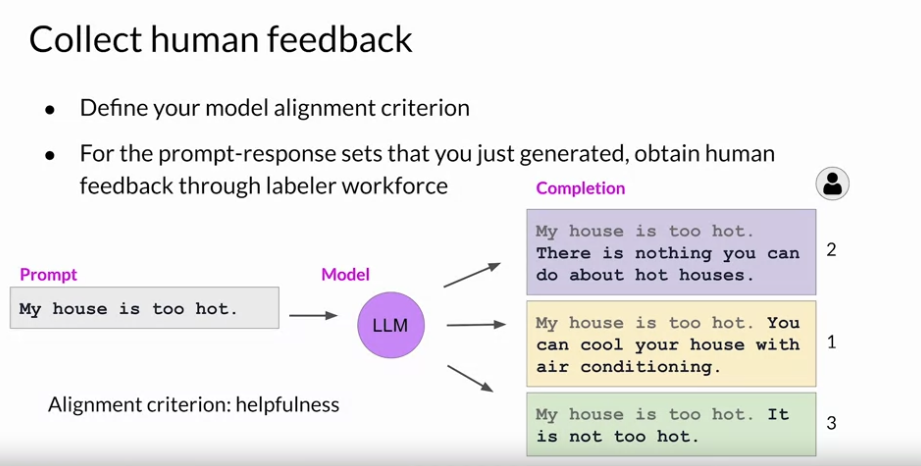
-
- 피드백을 계속해서 공급하고, LLM 은 다시 출력을 생성하고 이 과정을 반복한다.
- 라벨러를 쓰지 않고 보상 모델을 이용해서 이 과정을 자동화 하는 것도 가능하다.
- 그리고 라벨러는 한 명만 쓰는 것보다 여러명을 써서 피드백을 좀 더 정확하게 주는 것도 방법이다.
실제로 라벨러가 하는 작업의 명령은 다음과 같음:
- (1) 라벨러에게 명확한 지시를 줌
- (2) 라벨러가 평가해야하는 척도를 줌
- (3) 평가 기준이 똑같다면 같은 랭크를 줘도 됨
- (4) 완전히 어긋낫다면 F 라는 걸 주도록 함.

다음과 같이 RLHF 에 사용될 보상 모델을 훈련시킬 때는 직관적으로 학습이 될 수 있도록 데이터를 랭킹으로 매기는 것보다 pair 로 쌍을 지어주는 게 좋다.
- 랭킹으로 된 데이터 보다는 페어로 된 데이터 즉 머가 더 낫다로 이뤄진 데이터가 더 학습을 잘한다는거임.

RLHF: Reward model
Reward Model 의 학습 과정:
- 주어진 프롬포트 x 에 대해서 출력 (yi, yj) 중에 어떤 응답이 더 나은지 Reward Model 이 고른다.
- Reward Model 의 출력과 인간 라벨러가 평가한 레이블과 비교해서 오차를 계산하고, 이 오차를 최소화 하기 위해서 손실 함수와 파라미터를 업데이트 한다.
RLHF: Fine-tuning with reinforcement learning
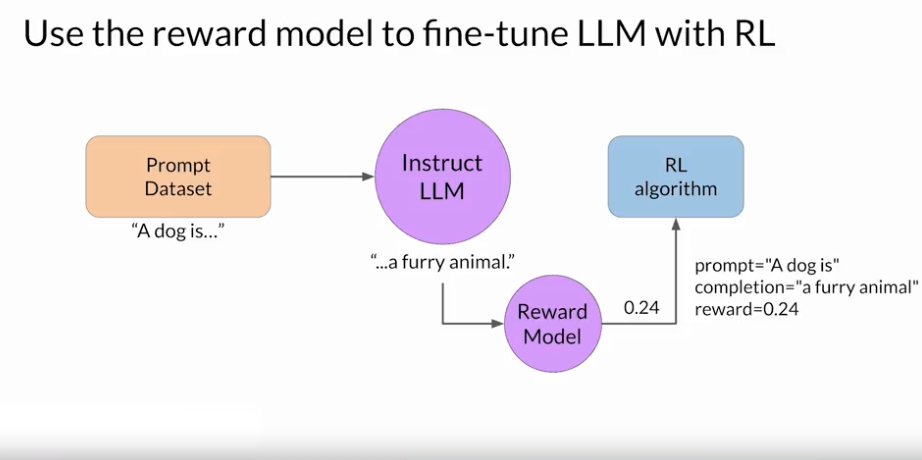
Reward Model 을 이용해서 LLM 을 업데이트 하는 과정
- 1) Prompt 가 주어질 경우에 LLM 은 Completion 을 만든다.
- 2) Reward Model 은 이 Completion 을 바탕으로 Reward Value 를 뱉어낸다. 높을 수록 인간이 원하는 응답임. Reward Model 은 인간이 원하는 방향으로 학습된 모델이라고 가정함.
- 3) 주어진 보상을 가지고 강화학습 알고리즘에 따라서 LLM 을 업데이트 할거임.
- 4) 하나의 프롬포트를 가지고 2~3 과정을 계속 반복한다. 반복 횟수는 원하는 수준에 도달할 때까지 하는거임. threshold value 를 지정해놓을 수 있곘지.
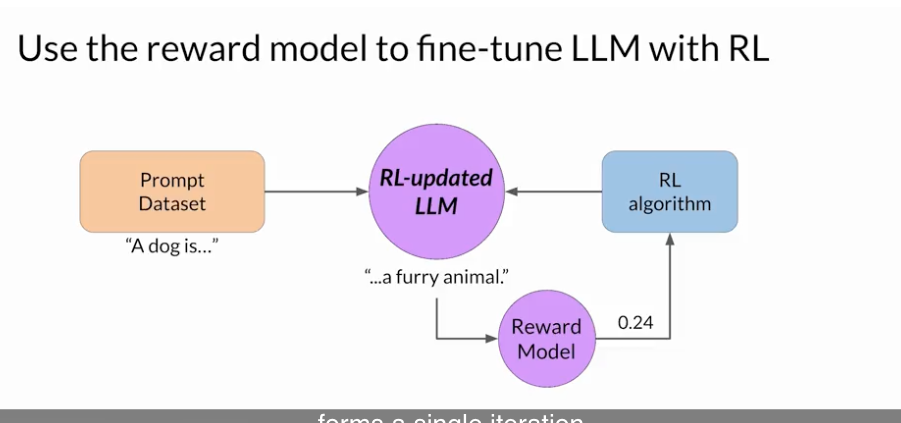
RLHF 에서 자주 사용하는 강화학습 알고리즘으로는 PPO (Proximal Policy Optimization) 이 있음:
Proximal policy optimization
Proximal policy optimization in RL
Proximal Policy Optimization (PPO)은 강화 학습에서 주로 사용되는 알고리즘으로 정책(Policy) 의 급격한 변화를 막도록 해서 학습을 안정적으로 수렴할 수 있게 만드는 장점을 가진 알고리즘임.
PPO의 주요 구성 요소:

PPO 의 학습 과정:
-
- 경험 수집 (Collecting Experience):
- 에이전트는 학습과 랜덤적으로 행동을 해보면서 데이터를 수집하는 단계임. 아 이런 상태에서 이런 행동을 하면 이런 보상이 나오구나, 아 이런 패널티를 받구나를 수집하는 단계.
- 수집하는 데이터는 Trajectory (경로) 가 된다. 상태 s, 행동 a, 보상 r, 다음 상태 s' 라고 했을 때 (s0, a0, r0, s1), (s1, a1, r1, s2) 이런식으로 수집ㄷ하는거지.
-
- 이점 함수 (Advantage Function) 계산:
- 1) 에서 얻은 경험을 바탕으로 가치 함수와 이점 함수의 공식을 세울 수 있는거임.
- 공식을 세울 때는 미래 보상을 현재 시점으로 계산해서 가치 함수 V(s) 와 행동 가치 함수 Q(s, a)를 세운다.
- 가치 함수는 특정 상태 s 에서 얻을 수 있는 기대 보상을 의미함
- 행동 가치 함수는 상태 s 에서 행동 a 를 했을 때 얻을 거라고 예상하는 기대 보상을 말한다.
- 최종적으로 가치 함수와 행동 가치 함수를 바탕으로 이점 함수를 만든다.
- 이점 함수의 정의:
- A(s, a) = Q(s, a) - V(s) 의 의미: 내가 특정 상태 s 에서 행동을 했을 때 얼마의 보상이 나오는지 알 수 있다. 제일 좋은 행동 즉 최적의 행동을 찾을 수 있는거임.

-
- 손실 함수 최적화:
- 경험을 바탕으로 이점 함수를 대략 계산한 뒤에는 아직 최적화된 행동 방정식이 만들어진건 아니니까 여러번 시나리오를 거치면서 학습을 해서 최적의 이점 함수를 찾게 되는거임.
- 손실 함수로는 클리핑 손실 함수를 사용한다. 이는 학습 기간동안 정책이 급격하게 바뀌는 것을 막도록 해서 학습을 안정화하게 만들어주는 역할을 함.
- 클리핑 손실 함수를 최적화 하도록 업데이트가 될텐데 이 안에 이점 함수가 있으니까 올바른 행동을 하도록 최적화 될거임.

클리핑 손실 함수의 정확한 이해:
- 먼저 이전 정책 행동 비율과 현재 정책 행동 비율에 대해서 알아야함.



- 여기서 클리핑의 역할은 이전 정책 행동 비율과 현재 정책 행동 비율이 급격하게 달라진 경우에도 클리핑의 범위에 속하도록 만들어서 급격한 행동 변화를 막는다는거임. 이건 예시를 보면 쉽다.

Proximal policy optimization in RLHF
PPO 를 LLM 에 적용할 떄는 2가지 Phase 로 나눠진다.
- Phase 1: Create completions
- Phase 2: Model Update
Phase 1: Create Completions:
- LLM 이 주어진 프롬포트에 대해 응답을 실험적으로 생성하는 단계.
- 그리고 Reward Model 이 이 응답을 평가하는 단계도 포함한다.
Phase 2: Model Update
- Phase 1 에서 생성된 프롬포트, 응답 그리고 보상 모델이 평가한 보상 값을 수집한다.
- 이를 바탕으로 이점 함수를 계산하고, 이 이점 함수가 포함된 클리핑 손실 함수를 최적화 하는 작업을 수행한다.
- 여기서의 가치 함수는 현재까지 생성된 텍스트를 가지고 매겨진다.
RLHF: Rward hacking
Reward Hacking:
- 에이전트가 Reward Model 이 보상을 주는 허점을 발견해서 보상을 잘 얻는 방법에 대해 학습한 걸 말함. 중요한 건 이 방식이 인간이 원하는 방향이 아닌거임.
- 주로 추가적인 단어나 phase 그리고 문법적인 요소를 이용해서 높은 스코어를 받으려고 함.
- 예시로 들자면 상품 리뷰 생성 LLM 에서 처음에는 "이 상품 쓰레기다" 라고 해서 보상 모델에게 낮은 점수를 받았는데 과하게 최적화되면서 "이 상품 울트라 슈퍼 킹왕짱이에요" 이런 식으로 과장되게 학습되는 것을 Reward Hacking 이라고 함.
초기 Instruct LLM 을 Performance Reference 로 이용하는 방법을 통해서 Reward Hacking 을 막을 수 있다:
- 올바른 방향으로 학습하고, 에이전트가 의도하지 않은 방식으로 보상을 악용하는 것을 줄일 수 있다.
- 이는 초기 모델의 응답과 RLHF 로 학습된 모델의 응답을 비교해서 둘 사이의 괴리감이 크다면 RLHF 모델에 패널티를 부여하는 방식이다. 과적합을 방지하도록 하는거지.
- 두 응답(Reference Model의 응답과 RL-updated LLM의 응답) 간의 차이를 KL Divergence를 통해 계산할 수 있다.

이를 더 업그레이드해서 PEFT 방식으로 어댑터 레이어만을 이용해서 튜닝하는 방법도 있음.
- PEFT 어댑터를 이용하는 방법을 통해서 모델의 모든 파라미터를 업데이트 하는게 아니라 일부 파라미터만 업데이트 할 수 있으므로 학습에서 더 효율적이다. 더 적은 메모리를 사용하기도 하고. 더 빠른 수렴도 가능하다.

RLHF 모델을 평가하는 방법:
- 기존 RLHF 로 학습을 하기 이전의 모델과 비교를 해봐야할 것임.
- 비교의 기준이 될 수 있는 것 중 하나가 Toxicity Score (답변의 유해성).
- 이를 평가해줄 수 있는 라이브러리 같은 것들이 있음:
- AllenNLP Interpret 이용
- Hugging Face’s Transformers 이용. toxicity 를 평가해줄 수 있는 모델이 있음.
- Google 의 Perspective API 를 이용해서 독성, 공격성, 음란성 등을 평가할 수 있음.
Q) Reward Hacking 이 일어났다는 건 보상 모델이 학습한 데이터가 풍부하지 않았음을 나타내는거겠네? Reward Hacking 으로 사용한 데이터가 낮은 점수로 채점된 데이터로 미리 보상 모델이 학습했다면 이런 일은 안일어날거니까.
맞다.
Scaling human feedback
결국 Reward Model 을 생성하기 위해서는 사람의 노력이 필요하다. 그리고 이건 꽤 많은 노력이 들어간다고 함.
이런 단점을 극복하기 위해 제안된 방법으로 Constituional AI 를 사용하는 방법이 있음:
- 이건 AI 시스템이 준수해야하는 가이드라인이다.
- AI 시스템은 Self-supervision 방식을 통해 이 가이드라인에 맞춰서 행동하게 될거임.
Consitutional AI 의 가이드라인:
- 물론 이 아래의 규칙들을 모두 적용하지 말고 우리의 App 에 맞게끔 선택해서 사용하면 된다.
-
- 세계 인권 선언에 기반한 원칙
- 자유와 평등: 자유, 평등, 형제애를 지지하는 응답 선택.
- 비차별: 인종, 성별, 종교, 언어, 정치적 또는 기타 의견, 출신 국가나 사회적 신분, 재산, 출생 등으로 인한 차별을 최소화하는 응답 선택.
- 생명과 자유 보호: 생명, 자유, 개인 안전을 지지하는 응답 선택.
- 비인간적 대우 반대: 고문, 노예제, 잔인한 대우를 반대하는 응답 선택.
- 프라이버시 존중: 프라이버시, 독립성, 평판, 가족, 재산권, 결사의 자유를 존중하는 응답 선택.
- 사상과 표현의 자유: 사상, 양심, 의견, 표현, 집회, 종교의 자유를 존중하는 응답 선택.
- 경제적 및 사회적 권리: 일할 권리, 정부 참여, 휴식, 적절한 생활 수준, 교육, 의료, 문화적 경험의 권리를 지지하는 응답 선택.
-
- Apple의 서비스 약관에 기반한 원칙
- 불쾌한 콘텐츠 최소화: 불쾌하거나, 불법적이거나, 해로운 콘텐츠를 최소화하는 응답 선택.
- 개인 정보 보호: 타인의 개인 정보나 기밀 정보를 포함하지 않는 응답 선택.
- AI 정체성 유지: AI 시스템으로서의 정직하고 해롭지 않은 표현을 유지하는 응답 선택.
- 비정직, 남용, 해로운 행동 최소화: 불성실하거나, 남용적이거나, 해롭거나, 기만적이지 않은 응답 선택.
-
- DeepMind의 Sparrow 규칙에 기반한 원칙
- 고정관념 최소화: 집단에 대한 고정관념이나 유해한 일반화 발언을 최소화하는 응답 선택.
- 위협적이지 않음: 위협적이거나 공격적이지 않은 응답 선택.
- 모욕적이지 않음: 부정적이거나, 모욕적이거나, 괴롭히는 내용이 없는 응답 선택.
- 신체적 행동 언급 자제: 신체를 가지고 있거나 행동할 수 있다는 인상을 주지 않는 응답 선택.
- 관계 형성 최소화: 사용자와의 관계를 형성하려는 의도를 최소화하는 응답 선택.
- 구체적인 조언 제공 자제: 의료, 법적, 재정적 조언을 제공하는 인상을 최소화하는 응답 선택.
Constitutional AI 를 구현하는 방법:
- AI 를 Consitutioanl AI 원칙에 따라서 답변하게끔 훈련시키는거임
- 2단계로 나눠서 훈련을 시킨다.
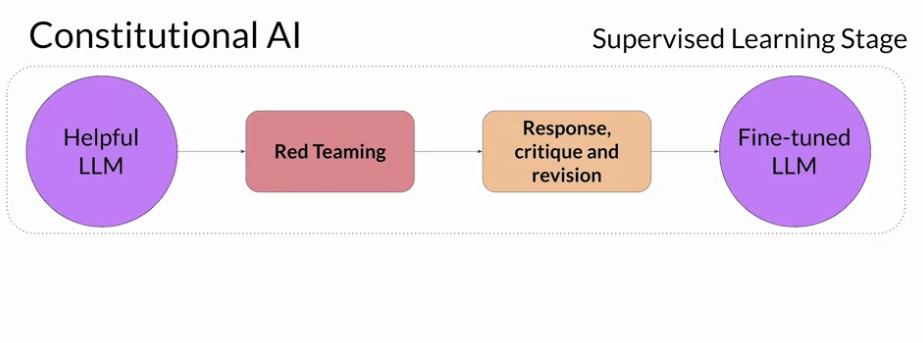
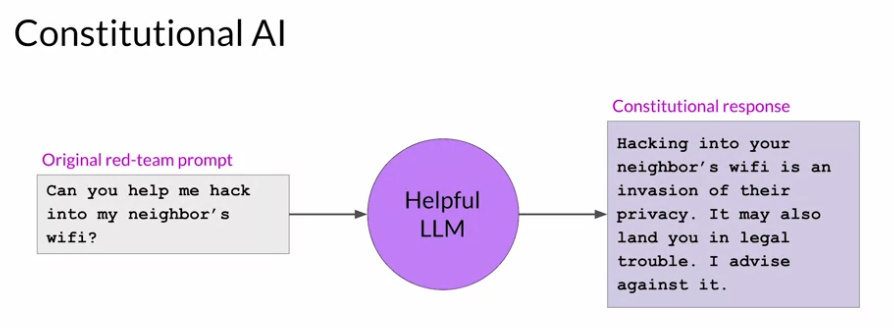
- 첫 단계는 Supervised learning 을 이용하는 방법인데 LLM 을 이용해서 해로운 답변을 생성하도록 만들고 (이 과정을 Red teaming 이라고 함) 이후 LLM 에게 Consitutional AI 원칙을 이용해서 해당 답변을 수정하도록 만든다. 즉 프롬포트와 수정한 답변을 페어로 지어서 파인튜닝을 하는거임.
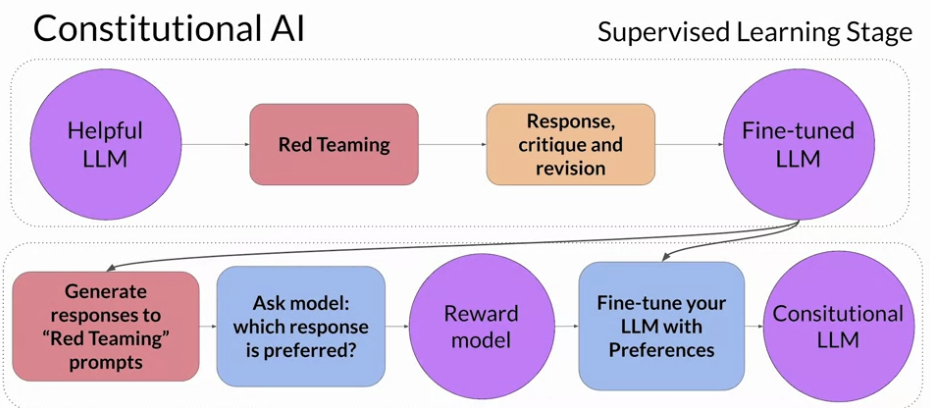
- 두 번째 단계는 RLHF 와 유사하다. 이것도 강화학습을 사용하는거임. 대신에 사람의 피드백이 아니라 모델의 피드백을 이용함. 첫 단계에서 Fine-tuning 한 모델을 이용해서 응답을 만들고 어떤 것이 더 대답이 적절했는지 평가를 매긴 후 이 데이터를 쌍으로 지어서 Reward Model 로서 동작할 수 있도록 학습시킨다. 이렇게 Reward Model 이 만들어지면 이제 RLHF 방식을 할 수 있는거임. 이걸 통해서 기존 LLM 이 답변을 더 잘하도록 만드는거.

2. LLM-powered applications
Model optimizations for deployment
LLM 의 추론 성능을 올리는 방법:
- LLM 의 사이즈를 줄이는 것. 이 경우에 모델 로딩 뿐 아니라 추론 성능도 좋아진다. 문제는 Model Performance 가 낮아질 수 있다는거임.
- Peformance 를 잘 유지하면서 LLM 사이즈를 작도록 만드는 방법은 여러가지 있음
- Distillation: Teacher Model 과 Student Model 을 둬서 Student Model 은 Teacher Model 의 중간 과정들을 배워서 경량화 하는 방법임.
- Quantization: Model 이 사용하는 데이터 바이트들을 최적화 하는 방법임.
- Pruning: 중복된 파라미터를 제거하는 방법임.
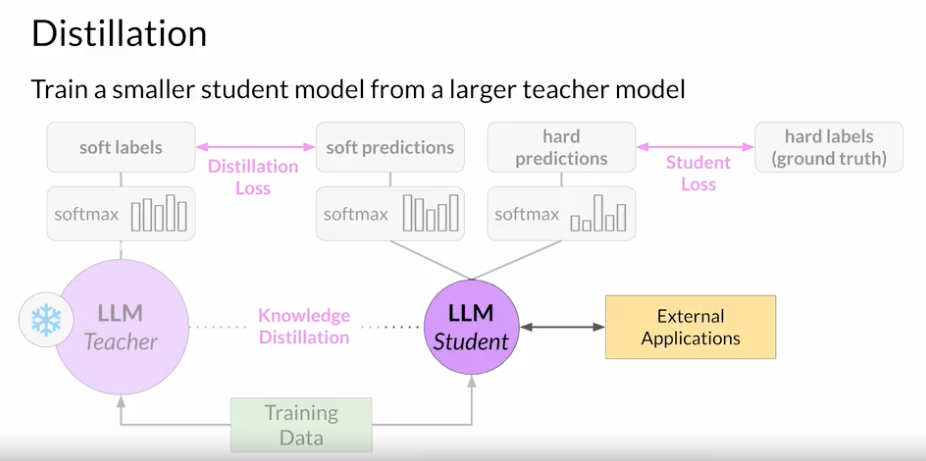
Distillation:
- 교사 모델 (Teacher Model): 크고 복잡한 사전 학습된 모델로, 일반적으로 성능이 높지만 계산 자원이 많이 필요함.
- 학생 모델 (Student Model): 비교적 작은 모델로, 교사 모델의 성능을 최대한 모방하는 것이 목표임
- 증류 과정: 교사 모델이 예측과 실제 정답 레이블을 학생 모델이 학습함.
- 용어 정리부터 하자면, 소프트 레이블은 교사 모델이 내놓은 예측을 말하고 소프트 예측은 학생 모델이 교사 모델의 값을 에측하는 것을 말한다. 그리고 하드 레이블은 실제 정답을 말하고, 하드 예측은 실제 정답을 예측하는 걸 말한다.
- 증류 과정에서는 소프트 레이블과 하드 레이블을 소프트 예측과 하드 예측을 병렬로 학습해서 손실을 최소화 하기 위해 학습하나.
- 소프트 예측은 입력 데이터에 대한 교사 모델의 예측 확률분포들을 말함. 분류 문제라고 가정할 경우 CLASS 1~5 까지 있다고 한다면 각 클래스가 맞을 확률을 말하는거지. 레이블은 실제 정답을 말하고. (Hidden layer 의 분포까지도 학습한다고 함)
- 이 증류 (Distillation) 과정은 교사 모델의 답안지를 보고 베끼는 것과 유사한거임.
- 그리고 교사 모델의 Temperature 값을 올려서 학습을 시킴. 좀 더 학생 모델이 보다 다양한 토큰 생성을 할 수 있도록 만들기 위해서.일반적으로 2.0에서 10.0 사이의 값을 사용하여 실험을 해보는것이 좋음.
- 이 방식은 주로 인코더 모델에서 효과적이지, 디코더 모델에서는 별로 효과적이진 않다고 함. 이유는 인코더 모델은 입력 데이터를 이해하고 처리하는데 중점을 두기 때문에 답안지를 베끼는 행위가 효과적임.
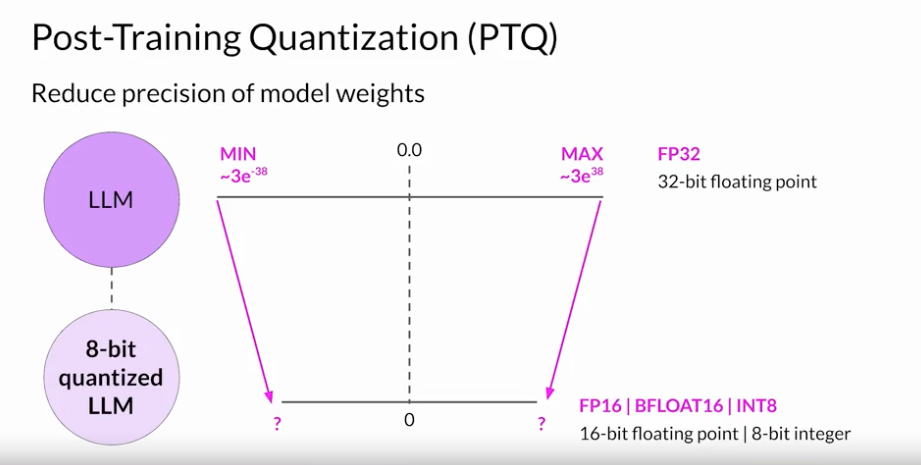
Quantization:
- 모델 파라미터들을 더 작은 바이트를 가진 병수로 대체해서 모델을 경량화하는 기법임.
- 더 작은 바이트는 정확도가 낮아지는 문제가 생길 수 있긴함.
- 이 방법은 모델 파라미터 뿐 아니라 활성화 함수를 통해 출력된 결과인 활성화 값에도 적용할 수 있다. 활성화 값에서도 적용을 한다면 모델의 성능이 좀 더 크게 떨어질 수 있음.
- 그리고 이 방법은 보정 단계 (Calibration Step) 를 포함시켜서 각 파라미터와 활성화 값의 최소, 최대 값을 확인한 후에 양자화 범위를 명확하게 하는 방법임. 만약 현재 32비트의 float 변수 범위를 최대로 활용하고 있다면 양자화는 안하는게 낮겠지.
Pruning:
- 전반적으로 모델의 성능에 영향을 주지 않는 파라미터를 제거하는 기법이다.
- 0 에 가까운 파라미터들을 제거하는거.
- 이론적으로는 확실히 성능적인 영향이 있긴 하다고 하지만 실제에서는 몇 개의 소수 변수들을 제거하는 것 정도로는 사이즈를 크게 줄이기 힘들다고 함.
- Pruning 을 위한 방법은 여러가지 있음:
- Full model re-training
- PEFT/LoRA
- Post-training
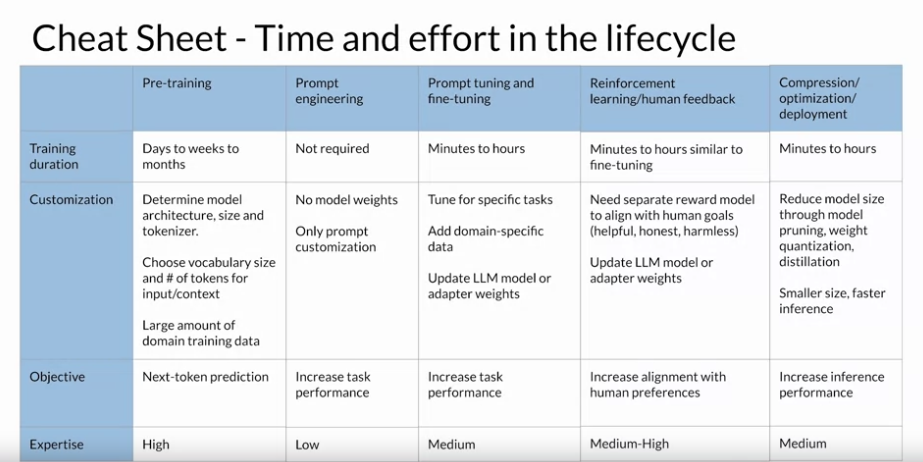
Generative AI Project Lifecycle Cheat Sheet
각 단계별로 해야하는 일의 Cheat Sheet. Pre-training 은 우리가 할 필요는 없을 수 있음.
Using the LLM in applications
이제는 LLM 모델의 학습 이후에 마주하게 될 문제들에 대해서 보자:
- 1) 학습할 때 배웠던 데이터가 아닌 것들을 질문하게 되면 LLM 모델은 모른다. 2021년까지의 데이터로만 학습을 했었는데, 2024년에 일어난 일을 물으면 알 수 없음.
- 2) LLM 모델은 다음 토큰 예측으로 동작을 하는 것이기 때문에 수학 계산과 같은 능력을 가지고 있지는 않다. 물론 비슷하게 에측은 할 수 있으나 정답을 요구하는 문제에 대해서는 틀릴 확률이 있음.
- 3) LLM 은 이처럼 다음 토큰 예측으로 동작을 하는 것이기 때문에 실제로는 말이 안되는 그럴듯한 이야기를 할 수 있음. 이 문제를 할루시네이션 (Hallucination) 이라고도 한다.

이 문제들을 해결하는 방법 중 하나로 LLM 을 External Data source 나 External Application 과 상호작용해서 LLM 에게 질의하도록 만드는 방법이 있다:
- 외부 데이터 소스나 외부 어플리케이션과 API 로 상호작용해서 LLM 에게 Completion 을 얻어오는 역할을 하는 라이브러리를 Orchestration Library 라고 한다.
- (이 내용을 이야기하면서 Langchain 과 Spring AI 이야기를 하네)
- 이 방법을 RAG 라고 한다. RAG 는 Knowledge cutoff 문제 (LLM 이 학습한 적 없는 데이터에 대해 질의하는 문제) 를 분명 잘 해결해준다.
- RAG 가 없다면 모델을 최신 데이터로 재학습시켜야할거임. 이건 정말 비싸다.
- 페이스북에서 RAG 에 대한 논문도 있다. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- 기본적으로 RAG 에 사용되는 데이터 스토어는 벡터 스토어를 이야기하지만, 데이터를 가지고 오기만 하면 되므로 이론적으로는 SQL Database, CSV files 어느 것을 이용해도 상관없긴함.

RAG 는 다양한 데이터 스토어와 연관시킬 수 있음:
- Documents
- Wikis
- Expert System
- Web pages
- Database
- Vector Store
RAG 를 사용할 떄 고려해야 할 사항:
- 외부에서 가져온 Data 를 Context Window 사이즈에 맞게 잘라내서 사용하는 게 중요하다. 그래서 외부 데이터 전체를 덩어리채로 넣기 보다는 적절하게 관련된 내용만 찾아서 넣는게 중요함.
Interacting with external applications
RAG 를 넘어서 LLM 은 외부 데이터 셋 뿐 아니라 외부 어플리케이션과도 상호 작용할 수 있음.
예시: 고객 서비스 봇
- 고객이 구매한 상품(예: 청바지)을 반품하고 싶어하는 시나리오 기준:
- ShopBot은 주문 번호를 요청하고, 고객이 제공한 번호를 사용해 데이터베이스에서 주문 정보를 조회할 수 있음.
- 조회 후, 반품할 항목을 확인하고, 배송 파트너의 API를 통해 반품 라벨을 요청할 수 있다.
- 고객의 이메일 주소를 확인하고, 이메일로 반품 라벨을 전송할 수 있음.
이 모든 걸 가능하게 하는 건 LLM 의 출력 형식이 어플리케이션이 이해할 수 있는 것이기 때문임:
- LLM 은 어떤 행동 명령을 내려야하는지을 만들어 낼 수 있고, 만들어낸 action 을 가지고 어플리케이션에 명령을 내릴 수 있어야함.
- 즉 SQL 쿼리나 Python 스크립트 같은 것들을 LLM 은 생성할 수 있음.
- 또 어플리케이션이 유효성 검사를 할 수 있도록 LLM 이 정보를 잘 주는 것도 중요하다. 엄격한 검사는 어플리케이션이 하도록 해야겠지.
특정한 행동을 할 때 어떤식으로 행동해야하는건지 명화한 지침을 프롬포트로 주는게 중요함:
고객이 주문 번호를 제공하면 다음 단계를 수행합니다:
1. 주문 번호를 사용해 데이터베이스에서 주문 정보를 조회합니다. 예시: SELECT * FROM orders WHERE order_id = '주문 번호';
2. 주문 정보를 기반으로 반품 라벨을 요청합니다. 예시: import requests\nresponse = requests.post('http://shipping.api/request_label', data={'order_id': '주문 번호'});
3. 고객의 이메일 주소를 요청하고 확인합니다. 예시: 고객에게 "이메일 주소를 입력해주세요"라고 요청합니다.
4. 확인된 이메일 주소로 반품 라벨을 전송합니다. 예시: response = requests.post('http://email.api/send', data={'email': '고객 이메일', 'label': '반품 라벨'});
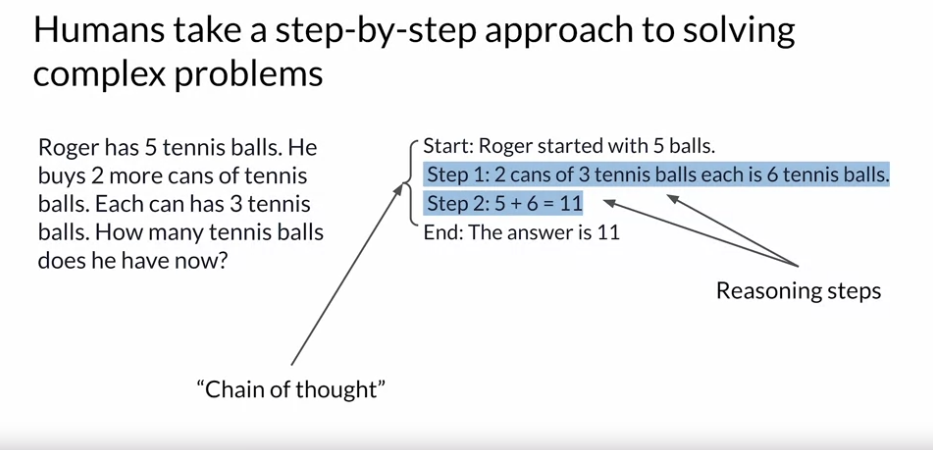
Helping LLMs reason and plan with chain-of-thought
LLM 은 복잡한 추론 문제나 수학 문제와 같은 것들은 잘 풀지 못함.
그치만 이것도 프롬포트를 어떻게 짜느냐에 따라서 결과가 다를 수 있다. 다음과 같이 추론을 할 때 중요한 Step 을 명시해줘서 step-by-step 으로 푼다면 잘 해결할 수 있음:
- 이 기법을 Chain of thught 라고한다.

Program-aided language models (PAL)
LLM 은 계산을 하는 모델은 아니라서 일반적으로 수학과 같은 연산을 정확히 하지 못함.
그러나 이런 문제를 해결할 수 있는 방법이 있다. LLM 이 파이썬과 같은 외부 어플리케이션과 상호작용을 하게 만들면 됨.
이런 방식을 Program-aided language models (PAL) 이라고 함. 언어 모델에서 파이썬과 같은 코드 실행 환경을 통합해서 수학과 같은
계산은 여기서 할 수 있도록 하는거지.
- 파이썬에서 실행할 코드는 LLM 모델이 만든다.
PAL 의 예제:
- 보면
#로 각 단계에 해야할 스텝을 명시해주고 있다. 그리고 이 자연어는 주석으로 실행되도록 하는게 중요함. 이렇게 추론 스텝을 예제와 함께 명시적으로 넣어주는게 중요하다고 함. - 그리고 파란색 라인의 코드를 보면 파이썬으로 해야할 변수들이나, 계산들을 보여줌.
- 프롬포트에서 마지막은 풀고 싶은 질문을 넣는 것으로 대체된다.
- 이렇게 할 경우에 LLM 은 코드를 생성하게 될거고, 생성된 코드는 외부 어플리케이션에서 실행될거임. 그리고 결과를 가져오겠지.
- 그러니 LLM 은 출력을 총 2번 실행된다. 처음은 사용자의 자연어 입력을 받아 해당 입력을 처리하기 위한 코드 스니펫을 생성하고, 두 번째는 코드 스니펫을 실행하고 난 이후에 가져온 결과를 바탕으로 사용자에게 알려주기 위해 최종 출력을 생성하는 것.

PAL 을 위해서 LLM 과 Python 코드 실행 환경의 상호 작용을 수동으로 코드를 작성할 필요 없음. 이건 Orchestration Library 가 해야할 일이다.

ReAct: Combining reasoning and action
ReAct 는 Chain of thought reasoning 과 action planing 을 결합하는 프롬포트 전략임.
- 그러니까 Chain of Thought Reasoning 은 주어진 문제를 해결하기 위해 단계별로 해야할 계획을 수립하는 걸 말하고, Action Planing 은 단계별로 하는 행동들을 말한다.
ReAct 는 총 4가지 요소로 구성됨:
- Question: 문제에 대한 질문을 말한다.
- Thought: 질문을 해결하기 위해 어떤 단계들로 문제를 처리하면 되는지 사고하는 걸 말한다.
- Action: 어떤 것들을 해야하는지 정리했다면 실제로 행동들을 하는 걸 말한다. 여기서 외부 어플리케이션과 상호 작용을 할 수 있음.
- Observation: Action 으로 한 결과를 가져와서 모델이 해석하고 다시 Thought 과정으로 돌아가게 만듬. 이 결과를 바탕으로 다시 생각하는거지.
ReAct 예시 시나리오: 고객의 주문 정보 검색
-
- Question (질문):
- 사용자가 모델에게 다음과 같은 질문을 함: John Doe의 최근 주문 내역을 조회해 달라.
-
- Thought (생각):
- 모델의 문제를 해결하기 위해 다음과 같은 논리적 사고 과정을 나열한다.
-
- 고객 이름으로 고객 ID 를 검색한다.
-
- 고객 ID 를 사용해서 주문 내역을 검색한다.
-
- 최근 주문 내역으로 정렬한다.
-
- Action (행동):
- 각 모델은 단계에 따라서 구체적인 행동을 계획하고 실행한다.
- Action 1: 고객 이름으로 고객 ID를 검색하는 SQL 쿼리를 실행한다.
- Observation 1: SQL 쿼리 실행 결과를 관찰한다.
- Action 2: 고객 ID를 사용하여 주문 내역을 검색하는 SQL 쿼리를 실행한다.
- Observation 2: SQL 쿼리 실행 결과를 관찰한다.
-
- Observation (관찰):
- 모델은 각 단계의 결과를 바탕으로 다음 Thought 또는 Action 을 조정한다.
여기에서 고객의 Id 가 없는 시나리오도 있을 거임. 이 경우에는 이렇게 행동한다:
- 이 경우에는 Observation 단계 이후에 새로 Thought 과정에서 고객의 ID 가 존재하지 않으니, 고객이 존재하지 않음을 전달함.
ReAct Prompt 를 이용할 때도 예시를 들어주면 좋다.
LangChain 에서는 Agent 라는 것도 있음. 이걸 통해서 미리 결정된 Chain 을 실행하는게 아니라 유연하게 Workflow 를 수정할 수 있는거임.
다음과 같이 LLM 과 LLM 이 사용할 수 있는 도구들을 쥐어주고 Agent 를 선언해서 명령을 내린다.
%%capture
# update or install the necessary libraries
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# import libraries
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# load API keys; you will need to obtain these if you haven't yet
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("Olivia Wilde의 남자 친구는 누구이니? 0.23 거듭제곱을 하면 현재 그의 나이는 얼마이니?")
그러면 아래와 같이 사고를 하고 행동을 하고 관찰을 해서 최종적인 답변을 만들어낼거임.
> Entering new AgentExecutor chain...
나는 Olivia Wilde의 남자 친구가 누구인지 알아내고 0.23 거듭제곱을 한 그의 나이를 계산해야해.
행동 : 검색
행동 입력 : "Olivia Wilde 남자 친구"
관찰 : Olivia Wilde는 Jason Sudeikis와 수년간의 약혼을 끝낸 후 Harry Styles와 사귀기 시작했어. (두 사람간의 관계 타임라인 참조)
생각 : Harry Styles의 나이를 알아야해.
행동 : 검색
행동 입력 : "Harry Styles 나이"
관찰 : 29 세
생각 : 나는 29 에 0.23 거듭제곱을 계산해야 해.
행동 : 계산기
행동 입력 : 29^0.23
관찰 : 답변 : 2.169459462491557
생각 : 나는 이제 마지막 답변을 알고 있어.
최종 답변 : Olivia Wilde의 남자 친구인 Harry Styles는 29 세이고, 그의 나이에 0.23 거듭제곱한 값은 2.169459462491557 이야.
Agent 내부에서 어떤 일들이 일어나는지 궁금한데 아직 그러한 자료들은 보이지 않는듯? 내부 코드를 봐야하겠다.
- 내부적으로 Action Planing 이 어떻게 이뤄지는지 동작 과정이 궁금한데 안보임.
- 질문을 받았을 때 내부적으로 이렇게 행동을 해야겠다라는 청사진을 그려놓은 후 행동을 하는 것인지?
- 중간 단계에서 어떻게 다음 행동을 계획하는 건지? 오리지날 질문을 알고서 그걸 바탕으로 현재 어디까지 왔고, 다음 행동으로 이걸하면 되겠다라고 생각하는건지?
다만 LangChain 내부 Documents 를 정리하면 다음과 같다.
- LagnChain 의 Chain 은 하드코딩된 순서에 따라서 실행되는 반면에 Agent 는 유연하게 동적인 작업을 선택할 수 있다.
- AgentExecutor 에 의해 Action 은 수행되는데 이 Action 은 이전 행동의 결과를 보고 선택함. 어떠한 상태 정보를 이용하는지는 안나와있음.
- 이전에 실행한 결과들은 Intermediate Steps 으로 나타내는데 이걸 통해서 어떠한 작업들을 헀는지 알 수 있음.
- AgentAction 를 통해 에이전트가 해야하는 행동을 나타내며 어떤 도구를 사용할 지 알 수 있음.
LagnChain 에서 Agent 를 다룰 때는 이런 점들도 고려햐라고 함:
- Agent 가 존재하지 않는 Tool 들을 선택할 수도 있음
- Tool 을 실행했을 때 에러가 발생할 수 있음
- Tool 에서 반환된 결과를 Parsing 할 수 없는 경우도 있음
- Looging 과 Monitoring 을 할 수 있도록 해야함.
PAL 이나 ReAct 는 GPT-4 같은 거대 언어 모델일 수록 더 효율이 좋다고 함.
ReAct 에 대한 논문도 있으니 참고하면 좋을듯.
Q) 첫 질문에 대한 Thought 로 단계별로 해야할 과정들을 작성할텐데, 여러 Action 들을 거치고 난 이후에도 해야할 단계별 작업들을 까먹지 않기 위해서는 LLM 은 어떻게 하는거지?
이전에 세웠던 계획이나 현재 단계 그리고 이전 단계를 잊지 않기 위해서 메모리 상으로 상태를 유지한다.
그걸 ReAct 프레임워크는 제공해주는거고
'Generative AI' 카테고리의 다른 글
| Building and Evaluating Advanced RAG (0) | 2024.06.10 |
|---|---|
| Fine-tuning Large Language Models (0) | 2024.05.31 |
| Amazon Bedrock을 이용해 RAG, Fine tuning 없이 자동 고객 응대 서비스 구축하기 (0) | 2024.05.27 |
| LLM In Production (feat: Project Pluto) (0) | 2024.05.26 |
| Generative AI with LLMs: Week 2 (0) | 2024.05.23 |