
이 글은 Beyond RAG: Scaling long context 포스팅을 보고 정리한 글입니다.
RNN 아키텍처에서 Transformer 아키텍처로 발전한 이유:
- RNN(순환 신경망)은 시퀀스를 순차적으로 처리하기 때문에 긴 문맥을 유지하는 데 어려움이 있었음. 뒤로 갈수록 Gradient Vanishing Problem 이 생길 확률이 있었다.
- LSTM 도 이를 완전히 해결하기는 어려웠음.
- 그리고 RNN은 시퀀스를 하나씩 처리하기 때문에 병렬 처리가 어렵기도 함. 이는 훈련 속도를 느리게 만들고, 대규모 데이터 세트를 다루는 데 비효율적임.
Transformer Architecture 의 등장:
- Self-Attention 메커니즘을 바탕으로 문장의 단어가 모든 단어와 상호작용을 통해 계산해서 문맥을 더 잘 이해하게, 중요한 단어를 더 잘 이해하게 만들었음.
- 그리고 Transformer는 단어의 모든 위치를 동시에 처리하는 병렬 처리가 가능했음. 이것과 GPU 의 발전과 합쳐서 훈련 속도가 크게 증가하고 LLM 이 등장했다.
하지만 Transformer 아키텍처의 단점:
- Self-Attention 메커니즘은 시퀀스 길이에 대해 제곱(quadratic)의 계산 복잡도를 가짐. 시퀀스 길이가 2배 길어지면 메모리와 계산 요구사항은 4배가 많아진다.
- 그래서 COntext Window 가 제한된 문제를 완벽하게 해결하기 어려움.
RNN Architecture:
- RNN은 시퀀스 데이터(예: 텍스트, 음성, 비디오)를 처리하고 예측하는 데 사용됨.
- RNN의 핵심 아이디어는 순차적인 데이터의 각 단계에서 이전 단계의 정보를 저장하고 이를 다음 단계에 전달하는 식으로 처리된다.
- 각 단계에서는 Hidden State Vector 를 유지하고 업데이트 하면서 다음 단계의 예측에 사용된다.
- 히든 상태 벡터는 메모리 역할을 하여 시퀀스의 이전 정보를 저장함.
- RNN은 다양한 시퀀스 데이터 처리 모드에 적용될 수도 있음:
- One to One: 단일 입력에 단일 출력
- One to Many: 단일 입력에 다수의 출력
- Many to One: 다수의 입력에 단일 출력
- Many to Many (동기화됨): 다수의 입력과 다수의 출력이 같은 길이로 동기화
- Many to Many (비동기화): 다수의 입력과 다수의 출력이 다른 길이로 비동기화
- RNN은 시퀀스가 길어질수록 이전 정보를 효율적으로 유지하는 데 어렵기 때문에 Vanishing Gradient Problem 를 겪음.

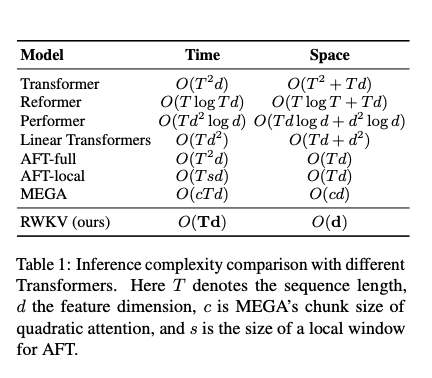
Receptance Weighted Key Value (RWKV) 아키텍처:
- RWKV는 RNN과 Transformer의 장점을 결합하여 만든 아키텍처임. 트랜스포머보다 더 나은 확장성을 가지고 있다고 한다.
- RNN 의 효율적인 추론 능력과 트랜스 포머의 병렬화 훈련을 결합한 거임.
- 트랜스포머는 시퀀스 길이에 대해 제곱적으로 확장되지만, RWKV는 선형적으로 확장된다고 함.
- 그래서 RWKV 아키텍처는 트랜스포머보다 훈련과 추론 시 비용이 더 적게듬.
- Self Attention 매커니즘은 각 토큰이 모든 토큰들과의 관계를 개선해서 중요도를 평가하고, 의미를 분석해서 출력을 생성하는 방식이다.
- RWKV 는 AFT(Attention Free Transformer) 아키텍처를 참고해서 만든 기법인데 AFT 는 학습된 위치 편향 정보를 사용해서 토큰의 상대적 위치를 고려해서 계산을 수행함으로써 전체 시퀀스를 한번에 처리하지 않아도 되는 방식을 말한다.
- 대표적인 Eagle 7b 모델은 다국어 벤치마크에서 다른 7b 파라미터 모델들 (Llama or Mistral) 과 비교해도 추론과 지연 시간 측면에서 우수한 성능을 보인다고 함.
- 다만 과거의 정보를 많이 참조해야 하는 작업에서는 약한 성능을 보이고, 프롬프트 포맷팅에 민감하다고 한다. 그러니까 입력 형식이 모델의 성능에 큰 영향을 미칠 수 있음.
- https://wiki.rwkv.com/?utm_source=div.beehiiv.com&utm_medium=referral&utm_campaign=beyond-rag-scaling-long-context
MonarchMixer 아키텍처:
- 스탠포드 대학교의 Hazy Research 팀이 개발한 새로운 아키텍처로 트랜스포머의 한계를 극복하기 위해 설계됨. 특히, 시퀀스 길이와 모델 차원이라는 두 가지 축에서 트랜스포머가 제곱적으로 확장되는 문제를 해결하려고 함.
- 시퀀스 길이: 트랜스포머의 Self-Attention 메커니즘은 시퀀스 길이에 따라 제곱적으로 확장되어 계산 비용이 증가한다.
- 모델 차원: 트랜스포머의 MLP(다층 퍼셉트론) 레이어도 모델의 차원에 따라 계산 비용이 증가한다.
- Monarch Matrices 를 이용해서 이 문제를 해결함. Monarch Matrices 는 특수한 형태의 텐서, 행렬 구조로 하드웨어 효율성이 높아서 시퀀스 길이와 모델 차원이 증가해도 선형적으로 시간 복잡도가 증가함.
State Space Models (SSMs) 모델:
- 시간에 따라 입력, 출력 및 상태 변수를 기반으로 시스템을 설명함.
- 과거 정보를 상태(state)로 요약하여 다음 상태를 예측하는 데 사용됨.
- SSMs는 다음 두 가지 주요 방정식으로 설명할 수 있다.
- 1) 상태 방정식(State Equation):
- 현재 상태가 시간이 지남에 따라 어떻게 진화하는지, 현재 입력이 상태에 어떤 영향을 미치는지를 설명한다.
- 수학적으로 상태 방정식은 다음과 같다.
- s(t + 1) = f(s(t), x(t))
- s(t) 는 시간 t 에서의 상태, x(t) 는 시간 t 에서의 입력을 말함.
- 2) 출력 방정식 (Output Function)
- 현재 상태가 출력으로 어떻게 변환되는지, 현재 입력이 출력에 어떤 영향을 미치는지 보여준다.
- 수학적으로 출력 방정식은 다음과 같다:
- y(t) = g(s(t), x(t))
- y(t) 는 시간 t 에서의 출력을 말함.
- 1) 상태 방정식(State Equation):
- SSMs는 모든 입력을 동일하게 취급하기 때문에 상태가 작고 효율적이라는 장점이 있다.
- 하지만 RNN 처럼 과거 정보를 잃어버릴 수 있기도 함.
Mamba 아키텍처:
- Selective State Space Models(SSMs)을 기반으로 한 새로운 시퀀스 모델링 아키텍처로 주로 긴 시퀀스를 효율적으로 처리할 수 있음.
- Mamba는 시퀀스 길이에 대해 선형적으로 확장되며, 트랜스포머보다 5배 높은 추론 속도를 자랑한다고 함.
- Selective State Space Models(SSMs)은 입력 토큰의 중요도에 따라 상태 정보를 선택적으로 전파하거나 잊음으로써 긴 시퀀스를 효율적으로 처리하는 모델임
'Generative AI' 카테고리의 다른 글
| Notion 에서 AI 프로덕트를 개발하는 방법 (0) | 2024.07.13 |
|---|---|
| LLMOps (0) | 2024.06.22 |
| Domain-specific LLMs (0) | 2024.06.20 |
| METAGPT: META PROGRAMMING FOR AMULTI-AGENT COLLABORATIVE FRAMEWORK (0) | 2024.06.20 |
| Building Agentic RAG with Llamaindex (0) | 2024.06.20 |